今天心血来潮,想看看异步爬虫的效率和普通爬虫的效率相比究竟如何,然后我选取了一个叫做当当网的购物网站,爬取最热门的书籍。
1. 使用异步的原因
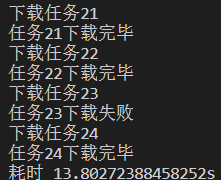
我们都知道异步非堵塞适合高并发的项目,但是在python中最常用的requests库是同步的,这样每次都只能是等上一次请求返回才会进行下一次请求,这样就显然会限制住爬虫的效率,但是随着python一些异步库的更新完善,异步爬虫开始崭露头角。我们可以先看下两种方式的速度对比(排除其他变量影响),第一张图是同步请求的速度,第二张图是异步请求的速度。可以看到总共才25个请求。速度差异就已经这么大了。
,
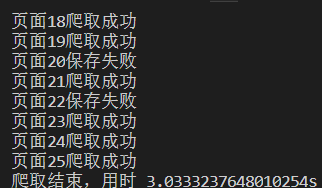
2. 书写异步爬取功能
在这次实践中,我们主要使用aiohttp这个异步库进行请求的提交,值得注意的是,在书写异步爬虫的时候,凡是有需要等待返回的地方,都是需要使用async/await这一语法糖的。aiohttp库发起请求的方式一般是这样的
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url,) as res:
print(await res.text())
return await res.text()
先创建一个ClientSession实例,然后用这个实例的get方法取请求一个url地址,并得到一个返回(这个返回实际上ClientResponse对象),我们的大多数操作都是针对这个返回值的。
然后在解析页面的时候,同样也是需要使用异步的,下面是所有代码
import asyncio
import time
from multiprocessing import Process
import aiohttp
import numpy as np
import pandas as pd
import requests
from scrapy.selector import Selector
from tqdm import tqdm
async def gethtml(url, dicts):
async with aiohttp.ClientSession() as session:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
cookies = {"cookies_are":dicts}
async with session.get(url, headers = headers, cookies = cookies) as res:
# print(await res.text())
try:
#设置编码方式
return await res.text('gb2312')
except:
return ""
#解析页面函数
async def parse(texts):
selector = Selector(text = texts)
css_for_title = 'body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul li > div.name > a::text'
css_for_author = 'body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul li > div:nth-child(5) > a:nth-child(1)::text'
css_for_price = 'body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul li > div.price > p:nth-child(1) > span.price_n::text'
titles = selector.css(css_for_title).extract()
authors = selector.css(css_for_author).extract()
prices = selector.css(css_for_price).extract()
return [titles, authors, prices]
async def main(url):
# print(url_list)
global icon
icon = 1
params = r"ddscreen=2; LOGIN_TIME=1554477709575; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20190405214132382691121618569658467; __visit_id=20190405224707728341459953194932707; __out_refer=; permanent_key=20190405232032240182889951b7f8e2; __rpm=login_page.login_password_div..1554477638469%7Clogin_share_bind_page...1554477708199; USERNUM=9k+wlGHtJmDpgx3V9fNOIA==; login.dangdang.com=.AYH=20190405232138043884709&.ASPXAUTH=H6JEeCLpLDkmMbb6j/xtACG1AULA4xr7xHRQDeCdj7ZIgM3G5eBykg==; dangdang.com=email=MTk5NzUyNjAxOTE1ODE1OEBkZG1vYmlscGhvbmVfX3VzZXIuY29t&nickname=&display_id=9341043676724&customerid=dzoyKRWFYdyI8gvrxuN36Q==&viptype=kXDbk8oIyG0=&show_name=199%2A%2A%2A%2A0191; ddoy=email=1997526019158158%40ddmobilphone__user.com&nickname=&agree_date=1&validatedflag=0&uname=19975260191&utype=&.ALFG=off&.ALTM=1554477708; sessionID=pc_33efdf47b8e4eff005e19cc13b74fffd9cabe44a000313acddd1672306adb00b; __dd_token_id=20190405232148632665868446bf7335; order_follow_source=-%7C-O-123%7C%2311%7C%23login_third_qq%7C%230%7C%23; __trace_id=20190405232149589371503745904925594"
response = await gethtml(url, params)
try:
result = await parse(response)
data = {
'书名':result[0],
'作者':result[1],
'价格':result[2],
}
one_page_msg = pd.DataFrame(data, index = [i for i in range(1,21)])
# if url == 1:
one_page_msg.to_excel("D:/book_data_new{}.xlsx".format(icon),sheet_name="sheet 1",encoding='utf-8')
# else:
# one_page_msg.to_excel("D:/book_data_new.xlsx",sheet_name="sheet 1",encoding='utf-8')
print("页面{}爬取成功".format(icon))
icon += 1
except:
print("页面{}保存失败".format(icon))
icon += 1
if __name__ == "__main__":
url_list = ["http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{}".format(i) for i in range(1,26)]
start_time = time.time()
print("开始爬取")
loop = asyncio.get_event_loop()
# maps = map(lambda main : main(), url_list)
maps = []
for url in url_list:
maps.append(main(url))
loop.run_until_complete(asyncio.wait(maps))
loop.close()
print("爬取结束,用时 {}s".format(time.time()-start_time))
在if name == “main”:后,我们使用了asycio这个python3.5后自带的异步库,aiohttp一般是配合这个库使用,这个库的使用我有写过
python使用asyncio内置库进行异步I/O
这里再简单提一下,我们先获取一个消息循环,然后创建一个包含了所有子事件的任务函数列表,接着将这个列表放入这个消息循环中(使用run_until_complete(asyncio.wait(任务函数列表))方法),这样就实现了异步操作。我们的爬虫部分也分析完了。
3. 导出并合并到一张excel表
其实上面的代码已经实现了导出excel的功能了,我使用的是pandas

data = {
'书名':result[0],
'作者':result[1],
'价格':result[2],
}
one_page_msg = pd.DataFrame(data, index = [i for i in range(1,21)])
# if url == 1:
one_page_msg.to_excel("D:/book_data_new{}.xlsx".format(icon),sheet_name="sheet 1",encoding='utf-8')
但是这个pandas的DataFrame的to_excel方法有个缺点,就是无法再旧的excel表上添加数据,它只会覆盖原来的数据,所以我将他们分成了多份excel文件。然后再写了一份新的代码来将这些excel文件合并
代码如下
import pandas as pd
dp = []
for i in [r"D:ook_data_new{}.xlsx".format(i) for i in range(0,23)]:
try:
dp.append(pd.read_excel(i))
except:
pass
dps = pd.concat(dp)
dps.to_excel(r"D:/book_data_new.xlsx")
print("合并完成")
逻辑就是将所有的excel表都使用panda的read_excel方法形成DataFrame结构并添加到一个列表里,然后使用concat方法合并这些数据,然后产生一张新的excel表。
至此我们完成了所有的功能。
项目我放在的我的github上 https://github.com/ayang818/Useful-Crawl