Zookeeper教程文档:https://www.w3cschool.cn/zookeeper/
Zookeeper是什么?
Zookeeper是大数据生态圈中的重要组件,如果你做过相关开发的话,应该经常能看到它的身影。其由雅虎开源并成为Apache的顶级项目。用一句话对其进行定义就是:它是一套高吞吐的分布式协调系统。从中我们可以知道Zookeeper至少具有以下特点:
- 1.Zookeeper的主要作用是为分布式系统提供协调服务,包括但不限于:分布式锁,统一命名服务,配置管理,负载均衡,主控服务器选举以及主从切换等。
- 2.Zookeeper自身通常也以分布式形式存在。一个Zookeeper服务通常由多台服务器节点构成,只要其中超过一半的节点存活,Zookeeper即可正常对外提供服务,所以Zookeeper也暗含高可用的特性。客户端可以通过TCP协议连接至任意一个服务端节点请求Zookeeper集群提供服务,而集群内部如何通信以及如何保持分布式数据一致性等细节对客户端透明。如下图所示
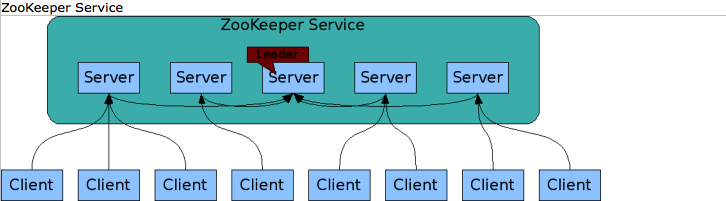
- 3.Zookeeper是以高吞吐量为目标进行设计的,故而在读多写少的场合有非常好的性能表现。如下图所示
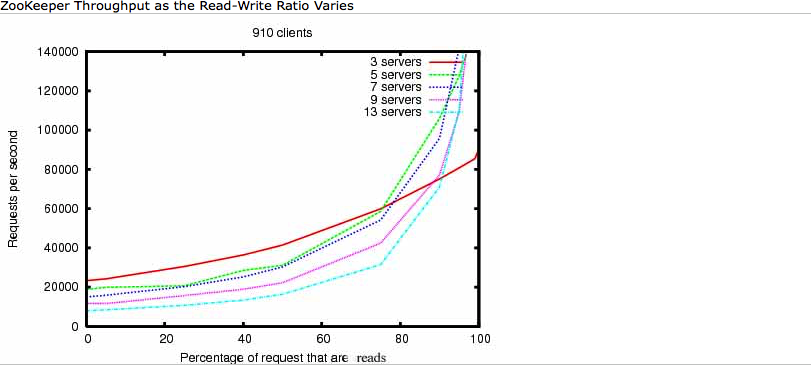
纵轴为每秒响应的客户端请求数,横轴为读请求所占百分比。从图中可以清晰的看到,随着读请求所占百分比的提高,Zookeeper的QPS也不断提高。
Zookeeper具有高吞吐特性的主要原因有以下几点:
1.Zookeeper集群的任意一个服务端节点都可以直接响应客户端的读请求(写请求会不一样些,下面会详谈),并且可以通过增加节点进行横向扩展。这是其吞吐量高的主要原因
2.Zookeeper将全量数据存储于内存中,从内存中读取数据不需要进行磁盘IO,速度要快得多。
3.Zookeeper放松了对分布式数据的强一致性要求,即不保证数据实时一致,允许分布式数据经过一个时间窗口达到最终一致,这也在一定程度上提高了其吞吐量。
而写请求,或者说事务请求,因为要进行不同服务器结点间状态的同步,一定程度上会影响其吞吐量。故而简单的增加Zookeeper的服务器节点数量,对其吞吐量的提升并不一定能起到正面效果。服务器节点增加,有利于提升读请求的吞吐量,但会延长服务器节点数据的同步时间,必须视具体情况在这两者之间取得一个平衡。
Zookeeper作为Hadoop和Hbase的重要组件,可以为分布式应用程序协调服务,同时还能使用Java和C的接口
https://www.cnblogs.com/takumicx/p/9508706.html【相关博客】
Zookeeper有什么作用?
一,命名服务(用到了zookeeper的文件系统)
命名服务是指通过指定的名字来获取资源或者服务的地址,利用zk创建一个全局的路径,提供服务的地址或者一个远程的对象等等。(Dubbo就是用zookeeper作为服务注册中心的)
二,配置管理(用到了zookeeper的文件系统,通知机制)
程序分布式的部署在不同的机器上,将程序的配置信息放在zk的znode下,当有配置发生改变时,也就是znode发生变化时,可以通过改变zk中某个目录节点的内容,利用watcher通知给各个客户端,从而更改配置。
三,集群管理(用到了zookeeper的文件系统,通知机制)——帮助其他软件搭建集群
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,集群就知道某个节点挂掉了
新机器加入也是类似,会在该父目录下创建一个临时子节点,然后所有机器收到通知:新兄弟目录加入
对于第二点,所有机器在zookeeper中都创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
四,分布式锁(用到了zookeeper的文件系统,通知机制)
有了zookeeper的全局一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于独占锁,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于控制时序锁, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次执行。
---------------------
作者:老子天下最美
来源:CSDN
原文:https://blog.csdn.net/sunshine_2211468152/article/details/83051148
版权声明:本文为博主原创文章,转载请附上博文链接!
Zookeeper应用于什么场景?
- 分布式协调
- 分布式锁
- 元数据/配置信息管理
- HA高可用性
分布式协调
这个其实是 zk 很经典的一个用法,简单来说,就好比,你 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zk 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zk 上对某个节点的值注册个监听器,一旦 B 系统处理完了就修改 zk 那个节点的值,A 立马就可以收到通知,完美解决。

分布式锁
举个栗子。对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就可以使用 zk 分布式锁,一个机器接收到了请求之后先获取 zk 上的一把分布式锁,就是可以去创建一个 znode,接着执行操作;然后另外一个机器也尝试去创建那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。

元数据/配置信息管理
zk 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zk 来做一些元数据、配置信息的管理,包括 dubbo 注册中心不也支持 zk 么?

HA高可用性
这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zk 来开发 HA 高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过 zk 感知到切换到备用进程。

作者:kevin0016
链接:https://www.jianshu.com/p/baf966931c32
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。