损失函数
总损失定义为:
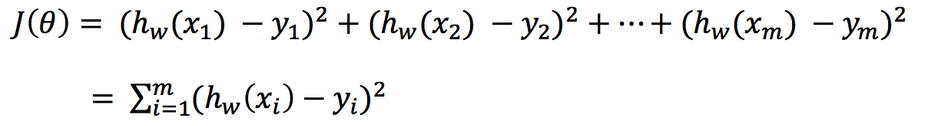
-
yi为第i个训练样本的真实值
-
h(xi)为第i个训练样本特征值组合预测函数
-
又称最小二乘法
-
正规方程
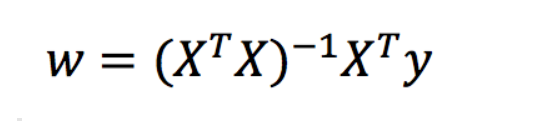
理解:X为特征值矩阵,y为目标值矩阵。直接求到最好的结果
缺点:当特征过多过复杂时,求解速度太慢并且得不到结果

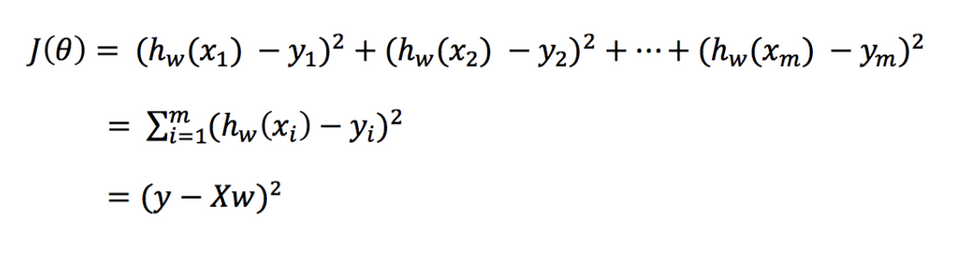
其中y是真实值矩阵,X是特征值矩阵,w是权重矩阵
对其求解关于w的最小值,起止y,X 均已知二次函数直接求导,导数为零的位置,即为最小值。
求导:
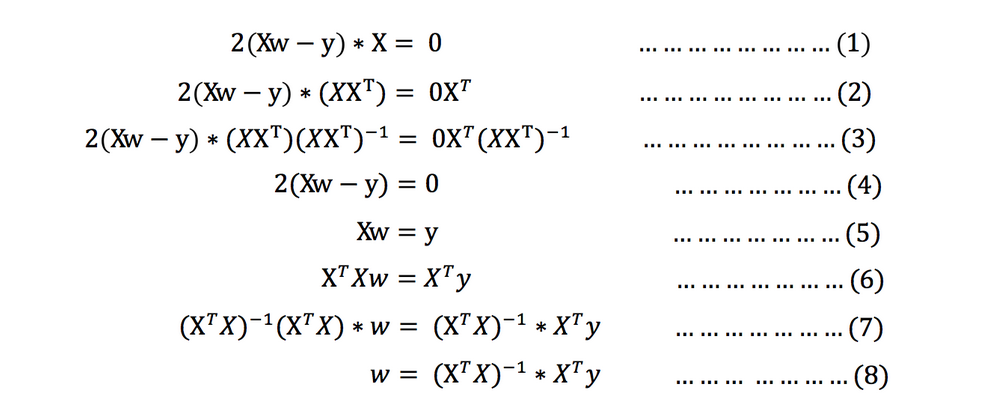
注:式(1)到式(2)推导过程中, X是一个m行n列的矩阵,并不能保证其有逆矩阵,但是右乘XT把其变成一个方阵,保证其有逆矩阵。
式(5)到式(6)推导过程中,和上类似。
梯度下降(Gradient Descent)
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,(同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走)。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
梯度下降的基本过程就和下山的场景很类似。
首先,我们有一个可微分的函数。这个函数就代表着一座山。
我们的目标就是找到这个函数的最小值,也就是山底。
根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向。 所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。
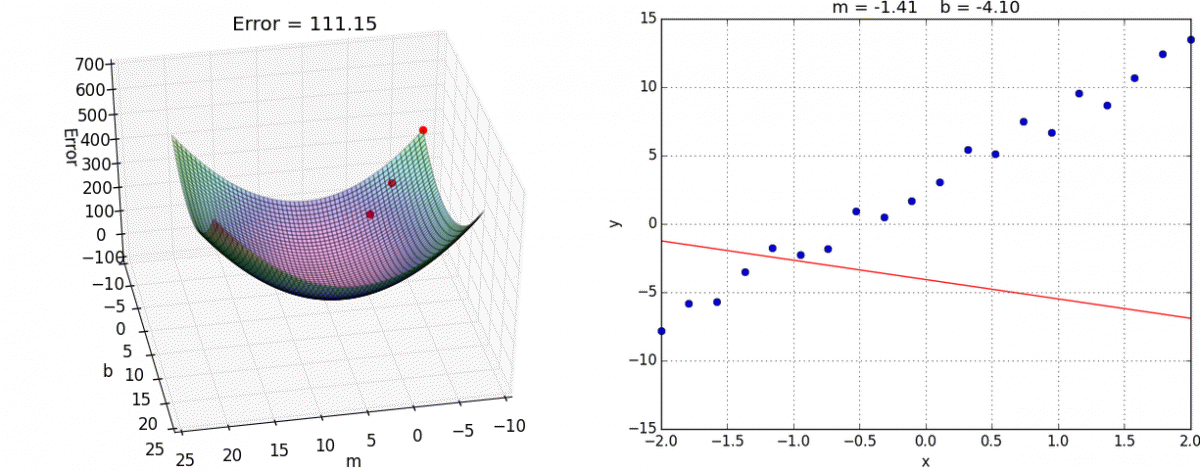
有了梯度下降这样一个优化算法,回归就有了"自动学习"的能力
梯度下降和正规方程的对比
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要迭代求解 | 一次运算得出 |
| 特征数量较大可以使用 | 需要计算方程,时间复杂度高O(n3) |