https://www.bilibili.com/video/BV1VZ4y1x7MP/?spm_id_from=333.788.recommend_more_video.12



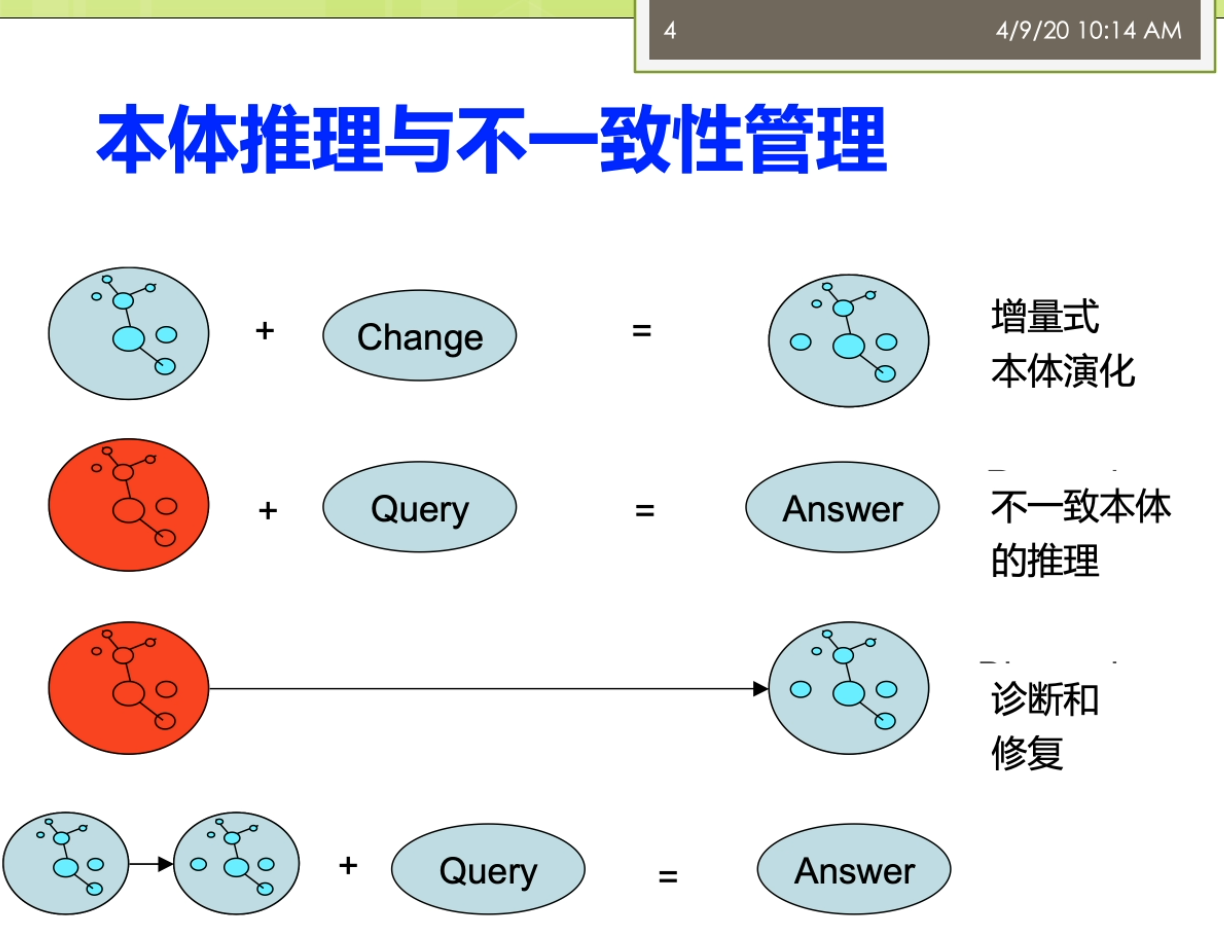















各位同学,我们开始这个呃上课了啊,那么今天呢我们开始讲一个新的章节。称未来就要这个基于本体的知识管理。那么这张呢主要嘞我们会讨论一些相对来讲啊这个知识管理过程中间的一些这个问题。那么这里呢我们还需要注意一下。就是我先讲两个事情。第一个呢就是我们这个课来其实我们跳了一章,还有一个第六章专门讲逻辑推理的这一这一章。那么这一章的内容呢我会那个在开学之后呢我会邀请这个呃我们系的李延辉老师,那么给大家来专门去做一个这个专题讲座,那个李老师来,他是这个专门做和这个逻辑推理相关的这个研究的一位老师能不能在这个逻辑推理方面的有比较多的一些经验?那么所以来那么他俩给大家到时候去专门上一次这个课。那么为什么不在线上呢?那么主要的原因是因为他那个客人会有一些相应的一些板书。那么会给大家来看一下这个逻辑推理的一些过程,所以在在这个网上上课了,这个呃不是那么方便。所以来这个到时候来我们把这个次序调了一下,把他的课来放到等等到我们正式开学之后来那么专门的去去讲。那么这个是一个事情。第二个事情呢是我们的这个呃课堂讨论的这个论文和分组来的吗?我刚才来已经在这个呃我们的那个教学立方中间公布了,那么大家来需要这个两个人一怎么返回来自己的这个学号和组员的学号,以及包括你们两个。聊这个分组的。那么第二个来是关于本体的学习,那么也就是说我们怎么样?这个去自动化的构建一些本体。那么之前呢我们的课堂讲过一些。关于这个使用这个比如说斯坦福的七步法,使用这个party这个软件去构建这个本体。那么也有一些工作的考虑,怎么样从一些这个知识源知识来源里面自动的去抽取这个本体。自动的构建本体。对这部分的事我们也经常会讲到。第三个了么会讲到一些。如果我们有了很多的本体的知识之后,我们这个本体的知识他到底长什么样?那么十大这个来有一些关于与以往的图结构分析方面的一些内容。那么后面呢我们还会讲到基于语义的面向服务的一些体系结构。那么实际上呢这个部分的那么主要的是和这个Web service相关的内容。最后呢我们还会讲的一个更大一点的概念,称为那叫这个万维网科学。那我们说的这个语义网等等的,实际上都可以归纳成这个万维网科学中间的一个研究问题。哦,我们来进行今天的这个第一个部分,关于本体推理和管理方面的一些相关的内容。那么这边的主要的我们会涉及到几块,包括了什么是本体的推理和管理。那么以及呢在这个里面涉及到的几个技术上的这个难题。第一个来是一些不一致本体的这个推理。也就是说我们的本体啊它不见得一定是这个一致的。也就是说这个本体里面可能会出现一些矛盾的东西。那么在这种矛盾的场景下,我是不是能可以的去做一些和推理相关的一些动作?那么是不是能退货?因为我们实际上可以大家可以知道,如果这个本体里面他逻辑上存在一些矛盾的话,那么他很可能他是不能推出一个真正的结果,因为我们从这个我们在离散数学里面大家学过,如果这个钱键为假的话,那么我推出来的这个结果实际上是这个总真的,所以这种情况下,那么我们怎么样在不一致的本体上是不是能取得?比如说一个比较小的一致的子集,在他上面做推理。这个呢就是一个研究的问题。另外呢还有的涉及到的是这个本体了,他可能会不断的演化,他会有多个版本。那么这个多个版本的这个本体我是不是能进行一个推理以及这个多个版本的这个本体啊?他怎么样进行管理?实际的来这个也是我们这一章这一小节会讨论那些内容。最后呢我们还会讨论这个本体的一些修改,本己的演化方面的一些问题。好,我们首先来看一看本体的推理和规制管理方面的一些内容。那么整体上来讲呢,我们可以把整个的这个东西分成这几个不同的这样形式。第一个形式,我们把它称为了叫增量式的本体演化。也就是说我原来有一个这个本体。那么这个本体来是一个我们这儿用一个这个亲颜色表示的是它是一个一致的本体。而这个红颜色表示这个本体的有问题,他有不一致性等等。那么这个对于一个正常的问题一个一致的本体来讲,我可能会通过一些在使用过程中间发现的一些修改。所以我会增加一些change,一些改变。那么把它变成一个新的本题。这个过程呢我们把它称为了叫本体的演化或者的是这个本体的增量式的这个修改。也就是说我把一个一致的本体通过一些变化变成了一个新的一致的问题。那么第二个我们把它称为了是一种这个不一致本体的这个推理。那么这个推理的过程把它建模成的一种这个查询并获得答案的这个过程。而在这个过程里面,我们说我们的本体可能是一个不一致里面出现的一些矛盾。或者一些错误,我是不是能在这个推理的过程中间我依然能做。能进行这个推理,获得我想要的答案。又或者我不是在这个不一致的本体当做推理,而是我想把这个不一致的本体把它修复。也就是说我给另一个本体,我能不能识别出这个本体是不是很赞。不一致性。另外我这个不一致的本体我能不能有方法通过一些改变。使得它这个修复层的修复之后,那么变成了一个一致的问题。那么最后一种我们可能说是在整个的这个本体他的一个演化的过程中间。他有多个版本的这个本机上,我是不是能做这个联合地推?那么这些都是我们说和本体推理与不一致性管理呀。相关的些内容,我们用一个图的形式可能比较清楚地展示出来他们之间的一些不同。那么我们说这个为什么会产生不一致性?那么这里的实际上有很多的这个原因。那么最主要的原因呢是由于我们说与以往的一些特点,渔网首先它的这个数据的规模很大。他是整个酱类似于互联网或者我们平时坐在万维网一样,那么他数据了,这个来源很广,他是一个分布式的结构。也就是说所有的人,所有的这个组织都可以在这个万维网雨衣网上发布自己的数据。那么这时候实际的多个来源的数据啊,那么自然就会产生了我们做的不一致性。那么这些问题的那么很难避免,因为这个和渔网自身的这个特点相关。你并不能要求说与以往变成一个集中式的。所以呢那么这个不一致性的值当是一个长期存在的问题。而我们只有使用一些这个方法来尽可能的去解决这个不一致性,而不能要求来这个与以往说没有公布之前。那么我们说这个本体。那么在这个语音往下面他为什么会产生一些不一致?那么这个地方呢他身上也有很多相关的一些原因。我们这里可以看到,比如说第一个原因是对于一些默认值的一些处理的错误。那么这个实话我们说这个默认值的处理的时候了会产生一些问题。比如说我说数据库里面,我们现在假设从数据库里面把一些数据提取出来。那么这个数据库里面经常会有这个闹这样的一个值空值。那么这个空值我在这个语义网里面怎么样去处理它?实际的这个时候处理了就会发生一些错误。
二手处理了就会把这些错误第二个可能是的一些一词多义的一些现象,比如说我们说有一些这个词,它在不同的上下文环境下它可能会有不一致。那我在构建本体的时候,由于没有清晰的度量,这些不一致,没有把它区分开来。那么就会导致了我们做的一些错误。比如说我假设我们现在有一个这个处理。比如说我们现在这个有一些这个单词,那么它呢在这个上下文里面有的地方她比如说是apple的吗?你家吃了几个apple,他有不同的含义。那么这个含义有的时候它可能是苹果公司,有的时候呢是我们错在这个水果。那么这时候你在构建本体的时候是不是有这个不同的一些表示的方法?那么通过不同的URI把它区分开来,如果没有区分呐,那么我们说可能我多个本体一起使用的时候,就会产生了一些矛盾。那么第三个原因呢是由于我们可能是从另一个知识系统里面迁移过来。另一个知识系统里面由于表达能力,或者表示的这个语言和我们的这个渔网里面的这个本体。或者基于owl的这个描述逻辑的这种形式来,它不是完全兼容。可能呢就会导致处理的时候来产生一些错误导致的一些这个不一致性。最后呢还有可能呢是因为我们想集成的多个数据多个数据源里面,那么它对于这个数据的建模方式不一样。存在的不义之行。最真里面的实际党会产生本体中间不一致性的这个原因啊,很多很多。这个很难呐,这个这个把这些问题呀都通过之前的一些规范来解决掉。那么比如说我们先说我们再扩展一下,我们向这个dv p列这个本体里面。那么他就会有一些这个特殊的方法去避免一些规定执行,比如说我们说啊这个人的身高,那么人呢这个身高这样的一个属性这个属性的时候,一般来讲我们再一个比如说假设我们在一个数据库里有着这样么国内的一个数据库里面,那么比较容易想的,大家都是按照一个米或者按照一个厘米的方式去写。但是呢比如说我们以这个美国为例的话呢,那么美国他那边人呢会讲这个多少英尺多少英寸这样的一个方法。如果你在这个设计这个本体的实话你没有注意到,那么就会产生的一些默认值的错误。你默认他是以这个厘米的方式或者以米的方式去处理,但是你获得的这个结果上并不是。这时候就会产生了一些对于末日之处理的错误,那么在dv里面,那么他怎么做的?他实际上是把这个属性以及他属性的取值在属性名上进行的一个显示话,也就是说他把一些属性啊认为这个属性呢是有做,我们说身高这个hate it来,然后cm。表示的是以这个厘米方式表示的,而这个hit的这个in inch这样的一个英尺的这个方法来,那么是表示的它的这个美式的这个表达方法。他通过这种显示的属性的定义了来避免的我们说的一些特错误的。这个默认值的错误,所以这个地方来要很小心,如果呢你不不是很留意啊。不是很注意的话,那么很有可能产生的一些默认值的这个处理货。那么我们再来看一看,比如说我们现在还有一些默认规则错误处理。导致的一个呗致敬。比如说这里我们有这样的一个例子,大家来来看一看,我们用了一个这个描述逻辑的一个方式去写了一下。你看一看你能不能比较容易的去看懂关于这个风流的这样的一个一个本体在讲了一些什么样的内容。我给了这个大家的这个呃一分钟的时间,大家来看一看。这个牛它是一个食草的动物。第二个嘞,他讲了这个风流应该是刘东间的一种。第三个呢,他又讲了风流呢,是吃了这个羊的的脑子。实在是哦,原来大家应该来基本上这个呃看了一下这样的一个东西。那么这个例子里面讲了一个什么呢?第一行他讲了这个牛,他是一个食草的动物。第二个呢,他讲了这个风流应该是刘东间的一种。第三个呢,他又讲了风流呢,是吃了这个羊的的脑子。实在是养老。而羊呢又是一种我们做的这个animal是一种动物。那么但是这里面我们说这个食草的这个动物啊,食草的这个vegetarian。他实际上定义的是怎么来定义的是他不吃任何的动物或者动物的一部分。而这个brain这个脑子呢是这个动物的一部分。所以这实话实际上我们就会说,如果我们有一个具体的the mad cow。一个具体的这个刘峰刘来讲,那么这时候我们要做一个就会产生了一个错误。这个错误就是因为我们一开始说这个风流的,他应该是你的话就留来讲,那么这时候我们要做一个处理的话。就会产生了一个错误。这个错误就是因为我们一开始说这个风流的他应该是吃草的。然后呢但是呢呃这个牛应该是都是吃草的,所以我们推出来这个风流应该也是一个吃草。但是呢这里有没有说的风流的,他实际上是吃了这个动物的一部分,还有不是吃糖。所以这时候就产生了一个矛盾。这个矛盾的他的原因就是由于我们对于一些默认规则啊他处理的一些错误。我们有的认为所有牛都是这个吃草这样一个默认的这个规则导致的,我们有一些这个例外情况出现。比如说我们还有类似的例子,我们说比如说所有的鸟都会飞等等的志向,一些例子都是由于一些默认的规则来。错误处理导致的这个不一致性。我们还可以看一个类似的这个例子,有赚,我们这儿有一个dice的这个本体,这个奶是这个一个生物医学的一个本体。这个本体里面也讲到了,我们说这个这个brain他是哪一个中央神经系统中间的一部分。然后来说这个brainer也是身体的一部分。而这个中央神经系统呢是神经系统的一个部分。但是呢又说这个身体的一部分,那他不属于这个神经系统,那么这时候又出现了一个矛盾,也就是说这个brain到底来是不是属于这个神经系统?这时候就会出现了这个矛盾,这个例子的更简单一点,很容易去看出来。因为我们做不认识这个body part,然后呢他不属于这个neural net那个neuroscience system。I got pregnant有属于这个central neural system又属于这个牛肉sister。这是后来就又出现了我们做的一个矛盾。那么这里我们实际上说如果我们有了这个规制性,有了这个矛盾。他迟到会造成的一个事情就是我们传统的这个推理的这个过程嘛。他会踩着一个爆炸性也就是说因为我们说如果前提p和这个飞屁,那么他实际上来都可以推出任意的这个结果,前提是假的话。那么就可以推出任意的这个故事。所以任意的一个换句话说就是任意的一个公式,都是一个矛盾的这个逻辑结果。那么这种情况下就会导致的我们的一个爆炸性,也就是说我们如果对一个不一致的本体,使用一个标准的生成的这个结果可能呢他的结果非常非常多,而且这些结果呢是完全没有意义。这样的一个过程实际上就是我们说的这个不一致性导致的推理的这个爆炸推理存在任何的结果,而这些结果并没有任何意义。对这个情况下就带来了我们做的一个挑战。我们怎么样在不一致性下?因为我们刚才说到这个不一致性啊,它是一个长期存在的现象。怎么在这种不一致性下面怎么样能尽可能做到一个有意义的推理的过程?
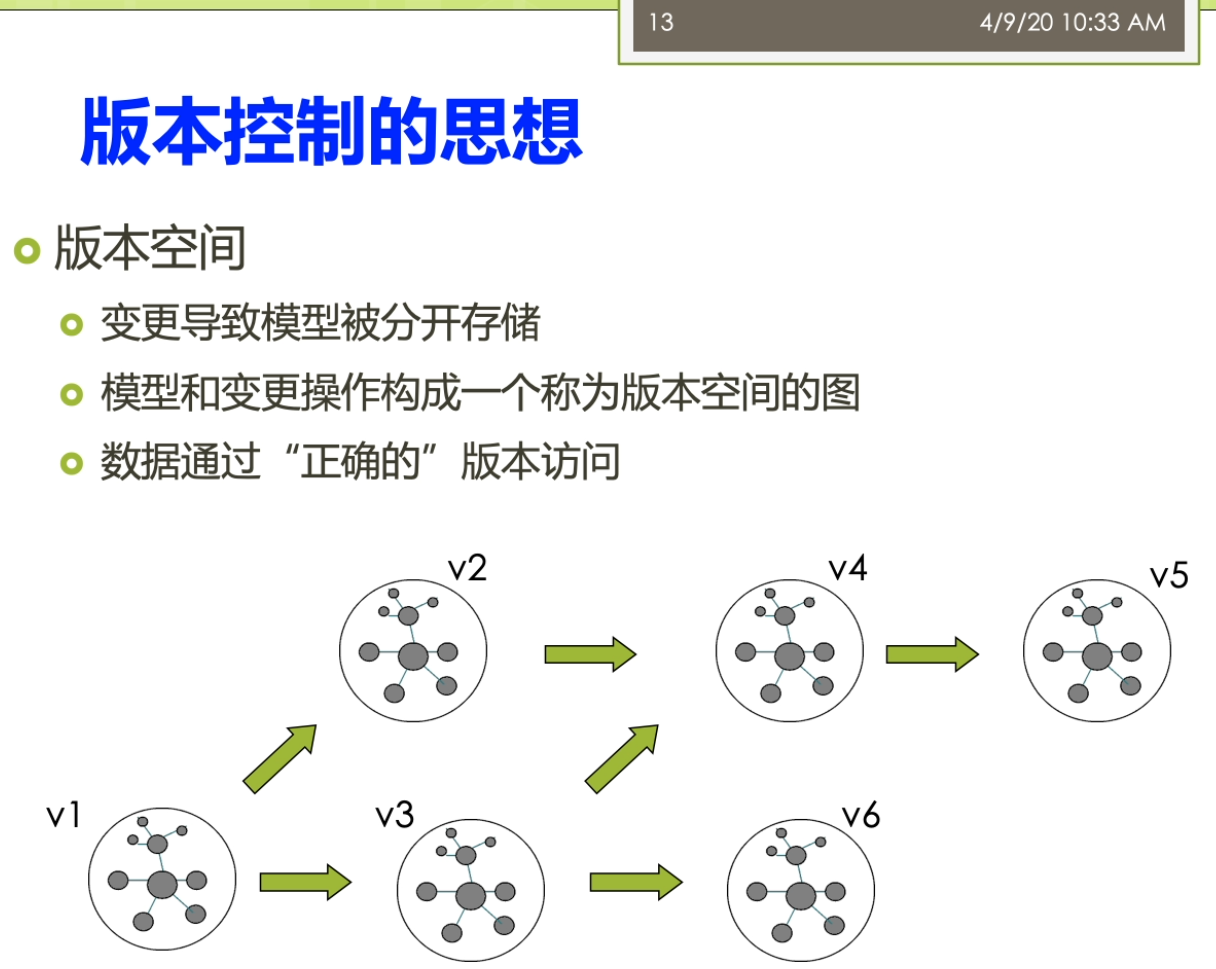
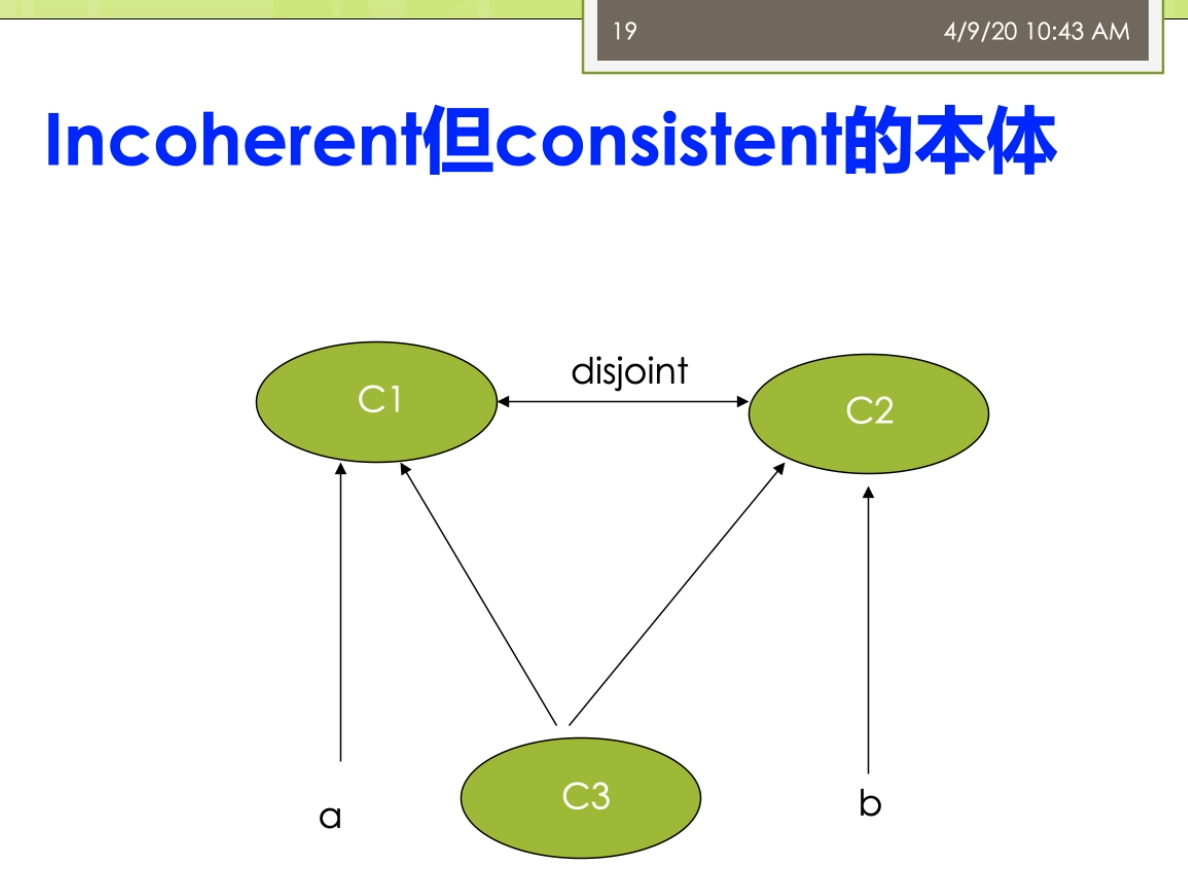
那么我们就来说为什么我们做一个描述逻辑的这个推理过程啊,不能避免刚才不一致的这么现实。因为咧,我们说这个推理检查他通常呢使用的一个可满足性的这个检查。I我们推理的这个算法,这个tabular的这个算法,那么它是基于一个可满足近检查的这个方法。那么他并不能去检查,我说刚才的这个概念层次上是不是出现了一些矛盾?它只能按照们实力的进行一个推导,这个tablets的算法来载我们上这个后面的课,就是这个李延辉老师给大家上的课里面。会专门讲的。那么这个算法来你可以把它简单的理解成,那么它是一种这个穷举的方法。他顺着每一条这个可能的推理的路径进行这个群一直找到了其中某一条路径,可以满足我们做的这个最后的这个增值。如果俩能满足,那么就表示这个推力的完成。那么在这里那么有很多的一些技术啊去尝试去处理这个不一致性。怎么找其他有几块,第一个来包括不一致性的诊断,把这个修有多早带这个2003年的怎么就有这个工作了?进行了一个本体诊断的。他去通过一个方法去看一看我的这个本体里面到底有没有这个不一致性。如果有了这个不一致性的,我来就把他了这个小组的。那么消除掉之后我是一个一致的这个结果一致的本体了,那么我在他上面做推理的就没有问题。而另外一种思路了,实际上是我不尝试着去修复这个本田,我还是用这个不一致性的这个问题,但是呢我的推理方法来能容忍这个不一致性。也就是说我不会来产生这个爆炸不会产生的无意义的结果,我尽可能的还是在这个不一致的这个本体上面。能推理出来有意义的一些结果,那么这来又分为了很多的不同的一些相关的一些这个研究了。包括了这个部分的这个一致的逻辑,受限的推理,近似的推理。资源受限的推理以及但基于这个关联度的一些信念修复的一些相关的技术。那么这些技术的那么实,当大家可从这个发表的年代感实际大已经有相当的一些年头。那么表明呢这个方向啊很早的时候呢就有许多人的进行了一些关注。另外呢我们说还有一个问题就是我们做本体啊,它会在不断的进行这个演化。那么这个时候我们就产生了一个叫多版本控制的。因为这个版本的某一个版本本体开发出来之后,那么并不是多态一定可以竞赛进的。所以呢这个时候呢我们就需要这个对本起来进行新的一些更新。更新完之后就形成了一个新版的问题。那么在这个过程中间呢我们就会产生了不同的版本。那么在这个版本控制的过程中间就要考虑了几个问题。第一个问题是这个变更的这个恢复。也就是说允许这个开发者撤销或者调整变更来避免意想不到的一些影响。这个方面的实战就类似于大家,如果你现在去开发这个程序的时候,你用会用到这个下这个地图,像这个SVM等等的一些版本控制的软件一样。这些软件呢会把这个多个版本保留下来。那么如果来新的版本有问题,你还可以来退回到这个旧的版本上。他进行一个相应的一个版本控制。而另外一个呢在我们的这个本体推理的这个过程中变得那么他还要考虑的另外一个事情,但是这个资源这些兼容性。那么这个兼容性的这个表现带来这个本体的使用者他可能去选择一个占用更少资源的一个早期版本,可能这个早期的版本的这个本体的相对来讲比较少。而不是来一个占用的更多资源的一个新版本,因为新版本的在这个旧版本上面由于一些调整啊等等,它可能会变得更加大。所以在这个兼容性的也是一个他们考虑的一个问题,在这个多版本控制你。那么这个版本控制的思想实在是比较容易去理解,我可以看到,那么在这个里面最主要的就是我们可以去建立一个称为叫版本空间的东西。那么在这个图里面我们最早有个危机的这个版本,那么这个唯一的版本的会变成一个v二版为300,然后呢v二,v三板的有可能有的变成了为600。或者v二,v三的合并又形成了各位400右眼画出来这个位置吧,真的。这个变更的在这个版本的空空间里面这个变更呢这样就导致了我不做模型被分开存储。不同版本的这个模型啊,本体的这个模型呢有不同的这个存储。而模型和变更的这个操作,也就是说我们这里的箭头是变更的,这个操作构成了一个称为了版本空间的这个。那么这个数据呢他可以通过了正确的这个版本的去访问给这个版本控制的这个思想,在这里我们来这个实际上没有多的太多了,需要讲。你如果来知道一些这个软件上面的这个版本的这样一些相关的软件,你用一些实用的经验之后呢再把这个版本控制价,我们这上是类似的一个东西。那么这里如果你去对版本想对控制的话,那么你的一个思想就是我可以这个管理员能够对呀版本空间去提问。然后呢我可以进行一些这个组合的推理,比如说这个推理里面我可以的用不到这个模态逻辑相关的一些东西。那么把每一个空间的可以看见的是这个一个模特。我还可以的,有一些原则,我做每一个本起来都是一个可能的正确的这个世界。而撞一个状态中间的这个声明的争执都是由这个描述逻辑的这个推理机的去确定。对这个版本的管理的这个过程呢就是这样的一个过程。那么另外两门还可以看看,比如说对于不一致性的一个修复和诊断,这里来有一个这个圆形细的叫Dio的两个系统。那么他呢主要的功能就是我给定一个不一致的这个本体。我去定位了可能不一致的这个源头,把这个提供给了知识的工程师来修复它。那么在这里呢,那么他使用的一个叫pin pointing的一个技术去定位这样的一个源头。但是这里需要大家需要注意的是,实际上这个修复啊并不是一个这个很容易的这个过程。也就是说这个推理的这个过程啊,他并不是很容易能定位到准确的某一条三元。做我们这条三元都写错,你觉得我们刚才看到的这个疯牛病的这个例子里面,比如说你很难去定位的是由于我说这个风流啊都是流血错了,还是留待是这个食草动物写错了。而做这个风流,但是吃这个养老的写错,实际打这个不一致性啊,他并不是由于某一条这个语句导致的,而是由于它整体上的有问题。虽然这个和我们在一般的软件里面的这样子一个debug的这个过程啊不太一样,软件里面大家可能会用到一些第八个的相关的一些功能。这个功能呢它可以通过运行,然后后来找到相映的自己的这个出错的这个位置。但是呢在我们这里这个本体上来,因为它是一个整体的推理,是一个整体的过程。那么很难真正的定位到一个具体的位置,一定做,只要你修复它就可以。但是在这里可以尽可能的去缩小这个空间,也就是说我可能知道在这样某一个局部可能是有问题。把这样的一个问题来提供给了这个知识工程师进行维修。那么在这个过程中间呢,我们实际上来比较希望大家可以买这个理解的来是这样的一个这个几个概念。我们之前这个讲过了,这个题box提box制止的事,我不做概念车的一些东西,而a box来着的是我们做的这个实力才在线内容。你就是说比如说一个学生是一个人,他就是个替box的定义,我到张寨那是一个学生,那么他就是我做的a box。这两个词从这个语义上来这个中文的很难去把它准确的这个翻译出来。那么我们这儿来就还是用它的英文形式去讲。我不说t box中间不可满足的概念指的是我在这个t box的任意的这样一个解释。对于这个解释啊他都是为空的。他没有存在一个不为空的这样的解释。而我们说incoherent的这样的一个替fox十大是存在不可满足的这个概念。
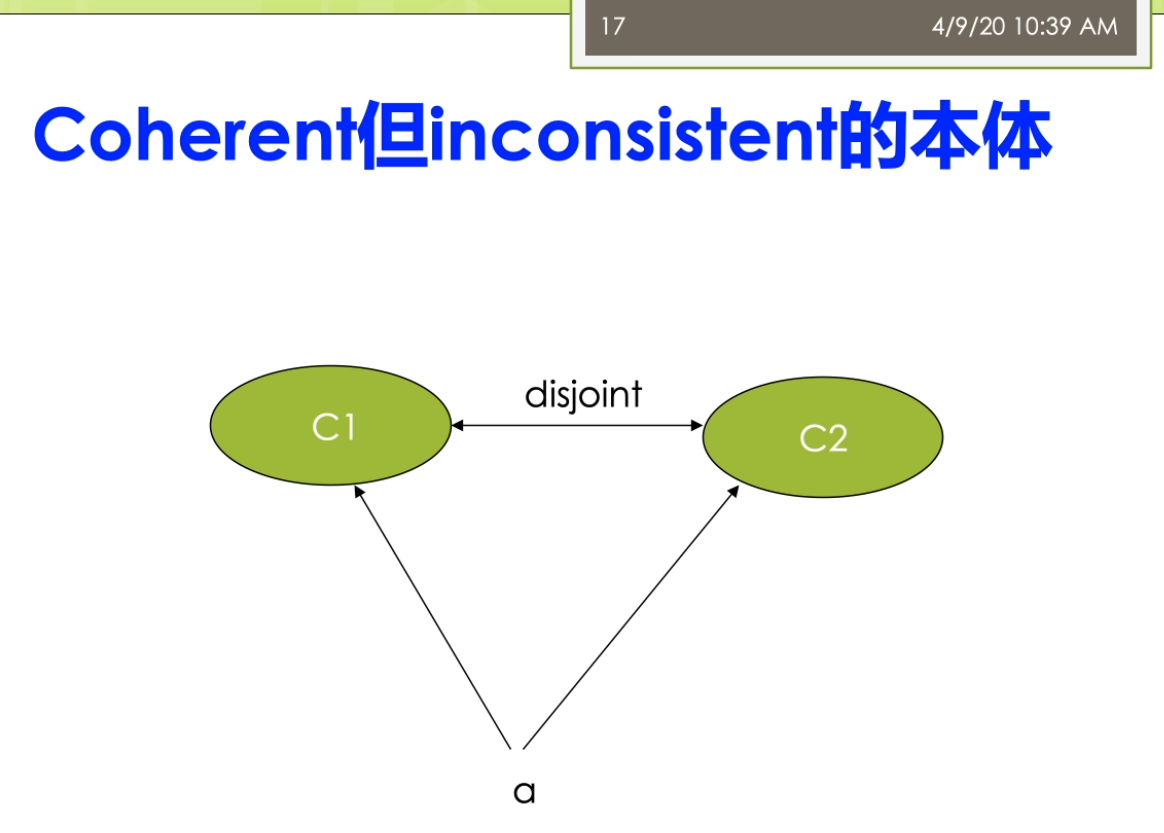
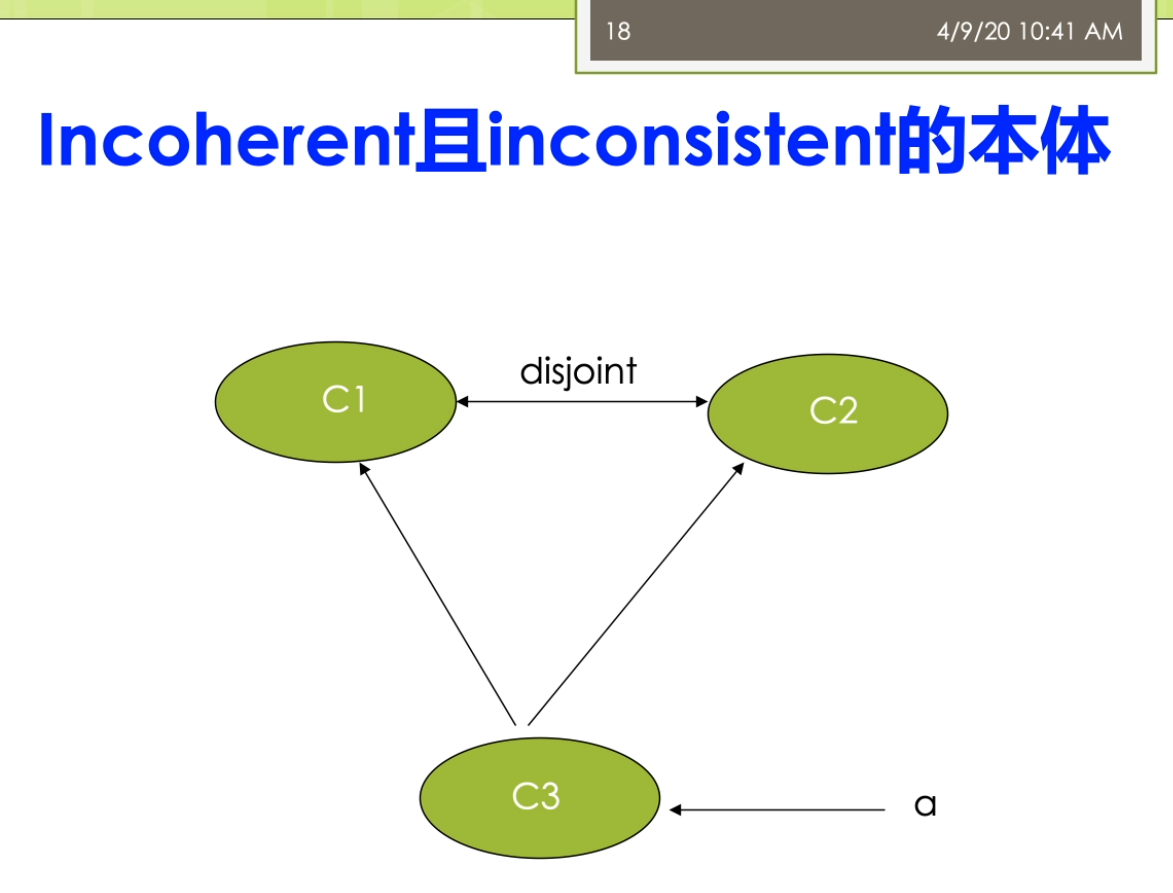
一个不为空的两个解释。而我不说incoherent的这样的一个t box时,大势存在不可满足的这个game。啊,incoherent ontology的就是说整个的这个题box是一个t后口亨瑞。进口Henry。R,另外呢inconsistent了,那么侧重的是底层的一些这个数据层,侧重的是a box。他指的是不存在的一个具体的一个模型。这个地方来教的讲的有一点点这个抽象,我们来看看几个例子。在这里第一个例子上面我们说它是一个称为叫口heron的。但是呢,inconsistent这样的问题。在这里我有两个概念,一个概念的称谓来叫声一一个概念的教师要我说c一和c二是destroyed这个不相交的关系。那么这个定义呀实际上带着个t box的这个层面在这个概念的层面上,那么他是没有问题。你就说我说这个student和teacher是这个不相交的。那么单看了这条语句没有任何的问题,但是他是一个inconsistent。意思是我已如果有一个实例,我有个a,我说a了,他既是c又是谁呀?比如说我们说a,那他是一个在职的研究生,这个在职的研究生啊,他可能同时是一个老师,也是一个学生。那么这时候他就产生了一个叫inconsistency。因为我们见面说c一和c二是一个destroy的这个关系。那么destroyed的关系导致了我们说a他不可能同时是c一的实力,又是car。对这种现象,这个例子里面把它称为在校口current,但是inconsistent。在我们再来看第二个例子。第二个例子,他是一个incoherent并且inconsistent。让一个本体。在这个例子里面大家比较容易看到了,我们说c和cr是destroyed。Rc三所我是c一的子类。我也十来c二的资料。这时候就出了一个问题。我们说c一和c二他是不想交的,那么c三怎么可能同时是c一个子类又是c二的词。除非来这个c三是个控制。啊,因为c三他是一个incoherent,他出现了一种不一致。那么我现在有一个a下一个实例,我说这个诶呀他的类型是c三。这时候我们又涉及到了a box的问题,那么这时候他又是一个inconsistent。加一个表情。对这个例子里面,我们说他既是incoherent又是了这个inconsistent。它是两种不一致性,都在这儿都存在。第三种呢,我们把它看成是这样一个懒觉,incoherent的,但是呢是consistent的。这个例子里面比较好理解了,我们刚才说的c三是有问题的,c一和c二是不相交。C三,那是c一和c二的同时是他们的子集,这个c三呢肯定是不成立的。但是呢这个并不妨碍我说a这个实体这个实力它的类型是c。B打的是这个类型的是c二,这个呢并不妨碍。所以这个地方呢我看出来他只有在这个概念层次上面出现的这个冲突。而在这个实力的这个数据层上面,他并没因为我们做a,它的类型是cb,它的类型是c二,这个一点问题都没有。所以这个例子反应的他是一个incoherent,但是consistent这样一个问题。哦,我们前面两个大概看了一下关于这个本体推理和管理方面的一些相关的一些例子,相关的一些基本的概念。我接下来看一看第二个方面就是关于我们说的本体学习呀这个方面的一些相关的这个研究。那么这个本体学习的这个过程的大体上来讲啊,它主要包括下面的一些步骤。第一个步骤是要搜集,选择和预处理这个语料库。语料库来就是我们做的数据的这个来源。那么你需要对于这些数据进行一些预处理。第二个本体的这个学习的过程中也需要发现一些相关的单词和短语,这些相关的单词和短语,比如说我们可以通过自然语言处理,里面的很多技术在这儿可以用。比如说我们可以用到的是这个命名实体识别,我去识别出来一些关键的这个名词。那么我也可以来用一些这个关系抽取的方法抽取出来一些主要的关系等等。因为第三部呢是在这个领域专家的这个帮助下,对这些术语来要进行一些确认。看一看这些术语,它到底是对的还是错。也是不我就发现了这个术语之间的语义关系,并且来扩大数与集合的这个规模。那么这样子的使得我的父本体学习的这个覆盖面很强。第五步又重复的去让这个领域专家。在他的帮助下,对新增的术语和关系的又要进行确认,最后呢第六部了要产生本体的一个形式化的这个表示。所以整个的这个本体学习的这个过程的就包括了这六个不同,对吧?你可以把它认为跟我们之前讲的斯坦福的这个七步法来讲。那么实在是很类似的这个过程,对吧?主要来讲也是一样,我说我要去明确一些范围,然后来进行一些术语的定义。那么在这块里面呢,他是要包括了我说的类的定义,属性的定义,打过来这个约束的一些定义等等的这些东西。那么另外呢它也是一个迭代的过程,他会不断地进行这个扩大,并且来请让这个领域专家进行也确认,最终担心这个问题。那么这里呢有一个需要注意的,比较有趣的现象是做人们呢往往选择已有的这个语料库。或者这个外部来进行这个本体学习。但是呢反过来的研究很少,也就是说很少有做为了学习这个本体而去构建相关的这个比较苦。所以这时候也就是说那么他很少去考虑啊怎么样去构建一些合适的这个语料库。不过这个呢大家也很容易去想象,因为我们说这个大家呢语料库来在真实世界里面是比较多的。比如说我们说外部网页的这个文本是他是很多很多,对吧?这个里面比从他里面学习出来这个本体是一个比较自然的一个需求。而比如说你无论选某一个本体土豆么,为了学这个计算机这个领域的本体。然后呢我要去构建计算机里这个整个领域的语料库,这个似乎了不是很自然。但是得需要注意的是,我们选择了一些这个语料库,特别是现在由于了这个概念啊关系等等的,往往都蕴含在文本中间。这个语料库的相关度和这个噪声啊对于本体学习的这个质量了是有着很重要的这个影响。因为如果来你的这个语料库有偏的,也就是说他这个处理的时候他不是完全针对你的需求。另外呢它里面的存在大量的噪音数据的话,那么都会导致的你的这个本体学习的这个过程不是很好。那么在这里我们从本体学习的这个内容上看来,这主要会分成几种。一种来说,我们做的术语的获取,一种来说我们称为的关系学习这两个不那么这个术语的获取的是在自然语言处理,特别是计算词典边度学中间的得到了很深入的研究。这个里面呢那么有很多很简单的自然语言处理的技术,再比如说我们刚才说的这个命名实体的识别就是其中一个很重要的一个基础。那么第二个方面呢主要是素与之间的关系的学习,比如说等价seamless。你则这样一个父类子类,帕特不是组成部分为雷霆的粗粮这个相关等等。那么面向于万物本体学习,他们的学习这些语义关系实际大了,也是面向本地与外部的这个面向于外部的本领学习的下一个研究的动力。儿童本体学习所利用的这个资源上看,它实际上主要的有很多很多,包括了自由文本或者俩这个Web的页面。字典或者词典知识库,半结构化数据关系模式的那么这里来大多数的情况下,我们应该看到本地学习所利用的资源还是以这种文本类型的数据的位置。不管你是这个结构化的还是半结构化的,都是以文本的形式去参加。但是现在呢还有一些相关的,最新的研究研究了一些多模态的问题。有的,我除了文字之外,我还可能有这个相关的一些图片,有一些相关的视频,相关的语音等等,我能不能把这些数据可能你有钱?我变成了这个粉底学习所可以利用节制。第三个,从本体学习的目标看,它主要来实际当时为了丰富或者客货带来已有的问题。有的像我的奶奶的人在这里丰富了,一般是指来是增加概念到这个班级总监。但是呢他不去增加了这个概念结构的这个深度。就算它平行的去补这个补充一些相关的一些概念,而扩展的,他也是讲这个概念的这个新的概念加入到本体总成。但是这个扩展啊增长了这个概念结构的一个四个深度在。对这两个词但它的用法藏还有一
也用完了,还有一点点这个小的区别。虽然现在的这个许多研究中价并不是很强调的一点,但是我们这里稍微做了一点点解释。儿童本体来他的一个自动化程度上看,直接打总体来讲,现在几乎还不存在完全自动的这个本体学习方法。那么在这个过程中间呢,或多或少的都需要来人去进行这个参与。那么目前的这个本体学习方法来往往来都是这个半自动。那么他需要人类的专家对学习到的这个概念和关系的进行一个确认。啊,如何利用这个外部账应用的各种资源或者知识来减小话来最小化人类的这个负担呢?它仍然是一个条件。在这个方面来,可能大家会听过像这个CMU他的这个never ended language learning的这样的一个项目,叫nel。那么这个方面呢他实际上来就是主要来去考虑的就是移动这个通过比较小的人类的那个监督的方式去进行这个相关的知识学习的这样的事情。那么他就模拟了怎么做一个这个儿童成长的过程。那么儿童成长的过程呢,他自己来可以进行很多很多的学习。但是他学习的过程中间可能会出错,所以再这个人呢这个大人呢会过一个在一定的阶段对于这个错误来进行这个纠正,他并不是时时刻刻都要进行这个训练或者反馈的。而是他是一个被称为教,终身学习等等概率,也就是说你的模型自动化了,在不断地这个处理。对吧?过一阵子的人会进行一个这个纠正的主动使大家这个模型啊这个变得更好,比如说我们做的这个学习的模型变得更准确。然后呢我再进行这个进一步的自动化的学习。那么最后呢从这个学期在这个技术上看是让它包括了很多和自然语言处理及分析,机器学习等等相关的检测技术。那么比如说自然语言处理,中间的词性标注,句法分析,语法分析,怎么话语分析,术语识别等等的,这都是我们坐在本体学习过程中讲非常常见的一些方法。而另外呢像统计分析中间的这个搭配贡献的这个分析也是一个很主要的个东西。有多我说在学习的时候打一些,就像一些概念她们经常一起出现,或者哪一些属性,它们之间的经常一起出现。那么我都可以作为来帮助我们进行这个粉底构建学习的一个过程,对吧?还有来。那么机器学习里面也用到了很多的像聚类分析呀,规则集的学习方法bs的方法。人工神经网络模型啊等等,但是总体来这部分本体学习对部分的,那么由于还是一个这个半监督这个过程。所以呢目前的还没有这个,比如说我完全基于深度学习的端到端的知道班级学习方式。我们这个如果大家感兴趣的话也可以作为未来的一个这个研究方向。但是这个呢相对来讲可能但也是比较难的那种野队。那么我们下面呢就开始讲一讲这个基于本体,基于不同的这个资源进行本体学习的一些相关的内容。对吧?主要包括了比如说基于文本的,我们还可以从数据库还可以从别的方面进行这个粉底学习。那么现在这个下课休息一下,那么接着来等会儿休息完之后我们再讲下一部分的主要内容。