MySQL 原理篇
MySQL5.5 及以后版本的默认存储引擎使用的是 InnoDB,接下来针对事务的讲解都是基于 InnoDB 存储引擎的。
事务的定义
事务:数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作; 事务是一组不可再分割的操作集合(工作逻辑单元)。
典型事务使用场景:转账
update user_account set balance = balance - 1000 where userID = 3; update user_account set balance = balance + 1000 where userID = 1;
MySQL 开启事务:
/* BEGIN / START TRANSACTION --手工 COMMIT / ROLLBACK --事务提交或回滚 SET SESSION autocommit = ON/OFF --设定会话级别事务是否自动开启 */
MySQL 默认是开启事务的,通过 SHOW VARIABLES like 'autocommit'; 可以查看 MySQL 的事务开启情况。
- 在 autocommit = ON(自动提交事务)的情况下,可以执行
BEGIN;或者START TRANSACTION;命令,改为手动提交事务,执行完 SQL 语句后,需要通过COMMIT命令提交事务,或者通过ROLLBACK命令回滚事务。 - 在 autocommit = OFF(手动提交事务)的情况下,执行完 SQL 语句后,需要通过
COMMIT命令提交事务,或者通过ROLLBACK命令回滚事务。
JDBC 编程:
connection.setAutoCommit(boolean);
测试命令:
SHOW VARIABLES like 'autocommit'; /* autocommit为ON */ update teacher set name ='seven' where id =1; insert teacher (name,age) value ('james',22); delete from teacher where name = 'james'; /* autocommit为ON如何开启事务 */ BEGIN; START TRANSACTION; update teacher set name ='seven' where id =1; insert teacher (name,age) value ('james',22); delete from teacher where name = 'james'; COMMIT; ROLLBACK; /* 将autocommit改成OFF */ set session autocommit = OFF; update teacher set name ='seven' where id =1; insert teacher (name,age) value ('james',22); delete from teacher where name = 'james'; COMMIT; ROLLBACK;
事务 ACID 特性
原子性(Atomicity):最小的工作单元,整个工作单元要么一起提交成功,要么全部失败回滚。
一致性(Consistency):事务中操作的数据及状态改变是一致的,即写入资料的结果必须完全符合预设的规则,不会因为出现系统意外等原因导致状态的不一致。
隔离型(Isolation):一个事务所操作的数据在提交之前,对其他事务的可见性设定(一般设定为不可见)。
持久性(Durability):事务所做的修改就会永久保存,不会因为系统意外导致数据的丢失。
参考(原子性和一致性的区别是什么?)这篇博文,讲了一下原子性和一致性的区别。
事务并发带来了哪些问题
脏读

比如 user 表中有一条用户数据,执行了如下操作:
- 事务B更新 id=1 的数据,age 更新为18,不提交事务
- 事务A查询 id=1 的数据
- 事务B回滚刚才的更新操作
这个时候,事务A中查询出的 id=1 的数据,age 的值是16还是18?
不可重复读

比如 user 表中有一条用户数据,执行了如下操作:
- 事务A查询 id=1 的数据
- 事务B更新 id=1 的数据,age 更新为18,并提交事务
- 事务A再次查询 id=1 的数据
这个时候,事务A两次查询出的 id=1 的数据,age 的值是16还是18?
幻读
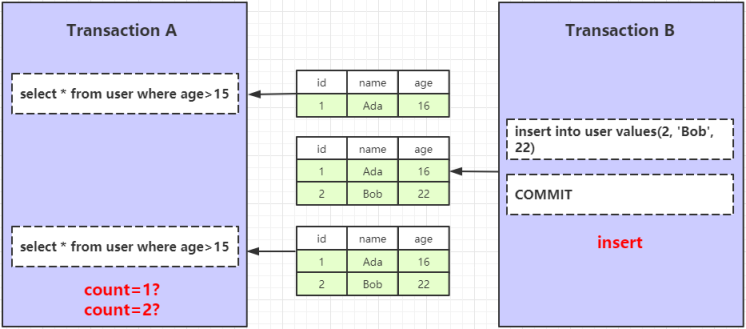
比如在 user 表中执行了如下操作:
- 事务A查询 age>15 的数据
- 事务B新增一条数据,age=22,并提交事务
- 事务A再次查询 age>15 的数据
这个时候,事务A两次查询出的数据,数量是1条还是2条?
事务四种隔离级别
SQL92 ANSI/ISO标准:http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
Read Uncommitted(未提交读) --未解决并发问题
事务未提交对其他事务也是可见的,脏读(dirty read)
Read Committed(提交读) --解决脏读问题
一个事务开始之后,只能看到自己提交的事务所做的修改,不可重复读(non repeatable read)
Repeatable Read(可重复读) --解决不可重复读问题
在同一个事务中多次读取同样的数据结果是一样的,这种隔离级别未定义解决幻读的问题
Serializable(串行化) --解决所有问题
最高的隔离级别,通过强制事务的串行执行
InnoDB 引擎对隔离级别的支持程度
|
事务隔离级别 |
脏读 |
不可重复读 |
幻读 |
|
未提交读(Read Uncommitted) |
可能 |
可能 |
可能 |
|
已提交读(Read Committed) |
不可能 |
可能 |
可能 |
|
可重复读(Repeatable Read) |
不可能 |
不可能 |
对 InnoDB 不可能 |
|
串行化(Serializable) |
不可能 |
不可能 |
不可能 |
事务隔离级别的并发能力:未提交读 > 已提交读 > 可重复读 > 串行化
InnDB 引擎默认的事务隔离级别是可重复读(Repeatable Read),在该级别中它把幻读的问题也解决了。InnDB 中事务隔离级别通过锁、MVCC 实现。
通过如下语句查看 InnoDB 的默认事务隔离级别:
/* 全局、当前会话的隔离级别 */ SELECT @@global.tx_isolation, @@tx_isolation;

通过如下语句设置 InnoDB 的事务隔离级别:
/* 设置全局隔离级别 */ set global transaction isolation level read committed; /* 设置当前会话的隔离级别 */ set session transaction isolation level read committed;
接下来我们来测试一下 InnoDB 的默认事务隔离级别(Repeatable Read)是否解决了脏读、不可重复读、幻读的问题。
数据准备:
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(32) NOT NULL, `age` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; insert into `user` (`id`, `name`, `age`) values('1','Ada','16');
是否解决了脏读的问题?
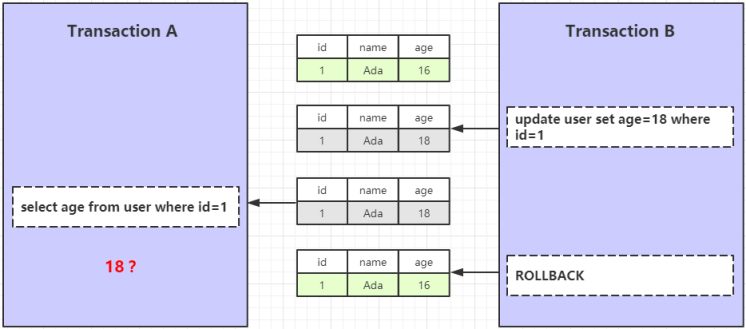
开启两个 MySQL 客户端,模拟事务A和事务B的操作,执行步骤如下:
- 事务B开启手动事务,更新 id=1 的数据,age 更新为18,不提交事务
- 事务A查询 id=1 的数据
- 事务B回滚刚才的更新操作
图中的数字是执行步骤,通过下图可以看出事务A的执行结果是16,InnDB 的默认事务隔离级别完美的解决了脏读的问题。
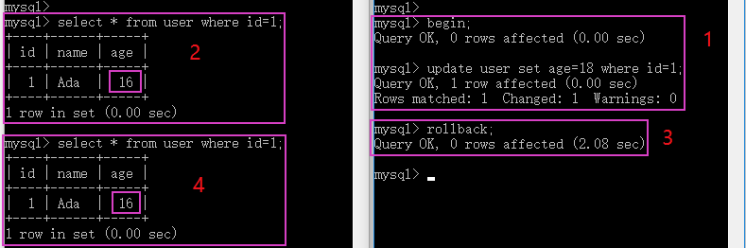
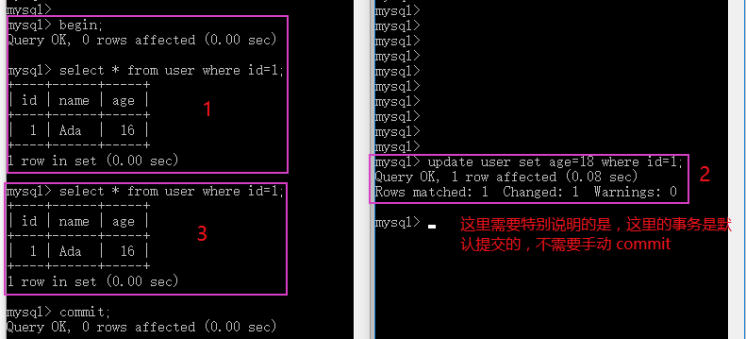
是否解决了不可重复读的问题?
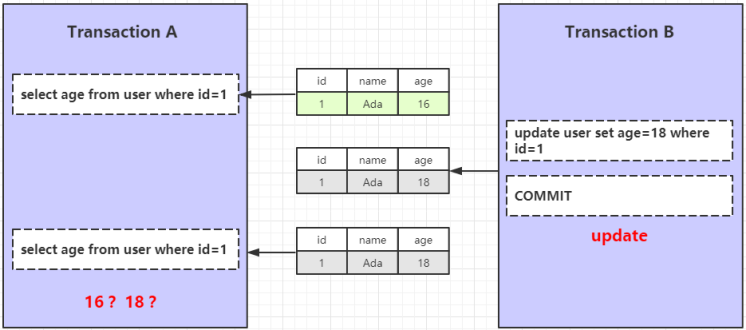
开启两个 MySQL 客户端,模拟事务A和事务B的操作,执行步骤如下:
- 事务A开启手动事务,查询 id=1 的数据
- 事务B更新 id=1 的数据,age 更新为18,并提交事务
- 事务A再次查询 id=1 的数据
图中的数字是执行步骤,通过下图可以看出事务A两次的执行结果都是16,没有受事务B更新操作的影响,InnDB 的默认事务隔离级别完美的解决了不可重复读的问题。
是否解决了幻读的问题?
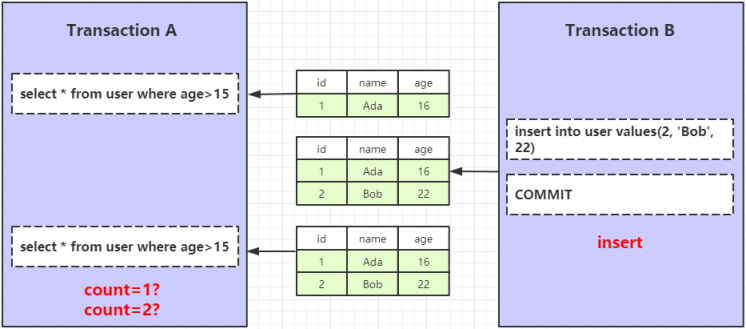
开启两个 MySQL 客户端,模拟事务A和事务B的操作,执行步骤如下:
- 事务A开启手动事务,查询 age>15 的数据
- 事务B新增一条数据,age=22,并提交事务
- 事务A再次查询 age>15 的数据
图中的数字是执行步骤,通过下图可以看出事务A两次的执行结果都是一条数据,没有受事务B新增操作的影响,InnDB 的默认事务隔离级别完美的解决了幻读的问题。
