一句话简介:2018年发掘的自回归模型,采用预训练和下游微调方式处理NLP任务;解决动态语义问题,word embedding 送入单向transformer中。
一、GPT简介
1.1 背景
目前大多数深度学习方法依靠大量的人工标注信息,这限制了在很多领域的应用。此外,即使在可获得相当大的监督语料情况下,以无监督学习的方式学到的表示也可以提供显着的性能提升。到目前为止,最引人注目的证据是广泛使用预训练词嵌入来提高一系列NLP任务的性能。
1.2 简介
GPT主要出论文《Improving Language Understanding by Generative Pre-Training》,GPT 是"Generative Pre-Training"的简称,从名字看其含义是指的生成式的预训练。
GPT 采用两阶段过程,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。
二、GPT模型概述
2.1 第一阶段
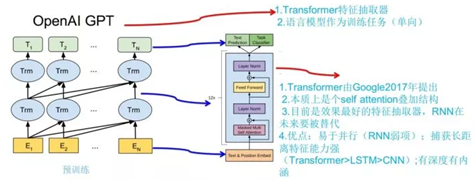
上图展示了 GPT 的预训练过程,其实和 ELMO 是类似的,主要不同在于两点:
- 特征抽取器不是用的 RNN,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN,这个选择很明显是很明智的;
- ELMO使用上下文对单词进行预测,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
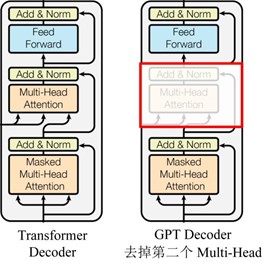
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
2.2 第二阶段
上面讲的是 GPT 如何进行第一阶段的预训练,那么假设预训练好了网络模型,后面下游任务怎么用?它有自己的个性,和 ELMO 的方式大有不同。

上图展示了 GPT 在第二阶段如何使用。
- 对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向 GPT 的网络结构看齐,把任务的网络结构改造成和 GPT 的网络结构是一样的。
- 在做下游任务的时候,利用第一步预训练好的参数初始化 GPT 的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行 Fine-tuning,【类似图像领域预训练的过程】
那怎么改造才能靠近 GPT 的网络结构呢?
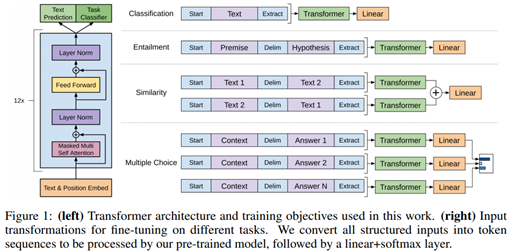
GPT 论文给了一个改造施工图如上:
- 对于分类问题,不用怎么动,加上一个起始和终结符号即可;
- 对于句子关系判断问题,比如 Entailment,两个句子中间再加个分隔符即可;
- 对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
- 对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
2.3 效果
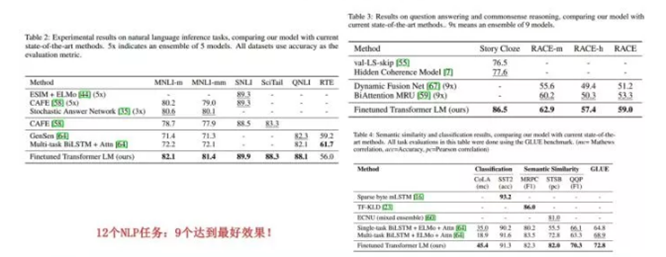
在GPT出来之时:效果是非常令人惊艳的,在 12 个任务里,9 个达到了最好的效果,有些任务性能提升非常明显。
三、GPT模型解析
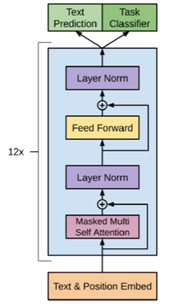
GPT 训练过程分为两个部分,无监督预训练语言模型和有监督的下游任务 fine-tuning。
3.1 预训练语言模型
给定句子 U=[u1, u2, ..., un],GPT 训练语言模型时需要最大化下面的似然函数。

文章中使用的是多层Transformer的decoder的语言模型。这个多层的结构应用multi-headed self-attention在处理输入的文本加上位置信息的前馈网络,输出是词的概念分布。

h0 表示GPT 的输入,Wp 是单词位置的 Embedding,We 是单词的 Embedding。得到输入 h0 之后,需要将 h0 依次传入 GPT 的所有 Transformer Decoder 里,最终得到 ht。最后送到softmax得到 ht 再预测下个单词的概率。
用V表示词汇表大小,L表示最长的句子长度,dim 表示 Embedding 维度,则 Wp 是一个 L×dim 的矩阵,We 是一个V×dim 的矩阵。
3.2 下游任务 fine-tuning
GPT 经过预训练之后,会针对具体的下游任务对模型进行微调。微调的过程采用的是有监督学习,训练样本包括单词序列 [x1, x2, ..., xm] 和 类标 y。GPT 微调的过程中根据单词序列 [x1, x2, ..., xm] 预测类标 y。

Wy 表示预测输出时的参数,微调时候需要最大化以下函数。

GPT 在微调的时候也考虑预训练的损失函数,所以最终需要优化的函数为:

四、总结
GPT 预训练时利用上文预测下一个单词,ELMO和BERT (下一篇将介绍)是根据上下文预测单词,因此在很多 NLP 任务上,GPT 的效果都比 BERT 要差。但是 GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。
优点
- RNN所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。
- 计算速度比循环神经网络更快,易于并行化
- 实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点
- 对于某些类型的任务需要对输入数据的结构作调整
- 对比bert,没有采取双向形式,削弱了模型威力
参考文献
【2】从Word Embedding到Bert模型——自然语言处理预训练技术发展史: https://www.jiqizhixin.com/articles/2018-12-10-8
【3】GPT2 https://www.sohu.com/a/336262203_129720 https://jalammar.github.io/illustrated-gpt2/
【4】Pytorch代码实现: huggingface/pytorch-openai-transformer-lm