分析一套源代码的代码规范和风格并讨论如何改进优化代码
我的工程实践选题为基于大数据问答训练的中文自然语言理解系统设计,本项目学习知识工程的构建方法,研究学习WordNet、frameNet等常用语义网络,使用机器学习算法研究中文自然语言理解,构建一套智能文本摘要提取系统。所以我在github上找到了一套名为seq2seq-chinese-textsum的源码。
1.结合工程实践选题相关的一套源代码,根据其编程语言或项目特点,分析其在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点
1.1目录结构
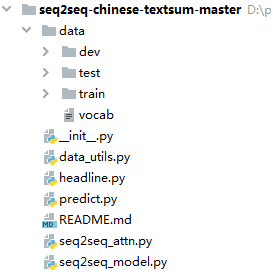
可以看出整个文件目录比较清晰,通俗易读,通过文件名就能知道文件功能。包括数据文件,数据处理文件,预测,训练模型,README文档使用说明等文件,还是比较清晰的。
1.2文件名/类名/函数名/变量名
文件命名
● 尽量使用小写命名,首字母保持小写,尽量不要用下划线(除非多个单词,且数量不多的情况),可以看出此项目是符合文件命名原则的。
类名
● 使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头。
● 将相关的类和顶级函数放在同一个模块里. 不像Java, 没必要限制一个类一个模块

函数名
● 函数名一律小写,如有多个单词,用下划线隔开
● 私有函数在函数前加一个下划线_
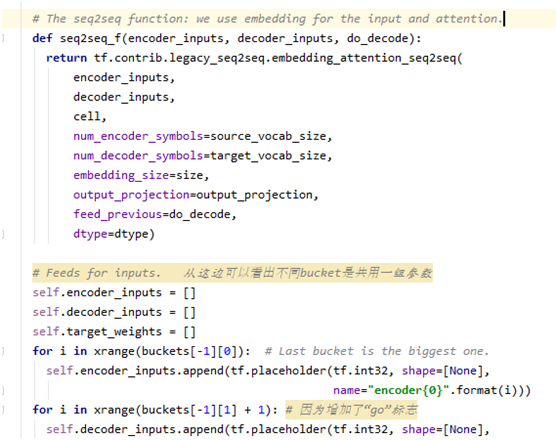
变量名
● 变量名尽量小写, 如有多个单词,用下划线隔开
● 常量采用全大写,如有多个单词,使用下划线隔开
1.3接口定义规范和单元测试组织形式
此项目中没有使用接口,也没有单元测试形式,这是应该改进的地方。
2.列举哪些做法符合代码规范和风格一般要求

在定义函数时,函数命名遵循规范,使用小写带有意义的英文,多个单词使用_下划线连接。并且在下方注释了函数的功能和参数的定义,还有返回类型
的说明,让读者理解起来更容易,方便调用。
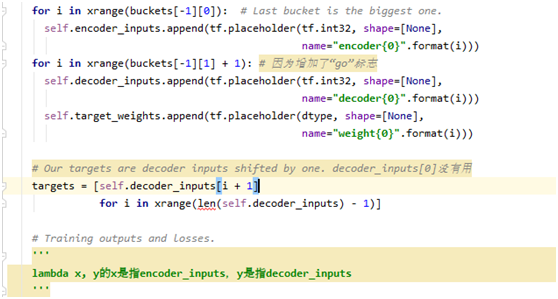
不同功能单元模块之间使用空一行分割,使用程序可读性更好,简洁明了,代码功能也分得清清楚楚,清晰简洁。
3.列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进

在设置递归次数的时候,可以设置一个全局变量来控制,这样要变更的时候不用每次到代码里面改。

这是关键核心代码,在函数定义时应该对其功能,参数,返回,里面的关键语句等有较为详细的注释,此处没有,可能会比较难理解。

作者在每次调用函数参数传递时喜欢对参数提行,即使参数很少很短,而且也没有对齐,看起来有点参差不齐,阅读性也差,建议参数少时不用提行,参数多且长时提行而且对齐。
4.总结同类编程语言或项目在代码规范和风格的一般要求
避免劣化代码
• 避免只用大小写来区分不同的对象;
• 避免使用容易引起混淆的名称,变量名应与所解决的问题域一致;
• 不要害怕过长的变量名;
代码中添加适当注释
• 行注释仅注释复杂的操作、算法,难理解的技巧,或不够一目了然的代码;
• 注释和代码要隔开一定的距离,无论是行注释还是块注释;
• 给外部可访问的函数和方法(无论是否简单)添加文档注释,注释要清楚地描述方法的功能,并对参数,返回值,以及可能发生的异常进行说明,使得外部调用的人仅看docstring就能正确使用;
• 推荐在文件头中包含copyright申明,模块描述等;
• 注释应该是用来解释代码的功能,原因,及想法的,不该对代码本身进行解释;
• 对不再需要的代码应该将其删除,而不是将其注释掉;
适当添加空行使代码布局更为优雅、合理
• 在一组代码表达完一个完整的思路之后,应该用空白行进行间隔,推荐在函数定义或者类定义之间空两行,在类定义与第一个方法之间,或需要进行语义分隔的地方空一行,空行是在不隔断代码之间的内在联系的基础上插入的;
• 尽量保证上下文语义的易理解性,一般是调用者在上,被调用者在下;
• 避免过长的代码行,每行最好不要超过80字符;
• 不要为了保持水平对齐而使用多余的空格;
编写函数的几个原则
• 函数设计要尽量短小,嵌套层次不宜过深;
• 函数申明应做到合理、简单、易于使用,函数名应能正确反映函数大体功能,参数设计应简洁明了,参数个数不宜过多;
• 函数参数设计应考虑向下兼容;
• 一个函数只做一件事,尽量保证函数语句粒度的一致性;
将常量集中到一个文件
Python没有提供定义常量的直接方式,一般有两种方法来使用常量;
• 通过命名风格来提醒使用者该变量代表的意义为常量,如常量名所有字母大写,用下划线连接各个单词,如MAX_NUMBER,TOTLE等;
• 通过自定义的类实现常量功能,常量要求符合两点,一是命名必须全部为大写字母,二是值一旦绑定便不可再修改;