摘要
提出一种新的帧内预测方法,使用GAN来消除空间冗余。基于GAN的方法的方法使用更多的信息来产生更灵活的预测模式。帧内预测被建模为一个去瑕疵过程,使用GAN来充满重建帧中丢失的部分。GAN模型被加入到编码器和解码器中,与传统的预测模型进行率失真比较。HM、VTM节约6%-8%的比特。
1.介绍
更好的预测导致更少的残差,也就需要更少的编码bit。与传统的基于解码样本的空间外推extrapolation的帧内预测不同,我们把帧内预测视作一个去瑕疵inpainting问题,采用GAN来预测像素。这篇文章的主要贡献有:
- intra预测的过程被表述为一个基于学习的inpainting task,利用GAN的generator在已经解码的block的基础上对缺失的部分进行预测,充分利用邻域信息,可以更好的预测当前待编码单元。
- 使用提出的GAN方法对intra预测模块进行了重新设计,并进行了率失真操作(RDO),以在传统方法和GAN方法之间选择最佳方法,并附加一个标记。
- 在编码器和解码器中都实现了基于GAN的帧内预测,提高了帧内编码性能。大量的实验结果表明,与目前最先进的基于深度学习的intra预测方法相比,该方法具有更好的性能。
2.相关工作
intra coding
inpainting image
图像inpainting的目的是填补一个图像缺失的部分,使其完整和自然。图像inpainting的方法可以分为两类:(1)邻像素插值的方法;(2)深度学习的方法。
第一类是根据相邻信息的相互关系来推断缺失的部分。Li等人提出了[23]提出了一种基于颜色方向块稀疏性的图像绘制方法,以保持缺失部分的结构一致性、纹理清晰度和内在一致性。该方法利用超小波变换对多目标信号进行估计退化图像的方向特征。Jin等人提出了[24]摘要提出了一种基于小块稀疏的平面方向导数图像绘制算法,保证了缺失区域边界元的连续性。在[25]中提出了一种基于马尔可夫随机场(MRF)的图像inpainting算法,该算法从一组patch中选取合适的搜索空间来选择候选patch。
近年来,基于深度学习的方法也被应用到图像inpainting中。在[26]中提出了一种基于上下文像素预测的无监督视觉特征学习算法。Yu等人提出了一种新的基于深度学习的图像inpainting系统,利用自由形式的mask和输入来完成图像。该系统是由门控卷积从数百万图像中学习而来,无需额外的标签。Yang等人使用条件GANs作为主干,并引入了一种新的基于块的程序方案来稳定训练阶段,以生成高质量的逼真的inpainting效果。在[29]中提出了一种基于全局GAN和局部GAN的图像融合方法。针对局部和全局一致的[30]图像,提出了一种新的图像补全方法。
3.动机和问题表达
H.264和HEVC的多种预测模式来预测都有一个缺点,那就是可参考的像素有限。通过实验,尝试了每种预测模式,发现它们不够灵活,结果都不够完美。因此,内部预测问题如图3所示,从左上、左和上的块都是可用信息,待编码块位于右下。使用邻居信息来完成inpainting任务。与HEVC中只利用最邻近的列和行的像素相比,可以利用更多的信息。此外,还可以根据生成模型生成可伸缩的预测模式。具体来说,可以生成圆形和椭圆形模式,以弥补传统内部预测的局限性。然而,直接将GAN应用于内层预测还存在一些挑战性的问题。特别是与传统inpainting方法解决缺部在中心的问题相比,缺少了周围的信息,只剩下上面和左边的方块,很难恢复结构信息。这促使我们设计一个先进的inpainting模型,专门用于内部预测任务。

4.提出的基于GAN的帧内预测方法
在本节中,我们将intra预测过程嵌入到inpainting框架中,开发了基于深度学习的intra编码方案。特别地,我们的intra预测策略采用了基于GAN的inpainting,因为它在推断缺失像素方面有很好的表现。更具体地说,第4-A节讨论了用于内部预测的基于GAN的inpainting的体系结构。第4-B节比较了两种方案。利用基于GAN的模型,我们将其整合到HEVC编解码器中进行intra预测。最后,第四部分对GAN模型的训练进行了讨论。
A. Architecture of GAN Model for Inpainting
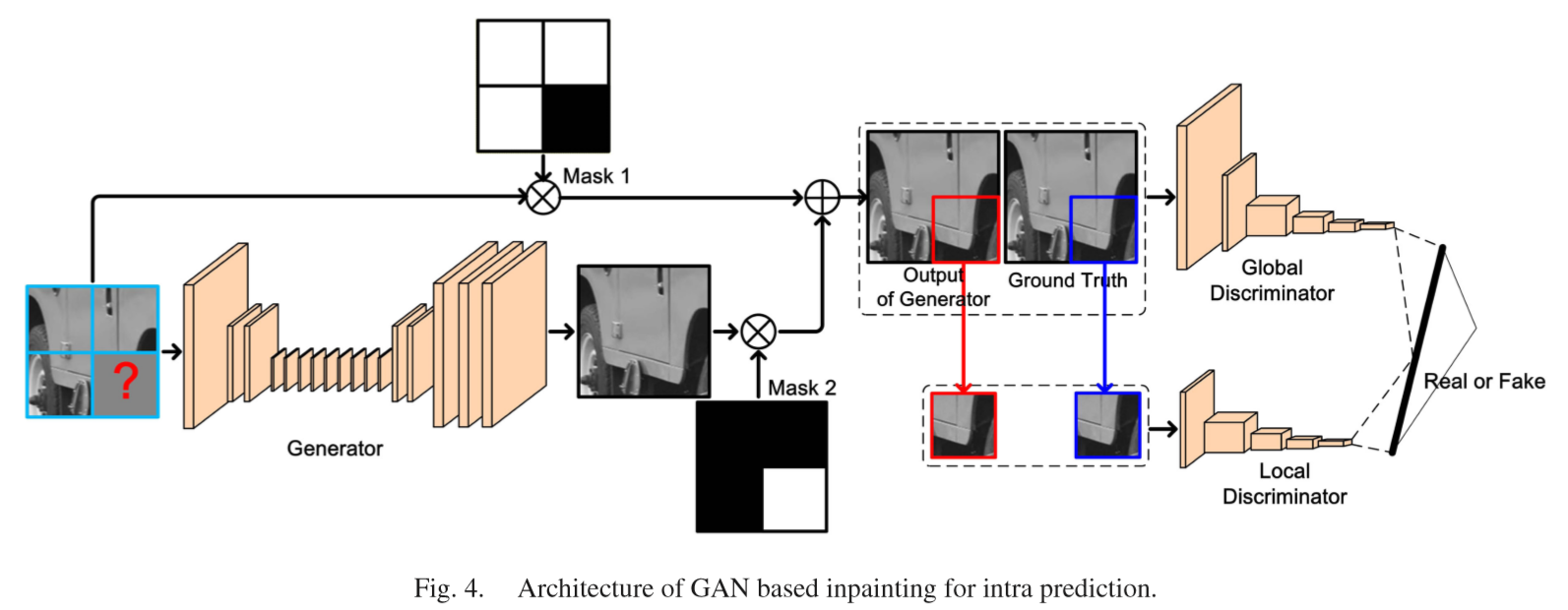
B. Scheme Selection
通常,有两种基于GAN的inpainting方案。一种是对于64x64的块的GAN模型,一种是分别对于64x64,32x32,16x16,8x8块的4个GAN模型。这两个方案的优缺点从以下几个方面来比较:实现,模型存储,编码端的操作,对VVC的适应,解码端的运行时间,编码增益。在表5中展示了比较结果。

方案1的优点(1)易于实施,在CTU级别进行视频编码,相邻重建CTU是易于获得的;(2)需要储存更少的GAN模型;(3)在编码端基于GAN的帧内预测需要更少的操作。每个CTU只需要进行一次帧内预测一次;(4)可以容易适应VVC,而不需要任何改变;方案1的缺点(1)在编码端需要额外的运行时间;在解码端,对于一个CTU中的中的小块,3x64x64的样本需要被喂进生成器,所以需要额外的运行时间。(2)有限的编码增益,基于GAN的帧内预测只在CTU级别进行。 对于小块儿,执行复制操作。它不能实现更多的编码增益。
方案2的优点是(1)在解码端不需要额外的运行时间;在解码端,如果选择了这种方法,每一个块儿都会被联合gan模型预测。(2)有潜力的编码增益,基于gan的针内预测每一个块儿的划分都会比较rd cost,所以可以获得更多的编码增益。方案2的缺点是(1)实现困难,块的话划分是递归的方式,对于一个小块儿而言,他的邻居块儿不容易获得,因为它们不是最终重建的。(2)需要储存更多的gan模型。Gan模型的数量依赖于块划分的数量。对于hevc而言,需要4种gan模型。例如: 64x64, 32x32, 16x16, 和8x8。(3)在编码端基于gan的帧内预测,需要更多的操作。对不同尺寸的块运行基于gan的模型会导致非常高的计算复杂度。(4)比较难适应vvc,更多的GAN模型需要被训练,特别是不对称块儿的划分。
所以我们觉得方案一更好。
C. GAN based Intra Prediction in Video coding
我们将基于gan的帧内预测模型加入到hevc编码框架中。尽管基于gan的inpainting在一些情况下可以获得更好的视觉上的效果的预测,但是因为比较的是SAD,所以并不总是能够保证更好的编码表现。所以传统的帧内预测与被拿来和基于GAN的帧内预测模型比较。特别地,视觉信号呈现出不同的统计特性,因此在HEVC中采用了不同的角度模式进行内部预测。同样地,GAN模型可以通过设计多种预测模式来处理不同的信号特性。在HEVC的基础上,设计了35种基于GAN的帧内预测模式。尽管这35种GAN模式可能具有相似的SAD值,但它们在RD cost方面表现出不同的编码性能。更多的模式将消耗更多的比特,因为索引也需要编码。但是,如果这35种模式之间的竞争对编码性能的提高更大,则采用35种GAN模式的方案。此外,在我们的工作中,这35个GAN版本的输出是并行生成的。因此,生成35个版本的运行时间与生成一个版本的运行时间相当。此外,对于预测,像素只是从这35个版本的结果复制得来。在研发成本的计算和比较过程中,与传统的内部预测是一致的。这样,基于GAN的intra预测可以与基于角度的HEVC的intra预测在RDO意义上竞争,并且只需要一个标志来表示预测策略。产生35个不同版本输出的方法将在第4-d节详细讨论。
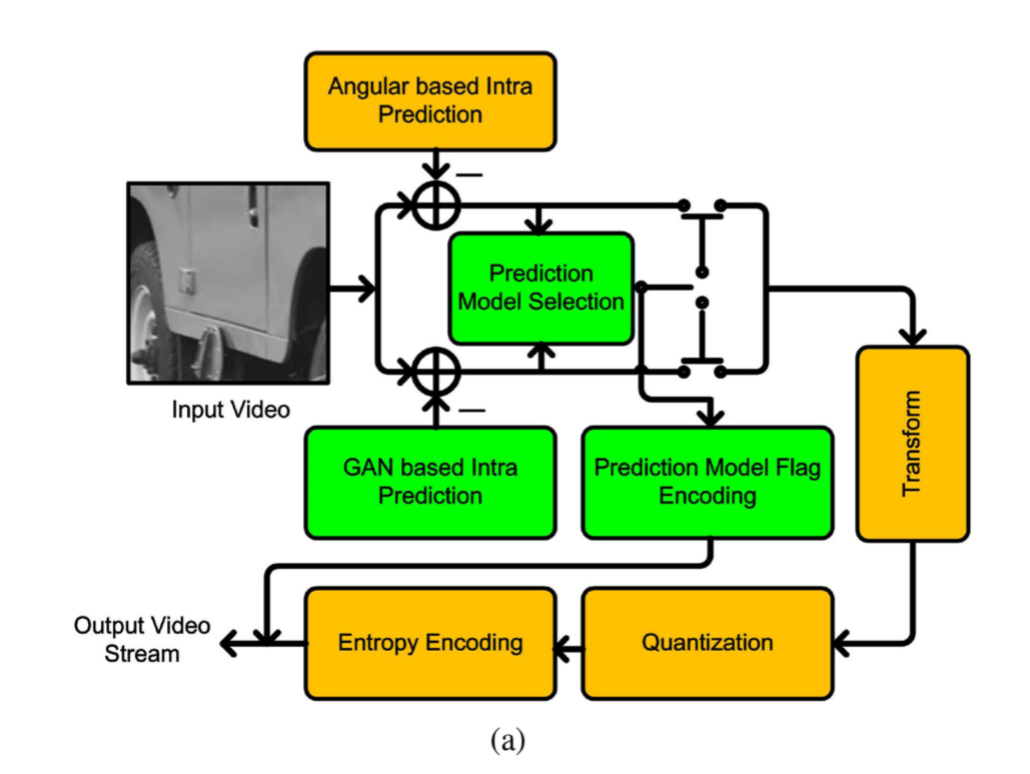
基于GAN的帧内预测视频编解码器如图5所示。图5(a)给出了编码器的结构。首先,同时进行基于角度的intra预测和基于GAN的intra预测。对于基于角度的intra预测,我们检查了原始的35种intra模式,并计算了它们的RD成本。对于基于GAN的intra预测,将生成35个版本的预测块。共有70种intra模式,最终选择研发成本最低的最佳模式。由于基于GAN的intra编码模式的索引编码(0-34)与HEVC相同,每个传统intra编码模式对应一个GAN模型的输出,因此只使用一个额外的标记来表示最终的预测策略。应该注意的是,基于的GAN的帧内预测只是用于预测大小为64 x 64的PU,其他大小小于64x64的PU的预测直接复制当前64x64的CU的像素。原因已在第4-b节中详细讨论。此外,由于上面的块和左块在一个帧中没有参考信息,通常采用基于传统外推的intra预测策略进行预测。
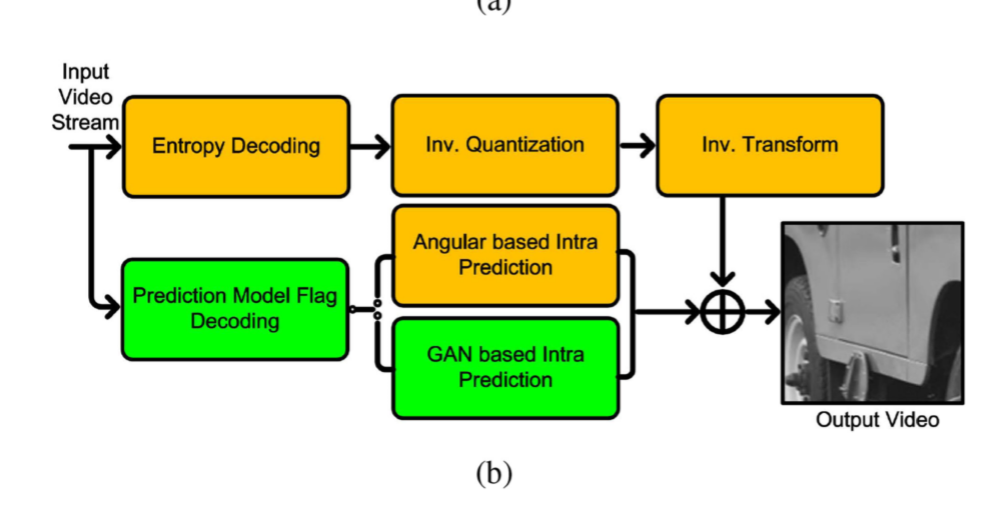
将基于GAN的帧内预测嵌入编码框架,如图5(b)所示。首先对预测模型标志进行解码,以指示各PU的预测策略。当标志位为1时,代表的是使用GAN进行额帧内预测,所以要用GAN来生成预测单元PU。否则,将执行原始的基于角度的intra预测。其他解码模块与原始解码器保持一致。
D. GAN Model Training
训练数据集包含800张图像,分辨率为512 x 384,来自未压缩的彩色图像数据库[32]。图像由HEVC测试模型进行编码,QP等于22。其中一个样本如图3所示,尺寸为128 x 128,其中缺失的部分位于右下角,尺寸为64 x 64。这个样本和它对应的不带任何编码失真的ground truth形成一个训练对。需要注意的是,只有色彩内容被提取出来用于训练。
为了从GAN生成35个版本的预测,一种直接的方法是训练35个GAN模型。然而,这种策略大大增加了编码器和解码器存储neu ral网络模型的负担。因此,我们定义了一个控制不同生成模式的潜在变量。更具体地说,在训练阶段,生成了35个不同版本的输入,它们的区别在于要预测的缺失部分的初始像素值。其中,为每个样本随机设置缺失部分的初始像素值。
(lfloor floor)表示的是向下取整,X为({0,1,2, ldots, 34})中随机一个,k代表bit深度,图6显示了GAN的35个版本的输入示例。这里,比特深度k = 8的参数。需要注意的是,在视频编码阶段,为了生成35个版本的输出,缺失部分的初始像素值是通过Eq(1)设置的,其中X从0到34依次选择,这里没有随机规则。实际上,我们还尝试了其他几种类型的初始化,比如棋盘格、垂直和水平模式。等式(1)中的板型表现出最佳的性能,本文采用这种板型。
在我们的任务中,目标是最小化预测和原始块之间的差异,这样就可以通过均值平方误差的损失函数对生成器进行前几个周期的训练
总的损失函数:
(min _{G} max _{D} mathbb{E}left[alpha L+log Dleft(A_{1}, B_{1}
ight)+log left(1-Dleft(A_{2}, B_{2}
ight)
ight)
ight])
(B_{1})和(B_{2})是全局信息,分别表示ground truth(R_{m})和生成器(Gleft(I_{m}
ight))的输出。参数(alpha)是平衡MSE loss的二值交叉熵。在训练阶段,我们按照[30]中的设置,设置为2500。

实验结果与分析
The original HM 16.17 is utilized as the anchor for RD performance comparison. The RD performance is measured by BjøntegaardDeltaBitRate (BD-BR)[34],and a negative value implies the RD performance improvement and vice versa. In addition, the original fast algorithm in HM platform is enabled, i.e., Rough Mode Decision (RMD)is performed firstly according to Sum of Absolute Transformed Differences (SATD) cost, then the selected intra modes plus MPMs will be checked one by one.
A. Intra Prediction Comparison
B. Influence of Adversarial Term
C. Coding Performance Comparison With the State-of-the-Art Algorithm
D. Cross-Validation of GAN Under Different QP Settings
E. Adaptation to the VVC Standard
F. Computational Complexity Analyses