概述
我们需要将数据从MYSQL写入到rocketmq。实现步骤如下:
安装canal.admin
修改配置
server:
port: 8849
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
一般我们修改端口,和数据库的链接用户即可。
初始化数据库
创建数据库
启动admin
输入地址
http://localhost:8849/
输入 admin/123456 登录

看到这个界面说明 canal.admin 部署成功了。
canalserver 配置
################################################# ######### common argument ############# ################################################# # tcp bind ip canal.ip = # register ip to zookeeper canal.register.ip = canal.port = 11111 canal.metrics.pull.port = 11112 # canal instance user/passwd # canal.user = canal # canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # 管理控制台配置 canal.admin.manager = 127.0.0.1:8849 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # admin auto register canal.admin.register.auto = true canal.admin.register.cluster = canal.admin.register.name = canal.zkServers = # flush data to zk canal.zookeeper.flush.period = 1000 canal.withoutNetty = false # tcp, kafka, rocketMQ, rabbitMQ
# 默认的tcp 修改成 rocketMq canal.serverMode = rocketMQ # flush meta cursor/parse position to file canal.file.data.dir = ${canal.conf.dir} canal.file.flush.period = 1000 ## memory store RingBuffer size, should be Math.pow(2,n) canal.instance.memory.buffer.size = 16384 ## memory store RingBuffer used memory unit size , default 1kb canal.instance.memory.buffer.memunit = 1024 ## meory store gets mode used MEMSIZE or ITEMSIZE canal.instance.memory.batch.mode = MEMSIZE canal.instance.memory.rawEntry = true ## detecing config canal.instance.detecting.enable = false #canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now() canal.instance.detecting.sql = select 1 canal.instance.detecting.interval.time = 3 canal.instance.detecting.retry.threshold = 3 canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery canal.instance.transaction.size = 1024 # mysql fallback connected to new master should fallback times canal.instance.fallbackIntervalInSeconds = 60 # network config canal.instance.network.receiveBufferSize = 16384 canal.instance.network.sendBufferSize = 16384 canal.instance.network.soTimeout = 30 # binlog filter config canal.instance.filter.druid.ddl = true canal.instance.filter.query.dcl = false canal.instance.filter.query.dml = false canal.instance.filter.query.ddl = false canal.instance.filter.table.error = false canal.instance.filter.rows = false canal.instance.filter.transaction.entry = false canal.instance.filter.dml.insert = false canal.instance.filter.dml.update = false canal.instance.filter.dml.delete = false # binlog format/image check canal.instance.binlog.format = ROW,STATEMENT,MIXED canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation canal.instance.get.ddl.isolation = false # parallel parser config canal.instance.parser.parallel = true ## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors() #canal.instance.parser.parallelThreadSize = 16 ## disruptor ringbuffer size, must be power of 2 canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info canal.instance.tsdb.enable = true canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:} canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; canal.instance.tsdb.dbUsername = canal canal.instance.tsdb.dbPassword = canal # dump snapshot interval, default 24 hour canal.instance.tsdb.snapshot.interval = 24 # purge snapshot expire , default 360 hour(15 days) canal.instance.tsdb.snapshot.expire = 360 ################################################# ######### destinations ############# ################################################# canal.destinations = example # conf root dir canal.conf.dir = ../conf # auto scan instance dir add/remove and start/stop instance canal.auto.scan = true canal.auto.scan.interval = 5 # set this value to 'true' means that when binlog pos not found, skip to latest. # WARN: pls keep 'false' in production env, or if you know what you want. canal.auto.reset.latest.pos.mode = false canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml #canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring canal.instance.global.lazy = false canal.instance.global.manager.address = ${canal.admin.manager} #canal.instance.global.spring.xml = classpath:spring/memory-instance.xml canal.instance.global.spring.xml = classpath:spring/file-instance.xml #canal.instance.global.spring.xml = classpath:spring/default-instance.xml ################################################## ######### MQ Properties ############# ################################################## # aliyun ak/sk , support rds/mq canal.aliyun.accessKey = canal.aliyun.secretKey = canal.aliyun.uid= canal.mq.flatMessage = true canal.mq.canalBatchSize = 50 canal.mq.canalGetTimeout = 100 # Set this value to "cloud", if you want open message trace feature in aliyun. canal.mq.accessChannel = local canal.mq.database.hash = true canal.mq.send.thread.size = 30 canal.mq.build.thread.size = 8 ################################################## ######### Kafka ############# ################################################## kafka.bootstrap.servers = 127.0.0.1:9092 kafka.acks = all kafka.compression.type = none kafka.batch.size = 16384 kafka.linger.ms = 1 kafka.max.request.size = 1048576 kafka.buffer.memory = 33554432 kafka.max.in.flight.requests.per.connection = 1 kafka.retries = 0 kafka.kerberos.enable = false kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf" kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf" ################################################## ######### RocketMQ ############# ################################################## rocketmq.producer.group = test rocketmq.enable.message.trace = false rocketmq.customized.trace.topic = rocketmq.namespace =
# 消息队列服务器配置 rocketmq.namesrv.addr = 127.0.0.1:9876 rocketmq.retry.times.when.send.failed = 0 rocketmq.vip.channel.enabled = false rocketmq.tag = ################################################## ######### RabbitMQ ############# ################################################## rabbitmq.host = rabbitmq.virtual.host = rabbitmq.exchange = rabbitmq.username = rabbitmq.password = rabbitmq.deliveryMode =
启动canal server.
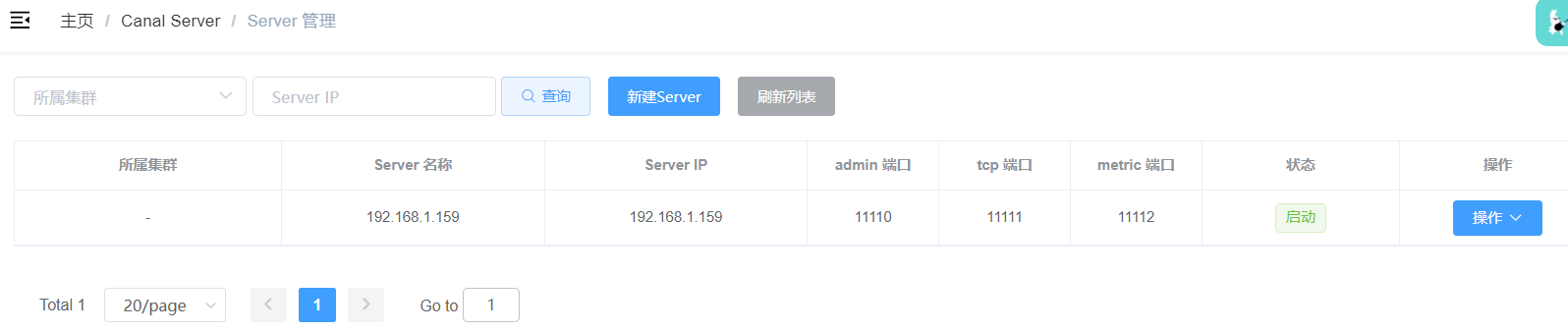
server 注册成功。
配置实例我们将数据同步到MQ
点击新实例按钮
比如我希望将 article 的表数据同步到 rocketmq中。
我们对配置做如下修改:
整个配置如下:
################################################# ## mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 # enable gtid use true/false canal.instance.gtidon=false # 数据库地址 canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # 用户名密码 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.defaultDatabaseName = cms_manage canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # 只选择文章表 canal.instance.filter.regex=.*\\.article # table black regex canal.instance.filter.black.regex= # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # 创建一个文章的队列 canal.mq.topic=article # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #################################################
配置完成后,尝试在 表 article对数据进行增加,修改删除。
可以通过对列管理器看到。

写消息到队列后,我们就可以读取队列做我们需要处理的任务了。