一、二叉树的遍历
1.1 先序遍历
先序遍历:按照根节点->左子树->右子树的顺序访问二叉树
【递归版】
1 public class PreOrderRecur { 2 public static class Node { 3 public int value; 4 public Node left; 5 public Node right; 6 7 public Node(int data) { 8 this.value = data; 9 } 10 } 11 12 public static void preOrderRecur(Node head) { 13 if (head == null) { 14 return; 15 } 16 System.out.println(head.value + " "); 17 preOrderRecur(head.left); 18 preOrderRecur(head.right); 19 }
怎么理解上述递归的先序遍历?

先打印当前节点,然后打印整颗左子树,然后再打印整颗右子树。上图二叉树的打印顺序为:1、2、4、5、3、6、7
实际应该怎么理解preOrderRecur()这个函数呢?其实来到每个节点的顺序并不是打印顺序。下面来套一下preOrderRecur这个函数:
来到1后,然后去它的左孩子,1→2,2→4,此时4遇到null,直接返回,返回后又回到4,然后又去4的右孩子,右孩子为null,又回到4,整个4这颗树遍历完后,回到2,2去到它的右孩子,来到5,5的左孩子null,直接返回,又回到5,然后又回到5的右孩子,右孩子为null,又回到5,依次类推。。。
所以如果忽略第16行的打印行为,递归函数来到每个节点的顺序是:1、2、4、4、4、2、5、5、5、2、1、3、6、6、6、3、7、7、7、3、1。
在这样一个顺序中,如果把打印放在第一次来到这个节点的时候,就是先序遍历:1、2、4、5、3、6、7
如果把打印放在第二次来到这个节点的时候,就是中序遍历:4、2、5、1、6、3、7
如果把打印放在第三次来到这个节点的时候,就是后序遍历:4、5、2、6、7、3、1
所以preOrderRecur这个函数依次访问节点时,每个节点都会访问3次,这个顺序是不变的,只是你把打印时机放在哪,就被加工成先序、中序、后序三种遍历方式。
所以重要的是理解递归函数这个结构的节点访问顺序,至于是哪种遍历,只是打印时机的问题。
【非递归版】
1 public static void preOrderUnRecur(Node head) { 2 System.out.println("pre-order: "); 3 if (head != null) { 4 Stack<Node> stack = new Stack<>(); 5 stack.add(head); 6 while (!stack.isEmpty()) { 7 //head变量被复用了,可以将此head理解为当前节点 8 head = stack.pop(); 9 System.out.println(head.value + " "); 10 //如果该节点的右孩子不为空 11 if (head.right != null) { 12 //栈中压右孩子 13 stack.push(head.right); 14 } 15 if (head.left != null) { 16 stack.push(head.left); 17 } 18 } 19 } 20 }
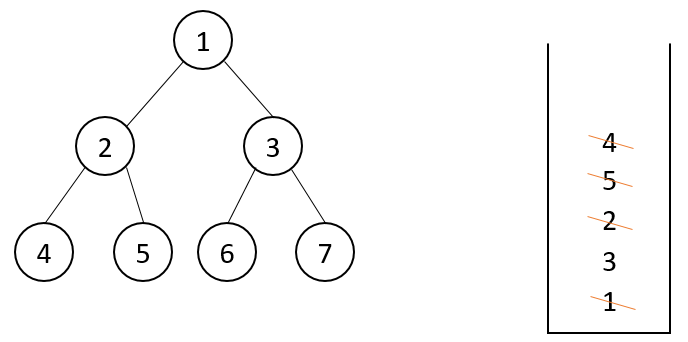
准备一个栈,先把头节点1放进去,开始走第6行的while循环:栈不为null,弹出栈顶1,并打印,1的右孩子3不为空,3进栈,1的左孩子2不为空,2进栈;继续此while循环,将2节点弹出并打印,2有右孩子5,5进栈,2有左孩子4,4进栈;再来到while循环,4被弹出并打印,因为4无左、右孩子,没有把任何东西放进栈里;再次来到while循环,将5弹出并打印,5也没有孩子,所以栈也不会进入新的节点。。。重复此过程。
当前节点被弹出的时候,先压右,后压左,弹出就是先弹左后弹右,于是当前节点为头,弹出的顺序是先左后右,先序遍历的顺序就被模拟出来了。
为什么要使用栈而不用队列?
因为二叉树只有从上到下的路径,没有回去的路径,所以就得想一个结构,让它能够回去,栈就再合适不过了。比如栈中压了1、2、4,我们可以依次弹出4、2、1,因为二叉树的整体顺序是从上到下的,而我们在遍历到某一位置的时候,我们是希望能回去的,所以这个结构就必须是:遍历的时候从上到下,回去的时候从下到上,所以要使用栈。如果使用队列的话,遍历的时候是从上到下的,队列又只能让你从上到下,所以就不能使用队列。
1.2 中序遍历
中序遍历:按照左子树->根节点->右子树的顺序访问
【递归版】
public static void inOrderRecur(Node head) { if (head == null) { return; } inOrderRecur(head.left); System.out.print(head.value + " "); inOrderRecur(head.right); }
【非递归版】
public static void inOrderUnRecur(Node head) { System.out.print("in-order: "); if (head != null) { Stack<Node> stack = new Stack<Node>(); while (!stack.isEmpty() || head != null) { if (head != null) { stack.push(head); head = head.left; } else { head = stack.pop(); System.out.print(head.value + " "); head = head.right; } } } System.out.println(); }
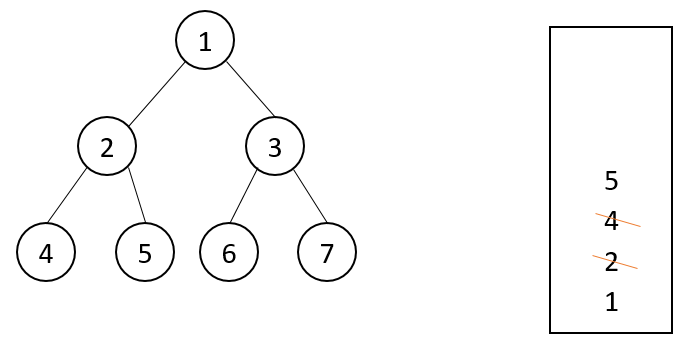
整体思路:只要是当前节点,就先把自己的左边界(包括当前节点在内整条左侧的边)先压到栈里。当前节点不为空时,当前节点压入栈,当前节点往左;当前节点为空时,从栈拿一个,让它变成当前节点,打印,当前节点往右边走。这个过程先压一侧左边界并依次往外弹,弹到每个节点再去遍历右孩子的过程,就是模拟了左中右的过程。
如上图,head依次指向1、2、4节点,1、2、4进栈,因为4无左孩子,此时head指向null。然后从栈中拿出一个节点4并打印,往4的右边(右孩子)走,右边又是空,接着从栈拿出2,当前节点往右走,即来到2的右孩子5,此时当前节点5不为空,将5压入栈;当前节点从5来到5的左孩子(null),5弹出。。。重复此过程,遍历结果为4、2、5、1、6、3、7
1.3 后序遍历
后序遍历:按照左子树->右子树->根节点的顺序访问
【递归版】
public static void posOrderRecur(Node head) { if (head == null) { return; } posOrderRecur(head.left); posOrderRecur(head.right); System.out.print(head.value + " "); }
【非递归版】
实现思路:
如果要实现“中右左”的遍历好不好实现?这很好实现,因为先序遍历是“中左右”,这个过程是当前节点先压右孩子,再压左孩子。怎么改出一个“中右左”的遍历?当前节点先压左孩子,再压右孩子就变成“中右左”了。实现“中右左”后,打印的时候我们可以先不打印,而是存入一个辅助的栈里,因为栈是一种顺序的逆序,所以当你实现中右左后,放到栈里后,把栈中的元素依次弹出就是左右中了,这就是后序遍历。
public static void postOrderUnRecur(Node head) { System.out.println("post-order: "); if (head != null) { Stack<Node> s1 = new Stack<>(); Stack<Node> s2 = new Stack<>(); s1.push(head); while (!s1.isEmpty()) { head = s1.pop(); s2.push(head); if (head.left != null) { s1.push(head.left); } if (head.right != null) { s1.push(head.right); } } while (!s2.isEmpty()) { System.out.print(s2.pop().value + " "); } } }
二、如何直观的打印一棵二叉树
二叉树可以用常见的三种遍历结果来描述其构造,但是不够直观,尤其是二叉树中有重复值的时候,仅通过三种遍历的结果来构造二叉树的真实结构是难上加难。
那么我们如何设计一个更直观的二叉树描述呢?首先我们来看下面图中这个二叉树结构,我们来设计一个算法用来更直观的描述树的结构
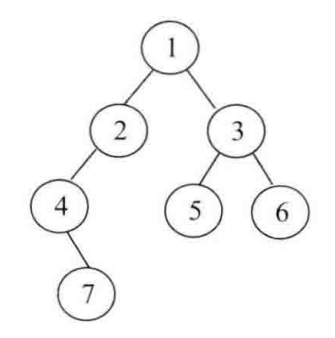
public class PrintBinaryTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } public static void printTree(Node head) { System.out.println("Binary Tree:"); printInOrder(head, 0, "H", 17); System.out.println(); } /** * * @param head 头结点 * @param height 树的高度 * @param to 字符表示 H代表头 V代表右结点,v代表左结点 * @param len */ public static void printInOrder(Node head, int height, String to, int len) { //保证结点空时退出递归 if (head == null) { return; } //先递归遍历右结点,找到右结点就输出加上符号V和固定空格的字符 printInOrder(head.right, height + 1, "v", len); //获得该结点对应的字符,VnumV,表示右结点 String val = to + head.value + to; //计算需要补多少位的空格 int lenM = val.length(); int lenL = (len - lenM) / 2; int lenR = len - lenM - lenL; val = getSpace(lenL) + val + getSpace(lenR); //输出补位空格的字符 System.out.println(getSpace(height * len) + val); //递归遍历左结点,如果不为空则打印字符 ^num^ printInOrder(head.left, height + 1, "^", len); } public static String getSpace(int num) { String space = " "; StringBuffer buf = new StringBuffer(""); for (int i = 0; i < num; i++) { buf.append(space); } return buf.toString(); } public static void main(String[] args) { Node head = new Node(1); head.left = new Node(2); head.right = new Node(3); head.left.left = new Node(4); head.right.left = new Node(5); head.right.right = new Node(6); head.left.left.right = new Node(7); printTree(head); } }
这个函数可以将你的二叉树非常直观以一棵树的样子打印出来,不过打印出来的结果需要将头旋转逆时针90度来看

上面打印结果中,H1H表示1是头节点,v6v指的是,我的父节点是我左下方离我最近的,即节点3;^5^表示,我的父节点是我左上方离我最近的,即节点3。
三、在二叉树中找到一个节点的后继节点
【题目】
现在有一种新的二叉树节点类型如下:
public class Node { public int value; public Node left; public Node right; public Node parent; public Node(int data) { this.value = data; } }
该结构比普通二叉树节点结构多了一个指向父节点的parent指针。假设有一 棵Node类型的节点组成的二叉树, 树中每个节点的parent指针都正确地指向自己的父节点,头节点的parent指向null。只给一个在二叉树中的某个节点 node, 请实现返回node的后继节点的函数。
【分析】
首先要理解一个概念:在二叉树的中序遍历的序列中, node的下一个节点叫作node的后继节点;在中序遍历序列中,一个节点的前一个节点叫它的前驱节点。

这颗二叉树中序遍历的序列为:4、2、5、1、6、3、7。2就是4的后继节点,5是2的前驱节点。
有一种很笨的方法:不管给的是哪个节点,通过parent指针都能找到头节点,然后从头节点开始,进行中序遍历得到一个序列,从序列中就能知道该节点的下一个节点。但是这样做会遍历整棵树,复杂度较高。
我们能不能不用遍历整棵树,就能找到一个节点的后继节点呢?比如说给你3,它的后继节点是7,能不能只走过2个节点就能找到7,而不用遍历整棵树,生成一个序列后才找到7?
整体思路如下:
一个节点X,如果X有右子树,这个X的后继节点一定是它右子树最左的节点。比如2有右子树,它的后继节点就是5;再比如1,有右子树,它的后继节点就是1的右子树最左的节点,即6。
一个节点X,如果X没有右子树,首先要考察X到底作为哪一个节点左子树的最后一个节点。比如节点4没有右子树,就要考察到底哪个节点,4作为整颗左子树的最后一个节点,2就是这样的节点,2的左子树的最后一个节点是4;如果给的是5,5也没有右子树,就要找到底是哪个节点,它的左子树的最后一个节点是5,5是作为1整颗左子树的最后一个节点被打印的,所以1就是5的后继节点;如果给的是7,哪个节点的左子树是以7结尾的,没有,所以7的后继不存在。于是这个问题就变成了:当X没有右子树,通过X的parent指针找到X的父节点,如果发现X不是父节点的左孩子,就继续往上,直到某个节点是它父节点的左孩子停止,父节点就是原始节点的后继。比如一开始X指向5,parent指向2,因为5不是2的左孩子,所以X往上指向2,parent指向1,2是1的左孩子,此过程停止,1就是5的后继节点。
public class SuccessorNode { public static class Node { public int value; public Node left; public Node right; public Node parent; public Node(int data) { this.value = data; } } /** * 得到某个节点的后继节点 * @param node 不是指头节点,而是二叉树中的某一个节点 * @return */ public static Node getSuccessorNode(Node node) { if (node == null) { return node; } //如果当前节点的右孩子不为空,说明当前节点有右子树 if (node.right != null) { //直接找到右子树最左的节点 return getLeftMost(node.right); } else { //当前节点没有右子树 Node parent = node.parent; //parent=null,或者当前节点等于自己parent的左孩子时,while停止 while (parent != null && parent.left != node) { node = parent; parent = node.parent; } return parent; } } /** * 找到这颗子树最左的节点 * @param node 某一颗子树的头部 * @return */ public static Node getLeftMost(Node node) { if (node == null) { return node; } while (node.left != null) { node = node.left; } return node; } public static void main(String[] args) { Node head = new Node(6); head.parent = null; head.left = new Node(3); head.left.parent = head; head.left.left = new Node(1); head.left.left.parent = head.left; head.left.left.right = new Node(2); head.left.left.right.parent = head.left.left; head.left.right = new Node(4); head.left.right.parent = head.left; head.left.right.right = new Node(5); head.left.right.right.parent = head.left.right; head.right = new Node(9); head.right.parent = head; head.right.left = new Node(8); head.right.left.parent = head.right; head.right.left.left = new Node(7); head.right.left.left.parent = head.right.left; head.right.right = new Node(10); head.right.right.parent = head.right; Node test = head.left.left; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.left.left.right; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.left; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.left.right; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.left.right.right; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.right.left.left; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.right.left; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.right; System.out.println(test.value + " next: " + getSuccessorNode(test).value); test = head.right.right; // 10's next is null System.out.println(test.value + " next: " + getSuccessorNode(test)); } }
补充问题:如何找一个节点的前驱节点?
X如果有左子树,左子树最右的节点就是它的前驱节点;X如果没有左子树,就往上找,直到某个节点是它父节点的右孩子就停止。
四、介绍二叉树的序列化和反序列化
【题目】
首先我们介绍二叉树先序序列化的方式,假设序列化的结果字符串为str,初始时str等于空字符串。先序遍历二叉树,如果遇到空节点,就在str的末尾加上“#!”,“#”表示这个节点为空,节点值不存在,当然你也可以用其他的特殊字符,“!”表示一个值的结束。如果遇到不为空的节点,假设节点值为3,就在str的末尾加上“3!”。现在请你实现树的先序序列化。给定树的根结点root,请返回二叉树序列化后的字符
【序列化】
我们知道所谓的二叉树是一种由对象引用将多个结点关联起来的抽象数据结构,是存在于内存中的,不能进行持久化,如果需要将一颗二叉树的结构持久化保存,需要将其转换为字符串并保存到文件中,于是关键是建立一套规则,使得二叉树可以与字符串一一对应,根据一个二叉树可以唯一的得到一个字符串,根据一个字符串也可以唯一的还原出一棵二叉树。
比如上面这棵树,它存在于内存里,怎么给它序列化呢?即怎么将这棵树变成字符串?把这个字符串记录在文本里面,下次建这棵树的时候,只要通过这个字符串就能还原成原来的树。
先序遍历的序列化结果就是:1!2!4!#!#!5!#!#!3!6!#!#!7!#!#!
遍历时对于为null的结点在判断条件中会直接跳过或者返回,但是在序列化时,对于为null的结点也需要遍历并将其对应为”#!”,即在序列化时对于任何null或者非null的结点都需要遍历和处理因此我们只是对非空的结点进行遍历,在遍历每个非空的结点时关注它的子节点是否为null,如果为null就为字符串加上“#!”并且不再继续遍历,如果不为null就继续遍历。
public class SerializeTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } /** * 先序序列化 * @param head * @return */ public static String serialByPre(Node head) { if (head == null) { return "#!"; } //先把当前节点作为整个字符串的头 String res = head.value + "!"; //然后加上左树形成的字符串 res += serialByPre(head.left); //再加上右树形成的字符串 res += serialByPre(head.right); //就是整颗树形成的结果 return res; } }
为什么要用到#呢?

比如这两颗树,它们的遍历结果都是1、1、1。如果我们不用#把位置占住,就无法区分原来的结构了。
为什么要用到!作为一个值的结尾?

比如这两棵树,如果不用一个字符来占结尾的话,上面两棵树遍历结果都是123,就无法区分是1、23还是12、3了,所以我们需要在一个值的结尾加上!来标记,这样1!23!和12!3!就能区分开了。
【反序列化】
所谓反序列化是根据一个字符串重新建立一棵二叉树,反序列化是序列化的逆过程,对于一个字符串,首先按照分隔符!将其分割为字符串数组,每个字符串元素代表一个结点,如果使用的是先序遍历的方式序列化的,就使用先序遍历的方式将字符串反序列化为二叉树。
/** * 将先序遍历序列化的字符串,反序列化为二叉树 * @param preStr * @return */ public static Node reconByPreString(String preStr) { String[] values = preStr.split("!"); Queue<String> queue = new LinkedList<>(); //将数组元素依次假如队列中,这样就可以依次弹出了 for (int i = 0; i != values.length; i++) { /* 区分add()和offer(): 两者都是往队列尾部插入元素,不同的是,当超出队列界限的时候,add()方法是抛出异常让你处理, 而offer()方法是直接返回false */ queue.offer(values[i]); } return reconPreOrder(queue); } public static Node reconPreOrder(Queue<String> queue) { String value = queue.poll(); if (value.equals("#")) { //如果value等于#,当前节点建出一个null return null; } //因为是采用先序序列化的,所以反序列化时也是先中再左再右 Node head = new Node(Integer.valueOf(value)); head.left = reconPreOrder(queue); head.right = reconPreOrder(queue); return head; }
中序遍历和后序遍历的序列化与反序列化与先序遍历基本相似。下面补充一个层次遍历的序列化与反序列化

这棵树层次遍历序列化的字符串为:1!2!3!5!#!#!6!#!#!#!#!(注意,5和6节点下面还有一层null节点)
public class SerializeTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } /** * 按层次遍历序列化 * @param head * @return */ public static String serialByLevel(Node head) { if (head == null) { return "#!"; } String res = head.value + "!"; Queue<Node> queue = new LinkedList<>(); queue.offer(head); while (!queue.isEmpty()) { head = queue.poll(); if (head.left != null) { res += head.left.value + "!"; queue.offer(head.left); } else { res += "#!"; } if (head.right != null) { res += head.right.value + "!"; queue.offer(head.right); } else { res += "#!"; } } return res; } /** * 按层次遍历的方式反序列化 * * @param levelStr * @return */ public static Node reconByLevelString(String levelStr) { String[] values = levelStr.split("!"); int index = 0; Node head = generateNodeByString(values[index++]); Queue<Node> queue = new LinkedList<>(); if (head != null) { queue.offer(head); } Node node = null; while (!queue.isEmpty()) { node = queue.poll(); node.left = generateNodeByString(values[index++]); node.right = generateNodeByString(values[index++]); if (node.left != null) { queue.offer(node.left); } if (node.right != null) { queue.offer(node.right); } } return head; } public static Node generateNodeByString(String val) { if (val.equals("#")) { return null; } return new Node(Integer.valueOf(val)); } /** * 直观打印二叉树 * @param head */ public static void printTree(Node head) { System.out.println("Binary Tree:"); printInOrder(head, 0, "H", 17); System.out.println(); } public static void printInOrder(Node head, int height, String to, int len) { if (head == null) { return; } printInOrder(head.right, height + 1, "v", len); String val = to + head.value + to; int lenM = val.length(); int lenL = (len - lenM) / 2; int lenR = len - lenM - lenL; val = getSpace(lenL) + val + getSpace(lenR); System.out.println(getSpace(height * len) + val); printInOrder(head.left, height + 1, "^", len); } public static String getSpace(int num) { String space = " "; StringBuffer buf = new StringBuffer(""); for (int i = 0; i < num; i++) { buf.append(space); } return buf.toString(); } public static void main(String[] args) { Node head = null; head = new Node(1); head.left = new Node(2); head.right = new Node(3); head.left.left = new Node(4); head.right.right = new Node(5); printTree(head); String level = serialByLevel(head); System.out.println("serialize tree by level: " + level); head = reconByLevelString(level); System.out.print("reconstruct tree by level, "); printTree(head); } }
五、判断一棵二叉树是否是平衡二叉树
平衡二叉树(Balanced Binary Tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。

根据上述性质我们可以发现图(a)是一棵平衡二叉树,而图(b)是一棵不平衡二叉树。图中结点的数值代表的就是当前结点的平衡因子。也验证了上述性质,一棵平衡二叉树的所有结点的平衡因子只可能是-1、0、1三种。
判断一棵树是不是平衡树,大的思路是:如果以每一个点作为头节点的树都是平衡树,则整棵树是平衡的。
假设遍历到X,怎么判断X的整棵树是不是平衡的?我们要收集以下信息:(1)左树是否平衡,如果不平衡,直接返回false;(2)右树是否平衡,如果不平衡,返回false;(3)在左树和右树都平衡的情况下,左树的高度是多少?(4)在左树和右树都平衡的情况下,右树的高度是多少?然后就可以判断左树和右树的高度差是否超过1。
列出上述的可能性后,设计递归返回结构。左树的过程应该给我一个返回值,返回值里包含(1)和(3)的信息;右树也要返回(2)和(4)的信息。所以递归函数的返回值应该包含两个信息:这颗树是否平衡,和这颗树的高度是多少。
public class IsBalancedTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } /** * 设计递归函数的返回值 */ public static class ReturnData { public boolean isBalance; public int height; public ReturnData(boolean isBalance, int height) { this.isBalance = isBalance; this.height = height; } } /** * 递归函数 * @param head * @return */ public static ReturnData process(Node head) { if (head == null) { return new ReturnData(true, 0); } ReturnData leftData = process(head.left); if (!leftData.isBalance) { return new ReturnData(false, 0); } ReturnData rightData = process(head.right); if (!rightData.isBalance) { return new ReturnData(false, 0); } if (Math.abs(leftData.height - rightData.height) > 1) { return new ReturnData(false, 0); } return new ReturnData(true, Math.max(leftData.height, rightData.height) + 1); } /** * 判断是否是平衡二叉树 * @param head * @return */ public static boolean isBalanceTree(Node head) { return process(head).isBalance; } public static void main(String[] args) { Node head = new Node(1); head.left = new Node(2); head.right = new Node(3); head.left.left = new Node(4); head.left.left.right = new Node(5); System.out.println(isBalanceTree(head)); } }
六、判断一棵树是否是搜索二叉树
二叉搜索树(BST),也称有序二叉树,排序二叉树,是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树。
- 没有键值相等的节点。

怎么判断一棵树是不是搜索二叉树?二叉树中序遍历的节点是依次升序的就是搜索二叉树。
使用二叉树遍历的非递归版本更方便判断,采用二叉树的中序遍历的非递归版本,在其中打印的位置用比较大小代替即可。
public class IsBSTTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } public static boolean isBSTTree(Node head) { if (head == null) { return true; } int preNode = Integer.MIN_VALUE; Stack<Node> stack = new Stack<>(); while (!stack.isEmpty() || head != null) { if (head != null) { stack.push(head); head = head.left; } else { head = stack.pop(); if (preNode > head.value) { return false; } preNode = head.value; head = head.right; } } return true; } public static void main(String[] args) { Node head = new Node(4); head.left = new Node(3); head.right = new Node(6); System.out.println(isBSTTree(head)); } }
七、判断一棵树是否是完全二叉树
判断逻辑:二叉树按层次遍历。
(1)如果一个节点有右孩子,但是没有左孩子,一定不是完全二叉树,直接返回false;
(2)如果一个节点不是左右孩子都全(有左无右、或者左右都没),它后面遇到的所有节点都必须是叶子节点,否则一定不是完全二叉树。
如果遍历完整颗二叉树后,都不违法(1)和(2),那么这棵树就是完全二叉树。
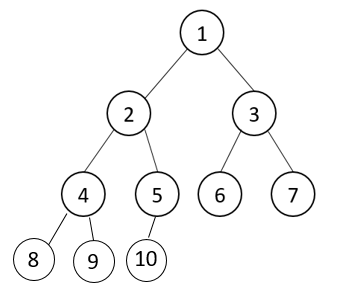
遍历到5之前的节点都不满足(1)和(2)的条件,5节点有左孩子,但无右孩子,因为5后面遇到的所有节点都是叶子节点,符合(2)条件,所以该树是完全二叉树。
public class IsCBTTree { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } public static boolean isCBT(Node head) { if (head == null) { return true; } Queue<Node> queue = new LinkedList<>(); //如果出现情况(2),leaf变为true,此时后面遇到的节点必须是叶子节点 boolean leaf = false; Node l = null; Node r = null; queue.offer(head); while (!queue.isEmpty()) { head = queue.poll(); l = head.left; r = head.right; /* (leaf && (l != null || r != null)):开启了叶子节点的阶段,并且左孩子不等于空,或者右孩子不等于空,返回false 即,如果开启了后序节点都是叶节点这一阶段,拿到的每一个节点的左右孩子都必须是null,否则返回false (l == null && r != null):情况(1),如果一个节点左孩子为空,右孩子不为空,直接返回false */ if ((leaf && (l != null || r != null)) || (l == null && r != null)) { return false; } if (l != null) { queue.offer(l); } if (r != null) { queue.offer(r); } //如果左右孩子不全,开启阶段 if (l == null || r == null) { leaf = true; } } return true; } public static void main(String[] args) { Node head = new Node(1); head.left = new Node(2); head.right = new Node(3); head.left.left = new Node(4); System.out.println(isCBT(head)); } }
八、已知一棵完全二叉树,求其节点的个数
要求:时间复杂度低于O(N),N为这棵树的节点个数
【分析】
不能通过遍历来求得节点个数,因为这样是严格的O(N)。
已知一个结论:如果一颗满二叉树的高度为h,那么它的节点个数是2h-1。
先遍历整棵树的左边界,因为这是一颗完全二叉树,所以遍历左边界后,就能知道这棵树的高度h,并记录高度。如果这棵树的节点是N,那么遍历左边界的代价是O(logN)。
然后遍历头节点X的右子树的左边界,判断右子树的左边界有没有到最后一层。
情况一:判断右子树的左边界到最后一层,那么X的左子树就是满的,左子树的高度就是3,所以左子树的节点数就是23-1,再加上头节点:23-1+1=23
右子树也是完全二叉树,可以递归求右子树的节点个数。
情况二:右子树的左边界没到最后一层,右子树就是满的,高度为左树满的高度-1,此处右子树的高度为2,那么右子树的节点个数就是22-1,再加上头节点:22-1+1。而左树又是一颗完全二叉树,递归左树。

所以每次拿到一个节点,就判断它右树的左边界有没有到最后一层,到了,左树就是满的;没到,右树是满的。只不过是左树满和右树满的高度不一样而已。
public class CompleteTreeNodeNumber { public static class Node { public int value; public Node left; public Node right; public Node(int data) { this.value = data; } } public static int nodeNum(Node head) { if (head == null) { return 0; } return bs(head,1,mostLeftLevel(head,1)); } /** * 递归过程 * @param node 当前节点 * @param level node在第几层 * @param h 固定值,表示整棵树的深度 * @return 以这个node节点为头的节点个数 */ public static int bs(Node node, int level, int h) { //如果level来到最后一层,node就是叶子节点,因为node在level上 if (level == h) { return 1; } //mostLeftLevel(node.right, level + 1)求这个node的右子树的最左的深度 //如果node的右子树的最左的深度和整体深度相等 if (mostLeftLevel(node.right, level + 1) == h) { //1<<(h-level):相当于2^(h-level),表示左树的节点个数+当前节点之后的节点总数 //bs(node.right, level + 1, h):右树也是一颗完全二叉树,递归求它的节点个数 return (1 << (h - level)) + bs(node.right, level + 1, h); } else { //右子树的左边界没到树的总深度 //(h-level-1):右树的高度比左树的高度少一个 return (1 << (h - level - 1)) + bs(node.left, level + 1, h); } } /** * 从node开始,node处在level层,求整棵树最左的边界到了哪一层 * @param node * @param level * @return */ public static int mostLeftLevel(Node node, int level) { while (node != null) { level++; node = node.left; } return level - 1; } }
复杂度分析:求的过程中,每一层只遍历一个节点,一共有O(logN)层。当遍历到一个节点时,会遍历它右子树的左边界,这又是一个O(logN),所以这个算法的复杂度是O((logN)2)。
参考:https://blog.csdn.net/qq_27703417/article/details/70958692