一、什么是Flink?
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。
二、Flink特点
1、现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持低延迟、Exactly-Once保证,而批处理一般要支持高吞吐、高效处理
2、Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
技术特点:
1、流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口操作
支持有状态计算 的Exactly-Once语义
支持高度灵活的窗口操作,支持基于time、count、session,以及data-driver的窗口操作
支持具有Backpressure功能的持续六模型
支持基于轻量级分布式快照(Snapshot)实现的容错
支持迭代计算
支持程序自动优化:避免特点情况下Shuffle、排序等操作,中间结果有必要进行缓存
Flink在JVM内部实现了自己的内存管理
2、API支持
对Streaming数据类应用,提供DataStream API
对批处理类应用,提供DataSet API
3、Libraries支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
Flink系统的关键能力
1、低延时:提供ms级延时的处理能力
2、Exactly Once语义:提供异步快照机制,保证所有数据真正只处理一次
3、HA:JobManager支持主备模式,保证无单点故障
4、水平扩展能力:TaskManager支持手动水平扩展
三、Flink技术栈
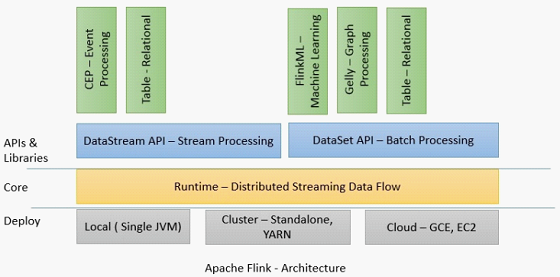
1、从部署上讲,Flink支持Local模式、集群模式(standalone模式或者Yarn模式)、云端部署(GCE、EC2)
2、Runtime是主要的数据处理引擎,它以JobGraph形式的API接收程序。JobGraph是一个简单的并行数据流,包含一些列的tasks,每个task包含了输入和输出(source和sink例外)。
3、DataStream API和DataSet API分别是流处理和批处理的应用程序接口,当程序编译时,生成JobGraph。编译完成后,根据API的不同,优化器(批或流)会生成不同的执行计划。根据不同的部署方式,优化后的JobGraph被提交给executors去执行。
四、Flink架构

Flink整个系统包含三个部分:
1、Client:
给用户提供向Flink系统提交用户任务(流式作业)的能力。用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群。
Client会将用户提交的Flink程序组装成一个JobGraph,并且是以JobGraph的形式提交的。
2、TaskManager:
业务执行节点,执行具体用户任务。TaskManager可以有多个,各个TaskManager都平等。
实际负责执行计算的Worker,在其上执行Flink Job的一组Task。
负责管理其所在节点上的资源信息,如内存、磁盘、网络等,在启动的时候将资源状态向JobManager汇报。
3、JobManager:
管理节点,管理所有的TaskManager,并决策用户任务在哪些TaskManager上执行。
Master进程,Flink系统的协调者,它负责接收Flink Job及Job的管理和资源的协调,包括任务调度,检查点管理,失败恢复、调度组成Job的多个Task执行等。
对于集群为HA模式,可以同时多个master进程,其中一个作为leader,其他作为standby。当leader失败时,会选出一个standby的master作为新的leader(通过zookeeper实现leader选举)
分布式执行:

1、Flink程序提交给JobClient
2、JobClient再提交给JobManager
3、JobManager负责资源的协调和Job的执行
4、待资源分配完成,task就会分配到不同的TaskManager,TaskManager会初始化线程去执行task
5、根据程序的执行状态向JobManager反馈,执行的状态包括starting、in progress、finished以及canceled和failling等等
6、当Job执行完成,结果会返回给客户端
五、其他常用概念
1、Source
Flink系统源数据输入。
可以使用readTextFile(String path)来消费文件中的数据作为流数据的来源,默认情况下的格式是TextInputFormat。也可以通过readFile(FileInputFormat inputFormat,String path)来指定FileInputFormat的格式。
2、Transformation
Transformation允许将数据从一种形式转换为另一种形式,输入源可以是一个也可以是多个,输出则可以是0个、1个或者多个。例如以下Transformations:
Map:输入一个元素,输出一个元素。
FlatMap:输入一个元素,输出0个、1个或多个元素。
Filter:条件过滤使用。
KeyBy:逻辑上按照Key分组,内部使用hash函数进行分组,返回KeyedDataStream。
Reduce:KeyedStream流上,将上一次reduce的结果和本次的进行操作。
Fold:在KeyedStream流上的记录进行连接操作。
Aggregation:在keyedStream上应用类型min、max等聚合操作。
Window:消息流的分段即称为窗口,最常见的就是时间窗口。
我们可以将流切分到有界的窗口中去处理,根据指定的key,切分为不同的窗口。我们可以使用Flink预定义的窗口分配器。当然你也可以通过继承WindowAssginer自定义分配器。
下面看看有哪些预定义的分配器。
1. Global windows:Global window的范围是无限的,你需要指定触发器来触发窗口。通常来讲,每个数据按照指定的key分配到不同的窗口中,如果不指定触发器,则窗口永远不会触发。
2. Tumbling Windows:基于特定时间创建,大小固定,窗口间不会发生重合。例如你想基于event timen每隔10分钟计算一次,这个窗口就很适合。
3. Sliding Windows:大小也是固定的,但窗口之间会发生重合,例如你想基于event time每隔1分钟,统一过去10分钟的数据时,这个窗口就很适合。
4. Session Windows:允许我们设置一个gap时间,来决定在关闭一个session之前,我们要等待多长时间,是衡量用户活跃与否的标志。
WindowAll:WindowAll操作不是基于keu的,是对全局数据进行的计算。由于不基于key,因此是非并行的,即并行度为1,在使用时性能会受到影响。
Union:Union功能就是在2个或多个DataStream上进行连接,成为一个新的DataStream。
Join:Join运行在2个DataStream上基于相同的key进行连接操作,计算的范围也是要基于一个Window进行
Split:Split的功能是根据某些条件将一个流切分为2个或多个流
Select:DataStream根据选择的字段,将流转换为新的流
Project:project功能运行你选择流中的一部分元素作为新的数据流中的字段,相当于做个映射。
3、Sink
数据结果输出。将结果数据输出到不同的地方,Flink提供了以下一些选择:
1、writeAsText():将结果以字符串的形式一行一行写到文本文件中
2、writeAsCsv():保存为csv格式
3、print() / printErr():标准输出或错误输出。输出到Terminal或者out文件
4、writeUsingOutputFotmat():自定义输出格式,需要考虑序列化与反序列化
5、writeUsingOutputFormat():也可以输出到socket,但是你需要定义SerializationSchema。
4、DataStream
Flink中的DataStream程序是实现数据流转换的常规程序(例如,过滤,更新状态,定义窗口,聚合)。
最初从各种源(例如,消息队列,套接字流,文件)创建数据流。结果通过接收器返回,接收器可以例如将数据写入文件或标准输出(例如命令行终端)
5、物理切片
Flink允许我们在流上执行物理分片,当然我们也可以选择自定义partitionning
1、自定义partitioning:根据某个具体的key,将DataStream中的元素按照key重新进行分片,将相同的元素聚合到一个线程中执行。
2、随机partitioning:不根据具体的key,而是随机将数据打散。
3、Rebalancing partitioning:内部使用round robin方法将数据均匀打散。这对于数据倾斜时是很好的选择。广播用于将dataStream所有数据发到每一个partition.