Beautiful Soup 是Python的一个HTML或者XML的解析库;会自动将输入的文档转化为Unicode编码,输出文档转换为UTF-8编码;
安装:
C:Usersissuser>pip install beautifulsoup4
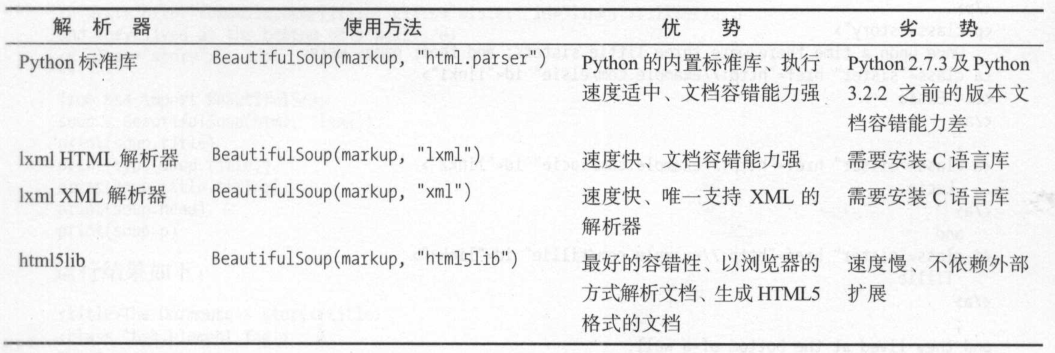
Beautiful Soup在解析时实际上依赖解析器,出了支持Python标准库的HTML解析器外,还支持某些第三方的解析器(lxml);
支持的第三方解析器为:
1 #Beautiful Soup使用 2 import requests 3 from lxml import html 4 from bs4 import BeautifulSoup 5 6 html=""" 7 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> 8 <html> 9 <head> 10 <title>第一个HTML页面</title> 11 <style type="text/css"> 12 body{ 13 margin:0px;padding:0px; 14 background:url('4.jpg') no-repeat fixed center; 15 background-color:#000; 16 } 17 div{ 18 border:solid 15px #fff; 19 border-style:groove; 20 500px; 21 height:500px; 22 color:#fff; 23 margin:0 auto;/*让该标签在父容器中居中,但是注意:必须在该HTML中引入头文件,才生效*/ 24 font-size:14px; 25 } 26 27 h2{ 28 text-align:center; 29 font-size:30px; 30 border:solid 1px blue; 31 } 32 p{ 33 line-height:24px; 34 text-indent:24px; 35 } 36 </style> 37 </head> 38 <body> 39 <div> 40 <h2 class="title">什么是青春</h2> 41 <p> 42 2010年大专毕业,各种原因,频繁换工作, 43 简历上能写的经验只有一年维护,女友看我这个现状分手,<image src="./abc.jpg" alt='图标ALT' title="图标Title"></image><span><label>[哈哈]</label></span> 44 去年打算考研,结果玩了一年,今年继续没工作考研,压力空前。 45 这三年,一步错步步错,没有坚定的方向,如今25岁才意识到, 46 人最可悲的就是不知自己想要什么喜欢什么想做什么,没女人没朋友没工作性格内向没背景 47 考研复习进度也很慢,可能是情绪关系一直看不进去,别人都第二轮了,我还刚开始, 48 每天失眠睡不着躲在被子里哭,也不知道该怎么办,每天连个说话的人也没有,商量的人也没, 49 抑郁的经常想去死打算九月份一个人去上海从零开始找程序员的工作,还要兼顾考研,读两三年毕业就29了 50 ,这时候怎么办,. 51 </p>
<p>我也不清楚!</p> 52 <!--margin:10px 40px;/*两个参数:第一个:上下,第二个:左右*/ 53 /*如果有四个参数值:顺序为上右下左*/--> 54 </div> 55 56 """ 57 #上面html没有完全结束,少</body></html> 58 #Beautiful Soup 解析 59 60 if __name__=="__main__": 61 soup=BeautifulSoup(html,'lxml')#初始化BeautifulSoup时则对html文本进行过了完整性修复 62 print(soup.prettify())#将要解析的字符串以标准的锁紧格式输出 63 print(soup.title.string)#获取title节点,通过string属性来获取文本内容 64 print(soup.title.string)#获取title节点,通过string属性来获取文本内容
65 print(soup.h2.string)
66 print(type(soup.h2))#<class 'bs4.element.Tag'> Tag类型,则可以通过string获取文本内容
节点选择器:即通过直接调用节点名称就可以选择该节点元素,string则可以获取节点中文本;
获取节点名称:
#获取节点名称 print(soup.h2.name)
获取节点属性:如果属性唯一,则获取返回结果为字符串;不唯一,则返回字符串组成的列表;
#获取节点属性 print(soup.h2.attrs['class'])
#获取所有属性 print(soup.h2.attrs)
或者更简洁方式:
#更简洁方式获取属性,则是省略attrs print(soup.h2['class'])
获取文本:如果有多个p标签存在;
#获取p的文本,注意:这里只能获取到第一个p标签的文本 print(soup.p.string)
嵌套选择:如果获取的节点结果类型依然是bs4.element.Tag类型,则同样可以继续调用节点进行下一步筛选;
例如,获取p标签中嵌套image,获取image的src属性则为:
#嵌套选择: print(soup.p.image['src'])
关联选择:有时候不能做到一步就选择到具体想要的节点, 需要选择某一个元素后,以它为基准再选择其他的子节点、父节点、兄弟节点等;
例如,获取p的所有子节点(包含标签前后文本内容,也会被拆分为节点),注意:contents只能获取到直接子节点,如果想获取孙子一下节点则需要再次继续层层获取:
#获取p节点的子节点,返回列表 print(soup.p.contents) print(soup.p.contents[1]['src'])
或者通过children属性获取子节点列表:
#也可以通过children获取所有子节点 print(soup.p.children) for i,j in enumerate(soup.p.children): print(i) print(j)
获取子孙节点,则可以通过 descendants属性获取:
#获取子孙节点列表 print(soup.p.descendants) for i, j in enumerate(soup.p.descendants): print(i) print(j)
获取直接父节点和祖先节点:通过parent和 parents(一直到最外层节点结束)实现;
#parent获取某个元素直接父节点(第一个) print(soup.span.parent) #parents获取所有p节点父节点,以及父节点层层祖先节点 print(soup.span.parents) for i ,j in enumerate(soup.span.parents): print(i) print(j)
获取兄弟节点:next_sibling和previous_sibling分别获取节点的下一个和上一个兄弟节点,next_siblings 和previous_siblings则分别返回所有前面和后面的兄弟节点的生成器;
#获取兄弟节点 print(soup.image.next_sibling)#后一个兄弟节点 print(soup.image.next_siblings)#获取image的所有后续兄弟节点 for i,j in enumerate(soup.image.next_siblings): print(i) print(j)
print(list(soup.span.parents)[0])
方法选择器:
1)find_all()查询所有符合条件的元素;除此之外还有find(),find_parents(),find_parent(),find_previous()等方法,下面略;
1 #find_all() 2 print(soup.find_all(name='span'))#返回列表,所有span元素 3 print(soup.find(name='span'))#返回查找的第一个元素 4 print(soup.find_all(name='image',attrs={'alt':'图标ALT2'}))#返回列表 5 6 for tag in soup.find_all(name='p'): 7 print(tag.find_all(name='image'))
for tag in soup.find_all(name='p'):
print(tag.find_all(name='image'))
外层for循环获取的tag类型为<class 'bs4.element.Tag'>,因此可以根据该字段,继续使用find_all方法继续查找;
根据id和class属性查找:
print(soup.find_all(id ='list-1')) print(soup.find_all(class _='element'))
2)Css选择器:select()方法筛选,参数传入css样式即可;
#css选择器:使用select方法 print(soup.select(".img")) print(soup.select("div p image")) print(type(soup.select('span')[1]))
注:#获取p的文本,注意:这里只能获取到第一个p标签的文本
print(soup.p.string)#
#两者等同
print(soup.p.get_text())
========================================================================================================================================================================
(上面写笔记过程中代码改了好多)完成代码如下:
1 #Beautiful Soup使用 2 import requests 3 from lxml import html 4 from bs4 import BeautifulSoup 5 6 html=""" 7 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> 8 <html> 9 <head> 10 <title>第一个HTML页面</title> 11 <style type="text/css"> 12 body{ 13 margin:0px;padding:0px; 14 background:url('4.jpg') no-repeat fixed center; 15 background-color:#000; 16 } 17 div{ 18 border:solid 15px #fff; 19 border-style:groove; 20 500px; 21 height:500px; 22 color:#fff; 23 margin:0 auto;/*让该标签在父容器中居中,但是注意:必须在该HTML中引入头文件,才生效*/ 24 font-size:14px; 25 } 26 27 h2{ 28 text-align:center; 29 font-size:30px; 30 border:solid 1px blue; 31 } 32 p{ 33 line-height:24px; 34 text-indent:24px; 35 } 36 .img{120px;height:200px;} 37 </style> 38 </head> 39 <body> 40 <div> 41 <h2 class="title">什么是青春</h2> 42 <p> 43 2010年大专毕业,各种原因,频繁换工作, 44 简历上能写的经验只有一年维护,女友看我这个现状分手,<image src="./abc.jpg" alt='图标ALT' title="图标Title"></image><span>qq<label>[哈哈]</label>qq </span> 45 去年打算考研,结果玩了一年,今年继续没工作考研,压力空前。 46 这三年,一步错步步错,没有坚定的方向,如今25岁才意识到,<span>第二个span</span> 47 人最可悲的就是不知自己想要什么喜欢什么想做什么,没女人没朋友没工作性格内向没背景 48 考研复习进度也很慢,可能是情绪关系一直看不进去,别人都第二轮了,我还刚开始, 49 每天失眠睡不着躲在被子里哭,<image class="img" src="./abc.jpg" alt='图标ALT2' title="图标Title"></image>也不知道该怎么办,每天连个说话的人也没有,商量的人也没, 50 抑郁的经常想去死打算九月份一个人去上海从零开始找程序员的工作,还要兼顾考研,读两三年毕业就29了 51 ,这时候怎么办,. 52 </p> 53 <p> 54 我也不知道怎么办呢! 55 </p> 56 <!--margin:10px 40px;/*两个参数:第一个:上下,第二个:左右*/ 57 /*如果有四个参数值:顺序为上右下左*/--> 58 </div> 59 60 """ 61 #上面html没有完全结束,少</body></html> 62 #Beautiful Soup 解析 63 64 if __name__=="__main__": 65 soup=BeautifulSoup(html,'lxml')#初始化BeautifulSoup时则对html文本进行过了完整性修复 66 print(soup.prettify())#将要解析的字符串以标准的锁紧格式输出 67 print(soup.title.string)#获取title节点,通过string属性来获取文本内容 68 print(soup.h2.string) 69 print(type(soup.h2))#<class 'bs4.element.Tag'> Tag类型,则可以通过string获取文本内容 70 #获取节点名称 71 print(soup.h2.name) 72 #获取节点属性 73 print(soup.h2.attrs['class']) 74 #获取所有属性 75 print(soup.h2.attrs) 76 #更简洁方式获取属性,则是省略attrs 77 print(soup.h2['class']) 78 #获取p的文本,注意:这里只能获取到第一个p标签的文本 79 print(soup.p.string)#print(soup.p.get_text()) 两者等同 80 81 #嵌套选择: 82 print(soup.p.image['src']) 83 #获取p节点的子节点,返回列表 84 print(soup.p.contents) 85 print(soup.p.contents[1]['src']) 86 #也可以通过children获取所有子节点 87 print(soup.p.children) 88 for i,j in enumerate(soup.p.children): 89 print(i) 90 print(j) 91 #获取子孙节点列表 92 print(soup.p.descendants) 93 for i, j in enumerate(soup.p.descendants): 94 print(i) 95 print(j) 96 97 #parent获取某个元素直接父节点(第一个) 98 print(soup.span.parent) 99 #parents获取所有p节点父节点,以及父节点层层祖先节点 100 print(soup.span.parents) 101 for i ,j in enumerate(soup.span.parents): 102 print(i) 103 print(j) 104 print("-----------------------------------------------------") 105 #获取兄弟节点 106 print(soup.image.next_sibling)#后一个兄弟节点 107 print(soup.image.next_siblings)#获取image的所有后续兄弟节点 108 for i,j in enumerate(soup.image.next_siblings): 109 print(i) 110 print(j) 111 print(list(soup.span.parents)[0]) 112 113 #find_all() 114 print(soup.find_all(name='span'))#返回列表,所有span元素 115 print(soup.find(name='span'))#返回查找的第一个元素 116 print(soup.find_all(name='image',attrs={'alt':'图标ALT2'}))#返回列表 117 118 for tag in soup.find_all(name='p'): 119 print(type(tag)) 120 121 print("-------------------------------------------------------") 122 #css选择器:使用select方法 123 print(soup.select(".img")) 124 print(soup.select("div p image")) 125 print(type(soup.select('span')[1]))