内存结构
Oracle内存,进程与数据库的图
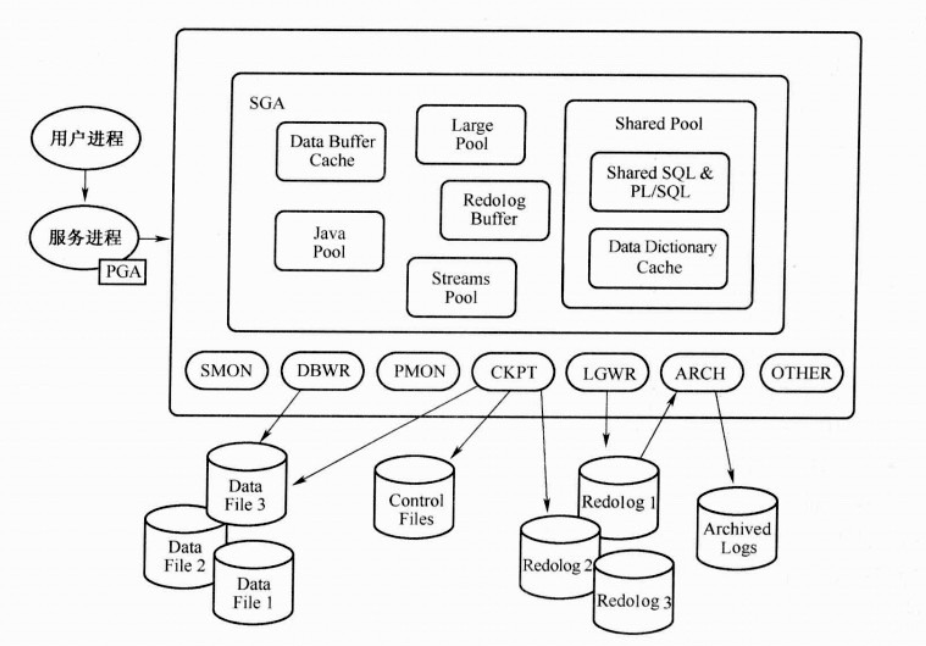
sga:系统全局区,用来存放操作的数据,库缓存,数据字典等控制信息的内存区域,
pga:进程全局区,服务进程专用的内存区域,大多数内容非共享
uga:用来保存用户的会话信息(如打开的游标,执行语句的私有变量),如果使用专用服务器,则uga在pga中分配,使用共享服务器,则uga在sga中分配。

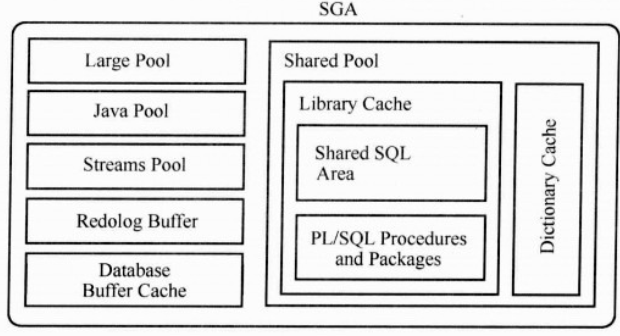
1 sga组成结构
sga是用来缓存数据库数据及控制信息的内存结构,大部分共享存在,sga中不同的池
共享池:share pool 控制大小—shared_pool_size
Java池 java pool—java_pool_size
大池 large pool—large_pool_size
流池 streams pool—streams_pool_size
数据缓冲区 database buffer cache—db_*_cache_size
重做日志缓冲区 redolog buffer cache—log_buffer
另外2个重要的参数,作用于整个sga内存区
sga_target:控制sga自动内存管理
sga_max_size:控制实例运行时sga最大能使用的内存空间
memory_target:用于自动内存管理(11g)
1.1 与sga相关的初始化参数
9i开始,oracle允许在实例运行中动态的修改sga的内存分配参数,而不需要重启实例
10g中直接支持修改当前内存参数值:shared_pool_size,large_pool_size,java_pool_size,
streams_pool_size,db_cache_size,sga_target
alter system set db_cache_size=2000m;
在sga中设置内存是,oracle已粒度作为单位,粒度大小不能修改,
SQL> show parameter java_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- --------------
java_pool_size big integer 0
SQL> alter system set java_pool_size=5m;
System altered.
SQL> show parameter java_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- --------------
java_pool_size big integer 8M
查看粒度大小
select component,granule_size from v$sga_dynamic_components
设置sga中的值时,不能超过sga_max_size的值
要修改db_cache_size的大小:1首先调低其他sga参数的大小,保证能有充分的空间来设置db_cache_size的大小 2 增加sga_max_size的值(物理条件允许),然后在调整db_cache_size,sga_max_size的值不能动态修改,重启才能生效
1.2 查看sga中的内存分配
show sga
select * from v$sga
select name,bytes from v$sgainfo—详细分配信息
2 自动管理sga
10g之前,需要手动设置几个参数值,sga中的内存只能自己使用,无法相互之间共享,
10g之后,引入sga_target参数,大于0,自动分配,等于0,则有dba手动分配
Statistics_level,设置为tepical或all,以便收集足够的统计信息,
select * from v$parameter where name='statistics_level'
alter system set sga_target=256m scope=spfile;
select * from v$parameter where name='sga_target'
3 数据缓冲区管理
在内存中操作数据,数据缓冲区用来存放从数据文件读取到的数据,数据缓冲区中的数据共享存在,数据一次性独到缓冲区,只要不被替换出,下次可以继续在缓冲区中读取,
3.1 数据在缓冲区中的管理方式
Oracle通过维护2个列表来管理数据缓冲区中的缓存块
写入列表:维护的是脏块,数据发生了修改,还未写到数据文件的数据
lru(最近最少使用)列表,包含空闲buffer,命中buffer,以及没来及写入的脏块
Oracle读取数据,首先检查数据缓冲区中是否有,没有则从数据文件中读取到buffer中,如果没有足够的buffer,则去搜索足够的空间,在搜索的过程中,如果遇到脏块,则dbwr进程将脏数据块写入到数据文件,如果搜索到足够的空间,则把数据读到缓冲区中。
刚刚读到buffer中的数据,并不是出现在mru端中,如全表触发的数据可能在lru段,具体在那个地方,有oracle决定。
如果搜索的数据缓存块达到一定的值,还没有找到空闲的内存,那oracle将启动dbwr进程,写脏数据倒文件,脏块就会变成空闲块
直接从buffer中读取(数据命中率)
查询命中率
select 1-(sum(decode(name,'physical reads',value,0))/
(sum(decode(name,'db block gets',value,0))+
(sum(decode(name,'consistent gets',value,0))))) "buffer hit ratio" from v$sysstat
一般低于95%就要注意调整sql
3.2 数据缓存区的大小设置
默认池:默认情况下从数据文件读取的数据都是存这里,对应初始化参数db_cache_size,
保持池:为了访问频繁但是不热的数据, keep pool,对应参数buffer_pool_keep
回收池:与keep相反,将不需要保存在buffer cache的数据快速替换出缓冲区,对应参数buffer_pool_recycle
数据加载到缓冲区时,存放在那个缓存池由对象的存储属性决定,在创建对象时,可以指定storage参数将会把数据加载到那个缓存池
Create table test(a number)storage(buffer_pool_keep)
不指定默认为在默认池
非标准数据块大小,db_nk_cache_size:2.4.8.16.32
SQL> show parameter db_block_size;
NAME TYPE VALUE
------------------------------------ ----------- -----
db_block_size integer 8192
alter system set db_16k_block_size=100m scope=spfile;
create tablespace 16k datafile ‘’size 100m blocksize 16k;
select name,bytes from v$sgainfo
4 共享池管理
Shared pool是sga中重要的组成部分,库缓存,数据字典缓存,用于并行执行消息缓存及控制结构组成
对应参数shared_pool_size
数据字典缓存,一般v$视图和dba_*(包含all和user)视图就存储在这里,
库缓存主要放执行过的sql和plsql,目的是为了重用
select sum(bytes)/1024/1024 mbytes from v$sgastat where pool='shared pool'
5 其他缓冲区管理
5.1 重做日志缓冲区
对对象的修改inset update create等等都会生成重做记录,重做日志缓冲区就是用来临时保存这些重做记录的区域,对应初始化参数log_buffer
重做日志缓冲区满足一定的条件就会触发后天lgwr进程将其写到重做日志
每3秒一次
无论何时有人commit
要求lgwr切换日志文件
重做日志缓冲区慢1/3时或者包含了1m的缓存重做日志数据
查看大小 select * from v$parameter where name='log_buffer'
select name,value/1024/1024 from v$parameter where name='log_buffer'
5.2 大池
Large_pool_size
执行并行查询:用来分配和协调并行任务
Rman备份:用于rman备份的磁盘的i/o缓存区
Uga:共享服务器连接,uga在这里分配
6 sga的共享池和数据缓存池的分配
1 v$db_cache_advice 参考值
用来生成不同大小数据缓存池的开销
select * from v$db_cache_advice
2 v$shared_pool_advice
select * from v$shared_pool_advice
6 pga的组成结构
pga是一,每块保存服务器进程的数据和控制信息的内存结构,oracle进程的专用区域,都非共享个连接到oracle的进程都有自己的pga区域,
专用服务器:私有sql区,会话内存区
单个会话允许的最大游标数open_cursors
Alter system set open_cursors=1000;
select * from v$parameter where name='open_cursors'
8 pga的管理
对于复杂的查询,pga中有专门的缓冲区,sql工作区
排序,hash –join,bitmap
pga_aggregate_target是一个上限目标
workarea_size_policy:manual或者auto,默认auto
将workarea_size_policy 设置为auto,Pga_aggregate_target有一个非0的值,oracle就会使用自动pga管理
select * from v$pga_target_advice
pga的参考值,v$pga_target_advice视图显示的预估值,需要statistics_level设置为all或者typical才有效。