事实确实如此 - 过去很多人都在谈论SR-IOV和DPDK,即使在我们自己的博客上也是如此。我认为这是一个挑战:有机会以稍微不同的方式讲述数据平面加速的故事。当然,我们的审查编辑也认为这是一个挑战,因为她正在浏览大量潜在的资料,在我的作品中寻找剽窃的例子。显然,“最诚恳的奉承”在写作界并没有价值。

真是惭愧,因为我与说这句话(指上段最后一句)的查尔斯·卡莱布·科尔顿有许多共同之处......不仅仅是因为我也逃离了英国,以逃避我的债权人。查尔斯在他的着作《Lacon, or Many Things in Few Words: Addressed to those who think》说:“当追随自己的经验时,错误比无知让自己更难到达终点”。写这样一篇文章的主要原因是:为了帮助我在前进之前控制我的无知,防止直撞悬崖。另外,我们网站上的其他页面也欢迎浏览,谢谢。
英特尔作为SR-IOV和DPDK的领导者或直接创始者,都是关于两者的绝佳信息来源。基于AMD(IOV),Inte(VT-d)等的输入/输出内存管理单元(IOMMU)技术的建立和标准化,“单根I/O虚拟化和共享规范”于2007年9月[1]首次发布,同时服务器虚拟化的概念正在大踏步前进。到目前为止,I/O虚拟化选项是严格基于软件的,虚拟机监控程序(VMM)永久驻留在物理网卡与虚拟网卡(vNIC)之间,vNIC与虚拟机紧密相连。
虽然通常我们就是这么看待虚拟化机的,而且这确实有一些优势,例如对老旧的应用程序支持和缓解对“专用”硬件的依赖,但使用虚拟机也导致了非常高的CPU利用率。这最终会降低吞吐量和一个平台实际部署的虚拟机数量--在某些情况下,从业务角度来看虚拟化已经不再可行。
与非虚拟化一样,在虚拟机中处理线缆中的数据包也是中断驱动的。当网卡接收到数据时,会向CPU发送中断请求(IRQ),然后CPU必须停下来去获取数据。任何有孩子的人都会明白,中断是无止境的 - 降低CPU执行主要计算任务的能力。在虚拟机中,这个问题被进一步放大了。运行管理程序的CPU内核不仅会被中断,而且一旦识别出该数据包属于哪个虚拟机(例如,基于MAC或VLAN ID),则必须再向运行该虚拟机的CPU内核发送中断,告诉那个虚拟机来获取它的数据。
这对性能是一个双重伤害,但更重要的是第一个CPU内核是主要的瓶颈,会很快到达最大负载。Intel采取了第一步消除这一瓶颈,并通过被称为虚拟机设备队列(VMDq)的技术来提高整体性能。顾名思义,VMDq使hypervisor能够为每个虚拟机分配一个不同的网卡队列。这样以来,不要先向管理程序CPU内核发送中断,只需要中断宿主目标VM的CPU内核。数据包只被搬弄一次,因为它直接复制到VM用户空间内存中。
现在VMDq已经消除了瓶颈,所有VM主机核心中的中断更加平衡。虽然这具有使hypervisor保持在循环中的优点,从而使得诸如vSwitch的功能保持在线,但是以数据平面为中心的虚拟化网络功能中的绝对数量的中断仍将对性能具有令人难以置信的不利影响。这就是SR-IOV诞生的由来。
当SR-IOV诞生时,我们正在经历一些中断根除运动。 InfiniBand风靡一时,其远程直接存储器访问(RDMA)技术有望推翻IRQs,只要它能够克服以太网。然而,像房子一样,以太网再次证明了这是不应该被打赌的东西。虽然不是“远程的”,因为没有独特的链路层协议,SR-IOV提供的是更加不可知的(读取:以太网)针对DMA的本地化和非overlay方法,专门针对虚拟化[2]。
源于PCI术语定义的元素把CPU和内存连接到PCI switch fabric (Root Complex),特别是自己定义名字的port(Root Port),SR-IOV允许单个的以太网接口表现的像多个独立的物理端口(很像VMDq),用以减轻中断问题,但是,SR-IOV比VMDq更好。

使用SR-IOV,hypervisor负责为每个VM实例划分NIC中的特定硬件资源。令人困惑的是我们所有人仍然试图让我们的脑袋围绕NFV命名,这些被称为虚拟功能(VFs)。虚拟功能由一个有限的,轻量级的PCIe资源[3]和一个专用的发送和接收数据包队列组成。在启动时加载VF驱动程序,hypervisor为每个虚拟机分配这些虚拟功能中的一个。然后NIC中的VF被赋予一个描述符,告诉它所在的具体虚拟机拥有的用户空间内存在哪里。一旦在物理端口上接收到数据包,并将其分类(通过MAC地址,VLAN标记或其他标识符),数据包将在VF中排队,直到它们可以被复制到VM的存储位置中为止[4]。
这种无中断的操作解放了VM的CPU核心,它就可以更多的被用于本机上的虚拟网络功能的计算。简而言之,SR-IOV很快。事实上,唯一比他更快的是PCI直通技术,但是我忽略了他是因为一次只能有一个VM使用,原因是PCI设备实际上是直接分配给了guest VM。也就是说,和SR-IOV不一样,PCI直通技术确实有作为纯软件解决方案的优点,但是他是基于特定的硬件特性(非标准化)。我也忽略了这些优点。
所有这些DMA的好处也是它的缺点,因为接口和虚拟机之间的任何事情都被绕过了。尽管OpenStack的Juno版本扩展了Neutron和Nova以支持网络设备的SR-IOV,从而减少了发生错误的机会,这个数据平面加速选项取决于NFV管理和编排(MANO)层,但DMA技术最终还是会导致流量绕过Hypervisor vSwitch。这引起了一些问题,包括SR-IOV支持便携性,灵活性,QoS,复杂的业务导向(包括用于服务功能链接的网络服务报头,如果VNF是中间件)的能力以及期望的NFV的云网络虚拟化需求的问题。
通常这并不是说你不能在同一台主机上或者你的云环境中同时运行SR-IOV和vSwitch,绝对可行。这将允许NFVI工程师在需要的时候使用vSwitch,SR-IOV或者两种结合使用。SR-IOV对于虚拟化是一个不错的选择,或者用以实施一个单独的虚拟化设备,对于期望获得高吞吐量的VNF设备,路由器或者三层为中心的架构,使用SR-IOV都是非常值得推荐的。而对于以二层为中心的中间设备或者VNF,如果对跨主机的东西向流量有严格的要求,那么就使用vSwitch。但是,这样的混合体系结构可能会增加管理的复杂性,也降低了构建通用,高效和灵活的SDN部署方式的可能性。
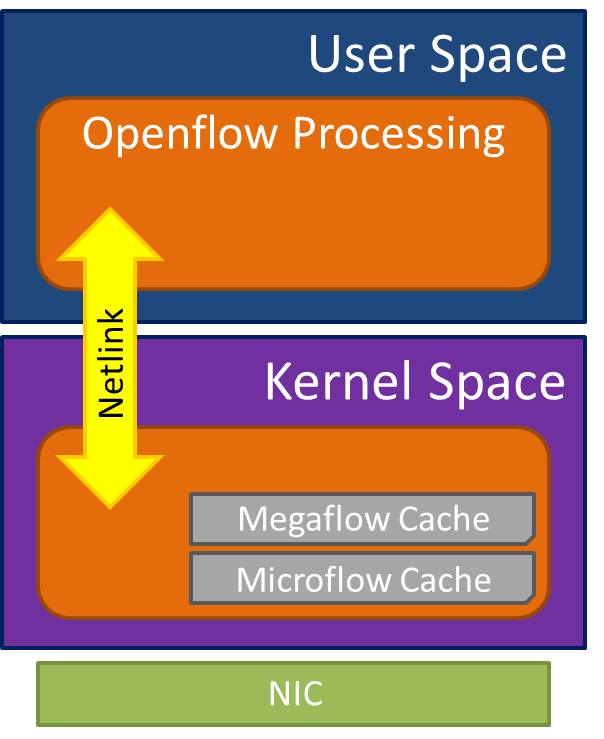
先把上面的推测放一边,简单的事实是在NFV基础设施中,我们在某些地方需要vSwitch。但是vSwitch很慢又笨拙。这并不令人感到惊讶,公平的讲,大家得到了想要的东西--灵活,可编程,状态可维护。但这些都不是没有代价的,这是以牺牲性能为代价的。如果我们讨论OVS,从现在开始,它尝试引入Megaflow(OVS 1.11 circa April 2011)的概念来提高性能,Megaflow是安装入内核中的二级流表缓存项。
通过把OVS拆分成内核态和用户态两部分,这样以来,一旦在用户态报文被识别并经过处理后,最近被精确匹配转发的数据包对应的Microflow项就通过NETLINK被下发安装到内核中。此外Megaflow每条缓存还包含通配符,可以匹配多个数据包,而不只是一个。这避免了大量的数据包频繁地与用户态进行IPC通信,减少上下文切换造成的性能损失。
但是据称,在OVS 2.1中,这种增强加速显得不太靠谱[5]。Megaflow的加速能力仍然依赖于数据包的特征和行为和穿越他的流量的模式,因此,不同的应用会有不同的结果。简单的说,他可能有效也可能无效--一定程度的不可预测性是不可能被开发和部署到商业服务中的。另一方面,他依然存在高开销的IPC,这就需要Data Plane Development Kit (DPDK) 大显身手了。
在Megaflow首次亮相(2011年9月)之后没多久,DPDK正式推向了世界,它是一个纯净又简洁的工具包。利用底层英特尔硬件的功能,它包含一组轻量级软件数据平面库和优化的NIC驱动程序,可针对特定应用程序进行修改。领先于6WindGate优化的产品和支持,紧随其后的是另一个Wind(River,英特尔部门),DPDK在2013年以开源BSD许可证形式向开发社区开放。DPDK可以应用于任何在Intel架构上运行的网络功能,OVS是理想的用例。
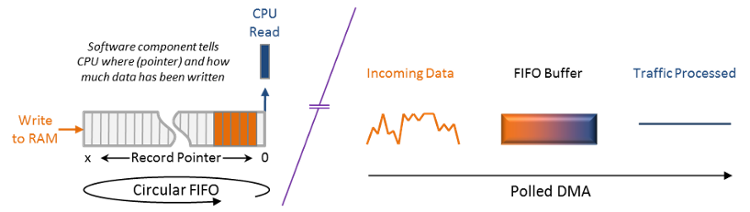
DPDK包含内存,buffer,和队列管理,此外还有一个流量分类引擎和一组轮询驱动程序。与Linux新API(NAPI)驱动程序类似,正如我们从SR-IOV知道的那样,DPDK轮询模式执行所有重要的中断缓解,这对于提高应用程序的整体性能至关重要。在网络流量较大的时候以轮询模式工作,内核会定期检查接口是否有传入数据包,而不是等待中断。为了防止poll-ution(是的,我用来它描述当没有数据需要被获取时的轮询状态)而不至于当有数据包到来时数据包需要等待被接收(这样会增加时延和抖动),当数据包流量低于某一个阀值时,DPDK可以切换到中断模式。
通过队列,内存和buffer管理器,DPDK还可以通过零拷贝直接把报文DMA到位于用户空间存储器中的大型先进先出(FIFO)环形缓冲区,类似于PF_RING。这又一次显着提高了数据包采集的整体性能,不仅可以实现更快的捕获速度,还可以平滑突发的入站流量,使应用程序能够更加一致地处理数据包,从而更高效地处理数据包。 另外,如果客户机CPU忙于处理应用程序,它可以将数据包保留在缓冲区中,而不用担心这些数据包被丢弃。自然,这个缓冲区大小以及轮询/中断阈值需要对延迟敏感的应用程序(如语音)仔细调优。
一个开放的vSwitch可以表现一些魔法,但是魔法总是伴随着一个代价,我们最终在CPU开销中付出了成本。 但是,如果使用修改后的DPDK实现CPU加速,那么CPU开销会大大降低。 那些使用DPDK加速OVS的方法已经实现了独立的控制和数据平面体系结构,这些体系结构在特定CPU内核的用户空间中执行分组处理,以从Linux卸载处理。 实际上,DPDK取代了Linux内核数据平面,这意味着microflows和megaflows都是在用户空间中以相同的方式操作的。
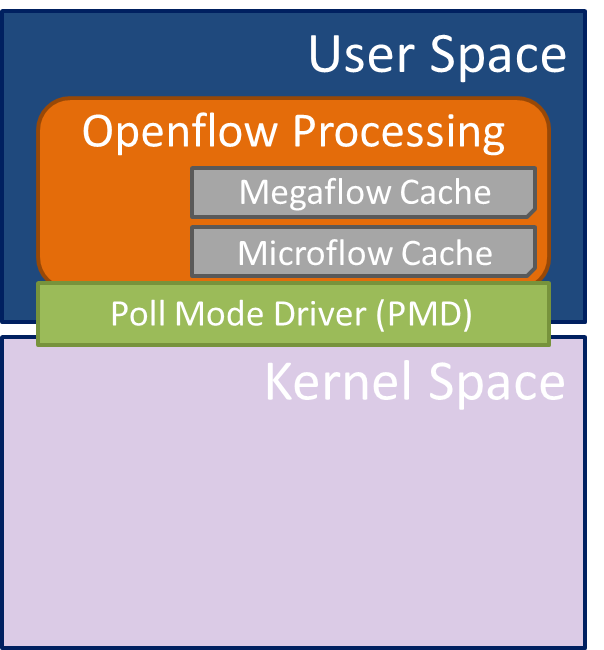
只有复杂的,基于状态的控制和管理协议(即ARP)才被发送到Linux网络堆栈进行处理。 但是,如果将加速的vSwitch与传统的vSwitch实现进行比较,则满足高吞吐量速率的虚拟化网络功能所需的CPU内核数量将大大减少。来自Wind的Charlie Ashton在一年前的博客上发表了一些具体的数字[6],一个OVS CPU核心处理0.3M(64字节)pps,需要12个才能支持4 Mpps(或1 Gbps全双工以太网)。即便更多的核心意味着更大的吞吐量,然而主机可以支持的VNF数量也会随之减少。 即使在不利的64字节数据包大小下,Wind的Accelerated vSwitch每个核心也能处理12 Mpps,因此只需要四个即可将单个全双工10 Gbps接口打满。
HPE最近发布了测试结果,比较裸机与SR-IOV和加速vSwitch的效果,这次是从6Wind[7]。虽然必须考虑CPU开销,但结果表明,一旦超出64字节的数据包范围,三者的表现都开始与接近高峰的表现大踏步前进。

虽然这在表格中看起来不错,但我们应该记住,典型的Internet Mix(IMIX)流量中的64byte长度的数据包,占平均流量样本的50%到60%。如果有问题的VNF碰巧正在处理实时语音和视频流量,例如会话边界控制器,这将会大大增加。这就是为什么我们将SBC用于SR-IOV和DPDK/OVS测试用例。正如Metaswitch首席技术官Martin Taylor在2015年1月的一篇博客文章中记录的,我们的结果让人们放心许多[8]。读了这么多之后,听到SR-IOV仅导致只有几个百分点的性能提高,比我们行业领先的裸机SBC实施还要少。然而,最令人满意的是,修改后的DPDK OVS达到了SR-IOV的90%的性能。即使通过这种加速的vSwitch方案带来了一些开销,但这也能够理解,毕竟它们有助于部署的灵活性。
如果上面的描述让你以为SR-IOV和DPDK只能二选一的话,那我得道歉。你当然可以使用SR-IOV把数据写入到使用DPDK的虚拟机中。如前所述,您也可以将DPDK加速vSwitch放入主机中,如果从部署的角度来看说的通的话,甚至可以混合使用(和正确的SR-IOV目标VNF加上适当配置的NFV基础架构管理器来处理这种复杂性)。这将仍然有待观察。
所以,感谢Mr.Colton的建议,我学到了什么?或者,更具体地说,我必须“忘掉”什么?我了解到,SR-IOV可以避免不止一个,而是两个中断和一个巨大的性能瓶颈。另外,我发现进程间通信调用对于vSwitch是多么的有害,而且DPDK将解决喝这个问题。总而言之,我就是这么想的。
原文链接:https://www.metaswitch.com/blog/accelerating-the-nfv-data-plane
相关索引材料
-
Rev 1.1 was introduced in January 2010.
-
iWARP and later RoCE brought true RDMA to Ethernet, in answer to the threat of InfiniBand.
-
The Physical Function (PF - the Ethernet port itself) continues to include a complete PCIe implementation.
-
These are not the physical memory locations, as the VM is unaware of those, so Intel Virtualization Technology for Directed I/O (VT-d) is required to perform the mapping between the virtual address space and the physical one.
-
Andy Hill and Joel Preas from Rackspace at the OpenStack Paris Summit in November 2014.
-
http://www.6wind.com/products/6windgate/optimized-architecture/
-
http://www.slideshare.net/jstleger/dpdk-summit-2015-hp-al-sanders
-
http://www.metaswitch.com/the-switch/tackling-the-nfv-packet-performance-challenge