目录
- CRF简介
- 序列标注问题
- tensorflow里的条件随机场
- 总结
上一篇介绍了隐马尔科夫模型(HMM)在词性标注任务中的应用,但HMM 引入了马尔科夫假设:即当前时刻的状态只与其前一时刻的状态有关。但是,在序列标注任务中,当前时刻的状态,应该同该时刻的前后的状态均相关。于是,在很多序列标注任务中,引入了条件随机场。本文详细介绍条件随机场在实体识别中的应用和tensorflow中的实现。
一、CRF简介
在NLP中,常用的是线性链的条件随机场,下面做一个简单介绍:
条件随机场(Conditional Random Fields, 以下简称CRF)是给定一组输入序列条件下另一组输出序列的条件概率分布模型(是给定随机变量X条件下,随机变量Y的马尔科夫随机场。)。在自然语言处理中得到了广泛应用,和HMM很相似,去掉了HMM中的齐次Markov假设和观测序列的独立假设。具体可见其他文章系列。
设X={x1,x2,x3,....xn},Y={y1,y2,y3,....yn}均为线性链表示的随机变量序列,若在给定随机变量序列X的情况下,随机变量序列Y的条件概率P(Y,X)构成条件随机场,即满足如下的条件:

从上面的定义可以看出,条件随机场与HMM之间的差异在于,HMM中,Y在i时刻状态与其前一时刻,即y(i-1)相关。而在CRF中,Y在i时刻的状态与其前后时刻,即y(i-1)与y(i+1)均相关。
二、条件随机场的参数化表现形式
我们先列出来CRF的参数化形式。假设P(Y,X)是随机序列Y在给定随机序列X情况下的条件随机场,则在随机变量X取值为x的情况下,随机变量Y的取值y具有如下关系:
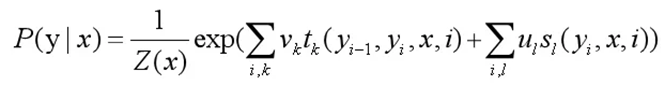
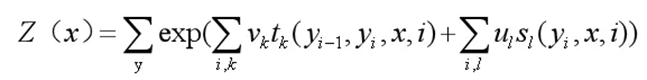
t_k和s_l是特征函数,v_k和u_l是对应的权值
t_k是状态转移函数,v_k是对应的权值;s_l是发射函数,u_l是对应的权值。好的,假如所有的t_k,s_l 和v_k,u_l都已知,我们要算的P(Yi =yi|X)是不是就可以算出来啦?
在给定随机序列X的情况下,计算概率最大Y序列可以用维特比算法,维特比算法在上一章节HMM中有详细的介绍。
大家应该还有一大堆的疑问,t_k,s_l 和v_k,u_l如何确定和学习?在实际中我们如何使用?
下面我们看看在tensorflow里,CRF是怎么实现的,以及我们如何使用的 。
三、tensorflow里的条件随机场
常见命名实体识别任务特征提取的网路结构如下:
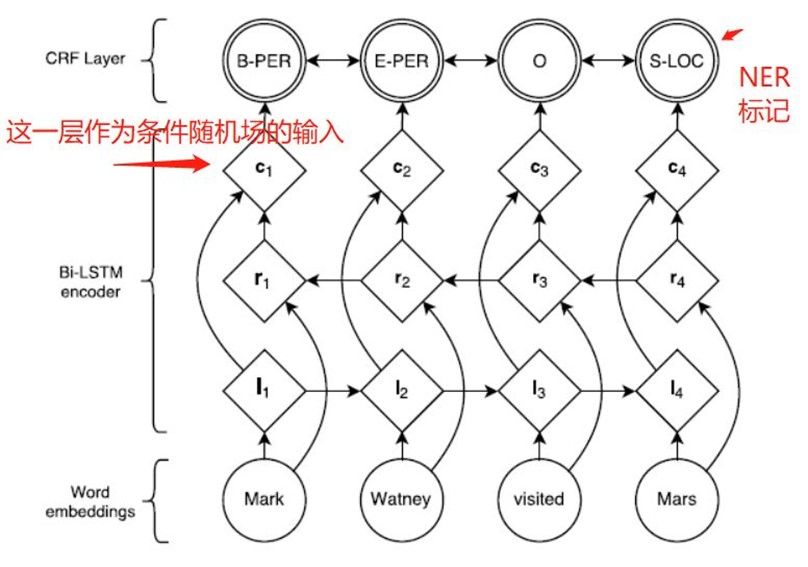
自然语言的句子经过神经网络(双向LSTM)进行特征提取之后,会得到一个特征输出。训练时,将这个特征和相应的标记(label)输入到条件随机场中,就可以计算损失了。预测时,将自然语言输入到该网络,经CRF就可以识别该句子中的实体了,这里重点关注CRF计算损失部分。具体的代码:
3.1 CRF用于损失函数
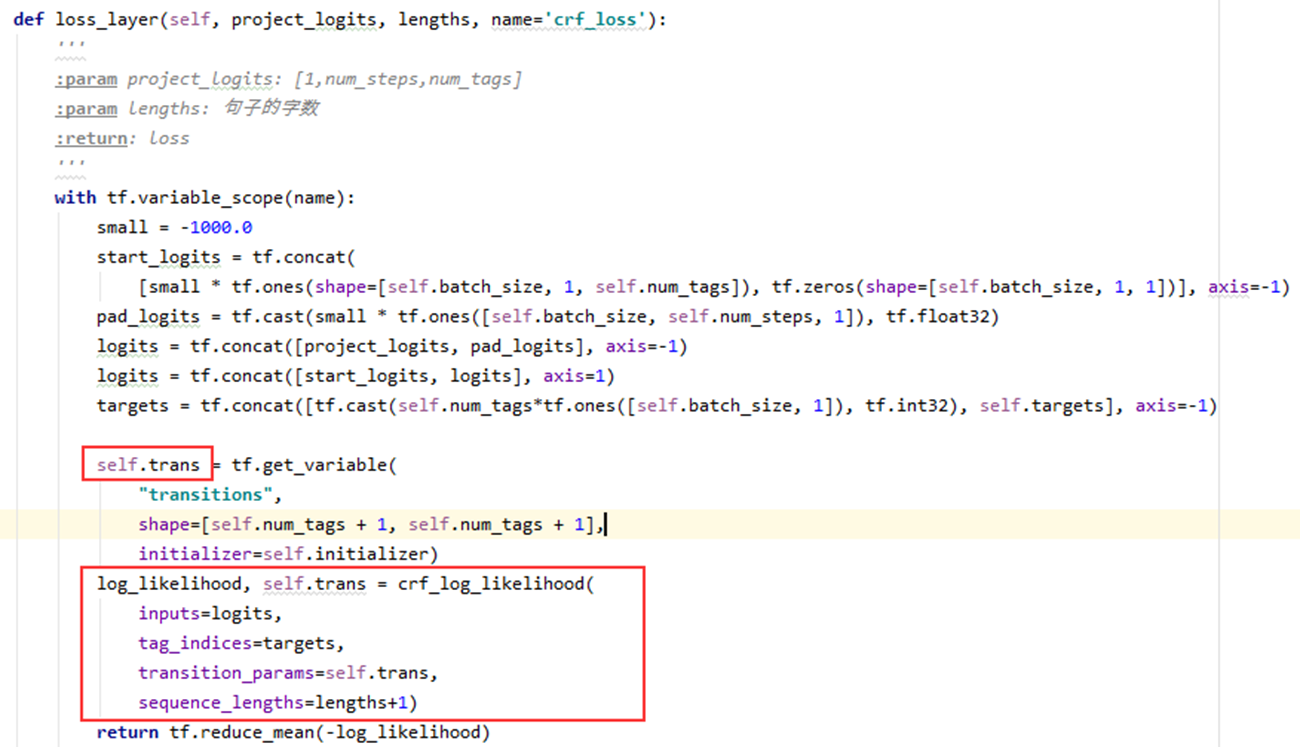
这是项目中的一小部分:定义的损失层,主要依据crf_log_likelihood函数,我们来看下其参数:
inputs=logits:由神经网络最后一层的输出project_logits变换后得到,该矩阵的shape为[batch_size, num_steps, num_tags],第一个是batch size,第二个是输入的句子的长度,第三个标记的个数,即命名实体识别总标记的类别数。
tag_indices=targets:targets是输入句子的label,即每个字的label,它的维度为[batch_size, num_steps]。
transition_params=self.trans:状态转移矩阵:大小是[num_tags+1, num_tags+1]加1是因为还有一个类别是未定义。
sequence_lengths=lengths+1:句子中字的个数
3.2 crf_log_likelihood的源码

crf_log_likelihood函数中分为两步,最终得到scores:
(1) 调用crf_sequence_score函数计算sequence_scores。
(2) 将sequence_scores进行归一化处理。
3.3 crf_sequence_score 函数源码
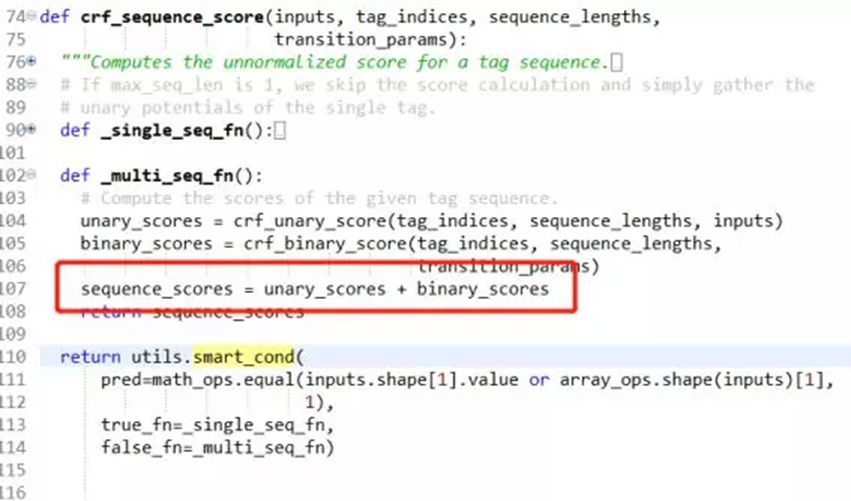
从crf_sequence_score函数的实现中,我们看出,tf中的损失值包括一元损失和二元损失:其中unary_scores表示的是输入序列之间转化的损失,unary_scores表示的转化矩阵的损失值。那这两项到底是什么呢?都是两项,是不是和CRF的参数化形式感觉有点像?我们看看相关论文是怎么说的。
论文:LampleG, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.

得分分为两项,第一项:
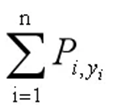
它表示输入句子中,第i个词,取某个标记的概率。
举个例子,假如输入的句子是"Mark Watney visit Mars", 相应的label是[B-PER,E-PER,O,S-LOC],则P(1,"B-PER")表示的是第一个词的标记是B-PER的概率。所以上面表达式在这个例子中是P(1,"B-PER")+P(2,"E-PER")+P(3,"O")+P(4,"S-LOC")。
前面提到过,project_logits是神经网络最后一层的输出,该矩阵的shape为[batch_size, num_steps, num_tags]。所以在tensorflow的实现中,该矩阵的值会取到project_logits矩阵中相应的值,这一点交叉熵有点像,第二项:

它代表的是整个序列从一个标记转化到下一个标记的损失值。它用每一项值从self.trans矩阵中取得。它最开始是按照我们初始化的方式初始化的,然后会随着训练的过程优化。
四、总结
CRF是一个在给定某一个随机序列的情况下,求另一个随机序列的概率分布的概率图模型,在序列标注的问题中有广泛的应用。
在tensorflow中,实现了crf_log_likelihood函数。在本文讲的命名实体识别项目中:
自然语言经过特征提取过后的logits(the inputs of CRF),是发射矩阵,对应着t_k函数;
随机初始化的self.trans矩阵是状态转移矩阵,对应着参数s_l,随着训练的过程不断的优化。
【将第二章节的公式放下来,方便查看】
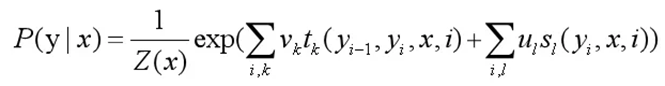
另外: 条件随机场(CRF)在现今NLP中序列标记任务中是不可或缺的存在。太多的实现基于此,例如LSTM+CRF,CNN+CRF,BERT+CRF。因此,这是一个必须要深入理解和吃透的模型。
主要参考
【1】来源: 用于语音识别、分词的CRF