转载至:https://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html
和https://blog.csdn.net/pursue_my_life/article/details/80253469
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
首先根据该数组元素构建一个完全二叉树,得到;
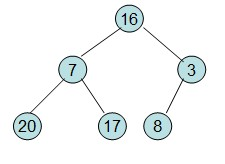
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
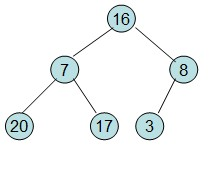
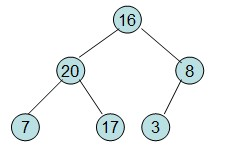
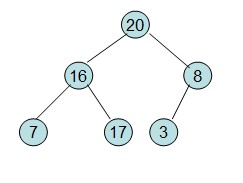
20和16交换后,16不满足堆的性质,因此需重新调整
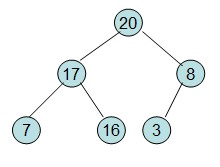
这样就得到了初始堆。
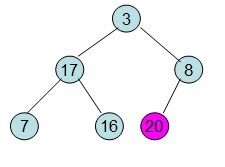
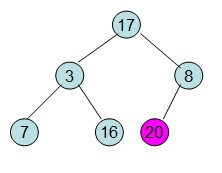
此时3位于堆顶不满足堆的性质,则需要调整继续调整:
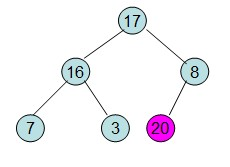


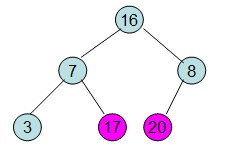

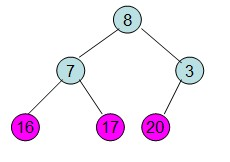
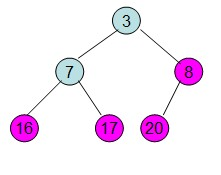
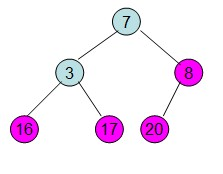
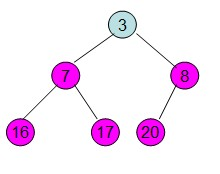
这样整个区间便有序了。
从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
堆排序Step:
一)建树部分
1.找到一个树的最后一个非叶子节点,计算公式为(n-1)/2,然后遍历树的每个非叶节点,使其符合堆的规则
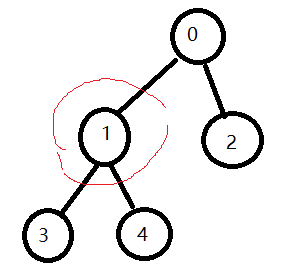
红圈为最后一个非叶子节点
1 void make_heap(int *a,int len){ 2 for(int i=(len-1)/2;i>=0;--i) //遍历每个非叶子节点 3 adjust_heap(a,i,len); //调整堆 4 }
2.要使某个节点的当前节点的字数符合堆规律,需要以下操作:
1 void adjust_heap(int* a,int node,int size){ 2 int left=2*node+1; 3 int right=2*node+2; 4 int max=node; 5 if(left<size && a[left]>a[max]) 6 max=left; 7 if(right<size && a[right]>a[max]) 8 max=right; 9 if(max!=node){ 10 swap(a[max],a[node]); //交换节点 11 adjust_heap(a,max,size); 12 } 13 }
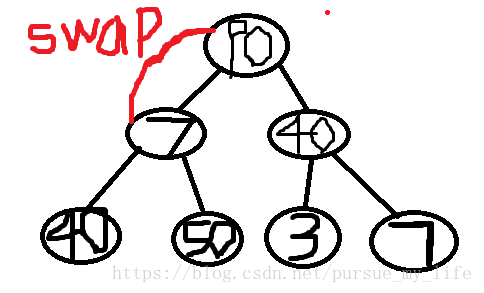
90和7交换后,发现7不能管住原来90的两个儿子,那怎么办呢??那就继续调用adjust()让他符合。
所以需要递归。
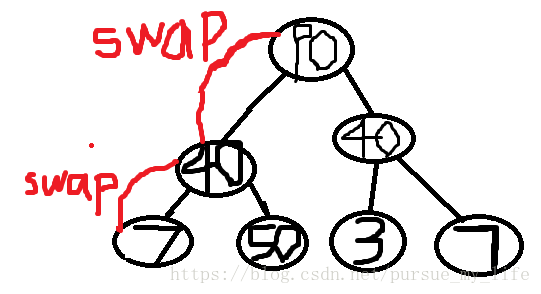
到此为止
这个整个树都符合堆的规律了,最大堆就已经建造好了。
二)排序部分
现在我们需要把最大堆中的元素排降序, 该如何呢 ???
将堆的顶部,与最后一个元素交换。 此时除了最后一个元素外, 剩下元素所组成的树已经不是 堆了。(因为此时顶部的元素可能比较小)。 所以, 要将剩下的元素通过 adjust函数调整成 堆。
然后继续将剩余元素中的最后一个元素 与 新堆的顶部交换 。。。。。。
代码如下:
1 for(int i=len-1;i>=0;i--){ 2 swap(a[0],a[i]); //将当前最大的放置到数组末尾 3 adjust_heap(a,0,i); //将未完成排序的部分继续进行堆排序 4 5 }
完整代码如下:
1 #include<iostream> 2 using namespace std; 3 void adjust_heap(int* a,int node,int size){ 4 int left=2*node+1; 5 int right=2*node+2; 6 int max=node; 7 if(left<size && a[left]>a[max]){ 8 max=left; 9 } 10 if(right<size && a[right]>a[max]){ 11 max=right; 12 } 13 if(max!=node){ 14 swap(a[max],a[node]); 15 adjust_heap(a,max,size); 16 } 17 } 18 void heap_sort(int* a,int len){ 19 for(int i=len/2;i>=0;--i) 20 adjust_heap(a,i,len); 21 for(int i=len-1;i>=0;i--){ 22 swap(a[0],a[i]); //将当前最大的放置到数组末尾 23 adjust_heap(a,0,i); //将未完成排序的部分继续进行堆排序 24 } 25 } 26 int main(){ 27 int a[10]={3,2,7,4,2,-999,-21,99,0,9}; 28 int len=sizeof(a)/sizeof(int); 29 for(int i=0;i<len;++i) 30 cout<<a[i]<<' '; 31 cout<<endl; 32 heap_sort(a,len); 33 for(int i=0;i<len;++i) 34 cout<<a[i]<<' '; 35 cout<<endl; 36 return 0; 37 }
而堆排序中的几个函数,还是可以通过优化来提升 时间复杂度的。比如 adjust()函数的优化
如果在用 adjust在调整最大堆时, 交换需要以下操作:
temp = a[node];
a[node] = a[max];
a[max] = temp;
需要操作三次,100000次 的交换需要操作 300000次。太过于耗时。所以我们可以做类似于插入排序的优化。
if( 节点的某一个儿子 > 节点本身 )
用 temp 把儿子存起来, 并把节点赋值给儿子;
用temp上浮一层到节点的位置, 继续执行判断, 这样一层层不停的上浮。直到不符合条件
if( temp < 同一层的兄弟节点 || temp < 父亲节点)
把 temp 赋值给当前层的元素;
这样省去了每次的交换, 100000的操作只需要操作100000次。大大提高了效率
本人才疏学浅,孤陋寡闻(略去一万字),有错误请指出。