针对点云无序性—采用maxpooling作为对称函数。最大池化操作保留最大值,不管顺序如何变化,最大值不会改变。
针对刚体变化—对齐网络T-net
特征提取阶段采用MLP,这种结构用到的运算都是乘法和加法(对称函数),不会受到排序影响。
Deep Learning on 3D Data
Volumetric CNNS/Multi-view CNNS/Spectral CNNS/Feature-based DNNS
Point cloud analysis
-
Point cloud: N orderless points, each represented by a D dim coorsinate.
Properties
-
- Unordered→network needs to be invariant to N! permutations of the input set
- Interaction among points→needs to be able to capture local structures from nearby points
- Invariance under transformations
-
Properties of a desired neural network on point clouds
- Permutation invariance 置换不变性
- Examples: f(x1,x2,...xn) = max{x1,x2,...xn}
- Permutation invariance 置换不变性
f(x1,x2,...xn)=x1+x2+...+xn
-
- Transformation invariance 变换不变性
Permutation invariance: 构造Symmetric function
网络的结构一般为:特征提取——特征映射——特征图压缩(降维)——全连接
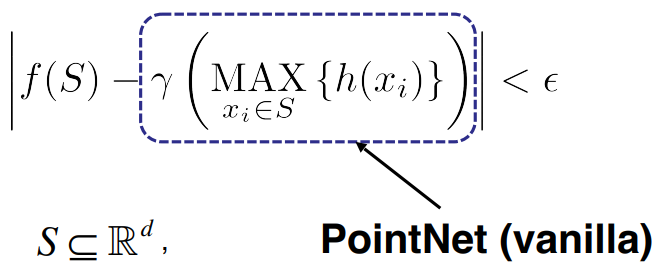
Observe: ![]() is symmetric if g is symmetric. 其中,x代表点云的某个点,h代表特征提取层,g表示对称方法,r表示高维特征提取,最后接softmax分类器。
is symmetric if g is symmetric. 其中,x代表点云的某个点,h代表特征提取层,g表示对称方法,r表示高维特征提取,最后接softmax分类器。
PointNet特征提取层是通过MLP实现,g通过maxpooling 来实现。
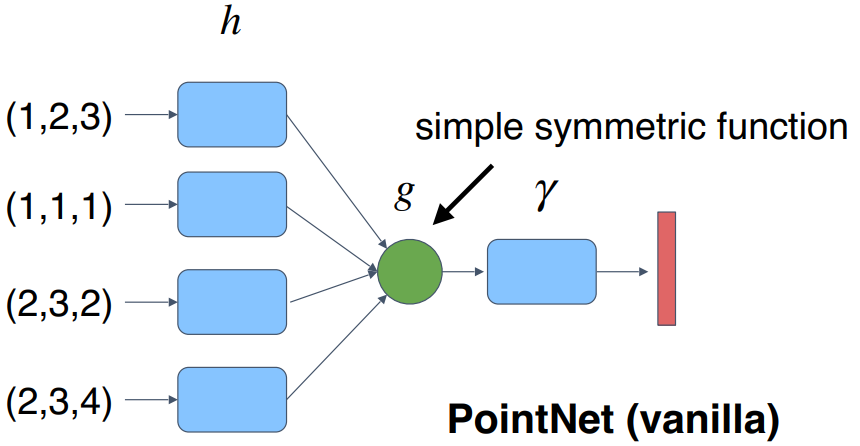
- Q: What symmetric function can be constructed by PointNet?
- A:Universal approximation to continuous symmetric functions
- Theorem:A Hausdorff continuous symmetric function f : 2x→R can be arbitrarily approximated by PointNet
PointNet Architecture

Experiment
3D Object Classification
1. ModelNet40 shape classification benchmark: 12,311 CAD models from 40 man-made object categories, split into 9,843 for training and 2,468 for testing.
2. Sample 1024 points and normalize them into a unit sphere.
3. augment the point cloud on-the-fly by randomly rotating the object along the up-axis and jitter the position of each points by Gaussian noise with zero mean and 0.02 standard deviation.
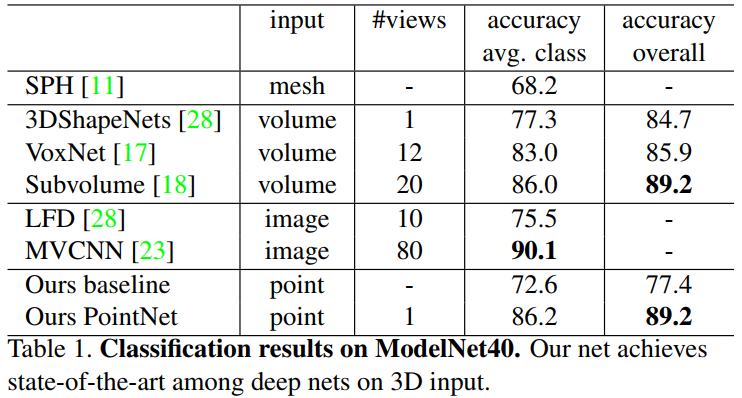
With only fully connected layers and max pooling, PointNet achieves state-of-the-art performance among methods based on 3D input (volumetric and point cloud);
A small gap with Multi-view based method(MVCNN) may be due to the loss of fine geometry details.
3D Object Part Segmentation
1. ShapeNet part data contains 16,881 shapes from categories, annotated with 50 parts in total.
2. Evaluation metric: mIoU
Semantic Segmentation in Scenes
1. Stanford 3D semantic parsing data set
2. Each point is represented by 9-dim vector of XYZ, RGB and normalized location as to the room (from 0 to 1)
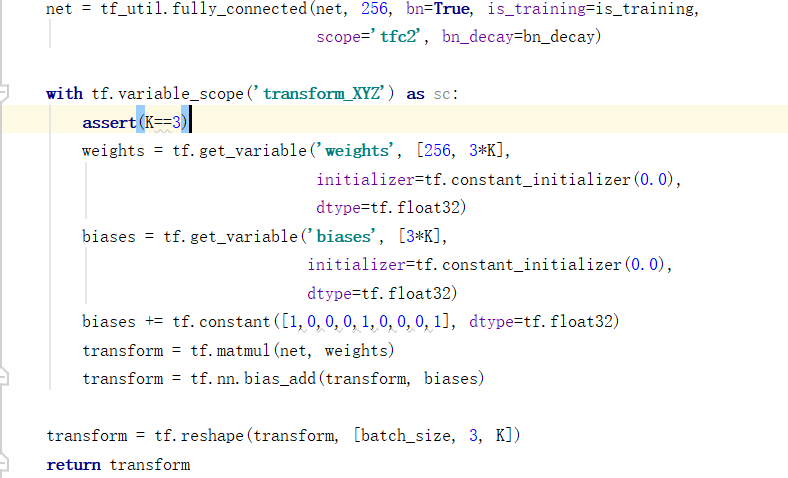
代码分析
T-net:由point independent feature extraction, max pooling, fully connected layers组成