忙了一上午学这个Selenium
考虑到我有备份博客园博客的需求,所以实战是仿着写了下面的代码,功能是Selenium爬取某用户博客园首页的全部博客
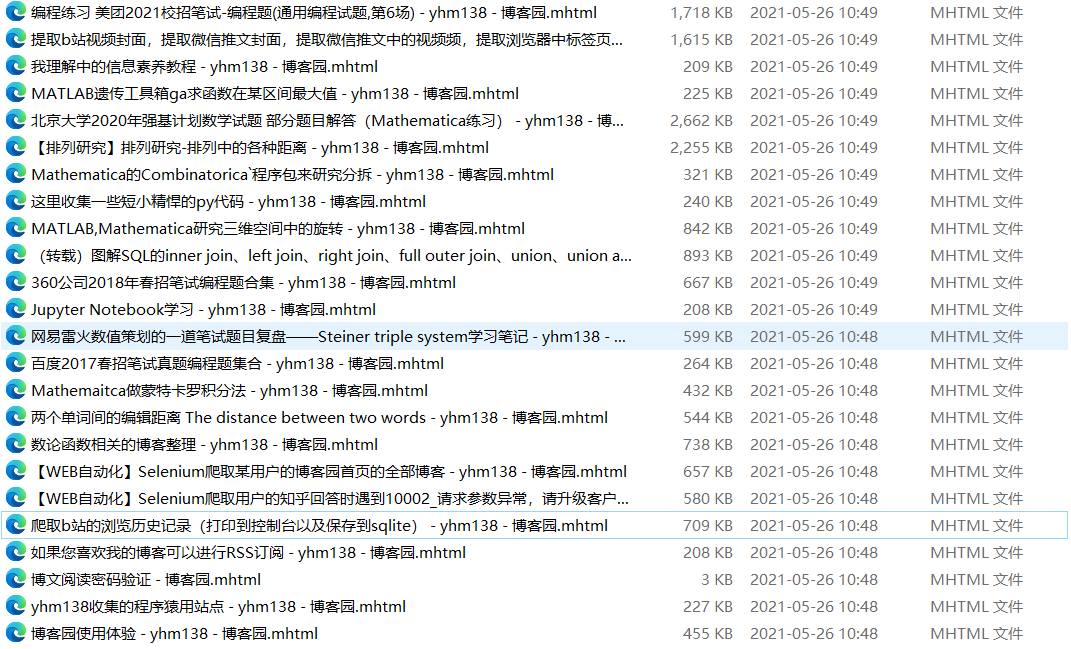
第一版只是把文章url和标题爬取了下来,博客网页另存为mhtml格式到本地
有时间会继续更新
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
import requests
from selenium.webdriver.common.keys import Keys
import win32api
import win32con
def load_photo(url, name):
'''给定图片链接,将图片以某个名称下载到本地'''
# url = 'http://img14.360buyimg.com/n1/s450x450_jfs/t1/148801/37/12770/118749/5f9d71e4E39f1e893/533675187c108953.jpg'
reponse = requests.get(url)
# name = 'd:/photo.jpg'
with open(name, 'wb') as ft:
ft.write(reponse.content)
def drop_scroll(browser):
'''将滑条从头滚动到底,以便让浏览器充分加载'''
for x in range(1, 11, 2):
# time.sleep(0.5)
j = x/10
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
browser.execute_script(js)
def switch_window(browser):
'''将browser的指令移到新打开的小窗口处'''
# time.sleep(0.5) # 如果移转失败,请增大这个时间
windows = browser.window_handles
browser.switch_to.window(windows[-1])
def switch_window_back(browser):
'''将browser的指令移回旧的小窗口'''
windows = browser.window_handles
browser.switch_to.window(windows[0])
def save_mhtml(DuringTime):
win32api.keybd_event(17, 0, 0, 0) # 按下ctrl
win32api.keybd_event(65, 0, 0, 0) # 按下a
win32api.keybd_event(65, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放a
win32api.keybd_event(83, 0, 0, 0) # 按下s
win32api.keybd_event(83, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放s
win32api.keybd_event(17, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放ctrl
time.sleep(1) #缓冲1s
win32api.keybd_event(13, 0, 0, 0) # 按下enter
win32api.keybd_event(13, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放enter
win32api.keybd_event(13, 0, 0, 0) # 按下enter
win32api.keybd_event(13, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放enter
win32api.keybd_event(27, 0, 0, 0) # 按下Esc
time.sleep(0.5) # 缓冲1s
win32api.keybd_event(27, 0, win32con.KEYEVENTF_KEYUP, 0) # 释放Esc
time.sleep(DuringTime)
# 构造网址
u_id= input('请输入您想查询的博客园用户用户名')
url = f'https://cnblogs.com/{u_id}'
page = int(input("要遍历的页数(从第一页开始)"))
# 打开博客园
options = webdriver.ChromeOptions()
options.add_argument('--save-page-as-mhtml')
browser = webdriver.Chrome(options=options)# 打开另存为mhtml功能
# browser.set_window_size(900, 500) # 设置窗口大小
# browser.set_window_position(300, 200) # 设置浏览器的位置
browser.get(url) #到达主页
#time.sleep(10)
# 遍历页面中每篇博客
count = 1 # 博客的编号
blog_urls=[]
for page_id in range(1,page+1):
# 翻页
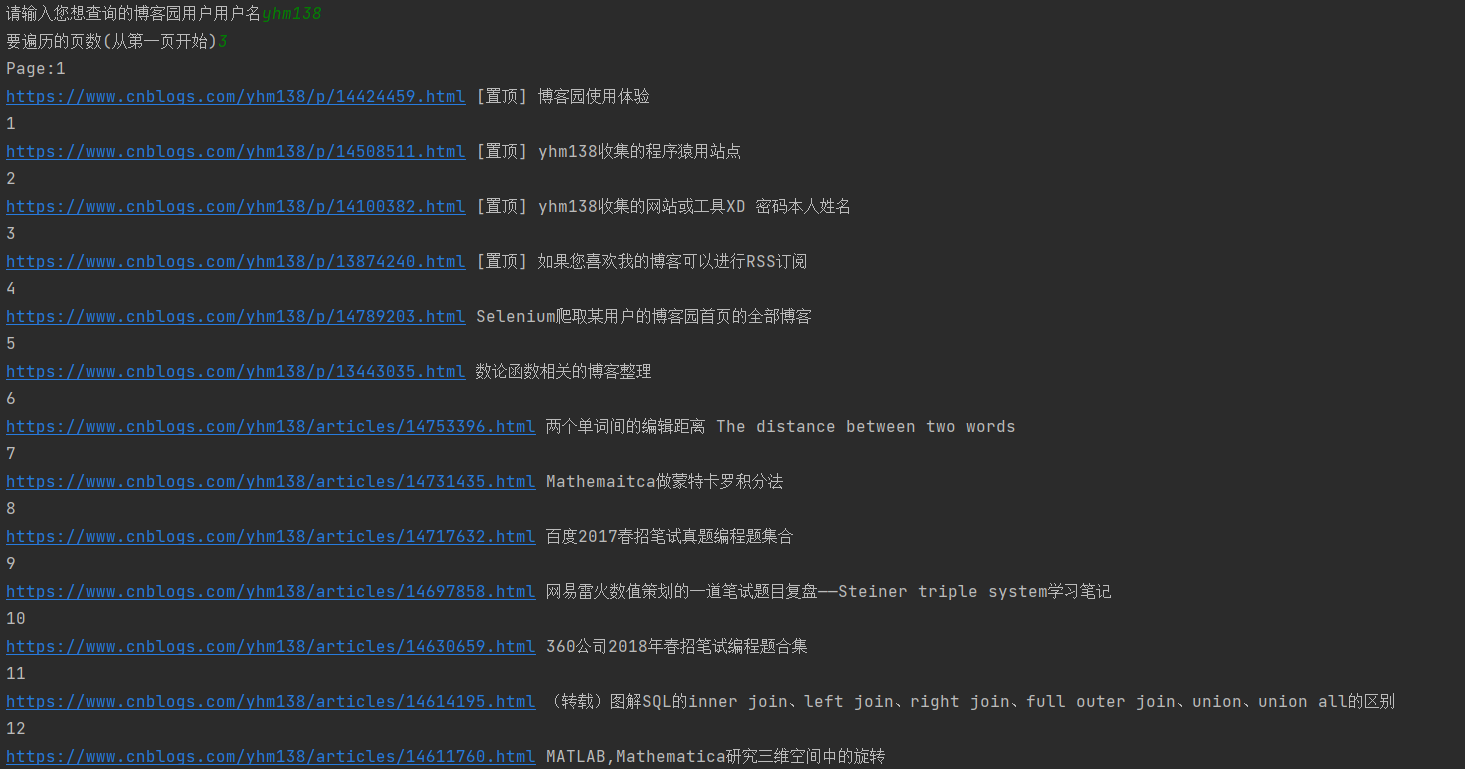
print("Page:%d" %page_id)
url = f'https://www.cnblogs.com/{u_id}/default.html?page={page_id}'
browser.get(url)
switch_window_back(browser) # 将browser的指令移回到新标签页
drop_scroll(browser) # 拖到底,让页面加载完全
blogs = browser.find_elements_by_xpath("//div[@class='postTitle']") # 获取所有博客
for blog in blogs:
btn = blog.find_element_by_xpath(".//a[@class='postTitle2 vertical-middle']")
blog_urls.append(btn.get_attribute('href'))
print(btn.get_attribute('href'),btn.find_element_by_xpath("./span").text,sep=' ')
print(count)
count = count + 1
# 如果不需要下面的部分可以删了
for blog_url in blog_urls:
browser.get(blog_url)
save_mhtml(DuringTime=2)
效果演示
使用方法
下载和你chrome浏览器版本号适配的chromedriver.exe,把路径放进$PATH
pip install selenium安装selenium模块
运行.py文件
由于涉及到了win32api下的按键控制,建议保持chrome窗口在最前方
参考
Selenium WebDriver-网页的前进、后退、刷新、最大化、获取窗口位置、设置窗口大小、获取页面title、获取网页源码、获取Url等基本操作
selenium---获取元素属性值
【爬虫入门】selenium爬取动态网页,以及常见的问题
利用selenium保存静态网页