Day1:
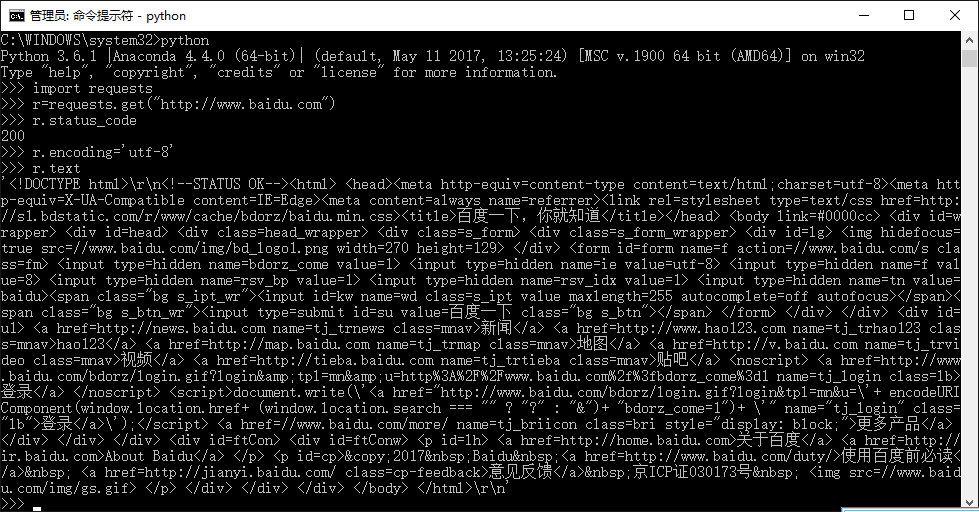
安装python之后,为其配置requests第三方库,并爬取百度主页内容。
语句解释:
r.status_code检测请求的状态码,如果状态码为200,则说明访问成功,否则,则说明访问失败。
注意Response对象的五个属性:
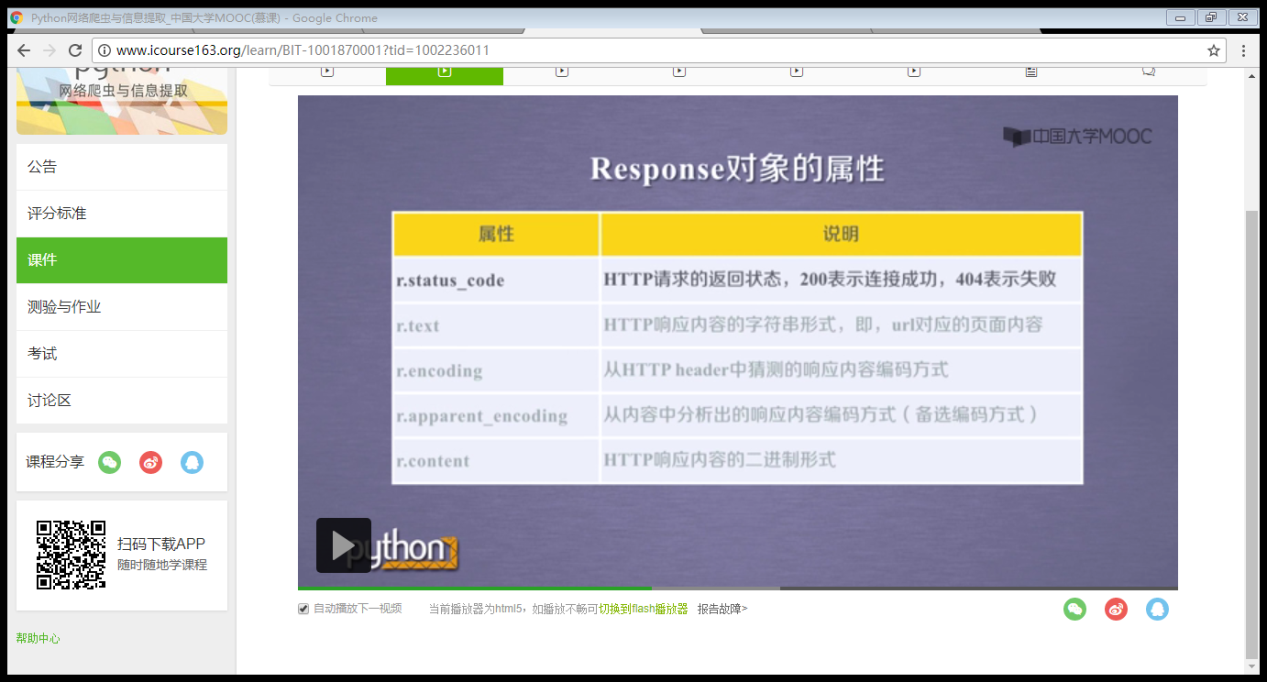
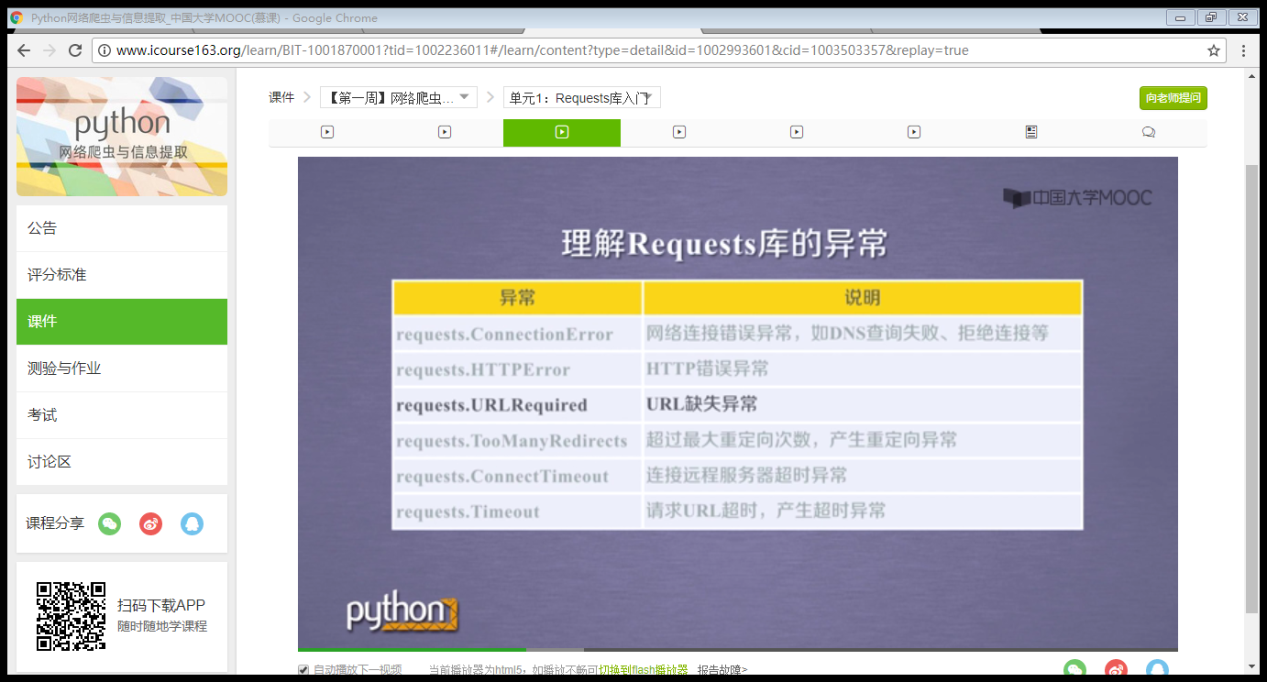
爬取网页的通用代码框架:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
HTTP URL的理解
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
http协议对资源的操作对应requests库的六个操作
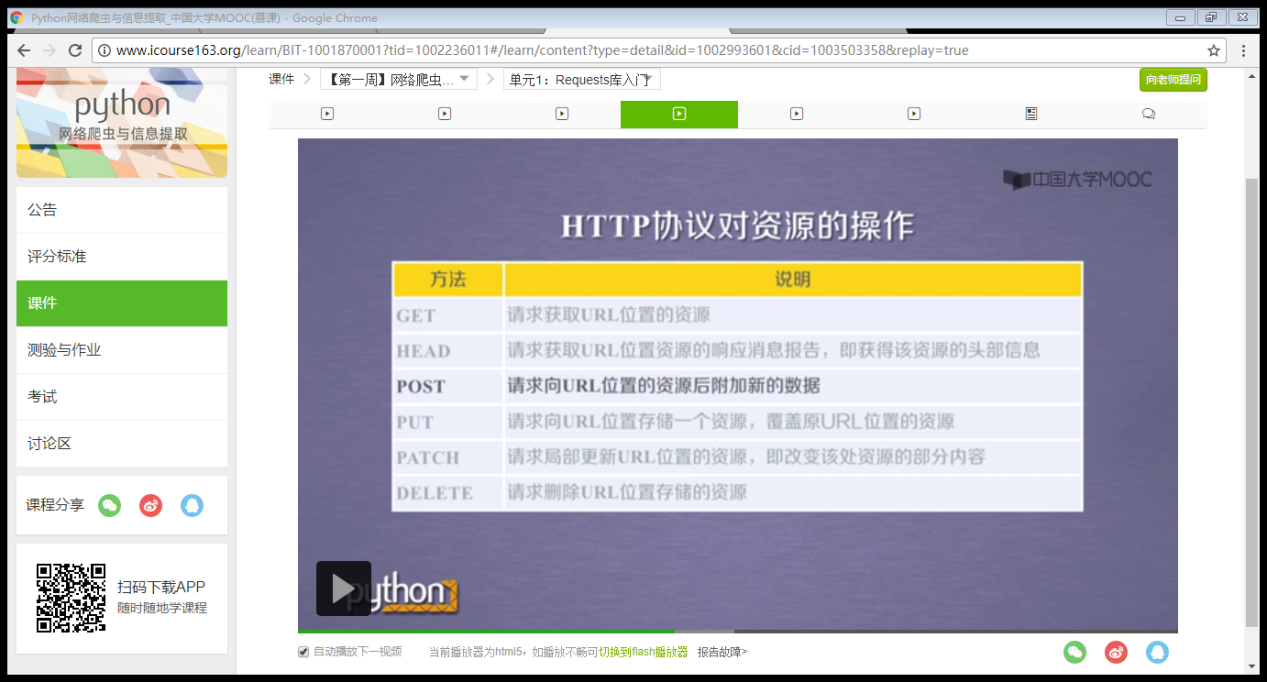
post:向URL POST一个字典,自动编码为form(表单);想URL POST一个字符串,自动编码为data