Oracle data guard学习:三思笔记

Data guard
1data guard结构:
data guard是一个集合,由一个primary数据库(生产数据库)和一个或多个standby数据库(最多9个组成),组成data guard之间的数据库由oracle的net service来连接,
1主库:单实例,rac
2standby:物理standby:物理结构相同,接收到redo后,以介质恢复的形式到standby库
逻辑standby:数据相同,结构可能有差异,将接受到的redo转换成sql来操作standby的数据
1.1 data guard服务:
1 Redo传输服务:RTS:从主库发送redo到其他的的standby,
2 LOG应用服务:LAS:保证primary与standby的事务一致
物理standby:data guard使用redo apply技术,通过recover的方式应用redo数据
逻辑standby:使用sql apply,先将接收到的redo数据转换成sql,以执行该sql来应用redo数据
3 角色转换:一套dg只有2中角色:primary,standby
角色转换也就是切换,切换分2中:switchover跟failover
Switchover:将primary跟standby(一个)进行切换,不会丢失数据
Failover:primary出现故障并不能及时恢复,通过failover将一个standby转换为新的primary,在最大保护模式跟高可用模式下,不会丢失数据,(高性能可能会?)
1.2 3种保护模式:
最大保护:maximum protection,这种模式确保无数据丢失,要求事务在提前前,redo不仅写入到本地的online redologs中,还要同时写入到standby 的standby的redologs中,并确认至少在一个standby中可以使用了,才会在primary库中提交,如果standby导致redo问题,primary会shutdown
最高性能(默认):maximum performance,这种模式在不影响primary下,提供最高级别的数据保护策略,事务可以随时提交,当前primary的redo数据至少写入到一个standby中,可以是同步与异步
最高可用:maximum availability,在不影响primary的前提下,提供最大模式的保护数据的策略,要求本地事务在提交前把redo写入到一个standby中,如果standby出现故障,primary并不会shutdown,而是自动转换为最高性能模式,等standby恢复正常,会自动转换为最高可能
3种模式都需要指定log_archive_dest_n参数
1.3 data guard特定总结:
容灾恢复及高可用特性,全面的保护数据,有效利用系统资源,故障自动检测及解决方案,集中的易用管理模式,自动化切换角色,
2.1 standby数据库类型
1物理standby:
物理standby跟primary一模一样,通过redo来应用standby,在物理standby没有执行redo应用时,可以以read only模式打开,如果数据库中指定了flashback area,可以设置成read write,操作完成后可以flashback database恢复到read write前的状态,然后开启接收primary的redo并应用
Redo应用:物理standby用过redo 应用来保持跟primary 的一致,(通过oracle的恢复机制,利用归档跟redo来恢复对应的块的操作),如果正在执行redo的应用,db不能被open,redo应用时物理standby 的核心,
Read only模式打开:打开后,可以在standby执行查询跟备份操作,此时standby任然会接收redo,只不过不会进行redo 应用,知道standby恢复应用(oracle11g,改进了物理standby,可以在standby打开是应用redo,这样可以实现读写分离)
Read write打开db:此时不能接收primary发送的redo数据,失去了保护数据的策略,此时已该模式打开数据库,可以进行一些数据调试(不方便在生产上做的),操作完成在闪回,
物理standby 的特点:灾难恢复及高可用,数据保护,分担primary的压力,提升性能
2 逻辑standby:
逻辑standby也是通过primary的复制创建的,不过由于逻辑的使用sql应用来改变数据,所以可能数据结构不一样,
逻辑standby正常情况下是read write打开,用户可以在任何时候访问db,由于sql自身的特点,逻辑standby对有些数据类型及一些dml/ddl操作的不支持,
逻辑standby数据库可以额外的创建index,物化视图等提高查询性能并满足业务需要,如创建新的schema(primary不存在的),分担主库压力,可以将查询报表分离出来,平滑升级(实现跨版本的升级,为数据库打补丁,)
Data guard的操作界面
Oem,sqlplus,dgmgrl(data guard broker命令方式)
3 Data guard的软件要求:
同一个data guard的环境所有的oracle必须运行在相同的系统构架上,不同的服务器上可以配置不同,
Primary数据库跟standby数据库必须运行在相同的系统平台上,
Data guard是oracle 企业版的特性
同一个data guard配置中的所有初始化参数:compatible值必须相同
Primary数据库必须处于归档模式,并且force logging模式
Primary,standby均可以用于单实例和rac结构,并且可以在多个standby中,可以有逻辑standby跟物理standby
PrimaRy跟standby可以放在同一台服务器上,但是控制文件,参数文件,日志文件,数据文件,归档文件的目录不同,以免被覆盖
Primary和standby数据库必须有sysdba权限
建议采用相同的数据存储结构,服务器的时间设置,
3物理standby
3.1物理standby创建前的准备
1启用force logging模式
SQL> conn /as sysdba
Connected.
SQL> select force_logging from v$database;
FOR
---
NO
SQL> alter database force logging;
Database altered.
SQL> select force_logging from v$database;
FOR
---
YES
alter database no force logging
2创建密钥文件(不存在的话)
在所有的dg数据库配置中,都必须有自己独立的密钥文件,并且保证,同dg中,sys的密码必须一样,以保证redo顺利的传输(通过tns,会验证sys密码)
使用dbca创建数据库,会自动创建密钥文件
[oracle@localhost ~]$ cd /u01/app/oracle/product/10.2.0/db_1/dbs/
[oracle@localhost dbs]$ ll
-rw-r----- 1 oracle oinstall 1536 03-24 15:55 orapwgrs
不存在就创建
$ orapwd file=orapwgrs password="987064" entries=10 force=y;
3配置standby redologs,用于存储接收主库的redo log
对应最大保护和最高可用模式,建议为standby 创建redologs(不配置可以,oracle将在standby端自动创建归档文件,并虚拟为一组standby redologs,并使用lgwr sync模式传输redo
关于standby redologs建议:1 standby redologs跟primar的redo文件大小相同,2 创建适当的日志数目,一般而言,standby的redolog要比primary的redo文件多一个,(每线程的日志组数+1)*线程数,防止主库的lgwr进程锁住,备库的RFS进程接收到primary的redo,保存在本地(就是standby log)
ARCH模式的话不写standby log,直接读取归档文件
管理standby redologs:standby redologs的大小最好跟redo log的一样
v$log v$logfile
SQL> alter database add standby logfile group 4 ('/u01/app/oracle/oradata/grs/redo04.log') size 100m;
Database altered.
--删除该日志组
SQL> alter database drop standby logfile group 4;
Database altered.
SQL> alter database add standby logfile group 4 ('/u01/app/oracle/oradata/grs/redo04.log') size 50m;
alter database add standby logfile group 4 ('/u01/app/oracle/oradata/grs/redo04.log') size 50m
*
ERROR at line 1:
ORA-00301: error in adding log file '/u01/app/oracle/oradata/grs/redo04.log' -
file cannot be created
ORA-27038: created file already exists
Additional information: 1
--需要物理删除
----保证主库与备库的日志大小一样,
SQL> alter database add standby logfile group 4 ('/u01/app/oracle/oradata/grs/redo04.log') size 50m;
Database altered.
SQL> select group#, thread#, sequence#, archived, status from v$standby_log;
GROUP# THREAD# SEQUENCE# ARC STATUS
---------- ---------- ---------- --- ----------
4 0 0 YES UNASSIGNED
SQL> select group#,type,member from v$logfile;
GROUP# TYPE
---------- -------
MEMBER
--------------------------------------------------------------------------------
3 ONLINE
/u01/app/oracle/oradata/grs/redo03.log
2 ONLINE
/u01/app/oracle/oradata/grs/redo02.log
1 ONLINE
/u01/app/oracle/oradata/grs/redo01.log
GROUP# TYPE
---------- -------
MEMBER
--------------------------------------------------------------------------------
4 STANDBY
/u01/app/oracle/oradata/grs/redo04.log
4设置初始化参数
SQL> create pfile ='/u01/oracle/backup/pfile' from spfile;
File created.
[oracle@localhost backup]$ vi pfile
grs.__db_cache_size=180355072
grs.__java_pool_size=4194304
grs.__large_pool_size=4194304
grs.__shared_pool_size=88080384
grs.__streams_pool_size=4194304
*.audit_file_dest='/u01/app/oracle/admin/grs/adump'
*.background_dump_dest='/u01/app/oracle/admin/grs/bdump'
*.compatible='10.2.0.1.0'
*.control_files='/u01/app/oracle/oradata/grs/control01.ctl','/u01/app/oracle/oradata/grs/control02.ctl','/u01/app/oracle/oradata/grs/control03.ctl'
*.core_dump_dest='/u01/app/oracle/admin/grs/cdump'
*.db_block_size=8192
*.db_domain=''
*.db_file_multiblock_read_count=16
*.db_name='grs'
*.db_recovery_file_dest='/u01/app/oracle/flash_recovery_area'
*.db_recovery_file_dest_size=2147483648
*.dispatchers='(PROTOCOL=TCP) (SERVICE=grsXDB)'
*.job_queue_processes=10
#*.log_archive_dest_1='location=/u01/app/oracle/archivelog/archivelog/'
*.open_cursors=300
*.pga_aggregate_target=94371840
*.processes=150
*.remote_login_passwordfile='EXCLUSIVE'
*.sga_target=285212672
*.undo_management='AUTO'
*.undo_tablespace='UNDOTBS1'
*.user_dump_dest='/u01/app/oracle/admin/grs/udump'
# DB_NAME=grs
*.DB_UNIQUE_NAME=grs
*.LOG_ARCHIVE_CONFIG='DG_CONFIG=(grs,grs2)'
*.LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
*.LOG_ARCHIVE_DEST_2='SERVICE=grs2 LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=grs2'
*.LOG_ARCHIVE_DEST_STATE_1=ENABLE
*.LOG_ARCHIVE_DEST_STATE_2=ENABLE
# *.REMOTE_LOGIN_PASSWORDFILE=EXCLUSIVE
*.LOG_ARCHIVE_FORMAT=%t_%s_%r.arc
*.LOG_ARCHIVE_MAX_PROCESSES=30
# 以下部分为主机切换为备库使用
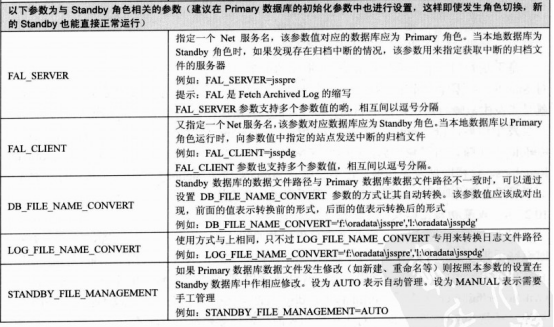
*.FAL_SERVER=grs_192.168.2.185
*.FAL_CLIENT=grs2_192.168.2.185
*.DB_FILE_NAME_CONVERT='/u01/app/oradata/grs','/u02/app/oradata/grs2'
*.LOG_FILE_NAME_CONVERT='/u01/app/oradata/grs','/u02/app/oradata/grs2'
*.STANDBY_FILE_MANAGEMENT=AUTO
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> create spfile from pfile='/u01/oracle/backup/pfile';
File created.
SQL> startup;
5将主库设置为归档模式
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /u01/app/oracle/archivelog/archivelog/
Oldest online log sequence 3
Next log sequence to archive 5
Current log sequence 5
如果是disable,需要启动到mount,然后SQL> alter database archivelog;
3物理standby创建的实际过程演示
源数据库primary
Ip:192.168.2.185
Oracle sid=grs
Db_unique_name=grs
安装路径:/u01/app/oracle/product/10.2.0/db_1/dbs
数据文件:/u01/app/oracle/oradata/grs
归档路径:/u01/oracle/backup
目标数据库standby
Ip:192.168.2.188
Oracle sid=grs2
Db_unique_name=grs2
安装路径:/u02/app/oracle/product/10.2.0/db_1/dbs
数据文件:/u02/app/oracle/oradata/grs2
归档路径:/u02/oracle/backup
1 primary主库的配置及相关
1 检查主库的归档
oracle@localhost backup]$ export ORACLE_SID=grs
SQL> archive log list;
如果不是归档状态,重新启动到mount,alter database archivelog
2 将主库设置为force loggin状态
SQL> conn /as sysdba
Connected.
SQL> select force_logging from v$database;
FOR
---
NO
SQL> alter database force logging;
Database altered.
SQL> select force_logging from v$database;
FOR
---
YES
alter database no force logging
3 配置主库的初始化参数
SQL> create pfile ='/u01/oracle/backup/pfile' from spfile;
File created.
[oracle@localhost backup]$ vi pfile
# DB_NAME=grs
*.DB_UNIQUE_NAME=grs
*.LOG_ARCHIVE_CONFIG='DG_CONFIG=(grs,grs2)'
*.LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
*.LOG_ARCHIVE_DEST_2='SERVICE=grs2 LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=grs2'
*.LOG_ARCHIVE_DEST_STATE_1=ENABLE
*.LOG_ARCHIVE_DEST_STATE_2=ENABLE
# *.REMOTE_LOGIN_PASSWORDFILE=EXCLUSIVE
*.LOG_ARCHIVE_FORMAT=%t_%s_%r.arc
*.LOG_ARCHIVE_MAX_PROCESSES=30
# 以下部分为主机切换为备库使用
*.FAL_SERVER=grs_192.168.2.185
*.FAL_CLIENT=grs2_192.168.2.188
*.DB_FILE_NAME_CONVERT='/u01/app/oradata/grs','/u02/app/oradata/grs2'
*.LOG_FILE_NAME_CONVERT='/u01/app/oradata/grs','/u02/app/oradata/grs2'
*.STANDBY_FILE_MANAGEMENT=AUTO
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> create spfile from pfile='/u01/oracle/backup/pfile';
File created.
SQL> startup;
4 创建standby库的控制文件
SQL> ALTER DATABASE CREATE STANDBY CONTROLFILE AS '/u01/oracle/backup/control01.ctl';
5 复制相关文件到standby数据库
可以采用rman,expdp,cp等命令,复制相关数据文件到standby
6 配置监听跟网络服务名
[oracle@localhost admin]$ cp -p /u01/app/oracle/product/10.2.0/db_1/network/admin/listener.ora /u02/app/oracle/product/10.2.0/db_1/network/admin/
[oracle@localhost admin]$ cp -p /u01/app/oracle/product/10.2.0/db_1/network/admin/tnsnames.ora /u02/app/oracle/product/10.2.0/db_1/network/admin/
修改监听文件
[oracle@localhost admin]$ vi listener.ora
# listener.ora Network Configuration File: /u01/app/oracle/product/10.2.0/db_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /u02/app/oracle/product/10.2.0/db_1)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME = Oracle8)
(ORACLE_HOME = /u02/app/oracle/product/10.2.0/db_1)
(SID_NAME = grs2)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.2.185)(PORT = 1521))
)
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC0))
)
)
[oracle@localhost admin]$ vi tnsnames.ora
# tnsnames.ora Network Configuration File: /u01/app/oracle/product/10.2.0/db_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
GRS2 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.2.185)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = grs2)
)
)
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC0))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
7 创建密钥文件(并复制到standby对应路径)
[root@localhost ~]# cd /u01/app/oracle/product/10.2.0/db_1/dbs/
[root@localhost dbs]# ll
-rw-r----- 1 oracle oinstall 1536 03-24 15:55 orapwgrs
不存在就创建
$ orapwd file=orapwgrs password="987064" entries=10 force=y;
2物理standby端的配置
[oracle@localhost backup]$ export ORACLE_SID=grs2
1 创建日志文件,后台进程的相关目录
[oracle@localhost oracle]$ mkdir -p archivelog/archivelog
[oracle@localhost oracle]$ mkdir -p /u02/app/oracle/flash_recovery_area/grs/onlinelog
[oracle@localhost oracle]$
[oracle@localhost oracle]$ pwd
/u02/app/oracle
[oracle@localhost oracle]$ mkdir admin
[oracle@localhost oracle]$ cd admin/
[oracle@localhost admin]$ mkdir grs2
[oracle@localhost admin]$ cd grs2/
[oracle@localhost grs2]$ mkdir adump bdump cdump udump
2配置监听跟网络服务名
配置好后,可以tnsping
3修改standby的参数文件
[oracle@localhost dbs]$ vi initgrs2.ora
*.LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
grs.__db_cache_size=192937984
grs.__java_pool_size=4194304
grs.__large_pool_size=4194304
grs.__shared_pool_size=75497472
grs.__streams_pool_size=4194304
*.audit_file_dest='/u02/app/oracle/admin/grs/adump'
*.background_dump_dest='/u02/app/oracle/admin/grs/bdump'
*.compatible='10.2.0.1.0'
*.control_files='/u02/app/oracle/oradata/grs/control01.ctl','/u02/app/oracle/oradata/grs/control02.ctl','/u02/app/oracle/oradata/grs/control03.ctl'
*.core_dump_dest='/u02/app/oracle/admin/grs/cdump'
*.db_block_size=8192
*.db_domain=''
*.db_file_multiblock_read_count=16
*.DB_FILE_NAME_CONVERT='/u02/app/oradata/grs2','/u01/app/oradata/grs'
*.db_name='grs'
*.db_recovery_file_dest='/u02/app/oracle/flash_recovery_area'
*.db_recovery_file_dest_size=2147483648
*.DB_UNIQUE_NAME='grs2'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=grsXDB)'
*.FAL_CLIENT='grs_192.168.2.185'
*.FAL_SERVER='grs2_192.168.2.185'
*.job_queue_processes=10
*.LOG_ARCHIVE_CONFIG='DG_CONFIG=(grs2,grs)'
*.LOG_ARCHIVE_DEST_1='LOCATION=/u02/app/oracle/archivelog/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs2'
*.LOG_ARCHIVE_DEST_2='SERVICE=grs LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=grs'
*.LOG_ARCHIVE_DEST_STATE_1='ENABLE'
*.LOG_ARCHIVE_DEST_STATE_2='ENABLE'
*.LOG_ARCHIVE_FORMAT='%t_%s_%r.arc'
*.LOG_ARCHIVE_MAX_PROCESSES=30
*.LOG_FILE_NAME_CONVERT='/u02/app/oradata/grs2','/u01/app/oradata/grs'
*.open_cursors=300
*.pga_aggregate_target=94371840
*.processes=150
*.remote_login_passwordfile='EXCLUSIVE'
*.sga_target=285212672
*.STANDBY_FILE_MANAGEMENT='AUTO'
*.undo_management='AUTO'
*.undo_tablespace='UNDOTBS1'
*.user_dump_dest='/u02/app/oracle/admin/grs2/udump'
4启动物理standby到mount状态
5接收归档文件
物理standby启动到mount状态后,就能够接收来自primary端的redo日志,需要切换到主库
Primary sql>alter system set log_arhive_dest_state_2=ENABLE;
然后primary库就会发送redo到standby,查看接收到的归档文件,V$ARCHIVED_Log
Primary修改的数据能否在standby看到,受几个方面的影响
1同步模式:默认情况下primary发送归档日志通过ARCH方式,只有当日志切换时,才会把产生的归档日志发送到standby,如果standby端配置了standby redologs,就支持lgwr传输redo到standby,这样产生的redo就能及时发送到standby端
2 是否启动了应用:将redo发送到了standby端,并不意味着standby就有数据,必须手动执行应用命令,才能将修改的应用到standby,在默认的情况下,物理standby数据库是执行的恢复过程,只有当主库产生日志切换时才会应用归档到standby,
3是否实时应用:在standby端配置了standby redologs,并且在传输redo数据时采用lgwr同步传输的方式,在这种情况下,redo是实时的,
Oracle10g,物理的standby是不能实时看到数据的(逻辑standby或者11g物理standby才可以)
6启动redo应用:即使当前standby处于open状态,也不需要重启,直接执行后,Oracle会切换到mount状态
SQL> alter database recover managed standby database disconnect from session;
暂停redo应用(并不是停止,standby任然会接收,但不会应用)
SQL> alter database recover managed standby database cancel;
停止redo传输应用,standby数据库
主库:SQL> ALTER SYSTEM SET log_archive_dest_state_2='DEFER';
System altered.
备库:SQL> alter database recover managed standby database cancel;
alter database recover managed standby database cancel
*
ERROR at line 1:
ORA-16136: Managed Standby Recovery not active
4 物理standby的角色切换
Switchover跟failover
Switchover:切换不会丢失数据,手动触发或者定时计划触发,
Failover:不可预知的原因导致不能恢复或者恢复时间较长,这就需要failover,
1 物理的switchover切换
1转换前的准备工作
检查各数据库的初始化参数,确认转换的primary跟standby,以及确认是否正确的初始化参数的配置
检查即将成为primary库是否为归档
检查物理standby的临时文件是否存在
确保standby数据库的rac实例只有一个实例在启动,
选择一个最适合转换的转换成primary

2物理执行standbyswitchover
1检查初始化参数
2检查是否支持switchover(主库)
SQL> select switchover_status from v$database;
SWITCHOVER_STATUS
--------------------
SESSIONS ACTIVE:当前任然有人连接primary数据库,(通过as sysdba连接,就会产生这样的状态)
primary>select switchover_status from v$database;
SWITCHOVER_STATUS
----------------------------------------
TO STANDBY
standby >select switchover_status from v$database;
SWITCHOVER_STATUS
----------------------------------------
NOT ALLOWED
SQL> select switchover_status from v$database;
SWITCHOVER_STATUS
----------------------------------------
TO STANDBY
如果该值为to standby,表示支持切换
SQL> select switchover_status from v$database;
SWITCHOVER_STATUS
----------------------------------------
RECOVERY NEEDED
3启动switchover
首先将primary库切换到standby状态
Primary SQL> alter database commit to switchover to physical standby;(with session shutdown)
并将该primary重新启动到mount状态
SQL> shutdown immediate
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> startup nomount;
ORACLE instance started.
SQL> alter database mount standby database;
4 在standby上检查是否支持switchover
SQL> select name,open_mode,protection_mode,database_role from v$database;
standby >select switchover_status from v$database;
SWITCHOVER_STATUS
----------------------------------------
NOT ALLOWED
显示的状态:SWITCHOVER_STATUS,TO PRIMARY,SWITCHOVER PENDING(当前standby数据没有启动redo应用,重新执行alter database recover managed standby database disconnect from session;
5转换角色到primary
SQL> alter database commit to switchover to primary;
待转换的standby可以是mount或者open read only状态, 不能是read write
6重新打开primary(新)
SQL> shutdown immediate
ORA-01507: database not mounted
ORACLE instance shut down.
SQL> startup
2物理的failover切换
Note:
1 failover后,原primary不再是dg的一部分
2 在多数情况下,其他物理/逻辑standby不直接参与failover过程,不需要做操作
3 某些情况下,新的primary数据库配置后,需要重新创建dg配置中其他的所有的standby
4 在执行failover之前,尽量把primary的redo跟归档都复制到standby
如果待转换的模式是最大保护模式,需要切换到最高可用模式
alter database set standby database to maximize performance;
1 检查归档日志是否连续
查询待转换的standby,
select thread#,low_sequence#,high_sequence# from v$archive_gap
如果有返回的记录,按照列出的记录号复制对应的归档到standby的服务器,文件复制过来,通过加入数据字典
alter database register physical logfile 'filespec1';
2 检查归档文件是否完整
主库跟备库分别执行
select distinct thread#,max(sequence#)over(partition by thread#) from v$archived_Log
必须保证2个max相同,不然就需要拷贝归档到standby
3启动failover
alter database recover managed standby database finish force;
force会停止当前活动的rfs进程
4 切换物理standby为primary
alter database commit to switchover to primary;
5启动新的primary数据库
处于mount,则直接open,open read only,则shutdown 然后重启,
5 read only模式打开物理standby
1物理standby直接从shutdown状态启动到read only
直接startup,就是read only状态
2 物理standby从redo应用到read only状态
首先需要取消redo应用
alter database recover managed standby database cancel;
然后在打开db
Alter database open
3从read only切换到redo应用
alter database recover managed standby database disconnect from session;
备库,read only模式打开后,可进行查询,备份等操作
Ready wirte模式打开数据库,standby将暂停redo应用。此时可以在备库上进行恢复,调试数据,操作完成之后,将数据库闪回到操作前的状态(闪回之后,dg会自动同步standby)
6 管理影响物理standby的事件
1 创建表空间或数据文件
初始化参数standby_file_management用来控制是否自动将primary数据库增加表空间或数据文件的改动,传播到standby服务器AUTO/MANUAL
AUTO:自动传播到standby
MANUAL:需要手动复制文件到standby,并更新控制文件
1 将standby_file_management 设置为auto(主库)
SQL> set sqlprompt "primary>"
primary>show parameter standby_file
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
standby_file_management string AUTO
SQL> create tablespace new_dg datafile'/u01/app/oracle/oradata/grs/new_dg.dbf' size 10m;
Tablespace created.
SQL> col tsname for a20
SQL> col dfname for a50
SQL> select ts.name tsname,df.name dfname from v$tablespace ts,v$datafile df
2 where ts.ts#=df.ts#;
TSNAME DFNAME
-------------------- --------------------------------------------------
SYSTEM /u01/app/oracle/oradata/grs/system01.dbf
UNDOTBS1 /u01/app/oracle/oradata/grs/undotbs01.dbf
SYSAUX /u01/app/oracle/oradata/grs/sysaux01.dbf
21 rows selected.
备库查看
SQL> col tsname for a20
SQL> col dfname for a50
SQL> select ts.name tsname,df.name dfname from v$tablespace ts,v$datafile df
2 where ts.ts#=df.ts#;
TSNAME DFNAME
-------------------- --------------------------------------------------
SYSTEM /u01/app/oracle/oradata/grs/system01.dbf
UNDOTBS1 /u01/app/oracle/oradata/grs/undotbs01.dbf
SYSAUX /u01/app/oracle/oradata/grs/sysaux01.dbf
USERS /u01/app/oracle/oradata/grs/users01.dbf
20 rows selected.
报错日志:
Errors in file /u01/app/oracle/admin/grsdg/bdump/grsdg_dbw0_10650.trc:
ORA-01157: cannot identify/lock data file 20 - see DBWR trace file
ORA-01110: data file 20: '/u01/app/oracle/oradata/grs/SPICEI2I02.dbf'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Mon May 5 10:41:18 2014
RFS[5]: Archived Log: '/u01/app/oracle/archivelog/1_258_827453919.arc'
Primary database is in MAXIMUM PERFORMANCE mode
RFS[5]: No standby redo logfiles created
待解决::::???
12c dg
SQL> show parameter standby_file
NAME TYPE
------------------------------------ ----------------------
VALUE
------------------------------
standby_file_management string
auto
SQL> create tablespace new_dg2 datafile'/u01/app/oracle/oradata/hongquan/hongquantest/new_dg2.dbf' size 10m;
Tablespace created.
2 将standby_file_management 设置为manual(主库)
ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=MANUAL;
在重复上述操作
记录多了一条,需要重命名
ALTER DATABASE CREATE DATAFILE ‘/u01/app/oracle/oradata/grs/XXXX’AS
/u01/app/oracle/oradata/grs/new_dg.dbf
然后重新启动redo应用
alter database recover managed standby database disconnect from session;
disconnect from session---启动应用,自动退到命令操作符
2 删除表空间
--对于表空间和数据文件的操作,STANDBY_FILE_MANAGEMENT=AUTO,无须手工干预,
3 重命名数据文件
--需要手工干预,STANDBY_FILE_MANAGEMENT=AUTO/MANUAL
在主库rename datafile文件,从库需要手动操作
备库:cancel redo log,shutdown,重命名数据文件,在startup mount,重启redo 应用
alter tablespace new_dg2 offline;
mv /u01/app/oracle/oradata/hongquan/hongquantest/new_dg2.dbf /u01/app/oracle/oradata/hongquan/hongquantest/new_dg2_test.dbf
alter tablespace new_dg2 rename datafile
'/u01/app/oracle/oradata/hongquan/hongquantest/new_dg2.dbf' to
'/u01/app/oracle/oradata/hongquan/hongquantest/new_dg2_test.dbf';
alter tablespace new_dg2 online;
alter system switch logfile;
select name from v$datafile;
alter database recover managed standby database cancel;
mv /u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2.dbf /u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2_test.dbf
----12c,备库ready only模式,不能改
alter tablespace new_dg2 rename datafile
'/u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2.dbf' to
'/u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2_test.dbf';
alter database recover managed standby database disconnect from session;
select name from v$datafile;
---12c 在线重命名数据文件
ALTER DATABASE MOVE DATAFILE '/u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2.dbf'
to
'/u02/app/oracle/oradata/hongquan1/hongquantest/new_dg2_test.dbf';
4 添加或删除redologs文件
--需要手工干预改文件的删除和创建
无论主库端对日志组或日志文件的操作是否传播到了standby端,也不会影响到standby的运行。
在主库增加或删除redo logs时,一定记得手工同步相关物理standby中的相关设置,保证standby log比primary redolog多一组操作要将STANDBY_FILE_MANAGEMENT=MANUAL
5垮open_resetlogs的应用


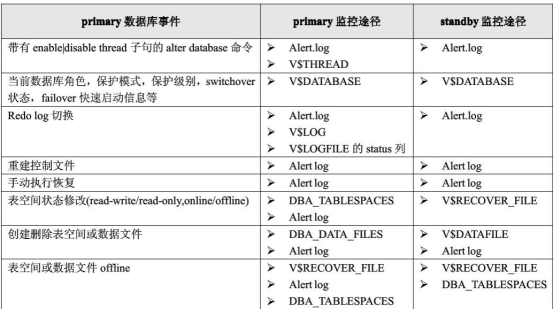
1 监控primary和standby库的事件


2 动态性能视图
1v$managed_standby 显示物理standby数据库相关进程的当前状态
standby>select process,client_process,sequence#,status from v$managed_standby;
ARCH ARCH 0 CONNECTED
MRP0 N/A 37 APPLYING_LOG
RFS ARCH 0 IDLE

2 v$archive_dest_status 显示归档文件路径配置信息及redo的应用情况
standby>select dest_name,archived_thread#,archived_seq#,applied_thread#,applied_seq#,db_unique_name from v$archive_dest_status where status='VALID';
3v$archived_log 检查归档文件路径和创建信息
standby>select name,creator,sequence#,applied,completion_time from v$archived_log;
4 v$log_history 查询归档历史
select first_time,first_change#,next_change#,sequence# from v$log_history;
standby>select thread#,max(sequence#) as "last_applied_log" from v$log_history group by thread#;
5 查看物理standby未接受的日志文件
standby>select local.thread#,local.sequence# from
2 (select thread#,sequence# from v$archived_log where dest_id=1) local
3 where local.sequence# not in
4 (select sequence# from v$archived_log where dest_id=2 and thread#=local.thread#);
3 管理归档中断gap
4 standby的选择数据保护模式

Primary的修改能否在standby端看到,受几个方面的影响:
1:同步模式:默认情况primary端发送归档日志通过ARCH的方式,只有当primary切换日志时,产生的归档日志才会发送到standby端。如果standby端配置了standby redologs文件,dg支持以lgwr方式传输redo数据,这样primary产生的redo就能及时发送到standby端。
2:是否启动了应用:将redo发送到standby端,并不代表standby端应用了改redo,必须手动执行命令。默认情况下,物理standby的应用执行是恢复过程,只有当主库primary库执行切换操作后,才会对切换产生的归档文件进行应用,在时效上比primary有延后
3:是否实时应用:standby端配置了standby redologs,并且prim传输redo日志时采用了lgwr同步传输的方式,这是redo传输实时(async,sync)
1 Dataguard 服务
1 redo传输服务rts
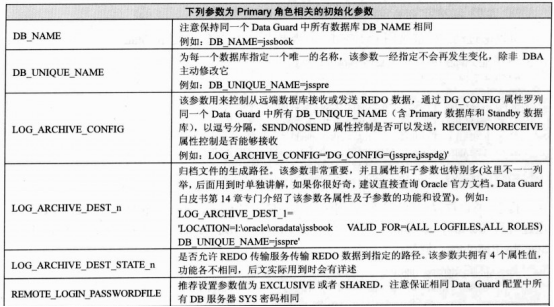
1 认识LOG_ARCHIVE_DEST_N参数
LOG_ARCHIVE_DEST_N(1-10)定义redo 发送的目的地,通过location或者service 来指定本地还是远程service,LOG_ARCHIVE_DEST_N都有对应的LOG_ARCHIVE_DEST_STATE_N用来指定LOG_ARCHIVE_DEST_N的属性是否生效,有4种属性
Enable:默认,表示允许传输
Defer:属性有效,但暂不使用该归档路径
Alternate:禁止传输,其他的失败,会自动enable
Reset:与defer相似,
LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES)
LOG_ARCHIVE_DEST_STATE_1='ENABLE'
用过service关键字指定redo的传输
LOG_ARCHIVE_DEST_2='SERVICE=‘’
log_archive_dest_state_2='DEFER'
可以通过alter system set来修改2个参数,修改会在下次日志切换时生效
Alter system set LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
SQL> col name for a15
SQL> col value for a20
SQL> set pageline 1000
SP2-0158: unknown SET option "pageline"
SQL> set pagesize 1000
SQL> set linesize 1000
SQL> show parameter log_archive_dest
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
log_archive_dest string
log_archive_dest_1 string LOCATION=/u01/app/oracle/archi
velog/ VALID_FOR=(ALL_LOGFILES
,ALL_ROLES) DB_UNIQUE_NAME=grs
log_archive_dest_10 string
log_archive_dest_2 string SERVICE=grsdg LGWR ASYNC VALID
_FOR=(ONLINE_LOGFILES,PRIMARY_
ROLE) DB_UNIQUE_NAME=grsdg
2 使用ARCn进程发送redo数据
默认情况下,使用ARCn进程发送redo数据,(只支持最高性能保护模式),在其他模式下需要lgwr传输,可以增加arcn进程
Alter system set log_archive_max_process=n;(0-30)
ARCHn归档过程,
Primary发生日志切换时,就会产生归档,:分别在primary跟standby
一旦arc0完成在线日志的归档,arc1就开始传输归档中的redo到standby(假设有2个进程)
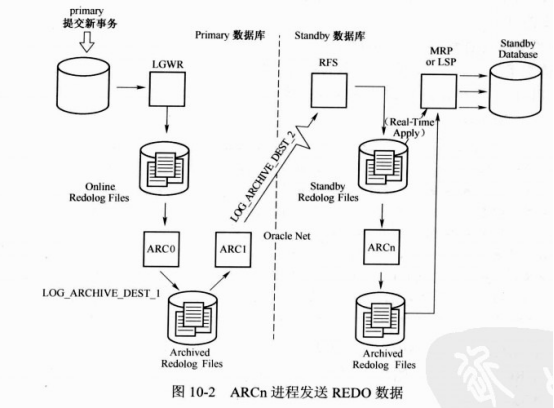
本地归档与远程归档并无联系,
3 lgwr进程传输redo
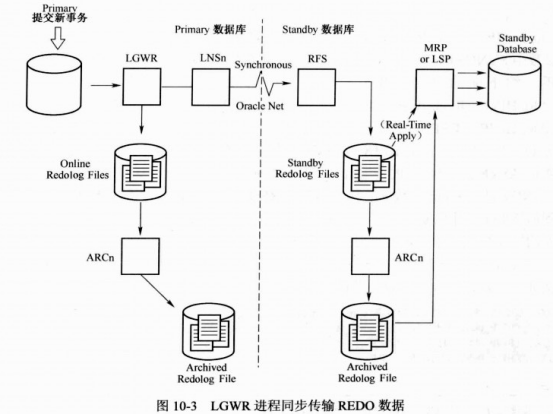
Lgwr进程不需要等日志完成切换或归档才传输,standby数据库的lgwr进程会选择一个standby redologs文件映射primary数据库当前活动的联机重做日志文件,一旦primary有redo产生,根据参数中的sync或async来确定同步或非同步方式发送redo
1 lgwr同步redo流程
*.LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
*.LOG_ARCHIVE_DEST_2='SERVICE=grsdg LGWR SYNC new_timeout=30
*.LOG_ARCHIVE_DEST_STATE_1='ENABLE'
*.log_archive_dest_state_2='DEFER'
---- new_timeout 连接超时,会返回错误
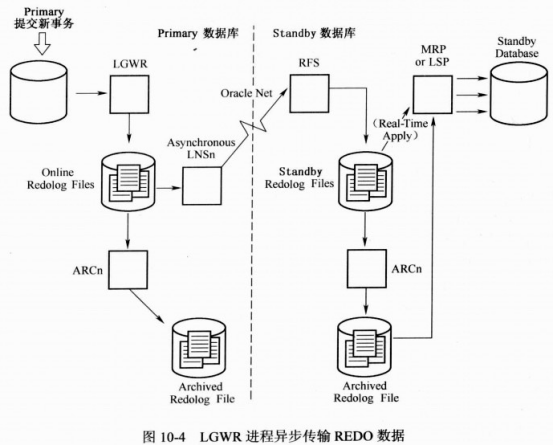
2 lgwr不同步归档流程
*.LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/ VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=grs'
*.LOG_ARCHIVE_DEST_2='SERVICE=grsdg LGWR ASYNC
*.LOG_ARCHIVE_DEST_STATE_1='ENABLE'
*.log_archive_dest_state_2='DEFER'
4安全传输redo
Redo传输的过程中使用密码验证的方式,保证primary跟standby的sys密码一样
什么时候发送
1 VALID_FOR属性指定传输及接受对象
VALID_FOR=(ALL_LOGFILES,ALL_ROLES)
VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)
2 通过db_unique_name指定数据库
DB_UNIQUE_NAME='grs'
LOG_ARCHIVE_CONFIG='DG_CONFIG=(grs,grsdg)'
3 出错了怎么办
LOG_ARCHIVE_DEST_1有几个属性来控制出现错误时采取的措施
1 reopen 指定时间后再次尝试归档
Reopen=seconds(300)默认
LOG_ARCHIVE_DEST_2='SERVICE=grsdg LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=grsdg reopen=100'
2 alternate指定替补归档路径
LOG_ARCHIVE_DEST_1='LOCATION=/u01/app/oracle/archivelog/ alternate=LOG_ARCHIVE_DEST_2'
LOG_ARCHIVE_DEST_STATE_1='ENABLE'
LOG_ARCHIVE_DEST_2='LOCATION=/u01/app/oracle/archivelog2/'
LOG_ARCHIVE_DEST_STATE_2='ALTERNATE'
3 max_failure控制最大失败次数
LOG_ARCHIVE_DEST_2='SERVICE=grsdg LGWR ASYNC reopen=100 max_failure=3'
4 管理日志文件
默认情况下,本地的归档都是放在LOG_ARCHIVE_DEST_2='location的路径下
设置是否可以被重用
设置控制文件中记录重用及增长规则
多个standby间共享文件路径
Dependency属性
2 log应用服务(log apply service)
Data guard用过redo来维持primary跟standby之间的一致性
Redo:物理standby专用,通过介质恢复的方式保持一致
Sql:逻辑standby专用,通过logminer分析sql语句,在standby端执行
因此物理的standby必须是mount状态(10g),逻辑可以是read only
1 redo实时应用
Redo不需要等归档完成了,接收到即可应用,standby端配置了standby redologs,物理实时启动,
alter database recover managed standby database using current logfile
2 redo延迟应用
LOG_ARCHIVE_DEST_2='SERVICE=grsdg ARCH VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=grsdg DELAY=15'
DELAY 默认30分钟
alter database recover managed standby database nodelay disconnect;
3应用redo到standby数据库
启动redo应用
alter database recover managed standby database disconnect;
停止redo应用
alter database recover managed standby database cancel;
4选择数据库保护模式

1 查看当前数据库的保护模式
select db_unique_name,open_mode,database_role,switchover_status,
dataguard_broker,protection_mode,remote_archive,guard_status from
v$database;
2 修改初始化参数
Alter system set
3设置新的保护模式,并重启db
alter database set standby database to maximize availability