接着上一章的来讲,对上一章的知识点做一些补充
唯一索引,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查。
唯一索引的效果和主键有些相似,但是最大的区别就是唯一索引是支持数据为空(NULL)的。但是在插入数据的时候也是不能有相同的。
使用场景:
表格里第一列ID为主键,第二列name,第三列是身份证号。正常的情况身份证号是不能重复的,但是如果没有统计身份证号这一列也是可以为空的。
CREATE TABLE t11 ( ID INT auto_increment PRIMARY KEY, NAME CHAR ( 5 ), cardNumber CHAR ( 18 ), UNIQUE uq1 ( cardNumber ));
同样,唯一索引也是可以用多列作为联合唯一索引。比如说一个表,统计了学生选修的各科成绩,第一列为表的主键ID,第二列为课程id(对应课程表的id外键),第三列为学生istudent_d,第四列就是成绩
CREATE TABLE `score` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `student_id` int(11) NOT NULL, `course_id` int(11) NOT NULL, `num` int(11) NOT NULL, PRIMARY KEY (`sid`), KEY `fk_score_student` (`student_id`), KEY `fk_score_course` (`course_id`), CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`), CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`) ) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
使用唯一索引,可以提高数据检索时的效率
我们在前一章已经点到了外键的特点和,使用,普通的外键是个一对多的使用环境。现在我们在看一看几种外键的变种使用环境
一对多
一对多就是最常见的使用环境,
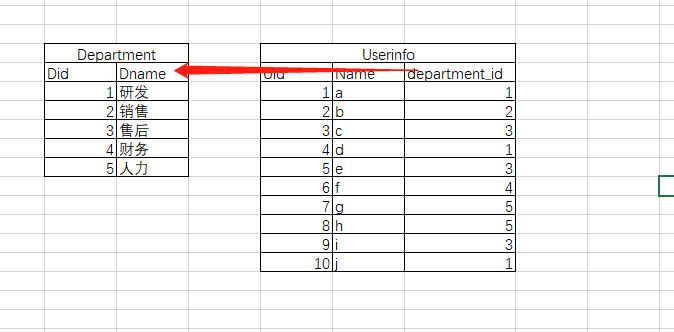
上面的表就是最常见的一对多的使用场景(上面的红箭头应该反过来,一对多)
看看怎么创建两个表
CREATE TABLE Department( Did int PRIMARY KEY auto_increment, Dname varchar(32)); CREATE TABLE Userinfo(Uid int PRIMARY KEY auto_increment, Name char(10), department_id int, CONSTRAINT fk_user_depart FOREIGN KEY (department_id) REFERENCES Department(Did));
一对一
还有一种情况是一对一,比方财务的报表,一个表是员工信息,另一个表是员工的工资账户,这里要求每个员工只能有一个账户,这两个表之间的外键就是个一对一的关系
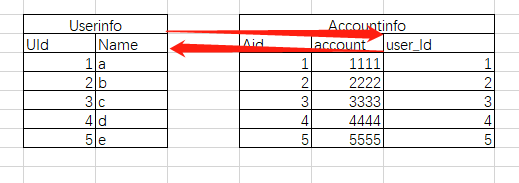
因为每个账户和员工都是一一对应的关系,这时候在设置外键的时候就把user_id设置成唯一索引,代码如下
CREATE table Userinfo(Uid int PRIMARY KEY auto_increment, Name varchar(32)); CREATE table Accountinfo(Aid int PRIMARY KEY auto_increment, account char(20), user_Id int, UNIQUE uq1(user_Id), CONSTRAINT fk_account_user FOREIGN KEY (user_Id) REFERENCES Userinfo(Uid));
再举个例子,我们做一个用户的数据库,包含id,用户名,用户等级,然后某个等级以上的可以登录,保存登录密码,如下图
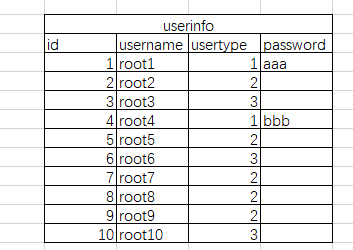
因为不是所有的员工都有登录权限,所以这个表在存起来就比较浪费资源。我们比较常用的就是把密码提出来放在另外一张表上
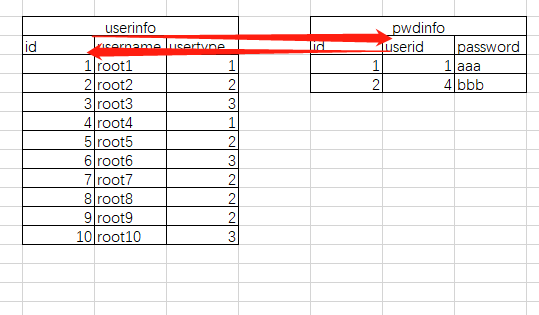
userid和id是一对一的关系,userid也是不能重复的。这个思路就能比较好管理和节省资源。代码就不放了,跟上面那个一对一的差不多。
多对多
还有一种情况是多对多,还是用个例子来说明,比方 有个婚恋网站的用户表,两个表分别记录了用户信息和约会的记录(userinfo其实可以根据用户性别分两个表)
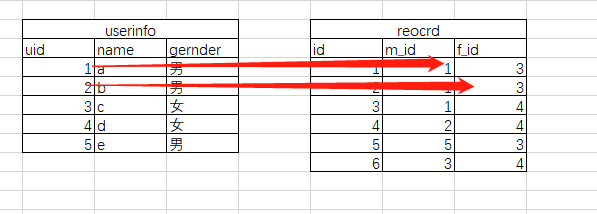
并且这种情形是可以在record里有重复的记录的(每一次约会都可以生成新的一次记录),创建方法
create table userinfo(uid int auto_increment primary key, name char(10), gender ENUM('男','女')); create table record(id int auto_increment primary key, m_id int, f_id int, CONSTRAINT fk_account_user1 FOREIGN KEY (m_id) REFERENCES userinfo(uid), CONSTRAINT fk_account_user2 FOREIGN KEY (f_id) REFERENCES userinfo(uid) )
还有一种情形,一个公司,有几台服务器,根据个人能力每个人用几台服务器,大概就是下面这个图的示意

我们可以在拿到hostid以后的字符串获取到对应的主机名。但是还有一个需求,比方我们想查一下c1这台机子有几个人在用,上面的方法就比较不方便了。所以一般在这种两个表互相占对方多组数据的时候(多对多)我们就在创建一个表
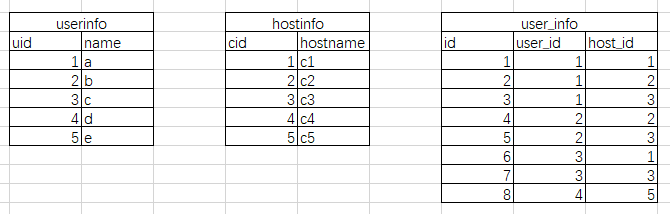
其实上面那个多对多的也可以分成这样的。但是这个user_info表有个特点,就是除了id作为表的主键外,user_id和host_id还可以作为联合唯一索引(因为一个user对一个主机的状态只能出现一次,再出现的时候就是数据异常了)。在实际使用过程中是否使用联合唯一,主要看业务逻辑。
我们在前一章讲了MySQL的数据基本操作,这里做一些补充
增
在添加数据的hi好可以用多个数据,同时用逗号分隔
insert into t1(id,name) values(1,'aa'),(2,'bb'),(3,'cc')
查
区间取值
这个区间是包括m和n的闭区间
select * from tb where id between(m,n);
多条件并行取值in
select * from tb where id in(1,3,5); 取id为1,3,5 的值的数据
通配符(like)
通配符常用的是多字符%和单字符_,
select * from tb where name like 'a%'; select * from tb where name like 'a_';
排序order by
升序asc 和降序desc
select * from tb order by id desc;
限制limit
显示那条数据
select * from tb limit 10;显示前10条数据 select * from tb limit m,n;显示从m开始取n条数据
MySQL里不支持直接从后面去多少条数据,需要先倒序排列在取数
select * from tb order by id desc limit 10 取后10个id的数据
分组 group by
可以根据相同的数据分组,比方下面的数据表
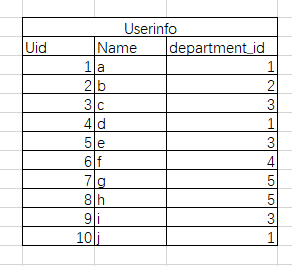
我们想统计不同部门的员工数
select count(Name) from Userinfo group by department_id
这里的count是聚合函数,常用的max,min,sum,avg等等。
分组后的筛选
比方我们要找出部门员工大于2,这时候的筛选就不能用where了,好用having
select Name from Userinfo group by department_id having count(id)>2
总之:where后不能加聚合函数。
连表操作是非常常用的操作。一般用来将多个表通过外键来联合显示内容(不一定非要是外键,不过一般都是用在外键的环境下)
join连表
还是那个一对多的外键
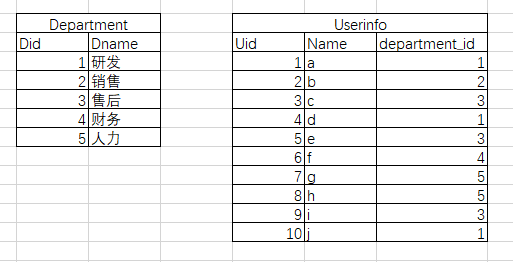
我们需要在结论里直接显示出来每个人的工作部门,这时候就需要用连表了
select * from userinfo left join department on department_id = Did
这里用的是left join,当然还有right join 有比较大的区别的

看一下上面的数据,用户表里是没有Did是5的,
select * from userinfo left join department on department_id = Did
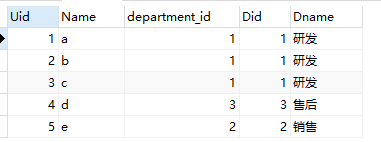
用right join的是这样的

所以,就是用left时,join左边的表会完全显示出来,而用right时,join右边的表的数据会完全显示出来(没有对应值的都是NULL)
也就是说,A left join B 和 B right join A的效果是完全一致的。
还有一种连表的方法是inner join 是自动去除空的数据。
union连表
和join连表左右连表的方式不同,union是把两个表(数据类型可以不同,但列数必须一致)竖着连在一起。列名是按照union前面select的数据的列名起的。
union
普通的union具有去重的功能,当两行数据完全一样的时候,进行union以后就会把相同的删除。下面的表格进行union
select * from t1 union select * from t2;
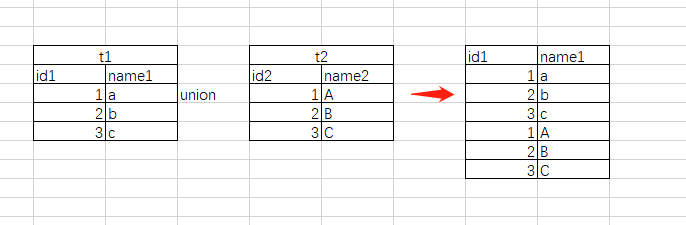
但是如果对t1直接union t1,
select * from t1 union select * from t1;
那么输出的表格和t1是一样的,因为他会去重。
union all
还有一种是不进行自动去重的用法,就是union all
select * from t1 union all select * from t2;
输出就是把t1 直接拼接到 t1后面。
在数学中,笛卡尔乘积是指两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员,
而在sql内,也有一种用法涉及到笛卡尔积,我们这里只先提一下概念,至于怎么用,后面会简单的提一下。

上面的过程就是下面的代码运行结果
select * from t1,t2
至于具体的使用环境我们在后面的案例中会提到,这里就不再细讲了。