根据Survey of Data-Selection Methods in Statistical Machine Translation的总结,MT中的数据选择分类图如下:
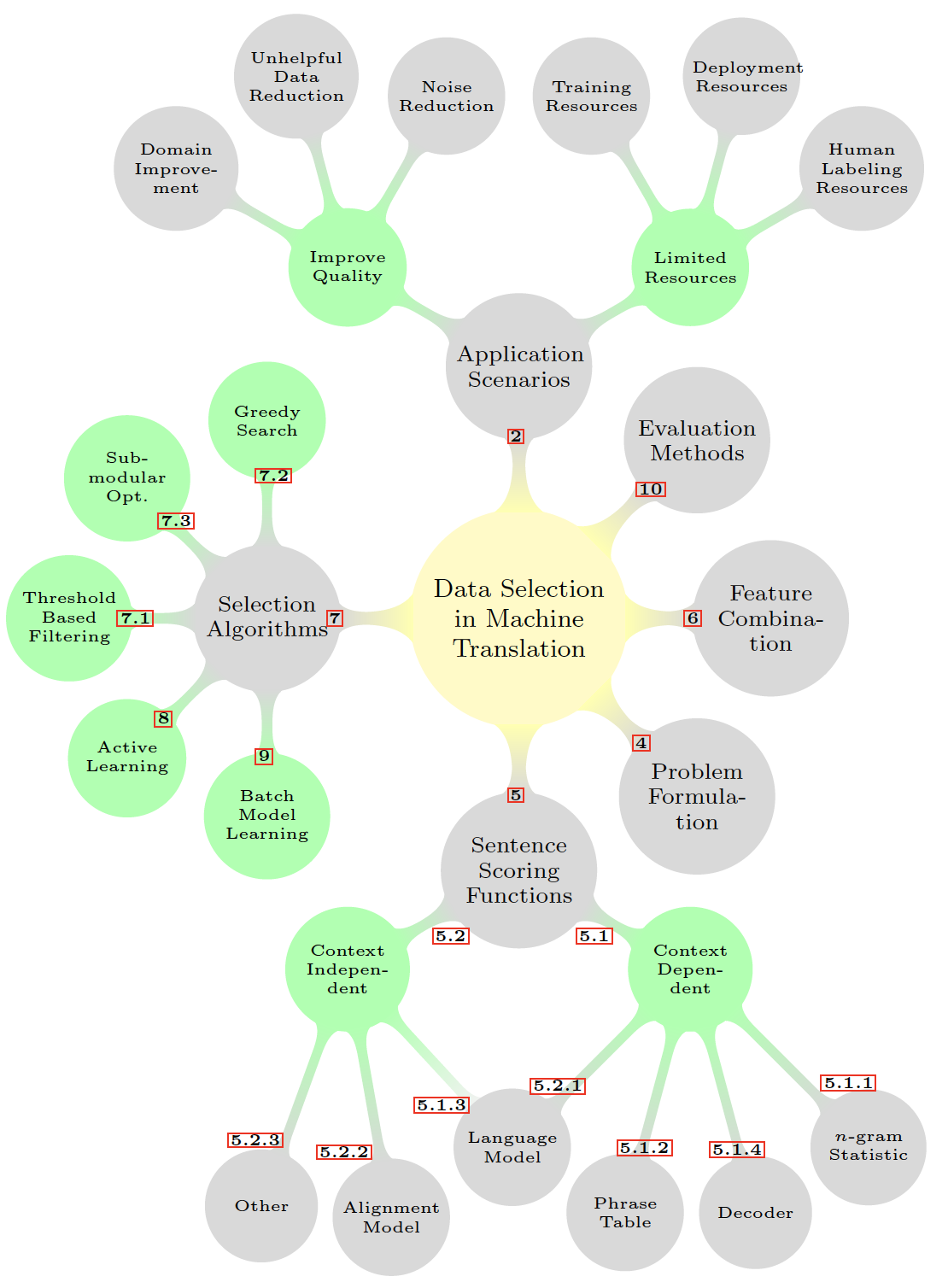
使用场景 数据使用的场景决定了选择什么样的数据,及该方法要解决什么问题。
- Improve Quality:Domain Improvement、Unhelpful Data Reduction、Noise Reduction
- Limited Resources:Training Resources、Deployment Resources、Human Labeling Resources
评估方法
特征结合
问题定义
句子打分函数
- 上下文无关(depend on nothing but the candidate sentences in question):语言模型、对齐模型、其他
- 依赖上下文(depend on the selected pool):语言模型、短语表、解码器、n元统计信息
选择算法
- 依据阈值过滤
- 贪心搜索
- 子模块最优化
- 主动学习
- Batch Model Learning
下面是一些经典的论文的总结,供个人学习用,写的不当的地方请轻喷~
Dynamic Data Selection for Neural Machine Translation 2017
静态数据选择
最初源自Moore-Lewis 2010的数据选择方法——交叉熵之差CED:用in domaingeneral domain 源端语料分别训练语言模型,再计算候选句子的in domain和general domain交叉熵之差,越低表示离in domain越近离general越远。(其中的语言模型可以是n gram语言模型或者LSTM等等)
上面方法的source、target双语变种 Axelrod 2011:源端的CED+目标端的CED
![]() ,G、I代表外领域和内领域。f、e代表源端和目标端。
,G、I代表外领域和内领域。f、e代表源端和目标端。
文章中用的双语的变种,语言模型是LSTM
动态数据选择
sampling
- 按照上述静态数据选择的方法给训练集中的句子对打分,排序;
- 把上述CED分数标准化到0-1之间,生成新的分数CED‘,离in domain越近的,CED‘分数越高(1 - 最大最小标准化);
- 再把每个句子的CED‘的分数归一化为权重;
- 每个epoch按照权重采样,不重复采样,分数高的句子会被多次采样
gradual fine-tuning
依照fine tune的灵感,先在general 数据集G上训,再在in domain数据上微调:本文逐步减小训练集G的大小,比如每两个epoch换一次数据,选的数据是上一轮分数排名靠前的60%——1、2个epoch在整个G上训练;3、4个epoch选择在G中静态数据分数排名靠前的60%,总量是0.6*|G|;第5、6个epoch选择3、4个epoch中静态数据分数排名靠前的60%,总量是0.6*0.6*|G|。。。
结果是语言模型LSTM 好于n gram、gradual fine-tuning好于sampling
Boost neural machine translation 2017
翻译PPL高的句子结构复杂,更难翻译,NMT应该花时间关注更难的句子。句子按翻译的ppl排序。
实验策略:
- boost——在original基础上加入10%高ppl的句子;
- reduce——去掉20%低ppl排名的句子,即保留80%高ppl的翻译句子。依次保留整个训练集中高ppl的100%-80%-64%-100%-80%-64%-100%-...。(此方法结果最好)
- bootstrap——random resampling 100%,从original中再次sampling,所以有些低ppl的或者高的会消失/重复出现
Dynamic Sentence Sampling for Efficient Training of Neural Machine Translation 2018
zhang 17(即上篇)的文章用sentence-level training cost作为衡量句子翻译质量的手段,训练损失越小代表模型把句子学的好,缺点有两个:训练损失小的句子继续训练可能还可以提升;如果训练数据不断变小,但是这些被移除句子中包含的知识可能在NMT的训练过程中逐渐被丢弃掉。
这篇文章用句子两次迭代的训练损失之差(the differences between the training costs of two iterations)作为句子翻译质量能否被提升的衡量标准。越小表示这句话的损失不太可能变化,所以这句话继续训练对NMT没有帮助:
(上一次的训练损失 - 该次训练损失)/ 上一次的训练损失 = 该次的dif
dif(差异度)可能是正值,也可能是负值。所以要最大最小归一化到【0,1】之间 = criterion
实验方法:
- weighted sampling WS——上述criterion值转换为归一化的概率分布,按照权重子采样整个训练集的80%(不重复采样)作为下一iteration的训练集,训练目标函数也会更新为在选的的子训练集上。一个句子可能在一个子采样的过程中没有被选择,但是在下一个子采样的过程中,由于被选择句子的criterion都发生了变化,未被选择的句子的criterion不变,因此weight也会发生变化,所以该句子仍有可能被选择到。
- review mechanisim RM——选择的80% top-ranked数据组成了
,未被选择的20%数据组成了
,
,比如为10%,则表示采样
中10%的数据进行复习。损失函数中会由
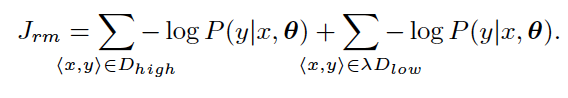 (该方法效果更好)
(该方法效果更好)
在极大数据集的训练中还提到可以采用小部分已经训练的和未训练过的句子相似度作为采样句子的一个标准。
Feature Decay Algorithms for Neural Machine Translation 2018
是一种transductive data selection method ,最初用在SMT中有很好的效果,现在把它用在NMT中。
FDA:用test set的源端来选择句子,让选择的样本能与该set最相关。一旦n gram被选上,就减小它们的值,FDA通过这样来最大化所选择训练集中relevant n-grams的方差。具体方法要看下面。
方法:
- 首先从test集抽取n-grams作为特征,这些特征有初始值,该值表明被选择的相关性;每个候选句也有总得分。
- 迭代的选择分数高的句子加入set L,选择一句话后,计算set L中已选择的数据的某个特征出现的次数,该特征的分值会随出现的次数增加而衰减。这样使得下一次选择之前没被选择的特征。
特征分值衰减公式:
![]() ,L is the set of selected sentences,CL(f) is the count of the feature f in L
,L is the set of selected sentences,CL(f) is the count of the feature f in L
句子得分的计算:sentences are scored as the normalized sum of values of contained features.
 ,Fs是句子s中的特征集
,Fs是句子s中的特征集
文章中的是3元特征,还用了第一篇文章中gradual fine-tuning的设置,训练集测试集都是WMT2015的实验结果中,在用FDA选择少量数据(100k 200k)时,先训练base model、到最后一轮再用FDA选择的数据微调比较好;当FDA选择的数据到500k时,只用FDA选择的数据从头训NMT模型效果更高。
Adaptation of Machine Translation Models with Back-translated Data using Transductive Data Selection Methods 2019
上篇的同一作者
Transductive Algorithm(TA)是利用test集的信息获取句子:
- Infrequent n-gram Recovery(INR)-选择包含不频繁n-gram的句子
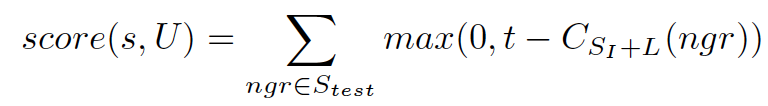
t是阈值:超过代表该n-gram频繁,小于代表ngr不频繁。
如果选择池中的ngr超过阈值t,则对句子分数没贡献=0
- FDA
(前面有提到)
原本是用test集(源端)作为种子,现在用通用NMT模型把test翻译为目标端,也作为种子,对源端和目标端种子都用TA方法选择数据,把两者选的数据combine
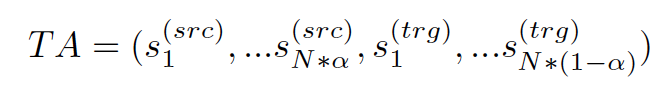
a和1-a,分别代表从TAsrcTAtrg中选的数据比例
方法比较见下图:
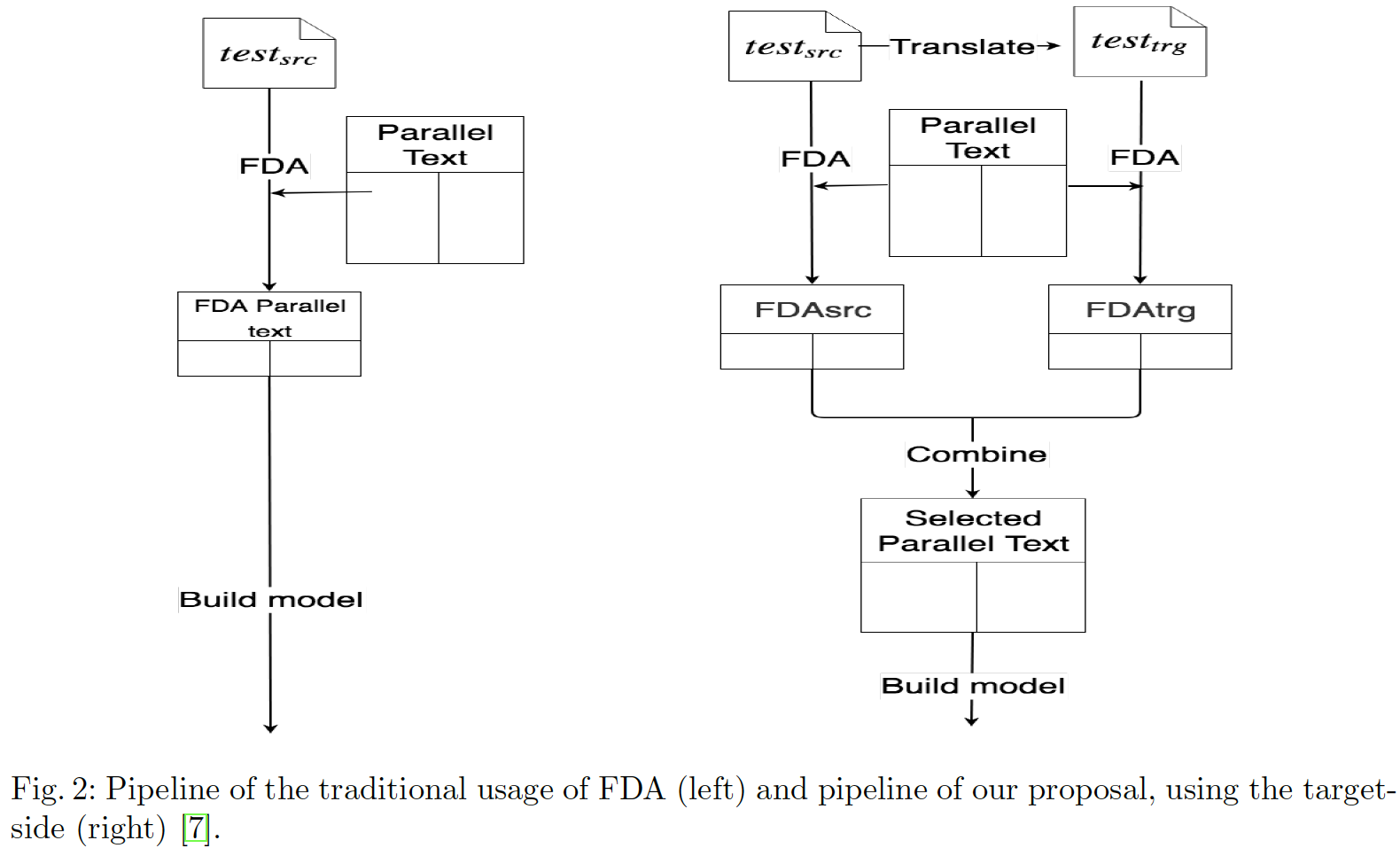
TA还包括TF-IDF距离:

词频逆文档频率
稀有词比常见词对句子相似度的指示性更强
下面两篇论文均有利用该指标
Extracting In-domain Training Corpora for Neural Machine Translation Using Data Selection Methods 2018
Dynamic Data Selection and Weighting for Iterative Back-Translation 2020
tf是term在文档中出现的频率;df是多少个文档中包含term(idf is the inverse document frequency),N是文档数
该文中(we apply tokenization, remove punctuation and common stopwords in the texts, and finally truecase the sentences)把数据集中的每个句子当文档,词当作term。
计算词(term)对句子(文档)的tf-idf值,把句子中所有词的tf-idf向量平均作为整个句子的词向量表示,再计算in和general中句子词向量的cosine相似度,按cos相似度给general domain的句子排序,相似度越大离in domain越近。

Dynamic Data Selection and Weighting for Iterative Back-Translation 2020
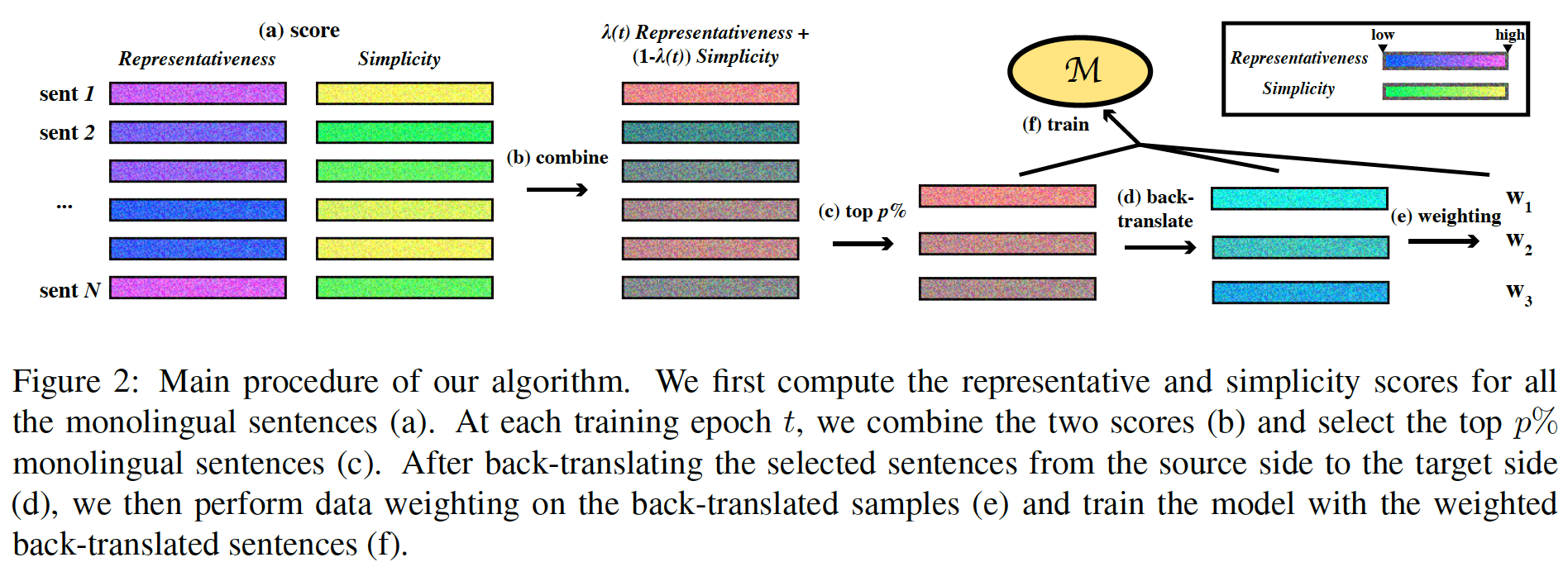
相对于静态选择数据,对迭代反向翻译,提出一个新的课程学习策略。
该论文中提到句子由代表性和简单性两种指标进行评分,注意评分都分别最大最小归一化到[0,1]
- 代表性指标:
In-Domain Language Model Cross-Entropy(LM-in)、TF-IDF Scores (TF-IDF)、BERT Representation Similarities (BERT).
- 简单性指标:
General-Domain Language Model Cross-Entropy (LM-gen)、Round-Trip BLEU (R-BLEU)
说一下BERT Representation Similarities (BERT).
把句子送入multilingual bert,把除了[CLS] [SEP] 之外输入tokens在第8层的隐藏状态平均,得到句子的表示,根据句子表示可以计算单语中某个句子和in domain所有句子的cosine相似度。
两种评分标准由一个参数lambda控制,该参数的来源是19的一篇CL的论文,代表了模型能力随epoch的变化曲线(按sqrt增加)。最初选的数据是简单性为主,随时间推移后期是选代表性的句子。
选择出的伪句子还会赋有权重,让翻译质量低的句子权重更小。提出两种当前质量估计方法:一种是计算伪平行句对分别用两个方向NMT模型的encoder的最后一层表示、再平均,算cosine相似度;另一种是计算伪平行句对在两个方向模型中的翻译概率、再计算条件概率之差绝对值、取负指数,值越大,句子质量越差。
还有计算句子质量进步的指标,该指标与当前质量结合了:![]()
———————— EMBEDDING-BASED METRICS ————————
Improving Neural Machine Translation by Filtering Synthetic Parallel Data 2019
学习一个线性映射,把两种语言词向量映射到同一词向量空间,通过双语词向量分别得到句子词向量(词向量累加再平均),计算双语句子向量的cosine相似度,设定阈值,去掉小于threshold的句子。
1.在维基百科语料上用fastext训练韩语、英语词向量;
2.选排名靠前的4500个常用英语单词创建英语词表(不含功能词和停用词)
3.会用双语的人把英语词表翻译为韩语;
4.利用已有双语的词向量X,Z和双语词典,用现有的方法学习线性映射W。
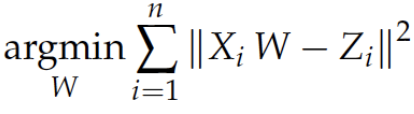
———————— Uncertainty ————————
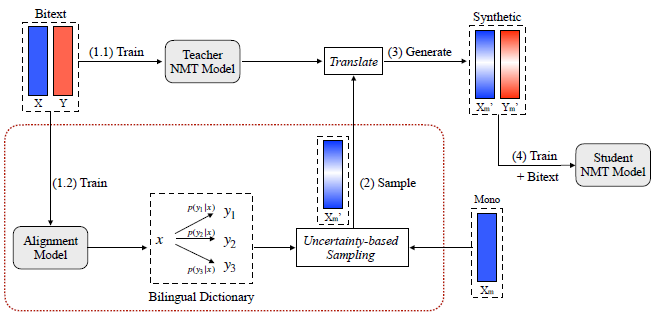
Self-training Sampling with Monolingual Data Uncertainty for Neural Machine Translation 2021
(私心:与我们的idea很类似)
单语数据量很大,应该要选择最有信息量的单语句子来补充平行语料。
文章提出一种对单语基于不确定性的采样方法,能够有效的在self-training中使用单语句子,让不确定性大的句子会有更高概率被采样。利用从平行语料中生成的双语词典计算句子的不确定性。无标注数据中的简单pattern预测的确定性高,不能提供额外收益,即不确定性低的句子简单,好翻译。文中用难pattern的句子来提升self-training的性能。结果也表明 除了不确定性特别高的句子之外,其他稍高一点不确定性的句子能提升NMT质量,那些不确定性极端的句子翻译的输出比较差,阻碍了NMT的训练。
self-training:用”老师模型“(文中用的transformer big)翻译源端单语到目标端,把生成的伪平行数据与真实语料结合,一起训练"学生"(transformer base)模型。self-training简化了生成的目标端句子的复杂性。
单语不确定性
数据不确定性:
给定源语料x,Y是所有可能的候选翻译。不确定性是所有候选句条件熵的和。
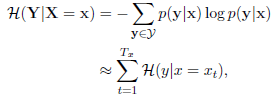
因为上述公式的计算需要互为翻译的句对,不适应单语的情况。
单语不确定性:
修改上述公式, 给定单语句子xj, Tx用来normalize防止长度bias。文章是基于双语词典计算单语句子的不确定性。src端单语中每个词的熵(用双语词典翻译的所有可能的tgt的条件熵)的和 / src端句长
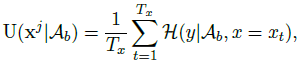
H(y|Ab, x=xt) 是词级别的熵 捕捉每个源词的翻译模态,双语词典Ab(能通过词对齐工具获得)—— 记录给定源词:所有可能的目标词,以及相应的翻译概率。H(y|Ab, x=xt) 计算的例子:
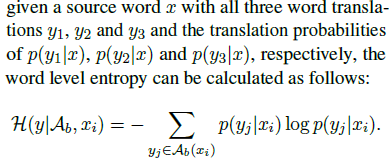
Ab:通过fast-aligh使用真实双语进行词对齐,使用对其来构建双语词典。
给单语句子打分之后按不确定性排序,分为大小相等的5桶(每桶8M),分别在每桶上进行ST得到下图。
分析5桶的数据的语言特性,包括句长、词的 rarity、翻译coverage(衡量src tgt词 对齐的比率)。下图证明bin 1确实简单,bin 5最难翻译。

具体的采样中会惩罚不确定性特别高的句子,因为语料中这种难度高的句子比较少,模型也很难训练好,“老师”模型也很难翻译。
(阈值Umax:平行语料中的R%单语要低于该阈值,R通常是80~100):
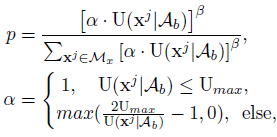 ,beta越大,给不确定性高的句子采样概率越大。文章进行了R,beta的实验,然后确定R=90, beta=2时效果稍好。
,beta越大,给不确定性高的句子采样概率越大。文章进行了R,beta的实验,然后确定R=90, beta=2时效果稍好。
整体流程
个人认为总体上就是用基于双语词典生成伪数据(word),基于src 和 伪tgt计算单语句的不确定性,基于计算的权重采样部分单语来给老师模型翻译生成伪数据,再与真实的双语合并进行训练。
实验
在受限 / 非受限大资源的场景下:
对比了随机采样,发现提出的方法确实有提升,此外还在ST生成伪数据之后利用tgt端的n-gram语言模型筛掉了20%的数据,能再带来0.2BLEU提升。