an我们在前面大概的讲了一下Django里ORM的使用(点击查看),上次是未完待续,这次继续总结一下Django里ORM的用法。
为了方便调试,我们这一章是用一个py文件来调用Django项目来实现ORM的操作的。
前期准备:
数据库创建database,名字无所谓,models里定义表,Django里数据库的设置和连接这里就不讲了。
class Worker(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=16) age = models.IntegerField() def __str__(self): return "<worker object:id:{},name:{}>".format(self.id,self.name)
然后随便在里面插入一些数据
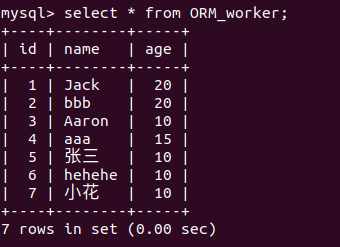
直接查询数据
我们前面的几个案例中,都是通过get和filter来实现的,其实还有一些方法我们还没用到,但是必须要掌握的。
1.all()
获取所有对象
workers = models.Worker.objects.all()
返回的是一个列表,可以通过for循环取出内容。
2.filter()
筛选内容,相当于SQL里的where
worker2 = models.Worker.objects.filter(id=2)
filter的返回值是一个QuerrySet,几遍只有一个对象满足索引要求的时候,也需要用切片的方式来操作该对象
3.get()
get的方法和filter差不多
worker = models.Worker.objects.get(id=1)
但是get返回的对象是一个ORM里在定义table的时候定义的类的对象,这点和filter,并且get用来返回有且只有一个对象的使用环境,如果没有匹配的对象就会直接报错
ORM.models.DoesNotExist: Worker matching query does not exist.
而使用filter 查询,如果匹配对象为空时会返回一个空的set。
4.exclude()
exclude用来筛选出不匹配的对象(not in)刚好和filter是相反的。
worker = models.Worker.objects.exclude(id=1)
上面的代码就是返回了除了id为1 剩下所有的对象。
5.values(Field)
values返回的是一个特殊的QuerrySet,当我们指定了一个字段,返回的Set就是一个key为字段,value为值的字典,如果不指定字段,返回字典的Key就是全部的字段
print(models.Worker.objects.values('name')) print('*'*120) print(models.Worker.objects.values()) ##########输出值########## <QuerySet [{'name': 'Jack'}, {'name': 'bbb'}, {'name': 'Aaron'}, {'name': 'aaa'}, {'name': '张三'}, {'name': 'hehehe'}, {'name': '小花'}]> ************************************************************************************************************************ <QuerySet [{'id': 1, 'name': 'Jack', 'age': 20}, {'id': 2, 'name': 'bbb', 'age': 20}, {'id': 3, 'name': 'Aaron', 'age': 10}, {'id': 4, 'name': 'aaa', 'age': 15}, {'id': 5, 'name': '张三', 'age': 10}, {'id': 6, 'name': 'hehehe', 'age': 10}, {'id': 7, 'name': '小花', 'age': 10}]>
6.values_list(Field)
和values()产不多,但是values_list返回的是一个QuerySet里是一个不包含字段名称的元祖,而values是一个key-value的字典
print(models.Worker.objects.values()) print('*'*120) print(models.Worker.objects.values_list()) #########输出值########## <QuerySet [{'id': 1, 'name': 'Jack', 'age': 20}, {'id': 2, 'name': 'bbb', 'age': 20}, {'id': 3, 'name': 'Aaron', 'age': 10}, {'id': 4, 'name': 'aaa', 'age': 15}, {'id': 5, 'name': '张三', 'age': 10}, {'id': 6, 'name': 'hehehe', 'age': 10}, {'id': 7, 'name': '小花', 'age': 10}]> ************************************************************************************************************************ <QuerySet [(1, 'Jack', 20), (2, 'bbb', 20), (3, 'Aaron', 10), (4, 'aaa', 15), (5, '张三', 10), (6, 'hehehe', 10), (7, '小花', 10)]>
7.order_by(Field)
对查询结果按照指定字段排序,如果只放字段名的话就是升序,字段名前加一个-就是降续
print(models.Worker.objects.all().order_by('id')) #按照id升序排列 print(models.Worker.objects.all().order_by('-id')) #按照id降续排列
这里插播一个课外知识
我们可以在定义ORM类的时候通过meta类定义该类的排序方法
class Worker(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=16) age = models.IntegerField() def __str__(self): return "<worker object:id:{},name:{},age:{}>".format(self.id,self.name,self.age) class Meta: ordering = ('age',)
注意是Meta不是meta,第一次在这里卡了半天。这个ording还可以按下面的方式来赋值
- ordering = ['id'] 按照id升序排列
- ordering = ('-id',) 按照id降续排列
- ordering = ['?id'] 按照id随机排序,?表示随机
- ordering = ['-id','age'] 按照id降续,age升序排列
8.reverse()
reverse()是一个方法,对查询返回的结果进行反向排序
print(models.Worker.objects.all().order_by('id').reverse())
这里要注意的是reverse()通常情况只能在具有已定义顺序的QuerySet上调用(对在models类里通过Meta指定或调用order_by()方法)
9.distinct()
去重,从返回值中删除重复的记录
worker = models.Worker.objects.values('age').distinct() print(worker) ##########输出值########## <QuerySet [{'age': 10}, {'age': 15}, {'age': 20}, {'age': 30}]>
如果查询跨越了多个表,可能会在计算QuerySet时候会得到重复的结果,此时就可以使用distinct()来去重,注意只有在PostgreSQL类支持按字段去重。
10.count()
统计匹配的的QuerySet对象数量,用法很简单
print(models.Worker.objects.all().count())
11.first()
返回匹配的QuerySet内的第一条记录,返回值为modes类对象
worker = models.Worker.objects.all().first()
12.last()
和前一条first()的用法相同,用来获取最后一条记录
13.exists()
判断返回的QuerySet内是否包含数据,返回值为True或False
总结
上面13条是非常常用的方法,按照返回值的类型我们可以这么划分
返回QuerySet对象
1 all() 2 filter() 3 exclude() 4 order_by() 5 reverse() 6 distinct()
返回特殊值
1 values() 2 values_list()
返回具体对象
1 get() 2 first() 3 last()
返回布尔量
1 exists()
返回数字
1 count()
双下划线在单表查询的使用
在单表查询时候常常要用到双下划线,特别是在做比较或判断的时候
worker = models.Worker.objects.filter(id__lt=2) #id小于2 worker = models.Worker.objects.filter(id__gt=2) #id大于2 worker = models.Worker.objects.filter(id__in=[1,3,5]) #id为1,3,5 worker = models.Worker.objects.exclude(id__in=[1,3,5]) #id不为1,3,5,同not in worker = models.Worker.objects.filter(name__contains='a') #name中包含a worker = models.Worker.objects.filter(name__icontains='a') #name中包含a,忽略大小写 worker = models.Worker.objects.filter(id__range=[1,5]) #between,包含头尾
此外还有一些关键字可以用:startswith,istartswith,endswith,iendswith(以某字符开头、结尾,加i表示大小写不敏感)
如果字段是date类型的话还可以直接指定年月日(比方有个字段是birthday)
worker = models.Worker.objects.filter(birthday__year=2019)
我们在前面大概讲了一下外键的使用,主要说的是正反向的查询(点击查看),这里补充一些其他的说明
正反向查询
先回顾一下正反向查询吧,把上面的表修改一下:
class Department(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=16) class Meta: db_table = 'department' def __str__(self): return "<department object:id:{},title:{}>".format(self.id,self.title) class Worker(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=16) age = models.IntegerField() department = models.ForeignKey(to='Department',on_delete=models.CASCADE) def __str__(self): return "<worker object:id:{},name:{}>".format(self.id,self.name)
注意下这里用了第二个Meta里的属性:db_table:指定了MySQL里的table的名称,便于后期操作数据库(但是这个使用环境有待商榷,因为如果app较多的时候可能会比较乱,不好管理)
在Worker表里,通过指定外键创建了一个字段:部门
我们先添加一些数据
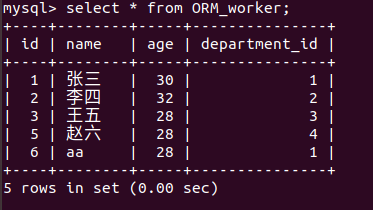

注意一下添加数据的方法:
models.Department.objects.create(title='售后') models.Worker.objects.create(name='aa',age=28,department_id='1') #外键:字段名_id
并且一定要先添加department。然后注意下外键那里是怎么添加的
正向查询(跨表)
因为在models里,定义外键的时候是在worker里,那么从Worker里查department就是正向查询

比方我们想查张三是哪个部门的:
方法1:利用对象跨表查询
print(models.Worker.objects.get(name='张三').department)
具体的思路在前面那个文章里有,这里就不详述了。
方法2:还可以用双下划线的方式跨表直接查:
表名__字段
dep = models.Worker.objects.filter(name='张三').values('department__title')#department__title为表名__字段名的方式实现跨表查询
反向查询
但是要查某个部门里有哪些职工,就要用到反向查询,有种复杂的方法:
先获取指定部门的ID号,再根据这个id号去Worker类里索引
dep_id = models.Department.objects.get(title='IT').id workers = models.Worker.objects.filter(department_id = dep_id)
这个方法有些麻烦,如果需要连好几个表的话需要多条语句才行,当然我们也可以用ORM的反向查询这个功能
dep = models.Department.objects.get(title='IT') workers = dep_id.worker_set.all()
虽然都是两行代码,但是还是有些区别的,第一个方法是用id(一个int类型的数据)去查worker,第二个是用返回的department对象的反向查询的属性查的。
要注意的是用_set的对象必须是ORM的类对象,不能是QuerySet对象,也就是说如果使用了filter的方法必须要用切片或者循环取出ORM对象才可以。
比方我们想查出IT和销售都有哪些人:
dep = models.Department.objects.filter(title__in=['IT','销售']) print(dep) for i in dep: workers = i.worker_set.all() print(i,workers)
反向查询的related_name
我们还可以在定义类的时候为外键加上一个参数:related_name,用来在反向查询的时候直接使用这个名字
department = models.ForeignKey(to='Department',on_delete=models.CASCADE,related_name='workers')
在定义外键的时候指定了一个反向的关系名,我们在反向查询的时候就可把_set改成这个名字
dep = models.Department.objects.get(title='IT') ret = dep.workers.all() #workers就是前面定义的related_name
这两个方法没什么区别,怎么方便都可以使用,但是要注意一旦定义了related_name就不能用_set的方法了。
加了related_name的反向跨表查询
在加了related_name以后,我们还可以用这个表名加双下划线来获取结论(name)
workers = models.Department.objects.filter(title='IT').values_list("workers__name") ##########注意返回值########## <QuerySet [('张三',), ('aa',)]>
related_query_name的使用
还有一种情形,我们可以在反向查询的时候指定一个表名
department = models.ForeignKey(to='Department',on_delete=models.CASCADE,related_query_name='xxx')
然后在反向查询的时候直接用xxx来表示一个表名
workers = models.Department.objects.filter(title__in=['IT','销售']).values_list("xxx__name")
这个方法的使用环境非常少,有些时候需要动态的绑定数据库的时候可能会用到,有时候会关联表1,有时候会关联表2,这时候要用这个方法来指定一个表名。
注意注意
我们前面用了两种方式来查询:基于对象的,和基于双下划线的,但是我们用的values或values_list的对象是一个QuerySet,用一个ORM的对象是不行的。所以,下面的方法是可以的
workers = models.Department.objects.filter(title__in=['IT','销售']).values_list("workers__name")
直接使用,不用for循环依次打印。
也就是说ORM的对象(get,all())之类的,有什么属性(name,id,title)就直接点什么就行了:department.id,department.title,worker.name这种方法
而用filter()得到的QuerySet还可以用values(),values_list()等方法。
级联删除
我们在前面说了,在Django2.0以后的版本中,定义外键的时候必须显性的指定下面的参数
on_delete=models.CASCADE
这里在讲一下级联删除的选项
- CASCADE ——级联删除,在Django2.0以前是默认选项,被引用的实体被删除后,相关的记录信息都会被删除
- PROTECT——组织删除被引用的实体,除非先把所有引用的记录删除
- SET_NULL——把字段设置成Null,但是必须允许为Null
- SET_DEFAULT—— 把字段设置为默认值
- SET()——可以传递一个函数给SET()方法,当字段引用的记录被删除以后,此字段的值有给定的方法决定
- DO_NOTHING——什么都不做,保持之前的值,如果数据库后端设置了外键约束,那么就会抛出一个IntegrityError。
这个先了解一下,以后可能还会讲到。
有些时候我们会对一张表进行字段的扩充,但是同时不改变原表,或者一部分字段检索的频率比较低,这时候就可以把不常用的字段独立出来做一个表,然后两个个表一对一的 关联起来。这样就在数据的完整保存的同时保证了更快的检索
比方我们想把前面的worker表里加上一个字段,里面放上每人的地址和爱好,电话。
class Worker(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=16) age = models.IntegerField() # department = models.ForeignKey(to='Department',on_delete=models.CASCADE) department = models.ForeignKey(to='Department',on_delete=models.CASCADE,related_query_name='xxx',related_name='workers') detial = models.OneToOneField(to='WorkerDetails',null=True,on_delete=models.CASCADE) def __str__(self): return "<worker object:id:{},name:{}>".format(self.id,self.name) class WorkerDetails(models.Model): address = models.CharField(max_length=128) hobby = models.CharField(max_length=64) phone = models.CharField(max_length=11)
在定义一对一的时候我加了个允许为空是因为worker表里是有数据的。还有,第二个这个表里是没有定义主键的。直接就可以建立。
同时,一对一关系插入新的数据也是要有顺序的,一定要先插入第二个表
detial_new = models.WorkerDetails(address='广州2',hobby='撸猫',phone='12344') detial_new.save() department_new = models.Department.objects.get(id=2) worker = models.Worker(name='abc',age=18,department=department_new,detial=detial_new) worker.save()
在上面的例子中,先创建病插入了一个新对象detial,然后在创建worker的时候把这个detial对象带进去。
查询的方法比较简单,跟外键的方法一样
worker = models.Worker.objects.get(id=1) print(worker.detial.hobby)
在前面的范例中我们已经使用过了多对多的关联,至于是如何实现的并没有深究,我们这里在看一看多对多的关联是怎么实现的,同样我们先用下面的代码创建两个表,并做一个多对多的关联
class Books(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=32,) def __str__(self): return self.title class Authors(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=16) books = models.ManyToManyField(to="Books") def __str__(self): return self.name
再看看多对多的正向查询和反向查询:
正向查询:指定作者查书籍:
author = models.Authors.objects.get(id=1)
author_book = author.books.all()
反向查询:指定图书查作者
book = models.Books.objects.get(title = '学习Linux') book_author = book.authors_set.all()
关联管理器——class RelatedManager
我们从关联管理器入手,看看多对多的关联是如何实现的
我们在前面那章说过了,多对多的关联是通过三个表的链接来实现的,那第三个表就是通过这个关联管理器来实现的。
我们用正向查询查一下指定作者的书籍,然后看看数据类型
author= models.Authors.objects.first() print(type(author.books)) ##########输出########## <class 'django.db.models.fields.related_descriptors.create_forward_many_to_many_manager.<locals>.ManyRelatedManager'>
注意看一下这个数据的类型——ManyRelatedManager
通过这个类的方法,我们可以直接操作这第三个个表
关联管理器的方法
create()
我们可以通过指定作者添加一本书
author= models.Authors.objects.first() author.books.create(title='学习修电视')
这样就会有下面两件事情发生
- 在books表里添加一个新的数据
- 在作者和书的关系表中添加一条新的关联记录
add()
add方法实现了添加关联记录的效果
book_obj = models.Books.objects.get(title='学习Python') #这本书还没有指定作者 author_obj = models.Authors.objects.get(name = '王五') author_obj.books.add(book_obj) #正向添加 book_obj.authors_set.add(author_obj) #反向添加
通过add是只操作了关联表,并不会操作书籍表或作者表。
add方法还可以添加多个对象,但是要用到拆包的方法
author_obj = models.Authors.objects.get(id=4) books_obj = models.Books.objects.filter(id__gt=2) #返回包含多个值的一个列表 author_obj.books.add(*books_obj) #多个对象被add,可以用拆包的方法:*+列表
注意一下,上面两个范例中add的对象分别是ORM对象和QuerySet对象,除此意外还可以直接添加id
author_obj.books.add(1) #直接添加id
set()
用来更新models对象的关联对象,参数可以直接穿id
author_obj = models.Authors.objects.get(name='王五') books = author_obj.books.all() print(books) author_obj.books.set([3,4]) print(books)
remove()
从关联的对象中删除指定的数据,使用方法和add一样,效果相反
author_obj = models.Authors.objects.get(id=4)
author_obj.books.remove(1)
remove的参数可以是model对象,id号,拆包的QuerySet列表
clear()
直接清空指定对象的关联表
author_obj = models.Authors.objects.get(name='张三') author_obj.books.clear()
要注意的是这里删除的只是关联关系,另外两个table里的数据不会变
补充说明一点:
ForeignKey字段中,如果要用clear()和remove()的话必须设置null=True,也就是说只有字段值可以为空才能删除有外键限制的数据。
重新修改一下models里的类,给Books加上一个价格的字段(price)
class Books(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) def __str__(self): return self.title
然后添加数据,效果如下
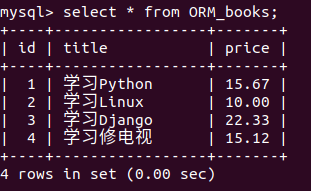
聚合查询
聚合查询aggregate()是QuerySet的一个终止子句,返回值是一个包含一些键值对的字典。键的名称是聚合值的标识符,是按照字段和聚合函数的名称自动生成的,值是计算出来的值。
现在想计算一下所有书籍的平均售价
from django.db.models import Avg,Sum,Max,Min #所用的聚合函数一定要先导入 avg_price = models.Books.objects.all().aggregate(Avg("price"),Max('price')) print(avg_price) ##########输出值########## {'price__avg': 15.78, 'price__max': Decimal('22.33')}
看一下,key的名称是不是就是字段名__聚合函数名,当然我们还可以指定这个key的名字
avg_price = models.Books.objects.all().aggregate(平均值=Avg("price")) ##########输出值########## {'平均值': 15.78}
这里演示一下,在真实的生产环境中还是不建议使用中文的。
分组查询
分组查询的效果类似于SQL语句中的groupby
比方我们现在想获取下每本书的作者个数
books = models.Books.objects.all().annotate(author_num=Count('authors')) for book in books: print(book,book.author_num)
第一条语句我们会在book里添加一个字段:author_num,字段的值是通过聚合函数计算的
我们还可以对分组的结论进行过滤,比方我们想筛选出作者数量大于1的书籍,就可以把上面的代码稍微修改一下
books = models.Books.objects.all().annotate(author_num=Count('authors')) books_2 = books.filter(author_num__gt=1) for book in books_2: print(book,book.author_num)
再查一下每个作者出的书一共价值多少钱:
author = models.Authors.objects.all().annotate(price_sum = Sum('books__price')) for i in author: print(i.name,i.price_sum)
其实我们可以用values()方法来看一下,查查经过分组以后有什么变化
author = models.Authors.objects.all().annotate(price_sum = Sum('books__price')) print(author.values()) ##########输出########## <QuerySet [{'id': 2, 'name': '李四', 'price_sum': Decimal('10.00')}, {'id': 3, 'name': '王五', 'price_sum': Decimal('37.45')}, {'id': 4, 'name': '赵六', 'price_sum': Decimal('37.45')}, {'id': 1, 'name': '张三', 'price_sum': None}]>
是不是多了一个字段。
F查询
在前面的所有例子中, 我们构造的过滤器filter都是讲字段与某个常量值来做比较,但是如果我们需要讲两个字段的值来比较的话,该怎么做呢?
Django提供了F()查询来满足我们这种需求,修改一下Books这个类,加上两个字段:已卖出sold和库存remain
class Books(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) sold = models.IntegerField(default=200) remain = models.IntegerField(default=150) def __str__(self): return self.title
然后把数据大概更改一下

现在如果想查一下售出的比库存多的数据,就要用到这个F查询了
from django.db.models import F books = models.Books.objects.filter(remain__gt=F('sold')) print(books)
Django还支持了F()函数和常数之间的计算操作,比方我们要刷个单,把已经卖出的书数量乘以2
models.Books.objects.update(sold=F('sold')*2)
这样就把已经卖出的数量乘了2
引申一个用法,上面的方法是对int类型的数据进行计算,除此以外还可以对char类型进行修改,比方我们要把书名后面加上“(第一版)”那要怎么操作呢?
from django.db.models.functions import Concat from django.db.models import Value models.Books.objects.update(title=Concat(F('title'),Value("(第一版)")))
Q查询
前面的操作里常常用到的filter()操作中的关键字查询默认情况都是一起进行AND操作的,
book =models.Books.objects.filter(price__lt=20,sold__gt=300)
上面的代码就是查询了价格低于20,并且卖出数量大于300的书籍
如果需要执行更复杂的查询时(比方是OR查询),就可以用Q查询
如果要查询卖出数量大于300 ,或者价格低于20,那要怎么查呢?
from django.db.models import Q book =models.Books.objects.filter(Q(price__lt=20)|Q(sold__gt=300))
重点:
如果在一个查询操作中同事存在Q查询和默认的字段查询是,一定要把Q查询放在前面
book = models.Books.objects.filter(Q(price__lt=20)|Q(sold__gt=300),title__contains='Linux')
一定要把Q查询放在前面,否则就报错了:
book = models.Books.objects.filter(title__contains='Linux',Q(price__lt=20)|Q(sold__gt=300)) ##########错误提示########## book = models.Books.objects.filter(title__contains='Linux',Q(price__lt=20)|Q(sold__gt=300)) ^ SyntaxError: positional argument follows keyword argument
在settings.py文件最后加上下面这段代码,可以在调试的时候显示出ORM生成的SQL语句。
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }