1.启动所有的线程服务 start-all.sh

记得要查看线程是否启动 jps
2.在根目录创建 wordcount.txt 文件

放置一些数据

3.创建 hdfs dfs -mkdir /文件夹名称

创建成功
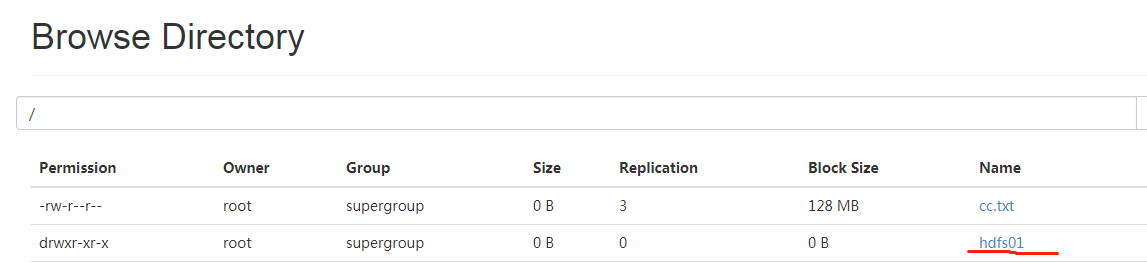
4.将wordcount.txt文件放置 hadfs01下

放置成功

5.到如下图所示的路径
5.1

5.2
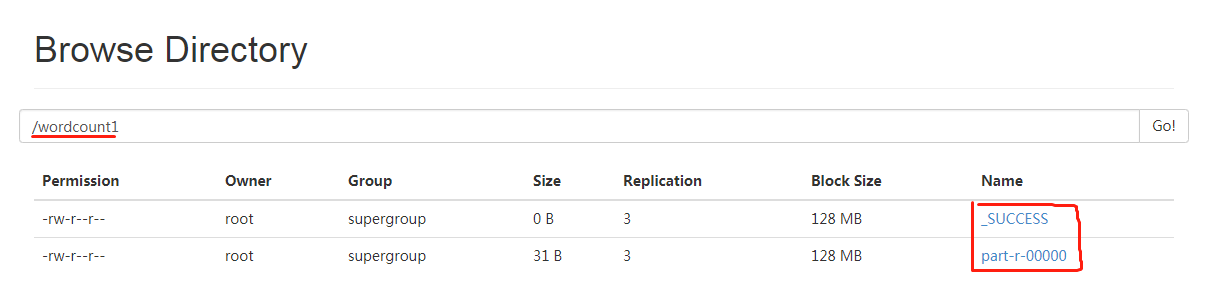
执行该命令 hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /hdfs01/wordcount.txt /wordcount1

成功