https://www.bilibili.com/video/BV117411C79Y/?spm_id_from=333.788.recommend_more_video.10
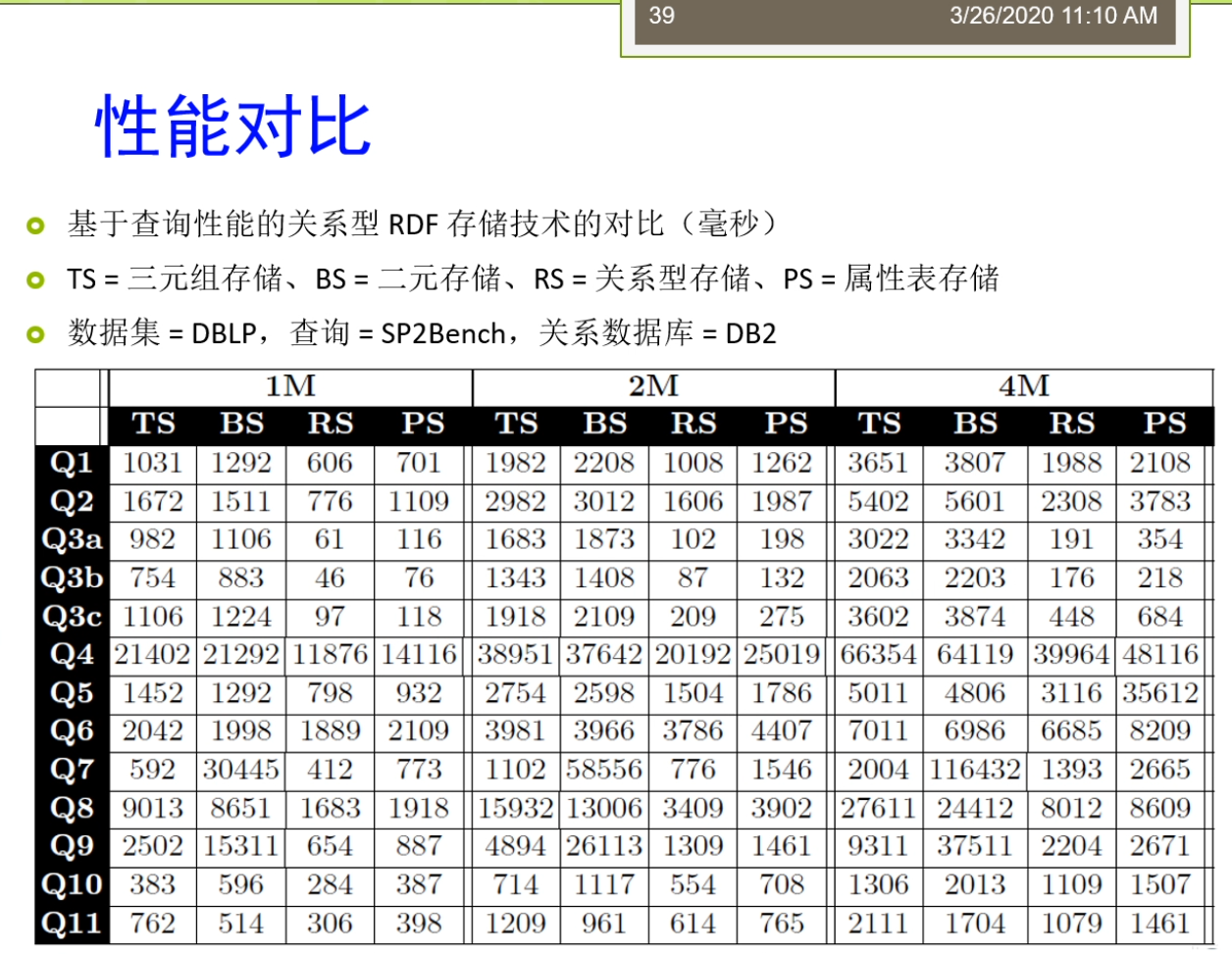


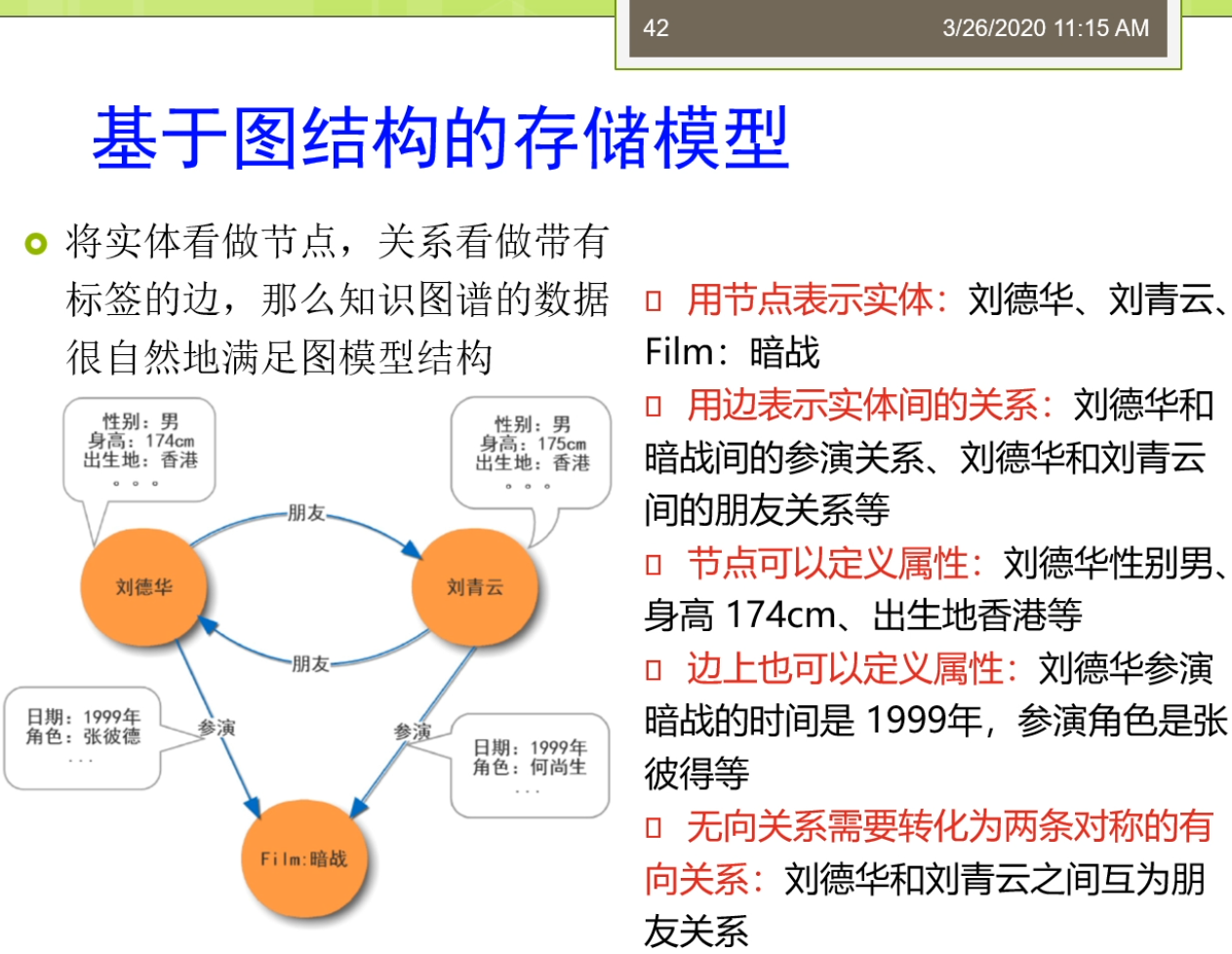







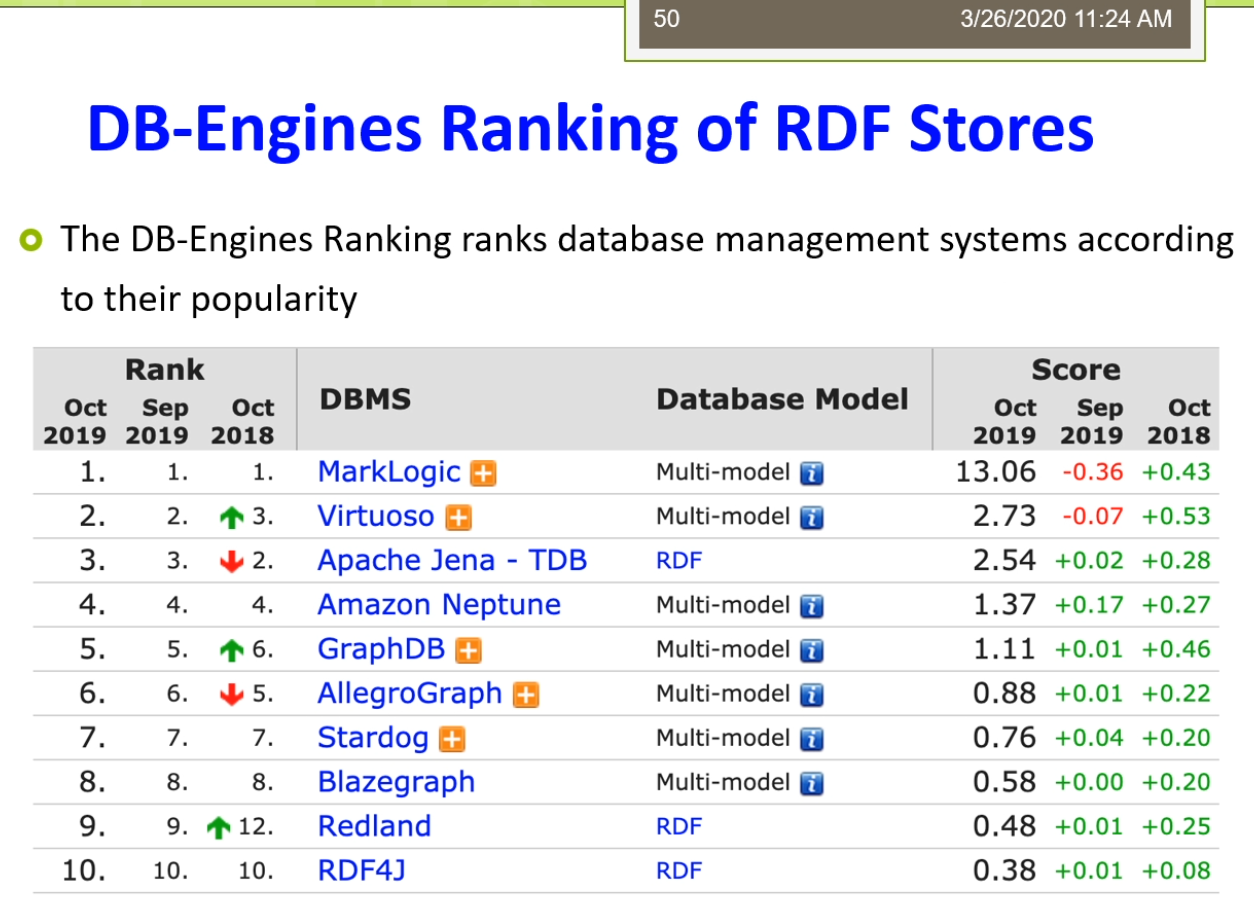



















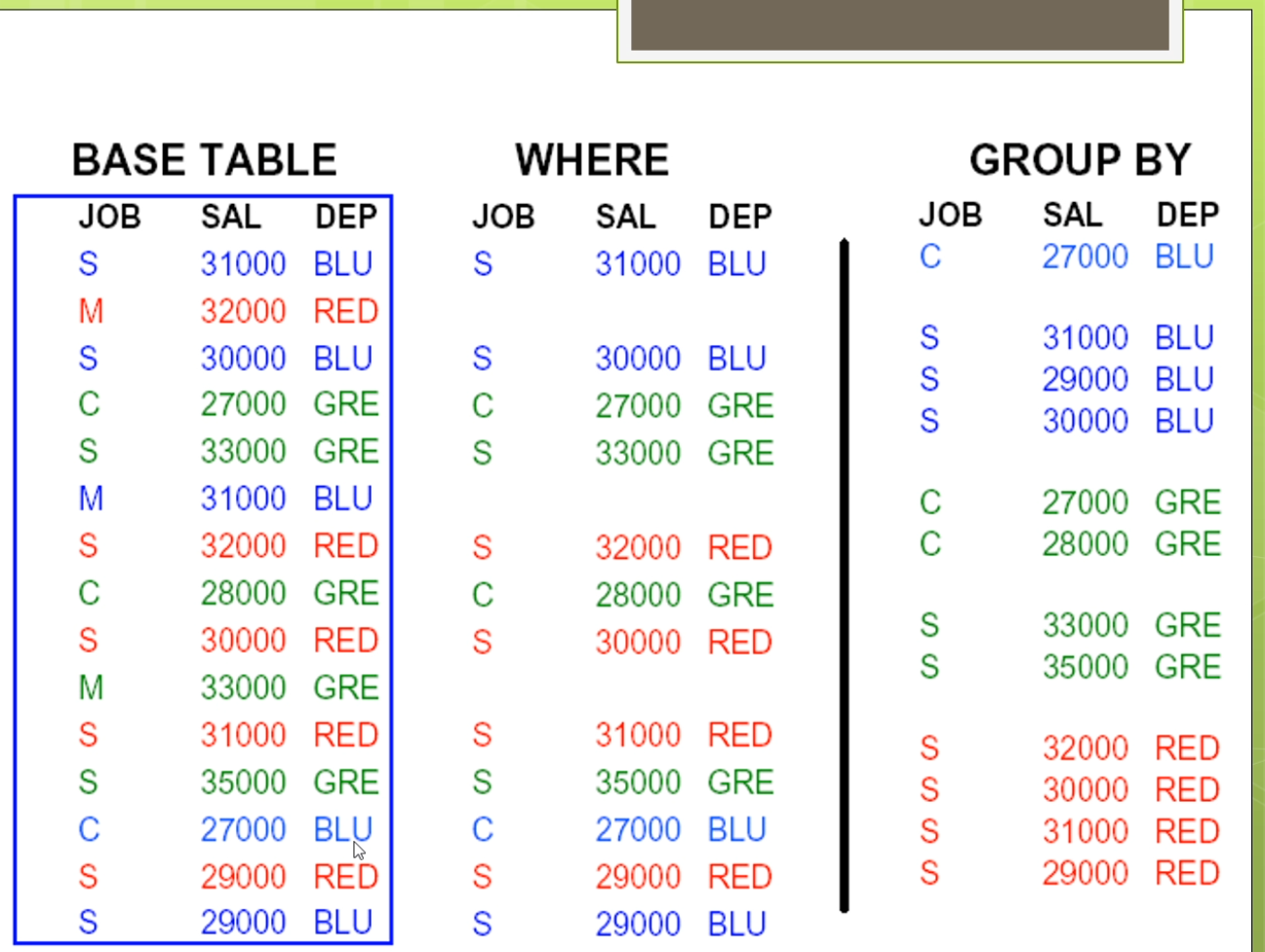



好,各位同学,我们嗯接着来讲。我刚才讲到了这个属性表,实际上来我们把这三种啊。这个这种存储的方式以及加上一个我们比如说直接在关系数据库里面去存储的方式啊。那么把它放在一起,我们可以来看一看我们这儿有没有一个这个比较。那么大家可以看到在这里我们呢这是我从别人论文弄建一个截取的这样的一个图。这个图里面那么他俩主要是基于查询性能的关系型RDF存储技术的一个队。这个里面的值呢都是以这个毫秒作为这样的一个一个比较。那么在这里呢,那么她列举了在十几个不同的这个查询,然后呢在不同的规模上,一个人是这个1M的,一个是2M的椅子,哥俩是这个这个4M。那么这样的一个规模上进行去做。那么这里呢气人死了表示的是三元组存储的方法。就是我们刚才说的垂直表。Bs的指的是水平表,就是我们刚才的二元存储的方法。Is的指的是我们直接来用关系数据库去存储的方法。最后来这个ps的射门,用那种划分的方法进行属性表程度的哦。准备这里让我可以看到很多的这个性能的这个比较。那么在不同的查询上,那么这个值了肯定是越小越好。那么意味着他的速度来越快。那么在这里面实际上有很多有趣的现象。比如说我们会发现,我们虽然刚才有三元组存储二元组存储属性表,就是我们刚才克再来讲的比较多的一些内容。这些内容啊,那么看起来他们都对啊df的数据啊进行了很多的设计。但是到头来大家看到在许多的查询上面,他们的效率还不如这个关系型的。所以呢这个是一个很有趣的这样的一个现象,也就是说尽管你这个查询的很多啊就优化了很多,好像设计了很多的东西。但是好像你对于这个性能方面的提升并不大。这是怎么回事啊?实际那这个里面呢有一些这个这个这有一些呢他的一些分析,那么这个里面我没放糖,但是那个论文里面这个讲了一些分析,那么最主要的一些情况是由于呢这个关系数据库啊,实际上她那还是有很多的这样的一个优化的措施。那么他由于这个关系,数据库已经发展了好几十年,那么相对来讲比较成熟。那么他虽然比如说在存储结构上并不是是很适合这个啊df的模型。但是呢他在许多其他的方面呢他进行了一些优化,使得在他的查询的效率还是很高的。对着这个地方来是大家需要注意。所以这个量呢也引出了我们说的一个问题,也就是说我们怎么样啊,应该怎么样去选择。这个id f的存储。也就是说我们到底用什么样的存储方法会比较好?这个里面了适当有很多的考虑。比如说第一个我们需要考虑的是这个应用啊,他通常他的一个数据导入的这个频率是怎么样?因为我们刚才也看到有一些方法数据导入的时候,那么是很容易的,比如说三列表,我直接很容易去导入。但有一些方法不容易,比如说我们刚才说的属性表的这个方法,那么它需要分析进行数据的划分。另外呢还要考虑比如说可伸缩性以及的导入的时间的带着那么有一些方法呢,他的这个数据量大了之后怎么弹的性能会比较低。第三个呢还要考虑的一个地方来是他推理的这个程度,我们前面多了。比如说有一些方法,那么在内存模型里面他可以很好的支持推理,但是呢到了我们做的这种离线的这种这种是持久化的存储里,并不是所有的这个现在的系统或者工具都能支持推理,只有少数几个可以。那么那少数几个如果你现在想支持推理的话,那你就不得不去选择那少数的钱。那么那少数的几个他使用了怎么样的id,f存储的方式,那么你就要使用这个牌子。另外还要去考虑的是未来你在查询的时候,那么这个它能支持怎么样的查询语言?那么最好来讲,那么是能支持w science的这个推荐标准才行。另外呢以及还有比如说他有没有特定的一些系统需求。比如说这个这个illegal这个graph这样的一个系统,那么它需要呢64位的这个处理器才可以去支持。这里奶奶讲的总体来讲啊,但没有唯一的一个答案,没有唯一的答案,他需要根据的应用需求了,决定了最佳的一种选择方案。所以这个地方了还需要的大家在实践中接的去这个逐步的去摸索。那么这是我们上面说基于的是这种表结构的这个存储。那么实际上现在呢还有一大类是基于这个图解做的。图解勾的存储时代也有很多的这个这个现在的工具软件,而且呢这些工具软件它不仅仅适用于我们说的啊df的这种图结果。那么还适用于许多别的东西在家可能现在比较注意到有时候我们有这个这个图数据库,从数据库来里面,那么像这个new for接啊等等的这些图数据库,那么它飞到了这个热门。那么实际上呢这些数据库他也能对RDF来进行这个支持。那么我们现在看一看,比如说第一个不是吧?基于图结构的这个存储模型是怎么样?在这个基于图结构的这个存储模型里面,我们会将来这个实体看作是节点。那么关系的看作是带有标签的这个边。那么这个知识图谱了他的这个数据啊就很自然的能满足了这个图模型的这个阶段。在家可以看到,比如说我们在这儿有一个这个图节点呢代表实体,有的在这个里面我们说刘德华,刘青云暗战等等的。他都是不同的节点。而且呢这些节点里面可能他还有个类型,有的刘德华,刘青云是个人那么而暗淡的是个电影。第二个呢,他们用边表示实体的关系。比如说说刘德华和暗战的关系的是一个叫参演的关系,而刘德华和刘青云呢是一个朋友的关系。那么大家注意这个朋友的关系可能还是个对称的,或者一个这个循环的这样子的关系。第三个这个节点呢它可以定义一些属性。也就是说,刘德华他有性别,性别的取值是男身高来说1m74,组成地点是香港。这些人他有相映的,这个节点可以带手机。而且这个边呢也可以带属性。有做刘德华参演了暗战的时间,是这个1999年参演的这个角色,但是脏比德那么另外呢这个里面我们刚才说的无相的关系,在我们的一个图里面,一般来讲刚才说的朋友比如说是个无降关系,他会转化成的两条有效的,对称的,有这样的关系。那么这样两项两条有向关系的,就是刘德华和刘青云之间的货物为朋友的家。所以总体来讲难的吗?这个就是我们说的一个图结构的对吧?存储模型这个模型大家可能会想到这个模型啊和我们原来的有个关系,数据库里面的这个亚模型适当也很类似。那么总体来讲呢,在我们这我们可以把它称为这个模型,就是叫节点。河边都带标签的这样一个模型,这个模型的也是一个比较常见的,也比较通用的一个模式。但是这个模型大家需要注意的是由于它的节点和彼岸都带标签,所以它比一般的简单图的这种模型来讲,他可能要稍微复杂一些。那么这个图数据库来那么它都是基于有向图的它的理论基础来就是我们做的图论。这个节点边把属性来都是这个图数据库上的这个核心概念。在这里节点呢用于表示实体事件等等对象给类比于关系数据库中间的记录或者数据表中间的行数据。比如说人物,地点,电影等等的都可以的作为图中间的节点。Rbna是指了这个图中连接节点的有效线条。用于表示了不同节点之间的关系。比如说我们做人物节点之间呢是这个夫妻关系,同事关系等等,都可以作为图中的边。而属性奶是这个用于描述结点或者边的特性,有做人物的姓名,夫妻关系的起止时间等等都是我们做的这个属性。那么在我们的这些系统里面,我们有许多的常见的这个图数据库啊。他的这个存储系统。那么最简单的来实际的或者最常用的一个不叫最简单是最常用的一个,那么是我们的称谓,一个叫what老鼠的这样的一个这个图数据库。这个我左手来他主要的是面向我们的RDF开发的。他是一个可伸缩的,高性冷淡。对象关系的这个数据库引擎。它提供了呢不仅仅是支持啊df了,她也支持这个SQL以及的这个XML的这样的一个数据库管理的功能。他支持了我们所有的linked data的茶存储查询的功能。常用于呢查询,存储,查询这个id,f数据。这个呢她的官方主页的可以从这来,好吗?在这个过程里面,实际上大家如果感兴趣的话呢,那么你可以把这个这个what我耍下载进行安装,那么它的配置呢实际上是在这个地方,是在这个,but also点,如果你是windows的话,那么他是这个这个等等的,那么它都是起了一个这样的一个配置文件,这个配置文件和这个一般的s这个my circle啊等等的配置文件都是比较类似的。你可以在里面来进行许多的设置,你可以来通过命令的形式把你的这个id,f数据啊把它导入进去。那么这个导入了实际上是很快的一个导入,那么它来进行的这个批处理,那么他来不是一条一条的数据的插入,而是把整个文件来进入到导入完之后呢,那么你就可以基于他的这样的一个查询的接口来进行查询。另外呢你也可以使用,比如说我们做前面提到的阿帕奇的那个艰难等等,去连接这个我主要做的数据库来进行查询。所以总体来讲呢,这个摩托说的它是一个面向这个id,f的。加一个图数据库,那么它的性能呢相对来讲比较搞笑。另外一个大家可能也比较常用的是一个叫new project。你要说进来是一个开源的这个图数据库系统。他将结构化的这个数据啊存储在图上,而不是表里面。这个理由破戒了,基于但是这个Java去实现了,它是一个具备啊完全事物特性的一个高性能数据库。具有的成熟数据库的所有特性,这个牛破解版又是个本地数据库。The又称,未来基于文件的那种数据还意味着在他不需要启动啊数据库的服务器。应用程序的不用通过网络访问数据库的服务,而是直接在本地的人进行操作。因此呢这个访问速度也会很快。因为在他开源,高性能,轻量级等等的优势来,这个妞for借了也受到了。这个你们可以进来,大家需要注意的是他是一个这个图数据,但是呢nu婆接来他有一个专门的插件。他可以去支持的我们的这个sparkle的这个查询。虽然本质上你要不借的话,你如果直接去用刘波借的这个查询语言,那么去查的话,你只只能能查这个图。我在这个产品里面而不能支持这个sparkle,但是呢有人给这个妞破戒了,写了一个sparkle的这样一个这个接口。一个插件,那么你可以来使用这个18口的查询语言了,就差这个牛福建里面的图。那么另外呢还有一些这个图数据库我们再来就不一一的这个罗列了,要么我们简单的看一看这个Orient的地密。然后hyper graph的db怎么还不回来?grab来呢嘛,它主要的这个优点来是它是基于一个操作定义。他不仅仅是一个图,他这个操作,所以呢他不仅仅允许一条并按指向多个节点,他还允许的指向其他的兵。这样来讲呢,这个Harper graph bb了,它比一般的涂了涂塑就过了,具有更强大的这个表示能力。另外呢还有这个infinite graph了,他是一个这个分布式的图书,对不对?还有呢这个info breed了是一个这个开源的互联网数据库,它有很多的这个插件等等。那么总体来讲了,和成熟的这个关键关系数据库相比这个图数据库来这个发展来相对来讲比较晚。相关的这个标准和技术的还不是很完善,实际中呢可能会遇到了这个很多的问题。Instead,你在选择这个数据库的实话,除了要考虑这个数据库本身的特性,性能等等。还需要考虑在这个数据库的应用性,技术文档的完整性。虽然这个地方来这个大家呢平时去使用的时候也要格外的去留意,有时候我们之前说到的这个摩托送那么这个摩托送来要不他俩因为这个时机打,就是比如说我们自己用的时候会感觉到还是挺好用的,性能蛮好的。但是他比较困难的地方就在于他的这个文档相对来讲比较少,而且呢因为在国内还相对来讲比较小众,中文文档更少。所以这就导致了你如果遇到了一些问题呀,可能呢就会这个比较难以解决。而这个牛头戒奶,那么因为现在用的人很多,那么所以呢你可能遇到一些问题了之后呢,你很容易带进查到相关的一些资料。所以呢那么可能他现在用的人那就比较多,人们攒一些钱。那么这里呢我们还从一个叫db engine ranking的这个地方我搜集到一个图。那么他是对于这个我这个啊df store他有一个这个排序,那么这个排序来是一个基于这个流行度的这样的一种排序了。在家可以看到在这个里面呢那么what我说了这个排名呢相对来讲还可以,这个是大概在2019年10月份的一个排名。我多说了这个排名到这个地儿那么接那的这个踢TVB了,那么排第三。我们这几个然后下面的都是一些graph的db啊,反正那么大家来可以看到。那么这个里面呢还是反映了一些这个流行趋势。因为呢还有一些这个考虑的现在比较多的,比如说这个分布式数据库相关的分布式的存储。在这个过程里面就有查询的效率,有多通讯代价,存储空间的利用率,可扩展性啊等等各方面的一些问题。在这里,因为我们这个课来关注点不是这个分布式存储,所以呢




