mq的作用主要是用来解耦,削峰,异步,
增加MQ,系统的复杂性也会增加很多,
也会带来其他的问题,比如MQ挂了怎么办,怎么保持数据的幂等性
幂等性问题通俗点讲就是保证数据不被重复消费,同时数据也不能少,
也就是数据一致性问题。
下面是MQ丢失的3种情况
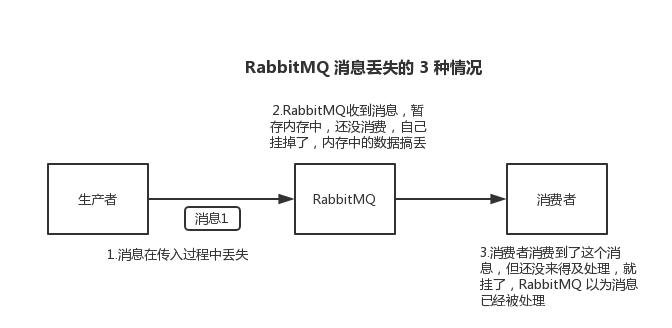
1,生产者发送消息至MQ的数据丢失
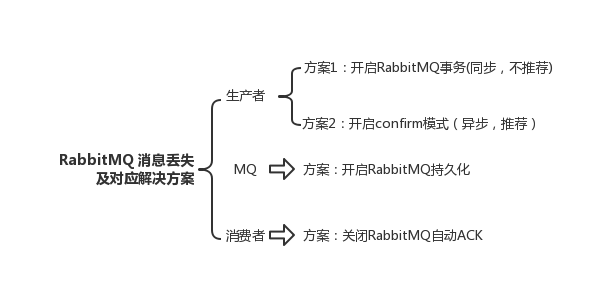
解决方法:在生产者端开启comfirm 确认模式,你每次写的消息都会分配一个唯一的 id,
然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了
2,MQ收到消息,暂存内存中,还没消费,自己挂掉,数据会都丢失
解决方式:MQ设置为持久化。将内存数据持久化到磁盘中
3,消费者刚拿到消息,还没处理,挂掉了,MQ又以为消费者处理完
解决方式:用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须关闭 RabbitMQ 的自动 ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack 了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
数据重复的问题简单的多,就是在消费端判断数据是否已经被消费过
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id
之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写
Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。