https://www.bilibili.com/video/BV1iz411b7jp/?spm_id_from=333.788.recommend_more_video.3











嗯,我们这个大家回来吧,这个我们开始这个继续了啊。那个嗯首先我们接着上一个内容讲,我们讲到了这个本体学习里面的相关内容。那么我们说第一种这个本体学习的方法,那么主要是采用的,我们说基于文本的这个本体学习的方法。基于文本的这个本体学习的采用自然语言处理和机器学习的技术。他从文本中来学习得到这个问题。这里的我们有好几类不同的这个呃方法,比如说包括了基于模式抽取的这个班级学习。那么通过我们定义一些抽取的规则,那么进行的这个相应的问题学习。我还可以来基于关联规则去发现的。这个本体学习,那么我们刚才说基于统计的一些方法,我们可以知道一些贡献信息。这实话我们很容易去学习,出来相映的观点不同。第三个我们说可以有一件基于概念的这个聚类的这个班级学习,我可以通过一些聚类的方法把一堆概念我还可以建议进建议进行基于这个本体修剪这个本期学习。以及基于概念学习的这个班级学习等等各种各样不同的这个技术。那么这些技术的,那么它时到乃个有这个利弊能解决的问题的也不太一样。首先我们来看一看,比如说第一种,比如说基于模式抽取的这个本地学习。假如啊我说在文本中间。这个单词序列和这个模式匹配。那么我就识别出来了他的这个语音关系。比如说,如果我们发现包含了嗯个数与的一个序列,而前n减一个术语的是第n个数女的一个下维词。那么这时候我就可以抽取出来一个相应的一个实体和这个概念之间的一个关系。这个来实际上来在这个本体的这样一个相关的研究里面有一篇很著名的文章叫这个house特这个模型赫斯特模型,那么他想做的就是这件事情。我可以看一下这个模型呢,它大概是讲这样的一个意思,比如说我们有这样的一个模式。着伦敦,北京等等等and other large cities。那么这时候就是我们说啊,我们发现了有人个数与伦敦,北京以及的这个large city。而且呢我们知道有一个模式叫做伦敦和北京啊,是large city的下位词。或者实力。那么这时候我们就有一个模式,说这个名词短语一名词短语就npmp二n减一and other men。是一个上下位的关系,而其前面的一二到n减一。都是这个mp and这个下位置我们可以构建一个实例和类之间的关系。所以呢这个赫斯特那篇文章里面,他就从这个自然语言这样一个构成的角度总结了这个分析了一些最常见的比较准确的一些模式。有这些模式的可以进行一些相应的这个抽取的任务,这就是我们做基于模式抽取的一个本地学习。那么这个方法非常好用,而且呢它的准确率呢这个相对来讲也是比较高的一些话。那么当然这个现在来讲,那么这套机组实际上以及这个过时了,对吧?现在的一些技术可能我们可以采用这个像序列标注啊等等的一些深度学习的一些技术。那么也很容易去识别出来相应的一些这个关系。第二个呢,我们说有一些基于关联规则发现的一些本地学习,比如说我说这个关联规则,所以出来是在这个数据库数据挖掘领域里面。大家可能比较这个熟悉的就是这个啤酒尿布的这样一个例子吧,有一些人,那么他去买这个尿布的时候呢,他顺便会买几瓶冰个啤酒。你就是一个关联规则。这力量我可以概念层次来我一个背景知识。那么首先呢将他来用于的这个概念之间那个非层次关系的一个学习。也就是说我们知道有一些概念他会频繁的在一起出现出现了,比如说学生就会出现这个老师。那么这时候了我就可以通过这个关联规则来进行一个相应的这个本地学习。另外几类呢?比如说我们说基于概念聚类的本体学习,他可以根据这个概念之间的一个与利语义距离的对概念进行的分组。并且形成了这个层次体系,任意两个概念之间的语义度量距离的度量呢可以考虑的这个多个因素。你们俩我们还可以基于在这个本体修剪的这个本体学习,他的目的来是基于异构资源构建了这个领域本体。我们还可以的有基于概念学习的这个问题学习,当新的概念被不断从真实世界的文本获取的时候了,给定这个分类体系。并且来进行这个增量和更新。总体来讲呢,那么这些方法呢都可以被归结的了,面向这个文本,基于文本的这个本体学习。这个扮丑女,那么当然也不仅仅只有我们的职业相关的教育学内容,那么还包括了现在许多的一些新的这个研究的进展,许多新的技术都可以用在这个本体学习。笑的跟这个问题上。之前我们刚才说到的是这个赫斯特模式或者合资的模型,那么他提出了就是从自然语言文本中点自动获取上下位关系的六种模式,他并且在他和这个手工编织的词典数据库啊这个world net进行了一个比较。他认为可以基于的自然原文,本词典,字典,百科全书等等的资源呢自动的构建,同义词的这个词典。我姐呢这个方法来实际上带着个粉底学习中的是得到了比较好的应用,成为了本季学习的一个主要方法。Dell方法来主要是利用了这个文本中间的警示的知识,它主要根据的是这个一个叫Henry的一个分布假设,也就是说单子的这个相似度啊由他们所在的圆学的语境的相似度来我觉得。所以呢他就把这个术语的语境啊这个表示成了一个向量,可以用这个向量空间模型呢对这个语境来进行这个建模。那么这时候呢他又可以用进一步可以分为基于相似度的方法,基于集合论的方法等等。那么这种影视知识的,那我们说如果在这个更进一步,那么在最近的降息,在自然语言的处理里面,我们经常会把它称为叫这个word embedding这样一个事情。那么比如说我在这个向量空间模型去计算相似度的时候,我存在大量的这个零对不上。所以嘞,那么我可以用word embedding的技术把它进行压缩,有个简单的就像这个word to work的这个方法。对吧?把咱家说成一个稠密的这个向量,然后呢在这个销量上面呢,我们进行这个比较,小土豆,我们刚才说的这样一个弯hot的这个方法里面他比较稀疏的这个问题。再到后来,那么他又利用了一些我们做的上下文的信息,这个语句的一些信息等等的。他可以呀,现在有很多的新的一些模型,越像波尔特等等的都可以去利用这个文本中间的影视知识。对吧?当然你也可以把两种知识把它相映的这个影视的和显示的知识的结合起来。那么除了文本以外,这边我们做文本呢是最主要的一种方式。那么除了文本以外了,还可以利用,比如说我们做质点。知识库半结构化数据关系模式进行这个各种各样的这个本体学习。而且呢在这些本体学习的这个过程中加他们的效果可能还会超过基于文本的这个学习。他的主要原因就是因为我不做这个文本,他处理得相对来讲还是有一定难度的,因为自然语言存在这个不确定性啊,奇异性啊,然后这个模糊性啊等等的一些问题。那么导致的这个
那么导致的这个一基于这个文本的方法来他的这个性能的还不是这个竞赛进去。但是反过来你有一些其他更偏向结构化的这个资源的话,那么你可能很容易地就可以去抽取到信息,我们去这个之前的科长去讲过这个利用这个把知识库转化成这个这个呃把这个数据库转化成这个我们说本体的这个形式,那么很容易我可以通过啊图案Maya,或者direct mapping,叫的一个语言直接进行转化。那么这种转换那么它就是一个相对应的一个比较正确的,比较容易保证正确率的一种状态方式。所以来在这里我们也提到,我们需要来综合的利用其它的资源啊去进行本地学习。这里比如说我可以基于字典的本地学习。基于字典或者词典的这个本体学习方法来会从机读字典中间抽取相关的这个概念。把这个关系那么这个方法比如说我可以去利用word,net,采用句法或者语义分析啊等等语言学分析方法。从字典或者词典中间的抽取到这个新的概念,新的关系。第二种呢,我也可以基于知识库进行班级学习。你就是说我基于从已知的知识库总价再去学习一些东西。那么比如说我根据我的需求,那么从这个知识库里面裁剪出来。这个方法呢目前的应用的比较少,相关的研究也比较少,因为在这个大家的比较容易去想象。我已经有了一个这个知识库,那我为什么不直接用?我还要从他里面再去学习,似乎没有这个必要。所以呢这个方面相关的研究的偏少一点,但是我们把它列在这里作为一个相应的这个完整性的介绍。因为还包括了一项合作,基于半结构化数据和关系模式这种结构化数据的这种班级学习。基于半结构化数据的这个本体学习方法来,他可以从我们做的预定义的一些结构的资源中介啊。学习本体。比如说我们说之前我们一开始课讲过这个XML,他有一个自己的模式叫XML schema。我可以利用来这个XML schema进行学习。另外呢,我们还可以说我们实际上你现在有很多的这种垂直网站,比如说我们做来大家可能看电影的话,你知道有个rmvb的这个网站。这种垂直网站啊,它实际上你可以把它翻译成一棵我们坐的express的这样一棵树。一个XML的数,一个查询的结构,它的结构时当也是一种比较固定的方式。因为每一个大家你可以到im TV上看一下每一个电影他是鸡杂。他的这个表示的形式实在是很类似的,它的这个结构是比较相关。所以这种情况下呢,我就可以用到这个这个利用了聚类模式识别的方法。那么他嘞最终的这个目的都是用于这个模式映射,使得我的半结构化数据。可以从中间去学习出来相应的这个问题。比如说我知道结过婚这个一个MTV网站里面,那么它有总是会描述这个导演啊,演员啊等等的这些信息。那么我就自然而然可以学出来他们相应的一个问题。那么我还可以的基于关系模式的这个班级学习这个方法来主要用于的是从数据库中间抽取概念的知识。这个方法主要用于的获取,比如说我从一个圆的数据库模式到目标数据库模式的映射。构建在中间的一个schema,这个过程往往基于的一个学习的映射的技术。并且来以这个目前的你手工的方法来维持后面的柯南,我们也会专门讲到这个本体匹配的相关的内容。那个问的内容呢就会介绍相映的自动化的这个处理方法。那么总体来讲,比如说对于关系模式的这样一个学习的,那么它也可以取得比较好的效果。因为你只要定义好了这个映射的模式,那么你进行转换的时候了,你的这个准确率还是很高的。以为你在数据库里面的数据是一种结构化的数据,它是一种很规整的这个质量很高的数据。那么它不像自然源这个这个处理里面的这个文本,那么它有这个很多的表达的方式表达很多样性。而这个数据库里面的数据就是表格再把你只要定义好了转换的模式之后,那么这个表格里面的数据啊,这个总是能这个比较方便比较正确地进行这个转换。最直线方法了都我们把它归结为基于其他资源的一些本地学习。而这些方法的学习出来的这个本体的,那么它的质量呢我们前面也说过,很有可能呢会超过一般的基于文本的这个学习的这个质量。怎么在这里呢?实际上我们还会多提一句本体学习呀,它可以利用很多相关领域的方法技术。特别是来来自于信息抽取领域的一些这个技术,这个地方来有很多的现代的研究。比如说我可以同时进行一些术语的识别和关系的这个学习。这个里面了已经有很多的一些研究了,称为来教一些joint的这个方法。比如说我在命名实体识别和关系抽取这两个不同的这个任务上面,我可以进行一个联合。因为他的假设是,如果我的实体命名实体识别的效果比较好,那么我后面抽取关系的时候肯定会更准。或者我抽取了一个关系,比如说我说一个学生指导的这个关系,那么我就自然知道,我前面命名实体识别里面应该来讲一般是一个人知道另外一个人。所以呢这时候我可以做一个joint的the model进行这个若进行完整怎么样?那么同时呢还可以利用的是一些少量的带标注的这个种子集合和大量未标注的这个训练样例呀来进行学习学习词典进行信息模式抽取。大大减轻呢标注语料库的这个负担。那么这个方面的实际上有很多的这个技术,比如说就这个获得stripping的这个技术active learning的技术等等。那么这里呢这个bootstrap的这套技术,我们把它称为叫自破胆的技术啊等等的,他可以将属性特征分成,比如说多个两个集合,每个集合来都可以进行训练完成任务,然后呢集合和集合之间来就可以互相的这个进行特训。那么还会经常利用的属性的,包括了一些名词短语啊,名词短语的一些引进啊等等相关的一些东西。啊,上面呢就是我们讲的第二个部分,关于的这个本体学习方面的写内容。总体来讲呢,这个本体学习了适合,如果你做的是从这个文本中间进行本体学习的话。那么实际大事和信息抽取和这个现代的自然语言处理的很相关。包括现在在主流的国际会议党已经有很多的这个自然语言处理的主流的国际会议,上面有很多关于这个相应的一些研究工作。我们这来把它概括的就粉底学习,但是实际上在那里面呢有很多的比如说要关系的抽取,啊,命名实体的识别啊,然后这个事件的收取啊,事件的关系的识别等等的这些东西。那么他都可以的泛泛的规程,或者说本体学习这个方面的经验就那那么第三个呢我们想讲的关于这个本体知识管理里面的相关的内容了。包括被称为来教育网的这个图结构的分析。那么这部分呢他的内容的主要来来讲,我们可以把它这样来分成几个部分。一般来讲啊这个图结构的分析来他大概来说包括了这几个不同的步骤。第一个我们把它称为叫采样数据。也就是说这个图它的结构啊它很大。那么它里面的节点的非常多,而且呢可能呢他很杂,也就是说这个里面他数据啊很多的不同的类型的数据交互的,另外呢这个数据的他并没有很多的这个这个具体的一些还是比较这个通俗的。也就是说比较这个浅显,那么你们可能还会出现的许多错。那么我们需要呢对这个数据的进行了这个采样,那么从中间来获取一些东西,因为呢如果这个数据太大了,那么实际上我们分析的很困难。比如说我们假设我们现在要对万维网进行一个分析,那么整个的万维网的这个图结构,那么谁来实际上都不知道,因为整个万维网上到底有多少网站实在是很难聚。完全获取了所以这时候呢我们必须要进行一个采样。那么这个采样呢那么这里就涉及到一个问题,这个采样啊你到底是一个是不是
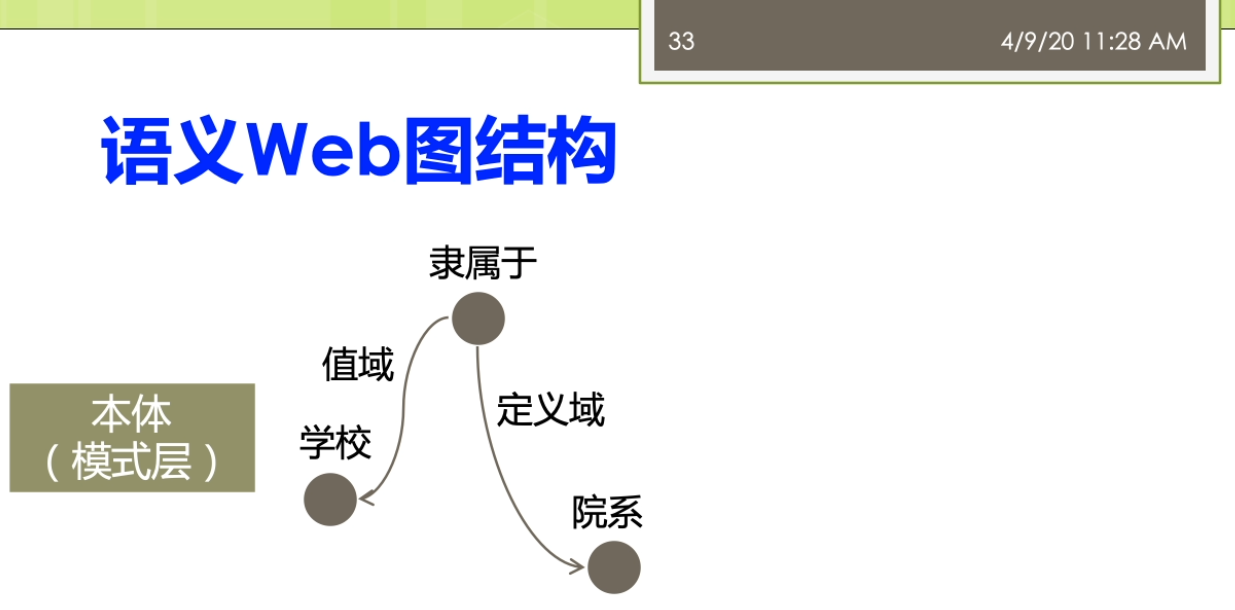
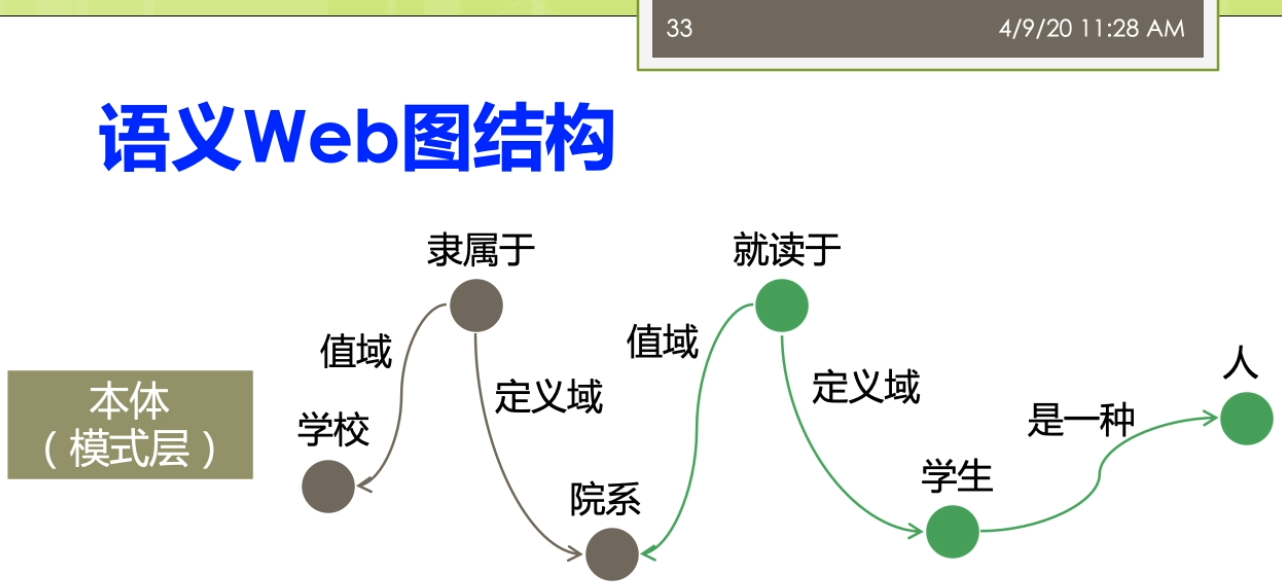
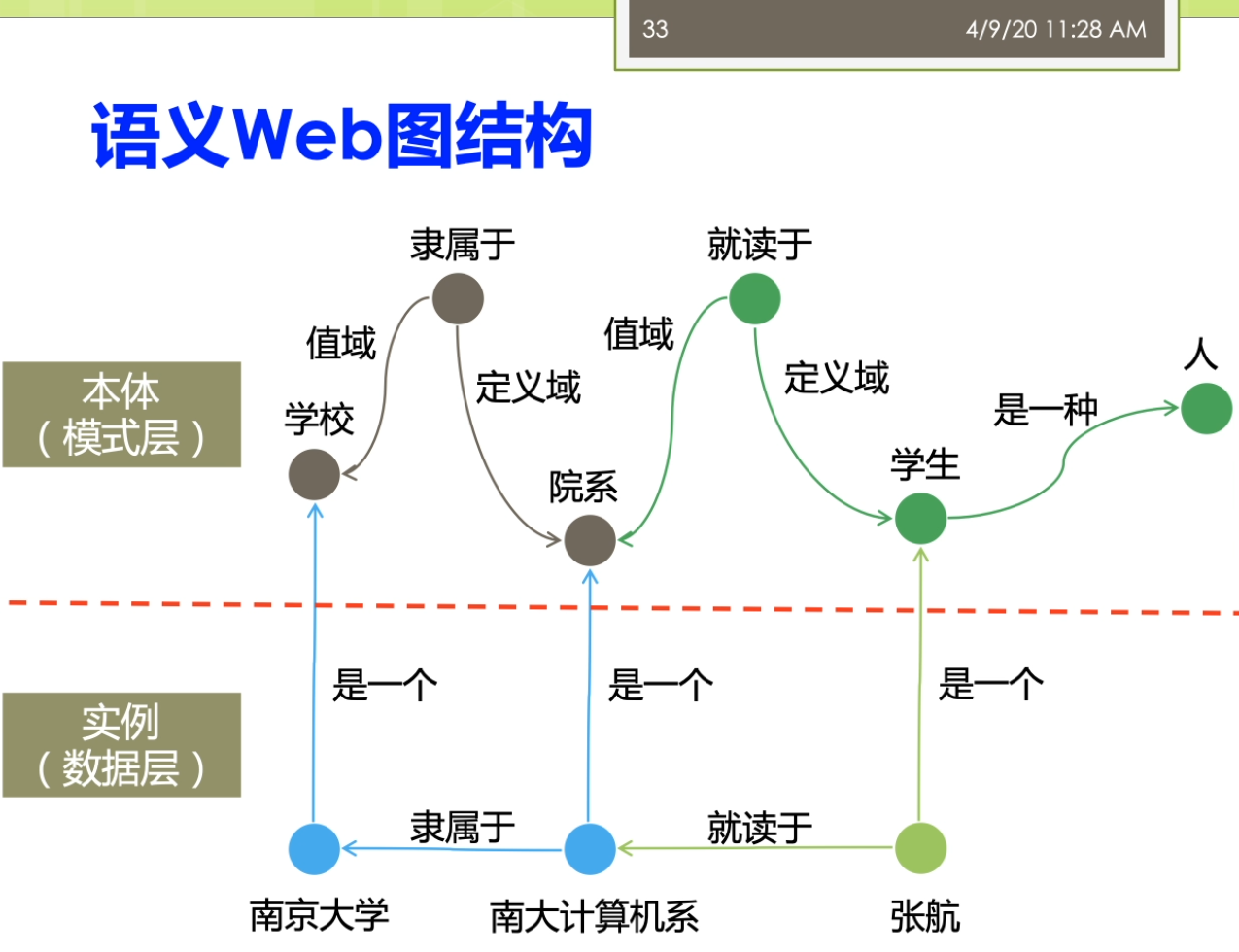
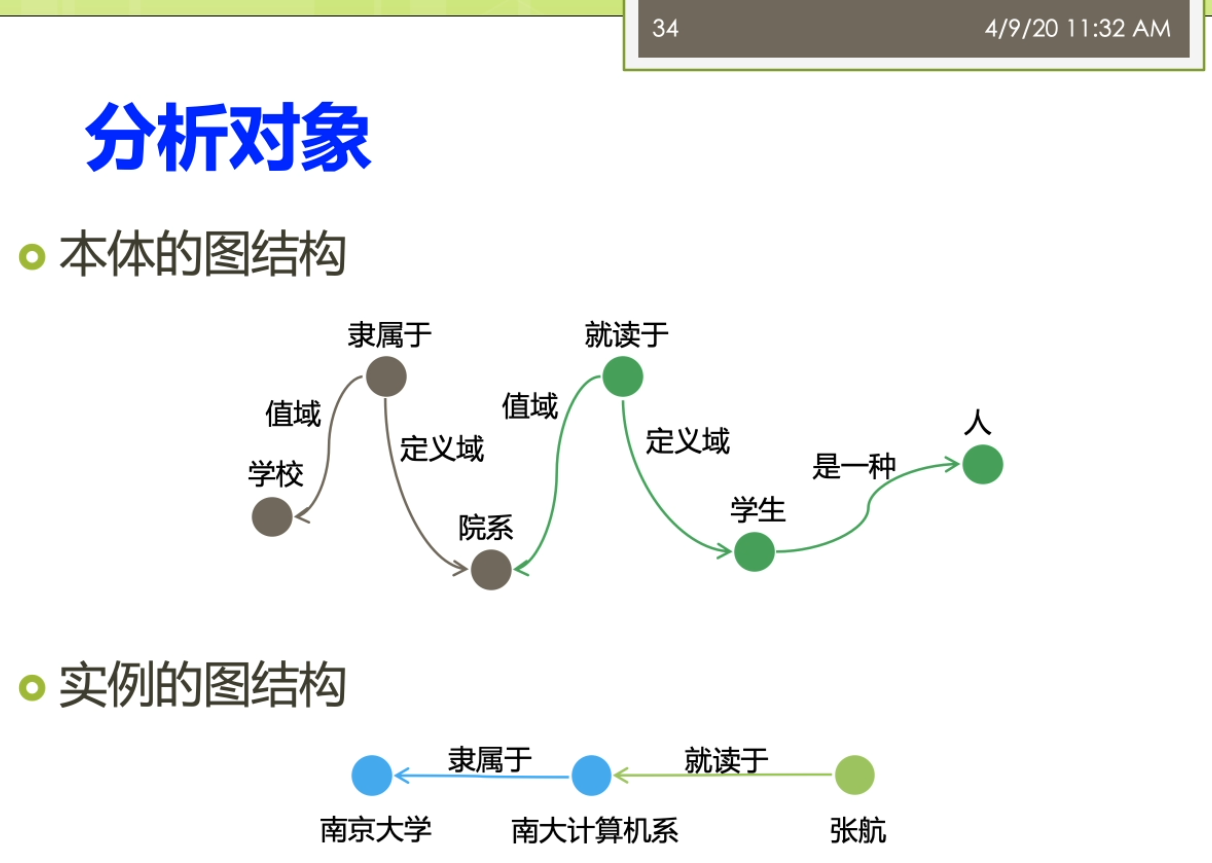
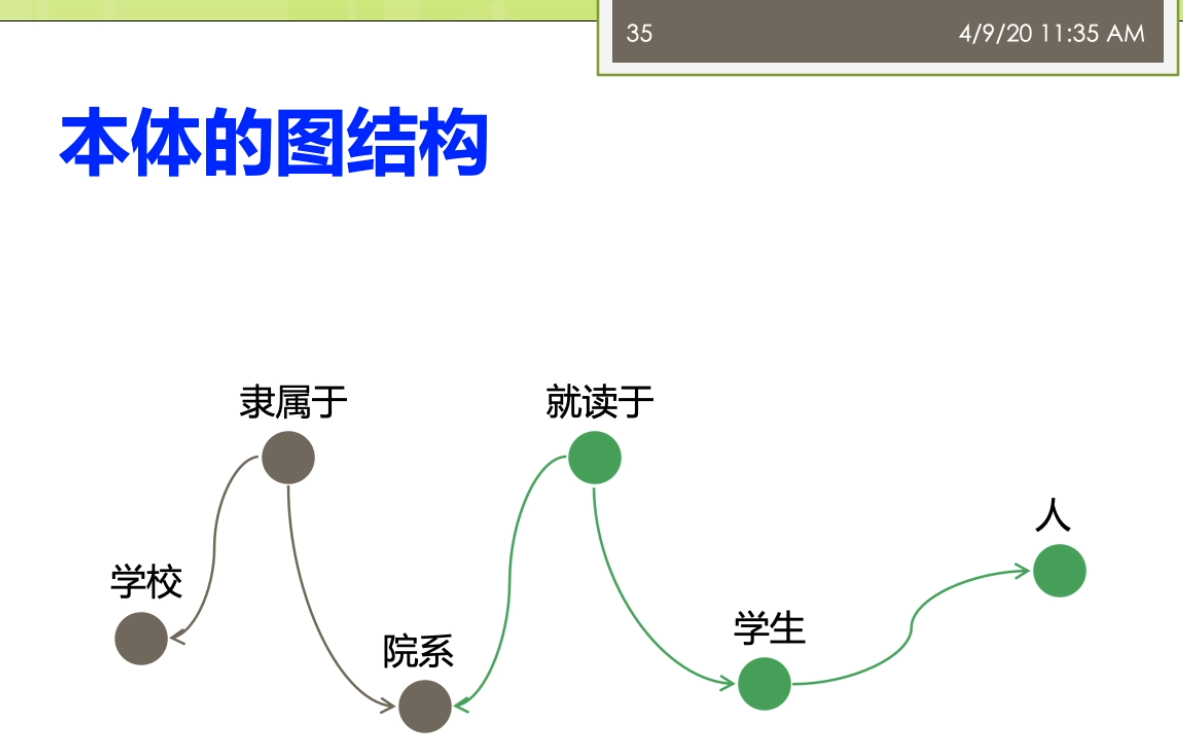
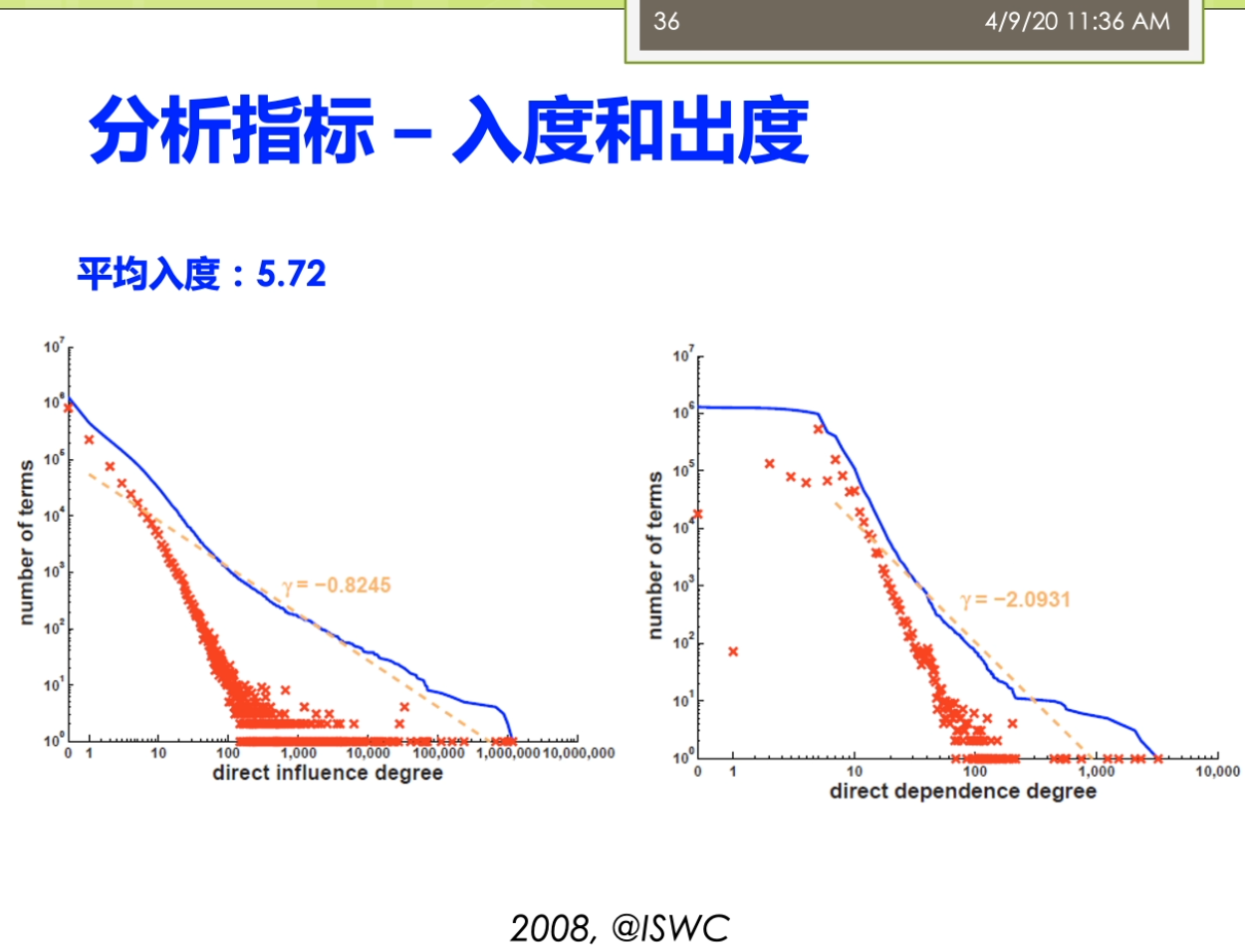
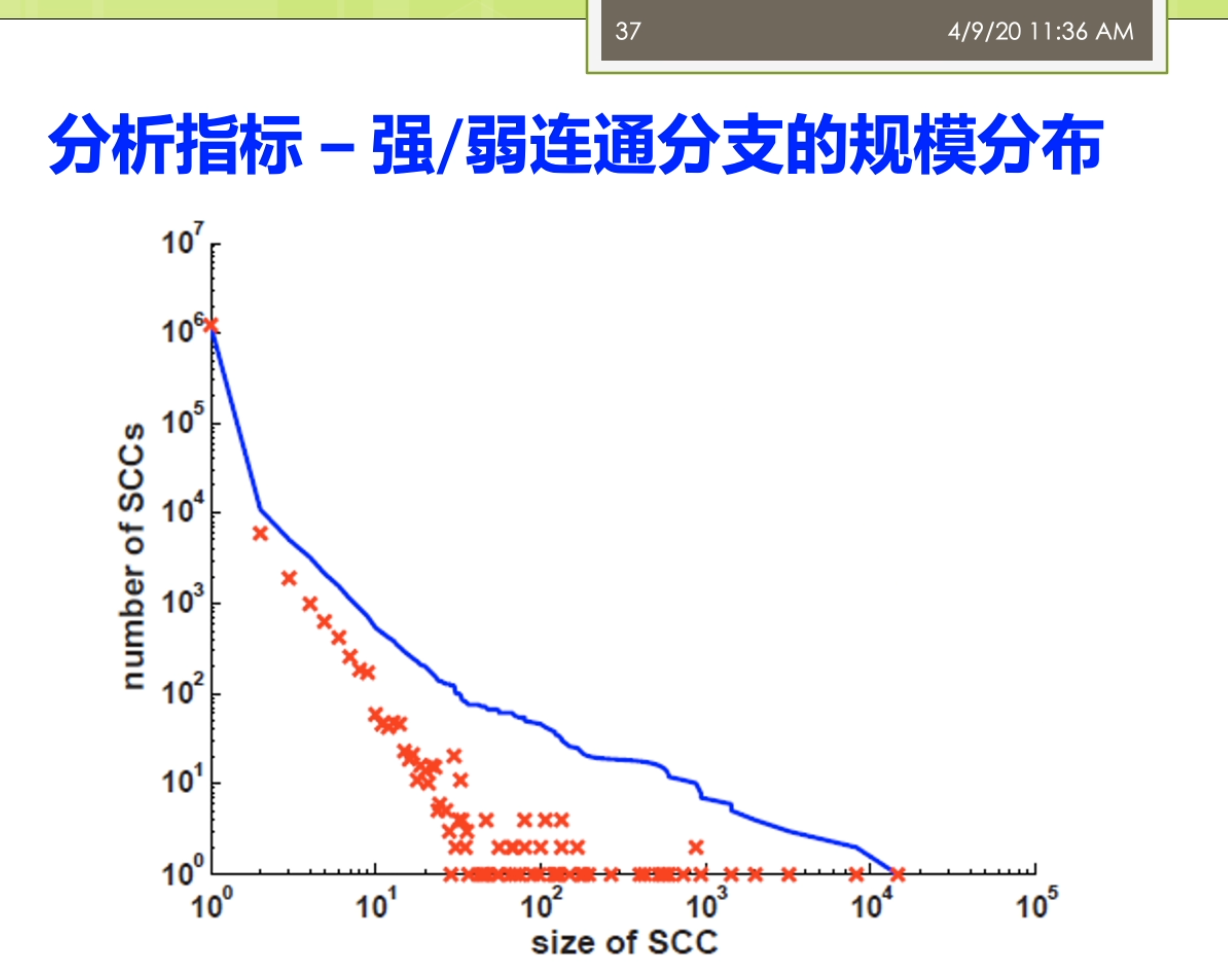
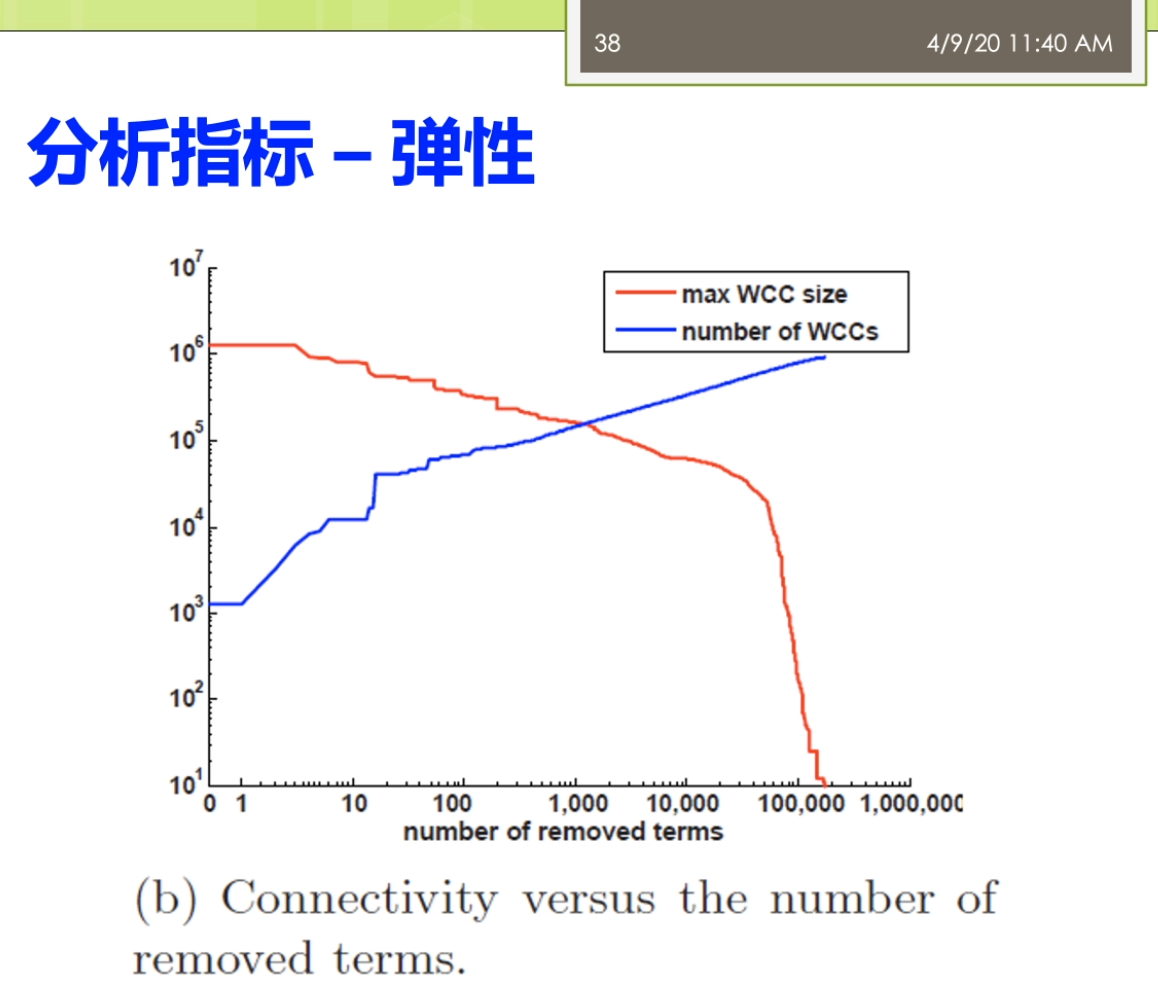
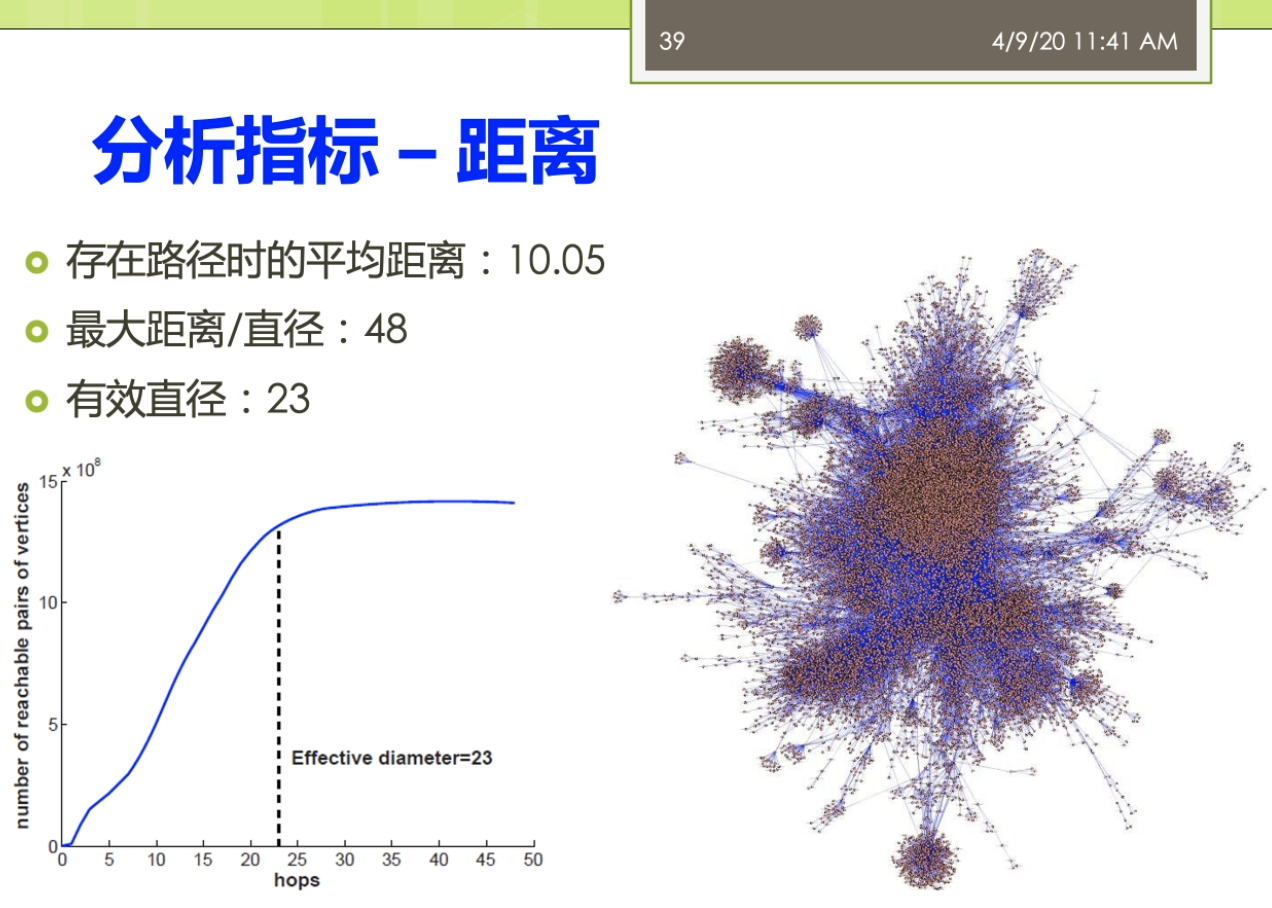
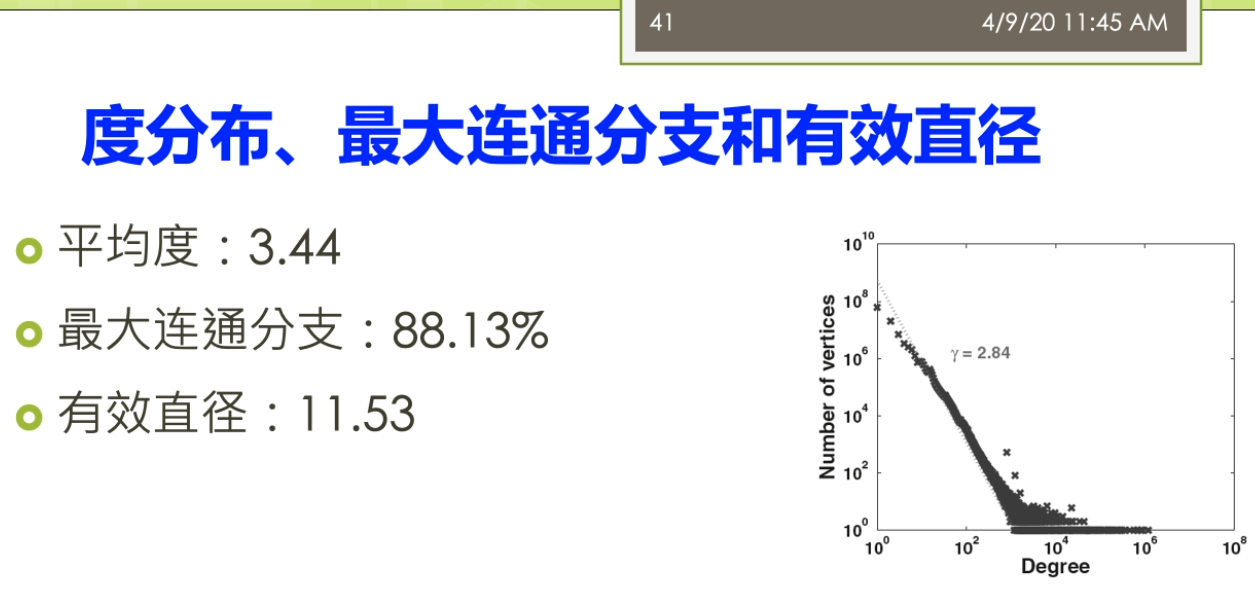
因为这里就涉及到一个问题,这个采样啊你到底是一个是不是一个公平的一个采样正确的材料?而不是你踩出来的这个采样啊,实际上是带有了一些偏偏治信息在里面。那么如果你的数据采集都出现了这个偏差,那么你后面的分析结果来世上就是很多情况下就不成立了。第二个呢我们就要进进行这个建立了这个图魔性,我们要分析的这个是什么?我们想用的指标是什么?那么我就要去建立了这个合适的这个图么金结构啊。进行了这个相应的这个之城,这时候这个图模型里面的含义的就非常明确了,比如说我节点表示的是什么?我的边表示的事情,并且我的这个图来是有向图还是无向图,还是一个复杂图等等等,都是染的这个地方来确定。第三个呢,我要去选择分析的指标,这些指标一般来讲它要有实际的意义。最后呢需要执行这个分析,这里来就有很多人先算法,因为在一个很大规模的这样的一个图结构上做分析的时候,不可避免的你要考虑到这个效率的问题。如果你的效率比较慢的话,你在很大的图上面去做的话,很有可能你就做不出来。这个来事分析的一般的这个前面的几个不同。之后呢得到结果之后,那么你就需要了这个进行这个解释,比较这些分析结果。看一看这个结果他到底隐含了什么样的这个物理意义。那不以及的得到这个结果对于现实有什么指导价值?这写的都是这个图结构分析呀,他需要考虑的。一般来讲了这个大多数的这个工作了,可能做到这个前五个就已经这个比较不错了。对吧?还有一些呢更高水平的工作啊,他会在做最后一步,他会推测了这个图的一个生存到这个模型。你就说前面你是对于这个图进行了一种分析,而最后一步了,实际上是对这个图来进行了一个拔高和归纳总结,能用一个函数或者一个公式,能把这个图的生成模型把它概括出来。那么有了这样的一个生成模型,实际上你就讲清楚了他的一个物理的兴趣。那么你可以用这个生成模型生成各种这个和刚才你分析的图非常礼盒的解其他的这些图。这部分呢一般来讲的是这个比较高水平的研究人员才能去做的。那么这个呢也是我们这个课的这个暂时的不会提的这个部分的。阿们。来看看与外部图的这个结构,我说我们还是按照我们的本体,这个题box的和这个a box人啊。进行一个这个分类。与外部图的这个结构来提box承担就是我们做的概念和这个属性之间的一些关系。有时候我说学校的隶属于的这个一个院系。这个时候嘞啊,这个院系隶属于一个学校,这时候院系仔就是我们的定义域。那么这个学校呢就说的值域,我把定义域和值域作为边,那么这时候来这个学校院系隶属于这个来就变成我们的点。我可以这样子的去构建一个四个相应的这个服务。那么儿我们这个图来也可以进一步扩大,有时候说学生就读于一个院系。学生那是一种人。他和一般的我们这个平时大家接触的比较多的这个图案不太一样。他这个图是这个节点和边呢识到都带有标签的这个,而一般我们说的这个简单的不那么实际再来它不代表钱,或者有一些研究里面,比如说我们在社交网络里面的这个图,那么一般来讲呢,它的这个节点了,他是带表情,有的节点是每个人。但是他的边呢可能会做一些简化,没有什么表情,比如说人和人之间就是朋友的关系,只有一种关系。或者不做互联网的下一个图,这个借鉴和节点之间就是一个超链接的关系等等。但是我们这这个节点和节点之间的边可能是很多不同的这种复杂的关系。而另外一方面我们还有数据的这个实力才我把它撤回来叫a box,这比如说我们可以说这个某一个学生。那么叫张恒的一个学生她来是一个学生,她来就读于南大的计算机系。所以这实话这个数据的实例承担又和我们的他只是历程之间自身难不行,那边有个张行,就读于南大计算机系。北大计算机系来隶属于南京大学。同时呢他又和我们的这个模式才能有些关系,说张航还是一个学生。南大计算机系的是一个院系,而南京大学的是一个学校。这样一个复杂的这样这个雨衣外部的这个图结构啊,如果放到很大的一个规模上,他到底会呈现出来一些什么样的性质?就是我们这个于外部图结构分析啊,想搞明白的事情。那么分析的对象,比如说可以有本体的这个图结构,也可以有了这个实力的这个图结果。那么针对不同的这个图结构了,我也可以利用不同的这个分析的指标来进行相关的这个分析。看看有没有什么样的结论。这个部分呢这个分析的这个内容呢,那么它实际上的从这个屋里的角度上来讲。怎么满足了我们对于这个客观世界的一些好奇心?也就是说比如说我们知道人类世界的有一个这个小吃街的这个现象,有个叫6度空间的理论。那么我们在这个语义网里面到底是有没有这个一个相关的一个内容?那么有没有这个相关的一个现象?实际上的我是觉得这个对于这个东西啊大家应该有一些很好奇的,你知道吗?想法想通过这个图分析的来看一看能不能找到一些客观的这个事实一些证据。啊,我们先来看看这个粉底的这个图结构啊,那怎么分析?我刚才说了这个本体的图结构里面有这个隶属啊就读啊等等的一些相关的形成了一些概念和属性之间的这个关系。那么第一个呢我们经常会用的一些指标被称为来叫这个入度和出路。魏都了,就是说一个节点,他有多少边指向他儿秋冬的就是他了,有多少遍了这个只出去。那么实际上呢有这个相关的一些研究,对整个的这个于外部上面的讲一些数据啊进行了一个分析,这个呢我看到这儿有两个这个图。一个来自关于这个入冬的一个展示关于速度的这个图,这个图里面的我把它称为了这个是一个叫power low的一个幂律分布的一个图。大家都要注意的是对于这个图来讲,它的坐标走啊它不是一个等值的一个坐标。而是他是以一个这个logo的这个作为了他的这个坐标。也就是说这个分真的里面呢事实然后下一个等长的是扩大到了100,再下个来是1000。那么在这个图里面,纵坐标来表示的是这个术语的节点的这个塑料。也就是说比如说这个第一个最高的表示呢有很多的节点没有度数。没有度数意味着什么呢?意味着它是孤立节点,也就是说他没有读过最有时代六次方左右。那么1度的也就是说只有一条边的,那么在这个位置,那么实在六次方和十的八次方之间的一个地方可能是这个,比如说这个5×10的这个六次方等等的。要大家注意这个不是一个均匀的,这个十的七次方,并不是在这个时代,六次方和十的八次方,中间这个相等的地方跟他可能再在这个更上面一点的地方等等。那么在这个里面呢,我会说这个里面这个数据啊很有可能。我们会分析出来他满足一定的这个兴趣,其中呢一个比较有意思的性质就被称为了叫这个power Lord这个分布。而落来中文翻译者翻译成在角这个幂律分布。这个分不了,那么表达了这样的一个含义。这部分量把它称为来叫这个肠胃,也就是说在结尾的地方有很多的低度数的节点。同时呢在这个头部又有数量很少,但是在他度数很高的这个节点。而他如果我们用一条这个曲,而他如果我们用一条这个曲线啊用一条直线。可以的么?你整个的这个分布的情况,在这个唠嗑唠的坐标系统,它如果等于这样的一个曲线可以去模拟的话嘞。那么实际咱俩它就类似于了我们说的一个叫幂律分布的一个情况。这个密令分布呢,对吧?展现了我说他是一个自然界中间比较常见的现象。比如说我们说人的这个这个许多的特征,自然界的许多特征都是满足了我们做幂律分布的。那么比如说我们假设这个人的这个财富啊等等的要么是呃不是财富,不是这个比率,胳膊就是比如说一些这个网站的一些结构,那么它就是一个幂律分布。那么因为互联网上可能有少数很少数的网站,有很多的人能饿,就很多的网页都指向他。那么但是呢也有大量的这个网站有做你个人的微博,那么没有人纸箱里的这个微博。所以呢,这个就是一个典型的一种幂律分布的情。还有一些呢分析的分析的我们说的一个叫强弱连通分支的一个情况。强弱连通分支大家贵这个这个学过一些数据结构。图二是个算法的同学都应该了解这个强弱连通分支一个来顺便向有向图,一个是武向图,我们去算他的这个连通分支的情况。那么这里强弱连通分支可以看到在整个的这个过程里面,那么我们实际上有很多的这个节点啊,他是这个一个的,也就是说他事故地点儿也有少数的这个连通分支很大。也就他里面超过了十的四次方。那么意味着那么这个连通分支是一个很大的那种问题,他可能占据了很大的一个规则。怎么这个图呢?它同样可能是一个这个polo的这个分布性分布的这个情况。那么通过这个强弱连通分支的实际上我们就可以观察出来,这个我们整个的这个语义网里面这个它的一个社团结构的那么知道他的这个社团的分布啊实际上是一个不均衡的一个情况。那么还有一些指标,比如说称为叫这个弹性的主要谈心的这个指标来,这个表明的实际上来是一个这个抗压的一个能力。比如说我们说在整个的这个万维网哦这个互联网上这个弹性的指标。那么就表现在怎么说,比如说这个网络里面我们做第一个s是个主机。那么这个主机啊如果我们其中一个主机当不了了之后,那么是不是大家就这个上不了网?阿志说这个我们的这个主机当掉之后,那么别的大家来还可以通过其他的这个DNS继续取消。那么这个弹进去不要来,那么它是怎么样去去测量呢?那么它实际上是这样的一个过程。那么他来取最大的这个联通分支。取最大的这个连通分支啊把它去掉。去掉之后呢,那么看整个这个节点,他的这个连通性啊他会不会这个便便差。那么然后呢再一个一个足够的删除最大的节点一个一个删除掉。那么只到了这个发现哦这个连通性啊,显著的这个变差了之后呢吧,就知道他的这个这个弹性啊到底好不好。比如说我们在这个里面,我先假设一开始这是他的这个联通。那么我来这个是最大的联通的分支的大小,然后嘞这是连通分支的这个速度。在这里我先删除了一个节点。那么最大的连通分支它的大小没有什么太大的变化,三读十个的时候也没有怎么办?但是到这儿删除的大概这个10万个左右的时候,那么就出现了这个一个断崖式的这个下跌。那么这个弹性呢那么实际上就反映了我们说的这个语义网里面这个数据它的一个中央性。如果来这个大家来是一个分布式的一个特性的话来,那么它的弹性一般来讲呢不会太差。那么如果来你是一个中央集权式的这种这种表示的这种数据来,那么它的可能呢它的弹性呢就会变得这个相对来讲差一点。因为这个量需要注意的是,虽然这个距离的说法,我们要算的是这个最大的,比如说连通分支,你因为这个距离如果你两个点不连通他他距离是无穷的,那么这时候你就算不了平均。这个量了我会按照联通的去做。比如说我们这边有个结论,说在这个分析报告里面分析出来这个平均的距离大概是这个10点左右。那么最大的距离或者称为叫纸巾的话,那么是这个48,那么有效的这个纸巾来大概是在这个23左右。所以这个地方呢这个分析指标距离里面了,那么也可以了发现一些东西。我说之前我们做6度空间的这个理论,实际上表明的这个距离大概来是人和人之间的平均距离的大概在六左右。而在语义网里面了,他的这个平均距离的大概是十吨,那么这个距离也不是一个很大的痣。也可以这个这个不精确的说,他也是满足了我们坐在一个小世界的这样的现象。那么大家来这个可能每个节点平均单通过十个边就能链接到了另外一个节点。那么对于实力的这个图结构上面来也有很多的这个分析工作,但是实力呢这个地方来大家需要注意的实力来相对来讲。他们之间的结构比较简单。但是呢实力的难点在于实力的这个图啊,它的规模了要远远的比这个本体的这个图来的大。因为我们知道,比如说你从一个数据库的角度上去想数据库的这个表结构啊,这个一张表可能就这个十几个列就完了,但是它存储的数据可能远远不止这个十几号,那几百行,几百万行都是很很有可能。同样的对于这个实力的图也是这样,那么我们语义网里面这个本体的数量可能不太多,但是我们说从知识图谱的角度看,这些利用这些本体,形成的这些数据,实际党它的规模是非常大的,所以针对实力的分析的这里来就有很多的这个研究的这样的一个。一个这个难点,要不然你的这个算法到底比如说是否高效,这个就成为一个难题。呃,这里呢也有一些相关的关于这个度分布最大连通分支有效直径啊相关的一些这个研究的结果。有算作平均的这个度大概是这个3.4左右意味着一个实体啊。大概平均跟3.4个其他的实体来相连。同样的从右边的这个图里面我们也能看出来,那么这个里面的这个度分布,他适当也是满足了我们类似的一个power law的兴趣。而且这个图里面大家可以看到跟刚才的我们的说的本体的那个度分布。相比呀这个图的这个度分布啊,他的这个结果这个泡儿闹的现象是非常明显。让我们稍微再回顾回到前面看一下,我们说我们这个地方的度分布,那么相对来讲还有一点这个这个鞋鞋,鞋鞋啊这个调还是有一些异常的这个情况的。那么在这个图里面,那么他的这个情况呢相对来讲更加明显一些。另外呢它的最大连通分支,那么嗯这个能达到了这个占地来在这个88%左右。那么它的有效直径呢大概在11左右,那么也满足了我们做的这个小心思小世界的现象等等的。那么这里呢我们可以做一个最终啊,我们可以做一个这个简单的这个比较。我们做这个于外部的这个分析呢,她不是这个图结构的分析啊,她不是一个这个呃就是说从从呃原创性的一个工作实际上来对于这个图结构的分析的有很多很多的相关,比如说针对真实世界的分析。那吧靠的很近的,比如说就对于我们做的互联网分析,万维网的分析。那么这里呢我们就把万维网和这个与意外吧进行一些这个对比,看一看他们的一些这个分析上面的一些结论,啊,他的大概的一些东西。那么这里呢我们时常可以看到第一个我姐论上面整个的这个万维网和语义网。他实际上都是属于一种无标度的这个吗?也就是说scale freed满足这个Paolo利率分布的情况。那么这种网络唻,那么它比较符合这个真实世界的这种情况。那么他表明呢这种这种网络了是一种自发形成的,而不是
不知道情况。那么这种网络来那么它比较符合这个真实世界的这种情况。那么他表明呢这种这种网络了是一种自发形成的,而不是一种人造的,知道吧?人造的网络来经常他不会满足了这个无标度的或者这个这个幂律分布的这种担心。第二个我们从这个分布的这样的一个一个它的结构上看来。这个万维网来有很多的这个分析的一些结论,有着最具代表性的制作。万维网的这个结构啊,他是一个这个蝴蝶结的这样一个结果,这个蝴蝶结来就是我们说的这个呃这边一个节这边一个节中间来有一个圆的这样一个结构。见到蝴蝶结的解构了,是这个万维网它的一个这个总结。中间的那块呢是营销合作的著名的这些网站。那么而两边呢一边呢是这个主要是出租的网站。另外一边但是主要是入读的话。所以呢这样的形成了一个我们做的这个蝴蝶结的这个结构。而与意外不来,目前为止还没有这个分析的这个。报告指出来他到底与一外国是一个什么样的这个切割,那么这个呢还有带来进一步的研究。包括来还有带一些这个想象力,因为这个外部的这个蝴蝶结的结构,包括后来的做的这个像茶壶的结构啊等等等,那么实际上也是这个人的一些这个直观的根据结果的一种想象。那么但是他想象的这个非常符合那个大家非常承认他的这个小将。而与外部来目前呢还没有分析出来他的一个准确的这个结构,那么这个想象方面呢也缺乏一些。第三个男士说的是这个弹性,这个方面我们刚才说的这个弹性啊就是一种抗压的能力。在Web上面呢它使劲大了,是一种高弹性的结构,大家可能会感觉到比如说我们在外部上面一个信息啊,经常会存在很多的这个荣誉,大家比如说会这个进行转帖,然后copy了好多的地方。那么即使一个网站当掉了,也不影响来你去访问到一些关键信息,因为在其他的网站上你也可以找到。所以这个呢它是一种高弹性的一种表现。而语义网与外部的他十档是一个相对来讲第一弹一些的一种结构。因为雨衣外部里面他的所有的数据啊依赖于我们说的这个我们的区打不了语言啊,df语言等等,也就是说对于这部分的原语,那么他实际上起到了一个核心的做假设,比如说我把owl class,这样一个节点把它删除掉。那么一下子我的整个雨衣外部里面的数据啊,他的整个的图结构就会被破坏,所以呢这是他的一个低弹性的那种情况。所以呢这种高弹性和低弹性,那么展现了这个外部和与15000之间的一个不太一样的地方。最后呢,关于Web和语义外部来实际的他们都满足了一个小世界的现象。外国人一般来讲的也可以通过十几部到达任意的一个网站而与1万步了,刚才我们看大哥来在十左右这样一个结果。因为我们说刚才我们说有一些高哦这个她因为一些低弹性,因为有一些节点非常重要,有次下owl,klass,RDF type等等的这些节点非常重要。那么所以的你的这个节点总是可以通过有的ow,class啊,df,太不啊等等等链接到其他的节点。所以在很容易去理解他们这个小世界的这个现象是应该来讲很容易成立的。虽然这几个指标从这样的一个观点上面会看出来,他也不是这几个指标之间是完全无关的。他也表明了他们一些指标上有一定的这个相关联存在一定的这个相互影响,这样这个相互作用这样子的特点。那么这里面呢还包括了一些关于有个社会基于语音的社会网络分析等等的一些应用。那么他是这个语义网和社会网络分析的一个交叉领域,出现了一些用户为中心的一系列的应用,比如说博客啊,大重分类呀,喂鸡鸭等等的。这些的我把它撤回来,叫外婆2.0。于外部的对外部上的这个社会网络分析啊提供了一种补充,它可以区分的不同方式的一些联系。允许更复杂的一些分析方案。比如说我们将与以往社会网络分析,外部2.0等等结合在一起,我就可以更好的去支持了人们的协同工作和经验交流。而语义网呢从四个社会网络分析总监来长期积累的这样一些经验。和技术中间的受益,并且可能在外部2.0中间发现一些新的可能性和测试平台。另外,采用社会网络分析技术可以分析的语义网的社区的一些社会网络和其的协同结构。并且去改进了一个社区的这个户主叫父亲,比如说我们也可以分析分析与一,外部里面的这些人。那么研究人员他们之间的是怎么样的一些关系等等。那么在这里呢,那么社会网络分析的没有会讲的社会网络分析的,他不是这个网络分析的单元,不是角色。而是呢个体集合以及他们之间的关系的实体网络分析的方法来主要集中于角色和关联组成的,对。若干队组成的组以及更大的系统,包括了个体,小组或者整个网络。那么这个社会网络分析在它可以帮助去揭示一些连接比较紧密的聚类或者应用社区。支持的很多的这个度量这个活跃性啊,中间状态紧密性等等。那么这些内容呢我们放到了这个下节课里面的我们再去再展开的再去讲一讲。啊,我今天克莱就上到这边那么提醒一下,再次提醒一下大家,要把这个我们的课后的这个课堂这个讨论的分组啊尽快的这个返回。行吧,我刚才看到已经有同学在这个问一些组队情况呢,那么大家来尽可能早一点找到自己的这个搭档。怎么把我们今天克莱就上到这边,我就下课吧。