感知器是一种早期的神经网络模型,由美国学者F.Rosenblatt于1957年提出.感知器中第一次引入了学习的概念,使人脑所具备的学习功能在基于符号处理的数学到了一定程度模拟,所以引起了广泛的关注。
简单感知器
简单感知器模型实际上仍然是MP模型的结构,但是它通过采用监督学习来逐步增强模式划分的能力,达到所谓学习的目的。
其结构如下图所示

感知器处理单元对n个输入进行加权和操作v即:

其中,Wi为第i个输入到处理单元的连接权值,f为阶跃函数。
感知器在形式上与MP模型差不多,它们之间的区别在于神经元间连接权的变化。感知器的连接权定义为可变的,这样感知器就被赋予了学习的特性。
利用简单感知器可以实现逻辑代数中的一些运算。

Y=f(w1x1+w2x2-θ)
(1)“与”运算。当取w1=w2=1,θ=1.5时,上式完成逻辑“与”的运算。
(2)“或”运算, 当取wl=w2=1,θ=0.5时,上式完成逻辑“或”的运算。
(3)“非”运算,当取wl=-1,w2=0,θ=-1时.完成逻辑“非”的运算。
与许多代数方程一样,上式中不等式具有一定的几何意义。
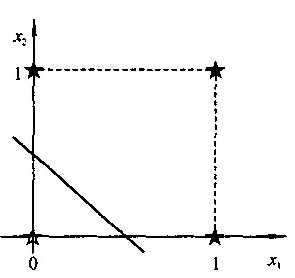
对于一个两输入的简单感知器,每个输入取值为0和1,如上面结出的逻辑运算,所有输入样本有四个,记为(x1,x2):(0,0),(0,1),(1,0),(1,1),构成了样本输入空间。例如,在二维平面上,对于“或”运算,各个样本的分布如下图所示。

{kind=link}
直线1*x1+1*x2-0.5=0将二维平面分为两部分,上部为激发区(y,=1,用★表示),下部为抑制区(y=0,用☆表示)。
简单感知器引入的学习算法称之为误差学习算法。该算法是神经网络学习中的一个重要算法,并已被广泛应用。
现介绍如下:
误差型学习规则:
(1)选择一组初始权值wi(0)。
(2)计算某一输入模式对应的实际输出y与期望输出d的误差δ
(3)如果δ小于给定值,结束,否则继续。
(4)更新权值(阈值可视为输入恒为1的一个权值): Δwi(t+1)=wi(t+1)- wi(t)=η[d—y(t)]xi。
式中η为在区间(0,1)上的一个常数,称为学习步长,它的取值与训练速度和w收敛的稳定性有关;d、y为神经元的期望输出和实际输出;xi为神经元的第i个输入。
(5)返回(2),重复,直到对所有训练样本模式,网络输出均能满足要求。
对于学习步长V的取值一般是在(0,1)上的一个常数,但是为了改进收敛速度,也可以采用变步长的方法,这里介绍一个算法如下式:

式中,α为一个正的常量。这里取值为0.1。
感知器对线性不可分问题的局限性决定了它只有较差的归纳性,而且通常需要较长的离线学习才能达到收效。
多层感知器
如果在输入和输出层间加上一层或多层的神经元(隐层神经元),就可构成多层前向网络,这里称为多层感知器。
这里需指出的是:多层感知器只允许调节一层的连接权。这是因为按感知器的概念,无法给出一个有效的多层感知器学习算法。

上述三层感知器中,有两层连接权,输入层与隐层单元间的权值是随机设置的固定值,不被调节;输出层与隐层间的连接权是可调节的。
对于上面述及的异或问题,用一个简单的三层感知器就可得到解决。

实际上,该三层感知器的输入层和隐层的连接,就是在模式空间中用两个超平面去划分样本,即用两条直线: x1+x2=0.5 x1十x 2=1.5。

可以证明,只要隐层和隐层单元数足够多,多层感知器网络可实现任何模式分类。
但是,多层网络的权值如何确定,即网络如何进行学习,在感知器上没有得到解决:
当年Minsky等人就是因为对于非线性空间的多层感知器学习算法未能得到解决,
使其对神经网络的研究作出悲观的结论。
感知器收敛定理
对于一个N个输入的感知器,如果样本输入函数是线性可分的,那么对任意给定的一个输入
样本x,要么属于某一区域F+,要么不属于这一区域,记为F—。F+,F—两类样本构成了整个线性可分样本空间。
[定理] 如果样本输入函数是线性可分的,那么下面的感知器学习算法经过有限次迭代后,
可收敛到正确的权值或权向量。
假设样本空间F是单位长度样本输入向量的集合,若存在一个单位权向量w*。和一个较小的正数δ>0,
使得w*·x>= δ对所有的样本输入x都成立,则权向量w按下述学习过程仅需有限步就可收敛。
因此,感知器学习迭代次数是一有限数,经过有限次迭代,学习算法可收敛到正确的权向量w*。
对于上述证明,要说明的是:正数δ越小,迭代次数越多;
其次,若样本输入函数不是线性可分的,则学习过程将出现振荡,得不到正确的结果。
感知器与逻辑回归的区别
两者都为线性分类器,只能处理线性可分的数据。
两者的损失函数有所不同,PLA针对分错的数据进行建模,LR使用平方损失建模。
两者的优化方法可以统一为GD。
LR比PLA的优点之一在于对于激活函数的改进。
前者为sigmoid function,后者为step function。
LR使得最终结果有了概率解释的能力(将结果限制在0-1之间),sigmoid为平滑函数,能够得到更好的分类结果,而step function为分段函数,对于分类的结果处理比较粗糙,非0即1,而不是返回一个分类的概率。
感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而求出感知机模型。感知机模型是神经网络和支持向量机的基础。下面分别从感知机学习的模型、策略和算法三个方面来介绍。
1. 感知机模型
感知机模型如下:
f(x)= sign(w*x+b)
其中,x为输入向量,sign为符号函数,括号里面大于等于0,则其值为1,括号里面小于0,则其值为-1。w为权值向量,b为偏置。求感知机模型即求模型参数w和b。感知机预测,即通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别1或者-1。
2. 感知机策略
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个损失函数并通过将损失函数最小化来求w和b。
这里选择的损失函数是误分类点到分类超平面S的总距离。输入空间中任一点x0到超平面S的距离为:

其中,||w||为w的L2范数。
其次,对于误分类点来说,当-yi (wxi + b)>0时,yi=-1,当-yi(wxi + b)<0时,yi=+1。所以对误分类点(xi, yi)满足:
-yi (wxi +b) > 0
所以误分类点(xi, yi)到分类超平面S的距离是:

3. 感知机算法
感知机学习问题转化为求解损失函数式(1)的最优化问题,最优化的方法是随机梯度下降法。感知机学习算法是误分类驱动的,具体采用随机梯度下降法。首先,任意选取一个超平面w0,b0,然后用梯度下降法不断极小化目标函数式(1)。极小化的过程不是一次使M中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
损失函数L(w,b)的梯度是对w和b求偏导,即:

其中,(0<<=1)是学习率,即学习的步长。综上,感知机学习算法如下:

这种算法的基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。
需要注意的是,这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。为了得到唯一的分类超平面,需要对分类超平面增加约束条件,线性支持向量机就是这个想法。另外,当训练数据集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。而对于线性可分的数据集,算法一定是收敛的,即经过有限次迭代,一定可以得到一个将数据集完全正确划分的分类超平面及感知机模型。
以上是感知机学习算法的原始形式,下面介绍感知机学习算法的对偶形式,对偶形式的基本想法是,将w和b表示为实例xi和标记yi的线性组合形式,通过求解其系数而求得w和b。对误分类点(xi, yi)通过

所以,感知机学习算法的对偶形式如下:

参考文献:
1.《统计学习方法》