目录
- scitit-learn SVM API说明
- 鸢尾花SVM特征分类
- 鸢尾花数据不同分类器准确率比较
- 不同SVM核函数效果比较
- 异常值检测(OneClassSVM)
- 分类问题总结
一、scitit-learn SVM API说明
1.1 算法库概述分类算法
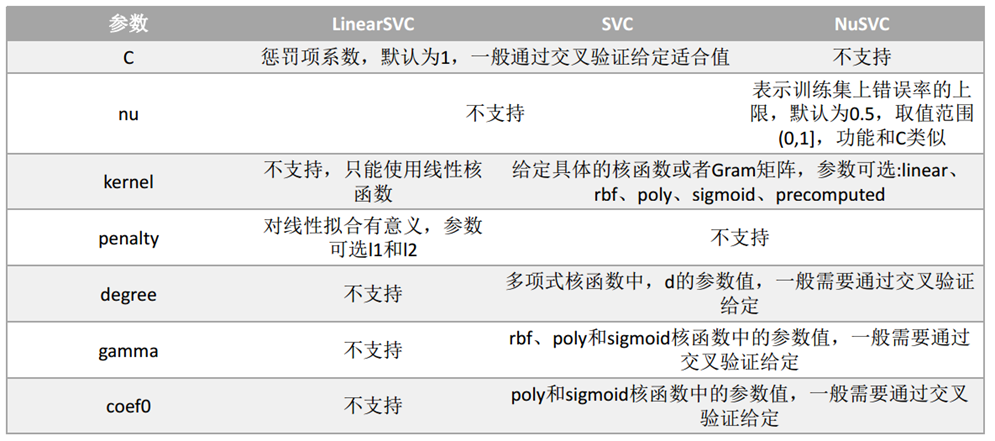
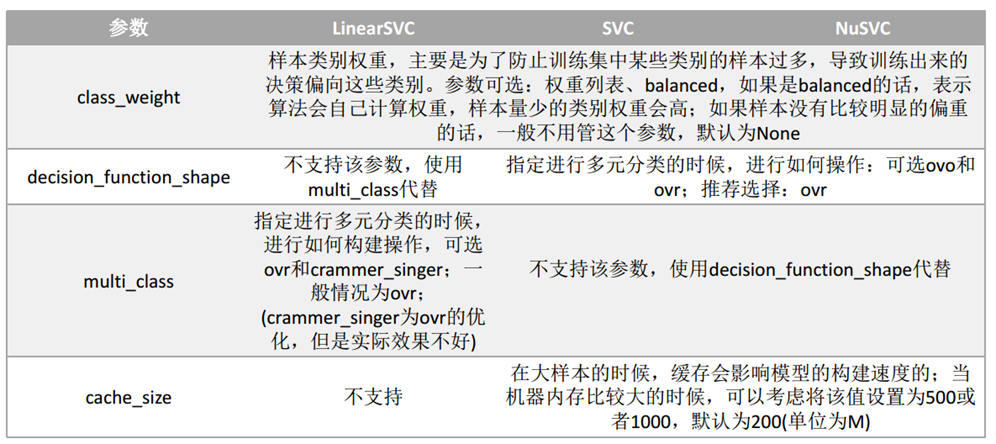
svm.SVC API说明:也可见另一篇博文:https://www.cnblogs.com/yifanrensheng/p/11863324.html
参数说明:
- C: 误差项的惩罚系数,默认为1.0;一般为大于0的一个数字,C越大表示在训练过程中对于总误差的关注度越高,也就是说当C越大的时候,对于训练集的表现会越好,但是有可能引发过度拟合的问题(overfiting)
- kernel:指定SVM内部函数的类型,可选值:linear、poly、rbf、sigmoid、precomputed(基本不用,有前提要求,要求特征属性数目和样本数目一样);默认是rbf;
- degree:当使用多项式函数作为svm内部的函数的时候,给定多项式的项数,默认为3
- gamma:当SVM内部使用poly、rbf、sigmoid的时候,核函数的系数值,当默认值为auto的时候,实际系数为1/n_features
- coef0: 当核函数为poly或者sigmoid的时候,给定的独立系数,默认为0
- probability:是否启用概率估计,默认不启动,不太建议启动
- shrinking:是否开启收缩启发式计算,默认为True
- tol: 模型构建收敛参数,当模型的的误差变化率小于该值的时候,结束模型构建过程,默认值:1e-3
- cache_size:在模型构建过程中,缓存数据的最大内存大小,默认为空,单位MB
- class_weight:给定各个类别的权重,默认为空
- max_iter:最大迭代次数,默认-1表示不限制
- decision_function_shape: 决策函数,可选值:ovo和ovr,默认为None;推荐使用ovr;(1.7以上版本才有)
1.2 scitit-learn SVM算法库概述回归算法

1.3 scitit-learn SVM-OneClassSVM

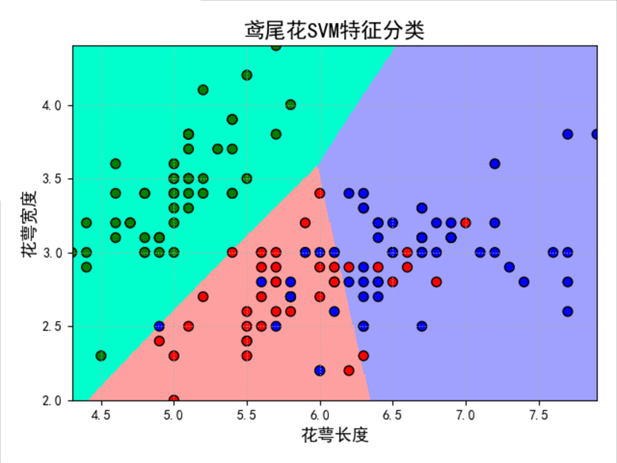
二、鸢尾花SVM特征分类
1 # Author:yifan
2 import numpy as np
3 import pandas as pd
4 import matplotlib as mpl
5 import matplotlib.pyplot as plt
6 import warnings
7
8 from sklearn import svm #svm导入
9 from sklearn.model_selection import train_test_split
10 from sklearn.metrics import accuracy_score
11 from sklearn.exceptions import ChangedBehaviorWarning
12
13 ## 设置属性防止中文乱码
14 mpl.rcParams['font.sans-serif'] = [u'SimHei']
15 mpl.rcParams['axes.unicode_minus'] = False
16
17 warnings.filterwarnings('ignore', category=ChangedBehaviorWarning)
18
19 ## 读取数据
20 # 'sepal length', 'sepal width', 'petal length', 'petal width'
21 iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
22 path = './datas/iris.data' # 数据文件路径
23 data = pd.read_csv(path, header=None)
24 x, y = data[list(range(4))], data[4]
25 y = pd.Categorical(y).codes #把文本数据进行编码,比如a b c编码为 0 1 2; 可以通过pd.Categorical(y).categories获取index对应的原始值
26 x = x[[0, 1]] # 获取第一列和第二列
27
28 ## 数据分割
29 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0, train_size=0.8)
30 ## 数据SVM分类器构建
31 clf = svm.SVC(C=1,kernel='rbf',gamma=0.1)
32 #gamma值越大,训练集的拟合就越好,但是会造成过拟合,导致测试集拟合变差
33 #gamma值越小,模型的泛化能力越好,训练集和测试集的拟合相近,但是会导致训练集出现欠拟合问题,从而,准确率变低,导致测试集准确率也变低。
34 ## 模型训练
35 #SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape=None, degree=3, gamma=0.1, kernel='rbf',
36 #max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
37 clf.fit(x_train, y_train)
38
39 ## 计算模型的准确率/精度
40 print (clf.score(x_train, y_train))
41 print ('训练集准确率:', accuracy_score(y_train, clf.predict(x_train)))
42 print (clf.score(x_test, y_test))
43 print ('测试集准确率:', accuracy_score(y_test, clf.predict(x_test)))
44
45 # 画图
46 N = 500
47 x1_min, x2_min = x.min()
48 x1_max, x2_max = x.max()
49 # print(x.max())
50 t1 = np.linspace(x1_min, x1_max, N)
51 t2 = np.linspace(x2_min, x2_max, N)
52 x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
53 grid_show = np.dstack((x1.flat, x2.flat))[0] # 测试点
54
55 grid_hat = clf.predict(grid_show) # 预测分类值
56 grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
57
58 cm_light = mpl.colors.ListedColormap(['#00FFCC', '#FFA0A0', '#A0A0FF'])
59 cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
60 plt.figure(facecolor='w')
61 ## 区域图
62 plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light)
63 ## 所以样本点
64 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
65 ## 测试数据集
66 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
67 ## lable列表
68 plt.xlabel(iris_feature[0], fontsize=13)
69 plt.ylabel(iris_feature[1], fontsize=13)
70 plt.xlim(x1_min, x1_max)
71 plt.ylim(x2_min, x2_max)
72 plt.title(u'鸢尾花SVM特征分类', fontsize=16)
73 plt.grid(b=True, ls=':')
74 plt.tight_layout(pad=1.5)
75 plt.show()
76
结果:
0.85
训练集准确率: 0.85
0.7333333333333333
测试集准确率: 0.7333333333333333
三、鸢尾花数据不同分类器准确率比较
1 # Author:yifan
2
3 import numpy as np
4 import pandas as pd
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 from sklearn.svm import SVC
8 from sklearn.model_selection import train_test_split
9 from sklearn.metrics import accuracy_score
10 from sklearn.linear_model import LogisticRegression,RidgeClassifier
11 from sklearn.neighbors import KNeighborsClassifier
12
13 ## 设置属性防止中文乱码
14 mpl.rcParams['font.sans-serif'] = [u'SimHei']
15 mpl.rcParams['axes.unicode_minus'] = False
16 ## 读取数据
17 # 'sepal length', 'sepal width', 'petal length', 'petal width'
18 iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
19 path = './datas/iris.data' # 数据文件路径
20 data = pd.read_csv(path, header=None)
21 x, y = data[list(range(4))], data[4]
22 y = pd.Categorical(y).codes
23 x = x[[0, 1]]
24
25 ## 数据分割
26 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=28, train_size=0.6)
27
28 # 数据SVM分类器构建
29 svm = SVC(C=1, kernel='linear')
30 ## Linear分类器构建
31 lr = LogisticRegression()
32 rc = RidgeClassifier()#ridge是为了解决特征大于样本,而导致分类效果较差的情况,而提出的
33 #svm有一个重要的瓶颈——当特征数大于样本数的时候,效果变差
34 knn = KNeighborsClassifier()
35
36 ## 模型训练
37 svm.fit(x_train, y_train)
38 lr.fit(x_train, y_train)
39 rc.fit(x_train, y_train)
40 knn.fit(x_train, y_train)
41
42 ## 效果评估
43 svm_score1 = accuracy_score(y_train, svm.predict(x_train))
44 svm_score2 = accuracy_score(y_test, svm.predict(x_test))
45
46 lr_score1 = accuracy_score(y_train, lr.predict(x_train))
47 lr_score2 = accuracy_score(y_test, lr.predict(x_test))
48
49 rc_score1 = accuracy_score(y_train, rc.predict(x_train))
50 rc_score2 = accuracy_score(y_test, rc.predict(x_test))
51
52 knn_score1 = accuracy_score(y_train, knn.predict(x_train))
53 knn_score2 = accuracy_score(y_test, knn.predict(x_test))
54
55 ## 画图
56 x_tmp = [0,1,2,3]
57 y_score1 = [svm_score1, lr_score1, rc_score1, knn_score1]
58 y_score2 = [svm_score2, lr_score2, rc_score2, knn_score2]
59
60 plt.figure(facecolor='w')
61 plt.plot(x_tmp, y_score1, 'r-', lw=2, label=u'训练集准确率')
62 plt.plot(x_tmp, y_score2, 'g-', lw=2, label=u'测试集准确率')
63 plt.xlim(0, 3)
64 plt.ylim(np.min((np.min(y_score1), np.min(y_score2)))*0.9, np.max((np.max(y_score1), np.max(y_score2)))*1.1)
65 plt.legend(loc = 'lower right')
66 plt.title(u'鸢尾花数据不同分类器准确率比较', fontsize=16)
67 plt.xticks(x_tmp, [u'SVM', u'Logistic', u'Ridge', u'KNN'], rotation=0)
68 plt.grid(b=True)
69 plt.show()
70
71
72 ### 画图比较
73 N = 500
74 x1_min, x2_min = x.min()
75 x1_max, x2_max = x.max()
76
77 t1 = np.linspace(x1_min, x1_max, N)
78 t2 = np.linspace(x2_min, x2_max, N)
79 x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
80 grid_show = np.dstack((x1.flat, x2.flat))[0] # 测试点
81
82 ## 获取各个不同算法的测试值
83 svm_grid_hat = svm.predict(grid_show)
84 svm_grid_hat = svm_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
85
86 lr_grid_hat = lr.predict(grid_show)
87 lr_grid_hat = lr_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
88
89 rc_grid_hat = rc.predict(grid_show)
90 rc_grid_hat = rc_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
91
92 knn_grid_hat = knn.predict(grid_show)
93 knn_grid_hat = knn_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
94
95 ## 画图
96 cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
97 cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
98 plt.figure(facecolor='w', figsize=(14,7))
99
100 ### svm 区域图
101 plt.subplot(221)
102 plt.pcolormesh(x1, x2, svm_grid_hat, cmap=cm_light)
103 ## 所以样本点
104 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
105 ## 测试数据集
106 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
107 ## lable列表
108 plt.xlabel(iris_feature[0], fontsize=13)
109 plt.ylabel(iris_feature[1], fontsize=13)
110 plt.xlim(x1_min, x1_max)
111 plt.ylim(x2_min, x2_max)
112 plt.title(u'鸢尾花SVM特征分类', fontsize=16)
113 plt.grid(b=True, ls=':')
114 plt.tight_layout(pad=1.5)
115
116 plt.subplot(222)
117 ## 区域图
118 plt.pcolormesh(x1, x2, lr_grid_hat, cmap=cm_light)
119 ## 所以样本点
120 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
121 ## 测试数据集
122 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
123 ## lable列表
124 plt.xlabel(iris_feature[0], fontsize=13)
125 plt.ylabel(iris_feature[1], fontsize=13)
126 plt.xlim(x1_min, x1_max)
127 plt.ylim(x2_min, x2_max)
128 plt.title(u'鸢尾花Logistic特征分类', fontsize=16)
129 plt.grid(b=True, ls=':')
130 plt.tight_layout(pad=1.5)
131
132 plt.subplot(223)
133 ## 区域图
134 plt.pcolormesh(x1, x2, rc_grid_hat, cmap=cm_light)
135 ## 所以样本点
136 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
137 ## 测试数据集
138 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
139 ## lable列表
140 plt.xlabel(iris_feature[0], fontsize=13)
141 plt.ylabel(iris_feature[1], fontsize=13)
142 plt.xlim(x1_min, x1_max)
143 plt.ylim(x2_min, x2_max)
144 plt.title(u'鸢尾花Ridge特征分类', fontsize=16)
145 plt.grid(b=True, ls=':')
146 plt.tight_layout(pad=1.5)
147
148 plt.subplot(224)
149 ## 区域图
150 plt.pcolormesh(x1, x2, knn_grid_hat, cmap=cm_light)
151 ## 所以样本点
152 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
153 ## 测试数据集
154 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
155 ## lable列表
156 plt.xlabel(iris_feature[0], fontsize=13)
157 plt.ylabel(iris_feature[1], fontsize=13)
158 plt.xlim(x1_min, x1_max)
159 plt.ylim(x2_min, x2_max)
160 plt.title(u'鸢尾花KNN特征分类', fontsize=16)
161 plt.grid(b=True, ls=':')
162 plt.tight_layout(pad=1.5)
163 plt.show()
164
结果:
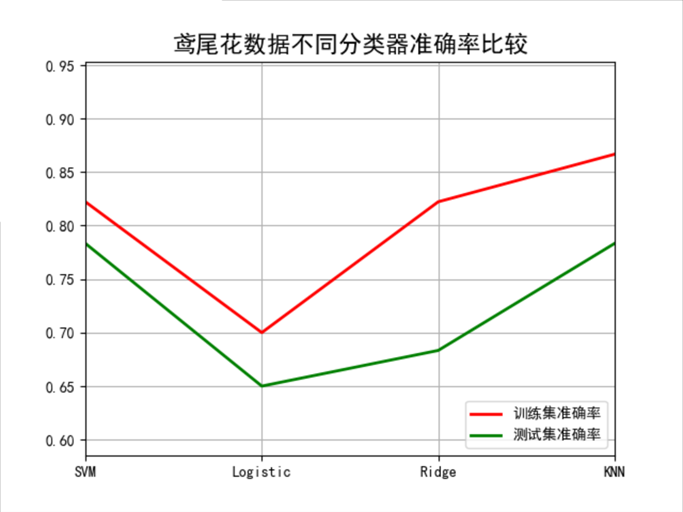

四、不同SVM核函数效果比较
1 # Author:yifan
2 import time
3 import numpy as np
4 import pandas as pd
5 import matplotlib as mpl
6 import matplotlib.pyplot as plt
7 from sklearn.svm import SVC
8 from sklearn.model_selection import train_test_split
9 from sklearn.metrics import accuracy_score
10
11 ## 设置属性防止中文乱码
12 mpl.rcParams['font.sans-serif'] = [u'SimHei']
13 mpl.rcParams['axes.unicode_minus'] = False
14 ## 读取数据
15 # 'sepal length', 'sepal width', 'petal length', 'petal width'
16 iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
17 path = './datas/iris.data' # 数据文件路径
18 data = pd.read_csv(path, header=None)
19 x, y = data[list(range(4))], data[4]
20 y = pd.Categorical(y).codes
21 x = x[[0, 1]]
22
23 ## 数据分割
24 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=28, train_size=0.6)
25
26 ## 数据SVM分类器构建
27 svm1 = SVC(C=1, kernel='linear')
28 svm2 = SVC(C=1, kernel='rbf')
29 svm3 = SVC(C=1, kernel='poly')
30 svm4 = SVC(C=1, kernel='sigmoid')
31
32 ## 模型训练
33 t0=time.time()
34 svm1.fit(x_train, y_train)
35 t1=time.time()
36 svm2.fit(x_train, y_train)
37 t2=time.time()
38 svm3.fit(x_train, y_train)
39 t3=time.time()
40 svm4.fit(x_train, y_train)
41 t4=time.time()
42
43 ### 效果评估
44 svm1_score1 = accuracy_score(y_train, svm1.predict(x_train))
45 svm1_score2 = accuracy_score(y_test, svm1.predict(x_test))
46
47 svm2_score1 = accuracy_score(y_train, svm2.predict(x_train))
48 svm2_score2 = accuracy_score(y_test, svm2.predict(x_test))
49
50 svm3_score1 = accuracy_score(y_train, svm3.predict(x_train))
51 svm3_score2 = accuracy_score(y_test, svm3.predict(x_test))
52
53 svm4_score1 = accuracy_score(y_train, svm4.predict(x_train))
54 svm4_score2 = accuracy_score(y_test, svm4.predict(x_test))
55
56 ## 画图
57 x_tmp = [0,1,2,3]
58 t_score = [t1 - t0, t2-t1, t3-t2, t4-t3]
59 y_score1 = [svm1_score1, svm2_score1, svm3_score1, svm4_score1]
60 y_score2 = [svm1_score2, svm2_score2, svm3_score2, svm4_score2]
61
62 plt.figure(facecolor='w', figsize=(12,6))
63
64
65 plt.subplot(121)
66 plt.plot(x_tmp, y_score1, 'r-', lw=2, label=u'训练集准确率')
67 plt.plot(x_tmp, y_score2, 'g-', lw=2, label=u'测试集准确率')
68 plt.xlim(-0.3, 3.3)
69 plt.ylim(np.min((np.min(y_score1), np.min(y_score2)))*0.9, np.max((np.max(y_score1), np.max(y_score2)))*1.1)
70 plt.legend(loc = 'lower left')
71 plt.title(u'模型预测准确率', fontsize=13)
72 plt.xticks(x_tmp, [u'linear-SVM', u'rbf-SVM', u'poly-SVM', u'sigmoid-SVM'], rotation=0)
73 plt.grid(b=True)
74
75 plt.subplot(122)
76 plt.plot(x_tmp, t_score, 'b-', lw=2, label=u'模型训练时间')
77 plt.title(u'模型训练耗时', fontsize=13)
78 plt.xticks(x_tmp, [u'linear-SVM', u'rbf-SVM', u'poly-SVM', u'sigmoid-SVM'], rotation=0)
79 plt.xlim(-0.3, 3.3)
80 plt.grid(b=True)
81 plt.suptitle(u'鸢尾花数据SVM分类器不同内核函数模型比较', fontsize=16)
82
83 plt.show()
84
85
86 ### 预测结果画图
87 ### 画图比较
88 N = 500
89 x1_min, x2_min = x.min()
90 x1_max, x2_max = x.max()
91
92 t1 = np.linspace(x1_min, x1_max, N)
93 t2 = np.linspace(x2_min, x2_max, N)
94 x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
95 grid_show = np.dstack((x1.flat, x2.flat))[0] # 测试点
96
97 ## 获取各个不同算法的测试值
98 svm1_grid_hat = svm1.predict(grid_show)
99 svm1_grid_hat = svm1_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
100
101 svm2_grid_hat = svm2.predict(grid_show)
102 svm2_grid_hat = svm2_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
103
104 svm3_grid_hat = svm3.predict(grid_show)
105 svm3_grid_hat = svm3_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
106
107 svm4_grid_hat = svm4.predict(grid_show)
108 svm4_grid_hat = svm4_grid_hat.reshape(x1.shape) # 使之与输入的形状相同
109
110 ## 画图
111 cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
112 cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
113 plt.figure(facecolor='w', figsize=(14,7))
114
115 ### svm
116 plt.subplot(221)
117 ## 区域图
118 plt.pcolormesh(x1, x2, svm1_grid_hat, cmap=cm_light)
119 ## 所以样本点
120 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
121 ## 测试数据集
122 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
123 ## lable列表
124 plt.xlabel(iris_feature[0], fontsize=13)
125 plt.ylabel(iris_feature[1], fontsize=13)
126 plt.xlim(x1_min, x1_max)
127 plt.ylim(x2_min, x2_max)
128 plt.title(u'鸢尾花Linear-SVM特征分类', fontsize=16)
129 plt.grid(b=True, ls=':')
130 plt.tight_layout(pad=1.5)
131
132 plt.subplot(222)
133 ## 区域图
134 plt.pcolormesh(x1, x2, svm2_grid_hat, cmap=cm_light)
135 ## 所以样本点
136 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
137 ## 测试数据集
138 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
139 ## lable列表
140 plt.xlabel(iris_feature[0], fontsize=13)
141 plt.ylabel(iris_feature[1], fontsize=13)
142 plt.xlim(x1_min, x1_max)
143 plt.ylim(x2_min, x2_max)
144 plt.title(u'鸢尾花rbf-SVM特征分类', fontsize=16)
145 plt.grid(b=True, ls=':')
146 plt.tight_layout(pad=1.5)
147
148 plt.subplot(223)
149 ## 区域图
150 plt.pcolormesh(x1, x2, svm3_grid_hat, cmap=cm_light)
151 ## 所以样本点
152 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
153 ## 测试数据集
154 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
155 ## lable列表
156 plt.xlabel(iris_feature[0], fontsize=13)
157 plt.ylabel(iris_feature[1], fontsize=13)
158 plt.xlim(x1_min, x1_max)
159 plt.ylim(x2_min, x2_max)
160 plt.title(u'鸢尾花poly-SVM特征分类', fontsize=16)
161 plt.grid(b=True, ls=':')
162 plt.tight_layout(pad=1.5)
163
164 plt.subplot(224)
165 ## 区域图
166 plt.pcolormesh(x1, x2, svm4_grid_hat, cmap=cm_light)
167 ## 所以样本点
168 plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
169 ## 测试数据集
170 plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
171 ## lable列表
172 plt.xlabel(iris_feature[0], fontsize=13)
173 plt.ylabel(iris_feature[1], fontsize=13)
174 plt.xlim(x1_min, x1_max)
175 plt.ylim(x2_min, x2_max)
176 plt.title(u'鸢尾花sigmoid-SVM特征分类', fontsize=16)
177 plt.grid(b=True, ls=':')
178 plt.tight_layout(pad=1.5)
179 plt.show()
结果:
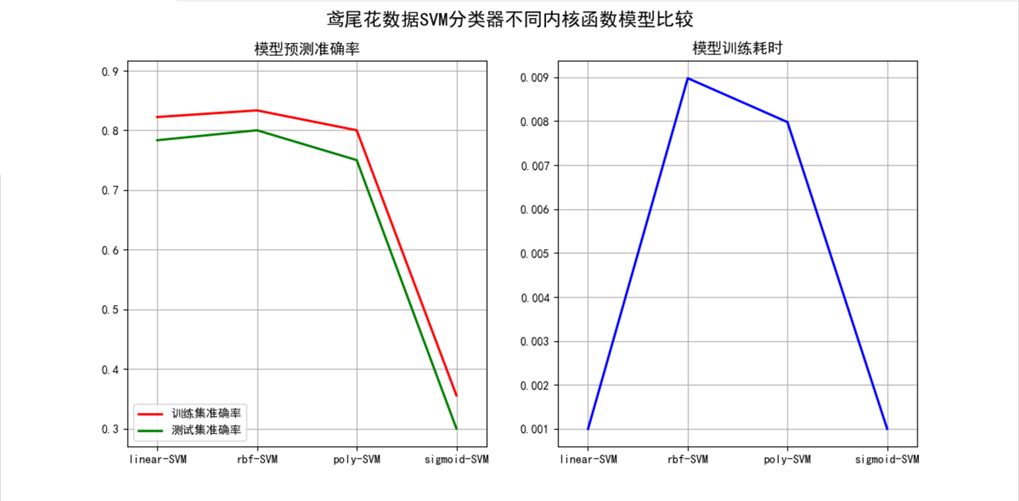
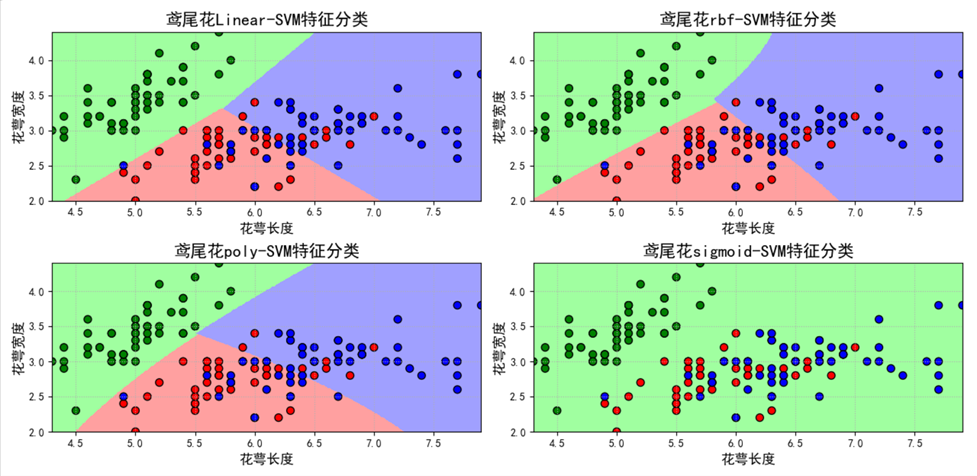
五、异常值检测(OneClassSVM)
1 # Author:yifan
2 import numpy as np
3 import matplotlib.pyplot as plt
4 import matplotlib as mpl
5 import matplotlib.font_manager
6 from sklearn import svm
7 ## 设置属性防止中文乱码
8 mpl.rcParams['font.sans-serif'] = [u'SimHei']
9 mpl.rcParams['axes.unicode_minus'] = False
10
11 # 模拟数据产生
12 xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
13 # 产生训练数据
14 X = 0.3 * np.random.randn(100, 2)
15 X_train = np.r_[X + 2, X - 2]
16 # 产测试数据
17 X = 0.3 * np.random.randn(20, 2)
18 X_test = np.r_[X + 2, X - 2]
19 # 产生一些异常点数据
20 X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
21
22 # 模型训练
23 clf = svm.OneClassSVM(nu=0.01, kernel="rbf", gamma=0.1)
24 clf.fit(X_train)
25
26 # 预测结果获取
27 y_pred_train = clf.predict(X_train)
28 y_pred_test = clf.predict(X_test)
29 y_pred_outliers = clf.predict(X_outliers)
30 # 返回1表示属于这个类别,-1表示不属于这个类别
31 n_error_train = y_pred_train[y_pred_train == -1].size
32 n_error_test = y_pred_test[y_pred_test == -1].size
33 n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
34
35 # 获取绘图的点信息
36 Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
37 Z = Z.reshape(xx.shape)
38
39 # 画图
40 plt.figure(facecolor='w')
41 plt.title("异常点检测")
42 # 画出区域图
43 plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 9), cmap=plt.cm.PuBu)
44 a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred')
45 plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred')
46 # 画出点图
47 s = 40
48 b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=s, edgecolors='k')
49 b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='blueviolet', s=s, edgecolors='k')
50 c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='gold', s=s, edgecolors='k')
51
52 # 设置相关信息
53 plt.axis('tight')
54 plt.xlim((-5, 5))
55 plt.ylim((-5, 5))
56 plt.legend([a.collections[0], b1, b2, c],
57 ["分割超平面", "训练样本", "测试样本", "异常点"],
58 loc="upper left",
59 prop=matplotlib.font_manager.FontProperties(size=11))
60 plt.xlabel("训练集错误率: %d/200 ; 测试集错误率: %d/40 ; 异常点错误率: %d/40"
61 % (n_error_train, n_error_test, n_error_outliers))
62 plt.show()
63
结果:
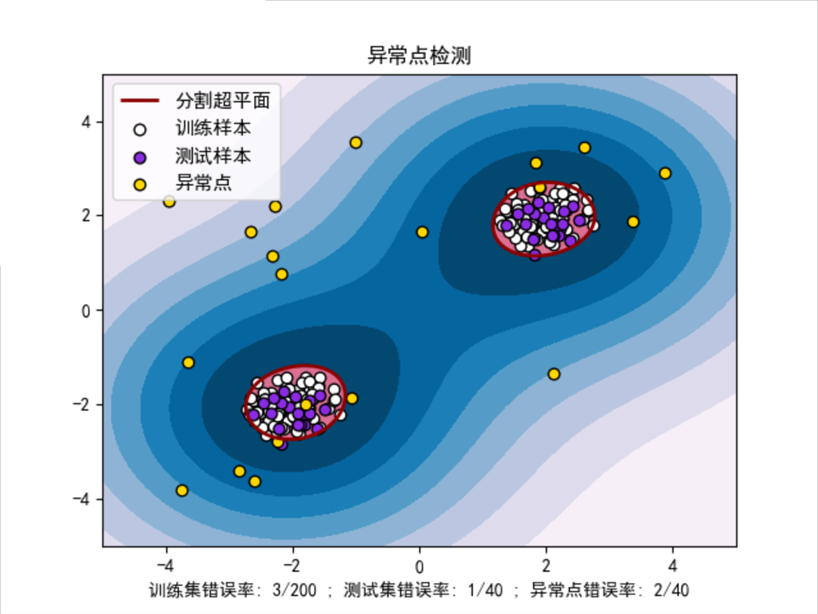
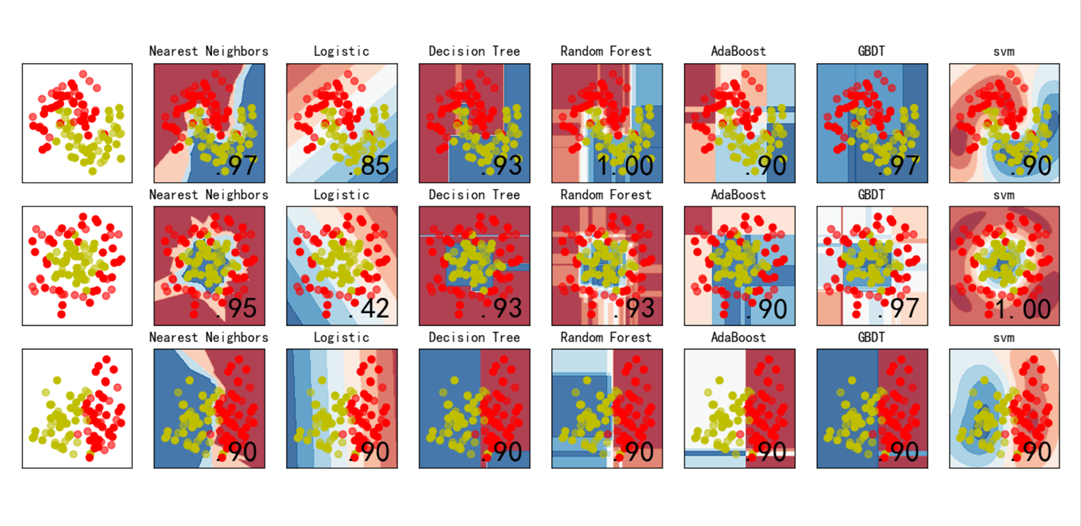
六、分类问题总结
比较逻辑回归、KNN、决策树、随机森林、GBDT、Adaboost、SVM等分类算法的效果,数据集使用sklearn自带的模拟数据进行测试。
# Author:yifan
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib.colors import ListedColormap
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegressionCV
## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
#构造数据
X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,random_state=1, n_clusters_per_class=1)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
linearly_separable = (X, y)
datasets = [make_moons(noise=0.3, random_state=0),
make_circles(noise=0.2, factor=0.4, random_state=1),
linearly_separable]
#建模环节,用list把所有算法装起来
names = ["Nearest Neighbors", "Logistic","Decision Tree", "Random Forest", "AdaBoost", "GBDT","svm"]
classifiers = [
KNeighborsClassifier(3),
LogisticRegressionCV(),
DecisionTreeClassifier(max_depth=5),
RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
AdaBoostClassifier(n_estimators=10,learning_rate=1.5),
GradientBoostingClassifier(n_estimators=10, learning_rate=1.5),
svm.SVC(C=1, kernel='rbf')
]
## 画图
figure = plt.figure(figsize=(27, 9), facecolor='w')
i = 1
h = .02 # 步长
for ds in datasets:
X, y = ds
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4)
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
cm = plt.cm.RdBu
cm_bright = ListedColormap(['r', 'b', 'y'])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
# 画每个算法的图
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
# hasattr是判定某个模型中,有没有哪个参数,
# 判断clf模型中,有没有decision_function
# np.c_让内部数据按列合并
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
else:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(name)
ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'),
size=25, horizontalalignment='right')
i += 1
## 展示图
figure.subplots_adjust(left=.02, right=.98)
plt.show()
# plt.savefig("cs.png")
结果: