中文文档 API: http://requests.kennethreitz.org/zh_CN/latest/
安装
pip install requests
获取网页
# coding=utf-8 import requests response = requests.get('http://www.baidu.com') # 第一种方式 获取响应内容 # 查看网页编码方式 print(response.encoding) # 修改编码方式 response.encoding = 'utf-8' # 获取响应内容 print(response.text) # 第二种方式 获取二进制响应内容 # 获取二进制响应内容 print(response.content) # 解码 decode('解码方式') 默认时utf-8的方式 print(response.content.decode())# coding=utf-8 import requests response = requests.get('http://www.baidu.com') # 第一种方式 获取响应内容 # 查看网页编码方式 print(response.encoding) # 修改编码方式 response.encoding = 'utf-8' # 获取响应内容 print(response.text) # 第二种方式 获取二进制响应内容 # 获取二进制响应内容 print(response.content) # 解码 decode('解码方式') 默认时utf-8的方式 print(response.content.decode())
保存图片
import requests response = requests.get('http://requests.kennethreitz.org/zh_CN/latest/_static/requests-sidebar.png') # 保存图片 with open('a.png','wb') as f: f.write(response.content)
获取状态码以及判断请求是否成功
import requests r = requests.get('http://www.baidu.com') # 获取状态码 print(r.status_code) # 获取到200不一定成功 可能获取的时跳转之后的页码 # 断言 判断请求是否成功 assert r.status_code==200 # 如果成功 没有任何反应 失败会报错 # 获取响应header print(r.headers) # 获取请求header print(r.request.headers) # 获取请求url print(r.request.url) # 获取响应的url print(r.url)
带header头伪装浏览器爬取内容
import requests # 模拟header头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} # 获取网页 r = requests.get('http://www.baidu.com',headers=headers) # 获取响应内容 print(r.text)
爬取贴吧内容
import requests class WebSpider(): def __init__(self, name): self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} self.url_temp = "http://tieba.baidu.com/f?kw="+ name +"&ie=utf-8&pn={}" self.name = name # 构建地址列表 def get_url_list(self): return [self.url_temp.format(i*50) for i in range(1000)] # 获取贴吧内容 def parse_url(self, url): #爬取数据 print(url) r = requests.get(url, headers=self.headers) return r.content.decode() def run(self): # 获取地址列表 urls = self.get_url_list() # 遍历 爬取数据 for url in urls: html_str = self.parse_url(url) # 保存 page_num = urls.index(url)+1 # 获取也码数 file_name = self.name + "第{}页.html".format(page_num) with open(file_name, "w", encoding="utf-8") as f: f.write(html_str) if __name__ == '__main__': r = WebSpider(input("请输入贴吧名字:")) r.run()
使用代理
import requests headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"} # 使用代理池 {协议:网址1和端口1, 协议:网址2和端口2} proxies = { "http":"http://39.137.69.8:80", "http":"http://111.29.3.184:80" } r = requests.get("http://www.baidu.com", headers=headers, proxies=proxies) print(r.status_code) # 查看是否成功
POST请求
# coding=utf-8 import requests import sys class BiyingFanyi(object): def __init__(self, trans_str): self.trans_str = trans_str self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"} self.url = "https://cn.bing.com/ttranslatev3?isVertical=1&&IG=1A4E692C98A4412BA37107204839D81C&IID=translator.5032.4" def parse_url(self, url, data): response = requests.post(url, data=data, headers=self.headers) data = list(eval(response.content.decode())) # [{},{}] 把类似列表的字符串转化为列表 return data def run(self): # 获取翻译的语言类型 # 请求地址 lang_data = {"text":self.trans_str, "fromLang": "auto - detect", "to": "en" } # 请求数据 lang= self.parse_url(self.url, lang_data) # 获取lang fromLang = lang[0]["detectedLanguage"]["language"] # post请求数据 trans_data = {"text":self.trans_str,"fromLang": "zh-Hans","to": "en"} if fromLang == 'zh-Hans' else {"text": self.trans_str, "fromLang": "en", "to": "zh-Hans"} # 三元运算符 # 获取相应内容 trans_str = self.parse_url(self.url, trans_data) trans = trans_str[0]["translations"][0]["text"] print(trans) if __name__ == '__main__': trans_str = sys.argv[1] # 启动该文件时加参数 fanyi = BiyingFanyi(trans_str) fanyi.run()
这样再终端调用的时候直接输入要翻译的数据

这种方法有点长 可以给文件起别名
找到.bashrc文件 vi ~/.bashrc在最下面添加
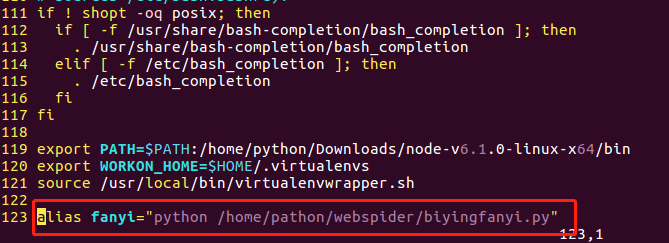
启动下bashrc文件

使用别名运行

使用cookie得三种方式
1,登录账号保存到session里
# coding=utf-8 import requests # 实例化一个session对象 session = requests.session() # 请求网址 post_url = "http://www.renren.com/PLogin.do" # 人人网账号和密码 post_data = {"email":"18656******", "password":"qw******"} headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"} # 使用session发送post请求,cookie保存在其中 session.post(post_url, data=post_data, headers=headers) # 在使用session进行请求登陆后才能访问的地址 r = session.get("http://www.renren.com/972533172/newsfeed/photo", headers=headers) # 保存页面 with open('renren1.html', "w", encoding="utf-8") as f: f.write(r.content.decode())
2.Cookie放入请求头
# coding=utf-8 import requests headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36", "Cookie":"anonymid=jso2jqr9-ua7yx8; _r01_=1; XNESSESSIONID=196ea2cc9d76; depovince=GW; jebecookies=d90c5751-c3f3-486e-a72c-745450b49686|||||; ick_login=5826e3f3-931a-4fef-ba96-44bbf4002755; _de=1F357FAF1F9FBA7F803C7095955979B8; p=4dc77dc5f602d42c37e075914279d3bc2; first_login_flag=1; ln_uact=18656711411; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=e0a9e51796415e5018a3adee3ea84a0b2; societyguester=e0a9e51796415e5018a3adee3ea84a0b2; id=972533172; xnsid=e7f4f06; ver=7.0; loginfrom=null; jebe_key=9d0aeb38-53ed-4f12-9bb6-c37611fbe84b%7C44bfbc433568681820735e4eb5dfc039%7C1571714808839%7C1%7C1571714811980; wpsid=15257123636357; wp_fold=0" } r = requests.get("http://www.renren.com/972533172/newsfeed/photo", headers=headers) with open("renren2.html", "w", encoding="utf-8") as f: f.write(r.content.decode())
3.设置cookies字典
# coding=utf-8 import requests headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"} cookie = "anonymid=jso2jqr9-ua7yx8; _r01_=1; XNESSESSIONID=196ea2cc9d76; depovince=GW; jebecookies=d90c5751-c3f3-486e-a72c-745450b49686|||||; ick_login=5826e3f3-931a-4fef-ba96-44bbf4002755; _de=1F357FAF1F9FBA7F803C7095955979B8; p=4dc77dc5f602d42c37e075914279d3bc2; first_login_flag=1; ln_uact=18656711411; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=e0a9e51796415e5018a3adee3ea84a0b2; societyguester=e0a9e51796415e5018a3adee3ea84a0b2; id=972533172; xnsid=e7f4f06; ver=7.0; loginfrom=null; jebe_key=9d0aeb38-53ed-4f12-9bb6-c37611fbe84b%7C44bfbc433568681820735e4eb5dfc039%7C1571714808839%7C1%7C1571714811980; wpsid=15257123636357; wp_fold=0" Cookies = {i.split('=')[0]:i.split('=')[1] for i in cookie.split("; ")} # 字典推导式 r = requests.get("http://www.renren.com/972533172/newsfeed/photo", headers=headers, cookies=Cookies) with open("renren3.html", "w", encoding="utf-8") as f: f.write(r.content.decode())
抓包 寻找登录的url地址
勾选perserve log按钮 防止页面跳转找不到url地址
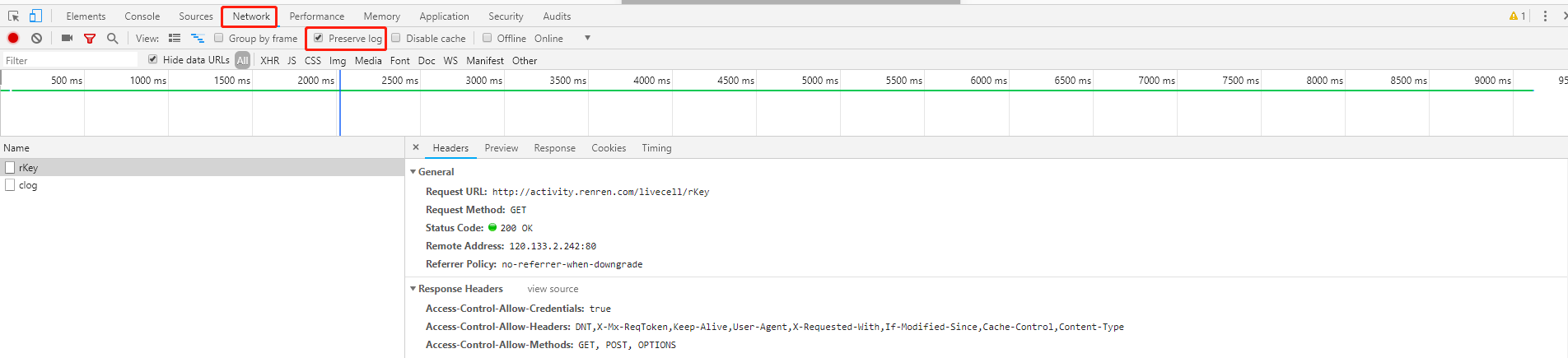
寻找参数时,需要多点几次,看参数变化不
定位js
1.选择会触发js事件得按钮,点击Event listeners,同时formwork listeners打勾,找到js的位置
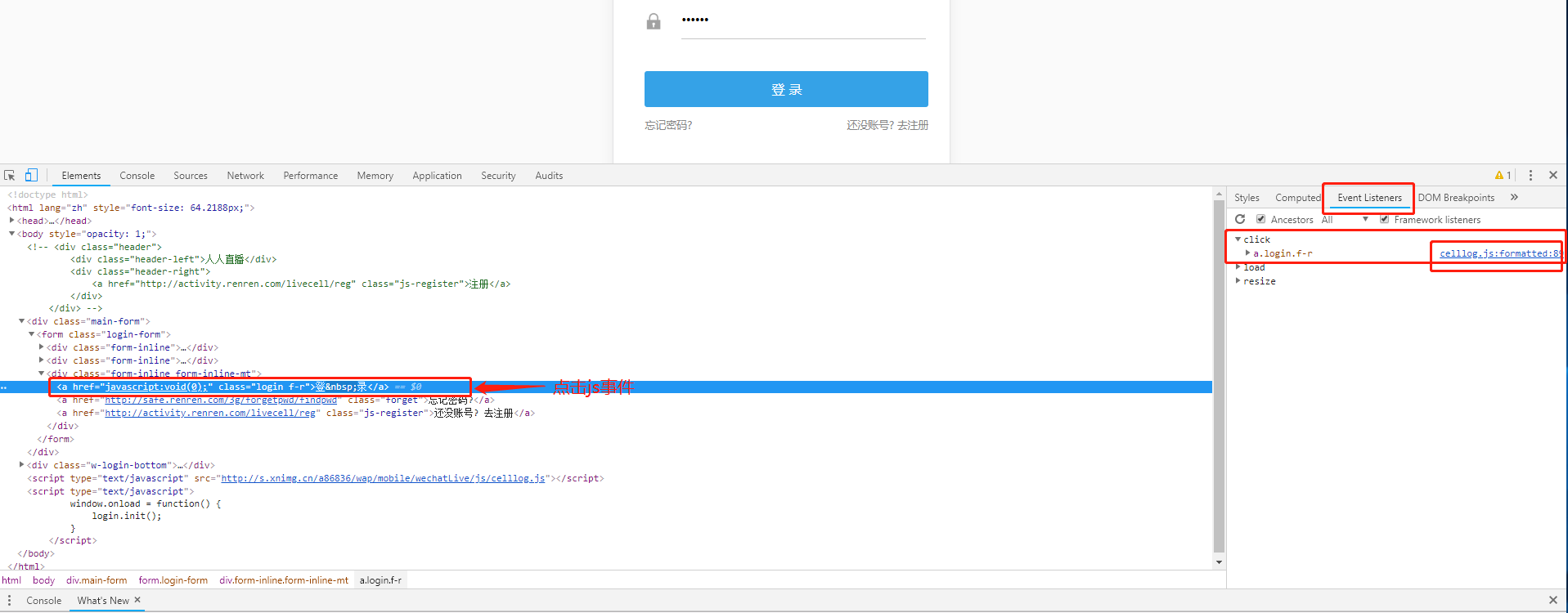
点击js
想看得js效果可以在console里直接复制进去

断点调试,点击js对应得行号
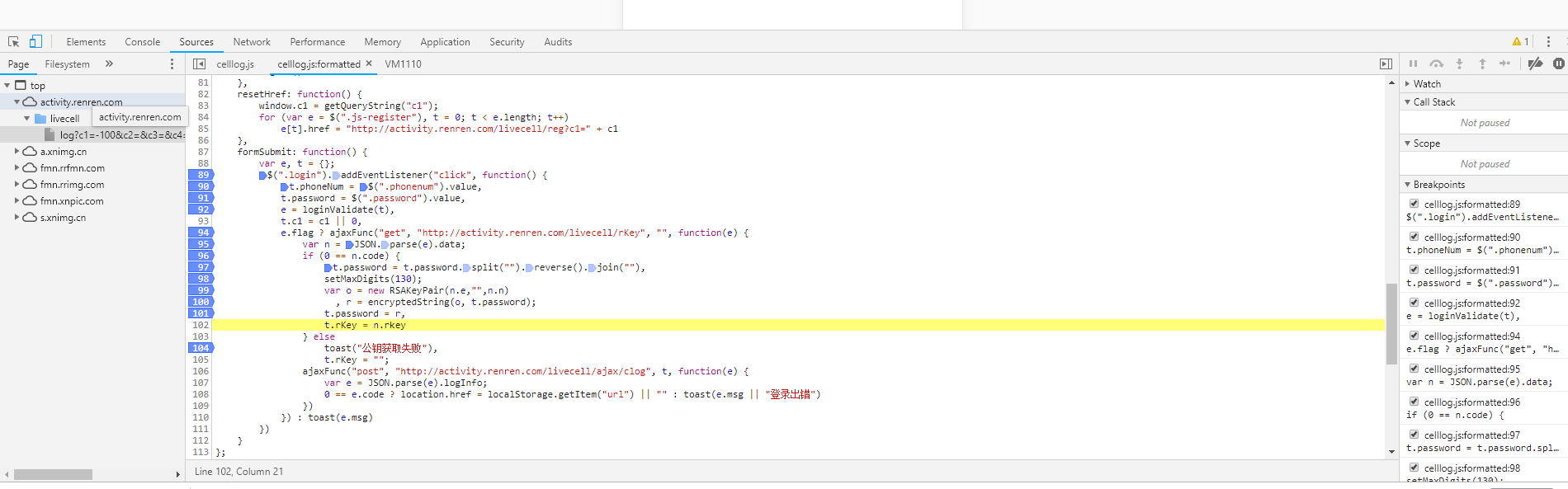
再点击次登录按钮进入调试状态
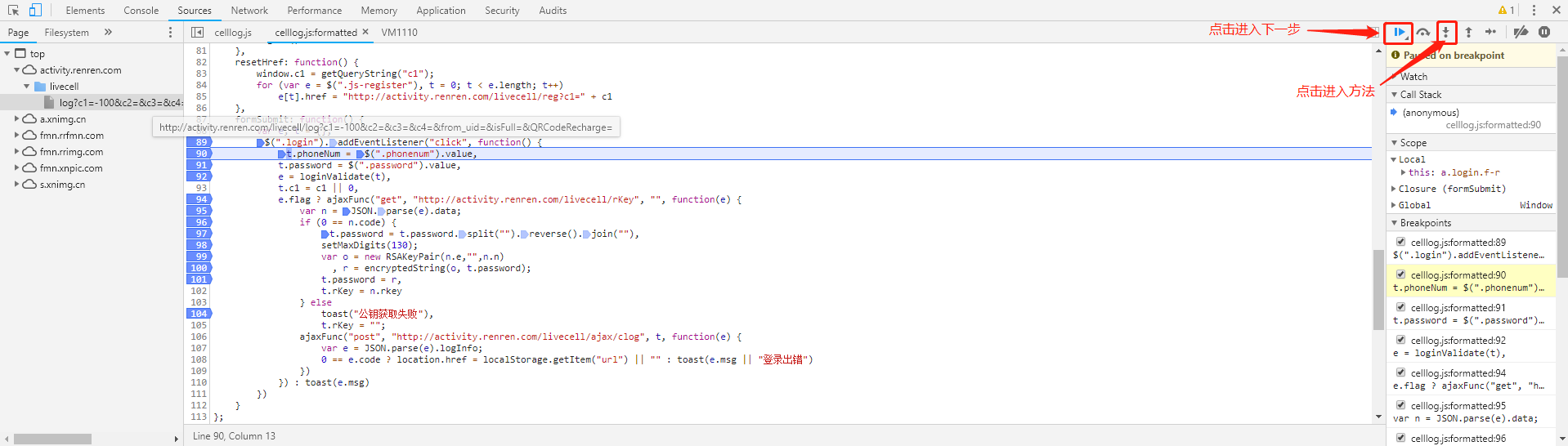
2.查找请求的地址
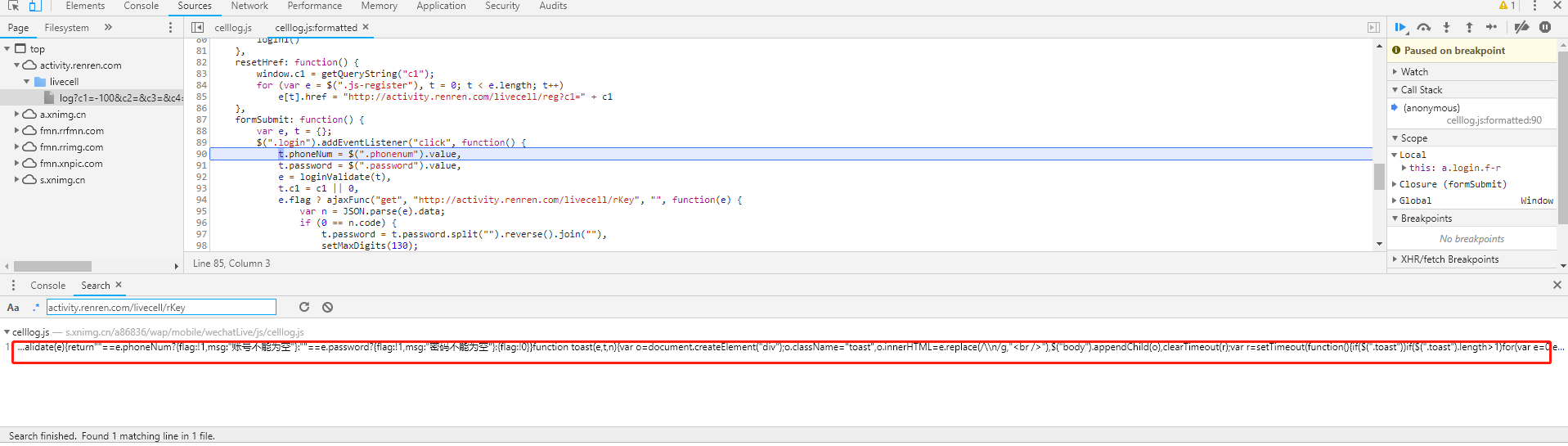
复制请求地址或关键字点search
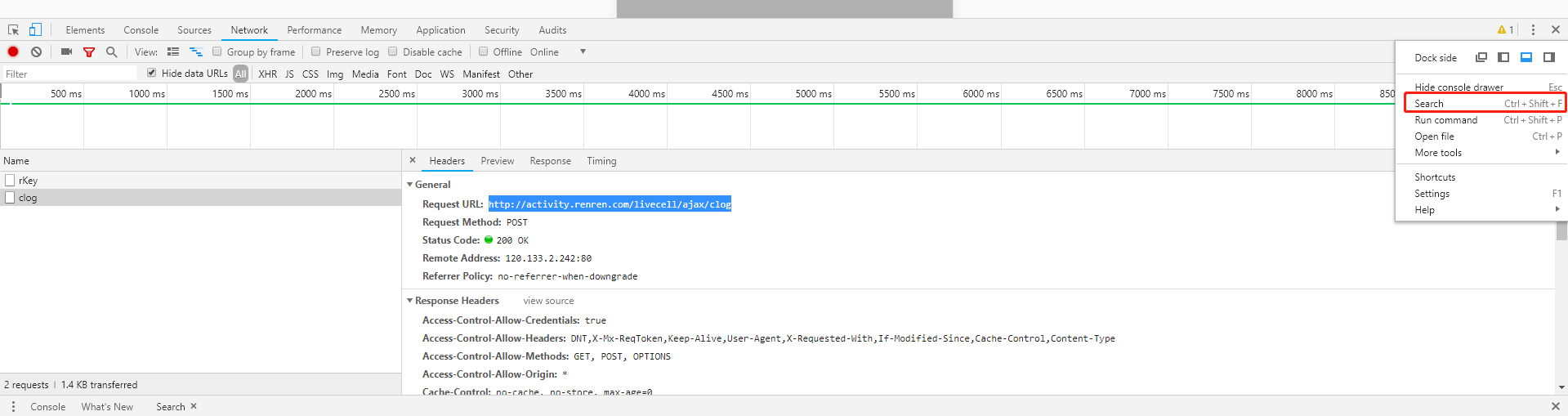
搜索复制的地址或关键字
requests其它小技巧
把响应数据里的cookie对象转换成字典

把字典转换成响应数据里的cookie对象
requests.utils.cookiejar_from_dict({'BDORZ': '27315'}
url解码
requests.utils.unquote("http://tieba.baidu.com/f?kw=%E6%9D%A8%E6%B4%8B")

url编码
requests.utils.quote('http://tieba.baidu.com/f?kw=杨洋')

请求SSL证书验证
response = requests.get("https://www.12306.cn/mormhweb/ ", verify=False)
添加超时参数
response = requests.get(url,timeout=10)
配合状态码判断是否请求成功
assert response.status_code == 200