一、time和datetime模块
1、time模块
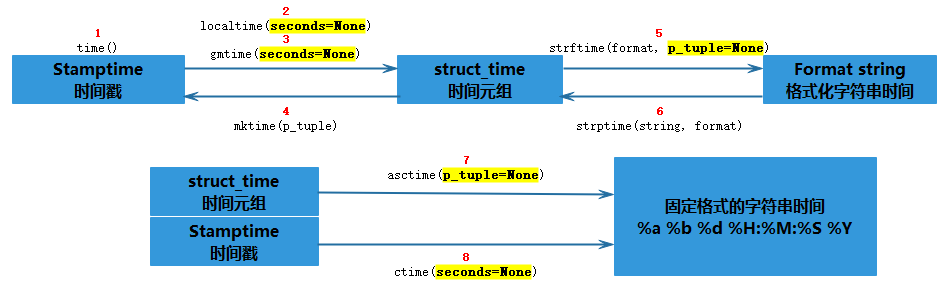
import time print(time.time()) # 从1970年到当前时间的秒数 print(time.ctime()) # 传入秒数,默认是time.time(),显示参数时间的固定可读形式如:Mon Jun 17 21:39:54 2019 print(time.clock()) # 可以计算运行程序代码的cpu时间 time.sleep(0) # 让程序暂停 print(time.localtime()) #返回一个当前时区的时间元组 print(time.gmtime()) # 返回一个世界标准时间的时间元组 print(time.mktime(time.localtime())) #将时间元组转化成时间戳 print(time.strftime("%Y-%m-%d %H-%M-%S", time.localtime())) # 格式化时间
问题:在统计程序运行时间时,time.time()和time.clock()的区别?
2、datetime模块
import datetime print(datetime.datetime.today()) # 当前的日期和时间 print(datetime.datetime.now()) # 同上 print(datetime.date.today()) # 今天的日期
# 对时期加减
today = datetime.date.today()
one_day = datetime.timedelta(days=1)
yesterday = today - one_day
二、random模块
import random random.random() # 从0-1的随机小数 random.uniform(m,n) # 从m-n的随机小数 random.randint(m,n) #从m-n的随机整数,包括m和n random.randrange(m,n,s) # 从m-n指定步长 random.shuffle(l) # 打乱一个列表 random.choice(l) # 从一个序列随机选择一个数 random.sample(l) # 随机选取指定个数
三、sys,os模块
1、os模块,与操作系统相关
import os os.mkdir(xx) os.makedirs(xx/xx/xx) os.rmdir(xx) os.removedirs(xx/xx/xx) os.path.join(xx,xx) os.path.listdir(xx) # 返回路径下所有文件名 os.path.getsize(xx) # 返回文件大小 os.path.isfile(xx) ps.path.isdir(xx) ps.path.exists(xx)
2、sys模块,与python解释器有关
import sys sys.args # 返回在命令行启动python时传递的参数 sys.path # 返回模块搜索路径的字符串列表,import模块时会在这些路径中寻找
四、pickle和json
import pickle pickle.dumps("xxx") # 将数据转换成字节 pickle.loads(xx) # 将字节转化成python数据 pickle.dump("xx", open("xx", "wb")) # 将数据以字节形式写进文件 pickle.load(open("xx", "rb")) # 将数据从文件读出来 import json json.dumps("xxx") # 将数据转换成json字符串 json.loads(xx) # 将json字符串转化成python数据 json.dump("xx", open("xx", "w")) # 将数据以json字符串格式写进文件 json.load(open("xx", "r")) # 将数据从文件读出来
五、hashlib模块
hashlib采用摘要算法进行加密,对同样的内容,加密结果永远不变,对不同的内容永远不一样。
hashlib不能解密。
应用场景:密码的密文存储、文件的一致性验证
import hashlib md = hashlib.md5(b'xx') # 可以加盐,防止撞库 md.update(b'xxxxx') # 必须是bytes类型 print(md.hexdigest())
但是这样的加密可能会被撞库破解,所以为了加强密码的安全性,可以为其加盐
在md = hashlib.md(b'salt'),这样加盐,盐也必须是一个bytes类型。
六、re模块
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| { n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| { n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| { n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| w | 匹配字母数字及下划线 |
| W | 匹配非字母数字及下划线 |
| s | 匹配任意空白字符,等价于 [ f]. |
| S | 匹配任意非空字符 |
| d | 匹配任意数字,等价于 [0-9]. |
| D | 匹配任意非数字 |
| , , 等. | 匹配一个换行符。匹配一个制表符。等 |
1、正则表达式
括号相关:[ ],[^... ],( ),{ }
元字符:d,w,s,D,W,S,|,.,^$
量词:?+*
2、re模块用法
import re re.findall(pattern,string) # 匹配所有符合的结果,返回一个列表 re.finditer(pattern, string) # 返回一个迭代器,保存所有符合的结果 re.search(pattern, string) # 全文匹配,返回一个对象,只匹配第一个符合的结果 re.match(pattern, string) # 匹配开头是否符合结果,返回一个对象,只包含一个结果 xx.group() # 上面三个方法返回的对象都可以通过.group()来获取值,如果没有匹配到会报错 re.split(pattern, string) # 用法和字符串的split一致,返回一个列表 re.sup(pattern, new, string) # 用法和字符串的replace一致,返回新的字符串 re.supn(pattern, new, string) # 返回一个元祖,保存新的字符串,和替换成功的次数 re.complie('xxxx') # 保存着一段正则规则,可以重复使用,减少字符串转化成正则表达式的次数
3、贪婪匹配和惰性匹配
正则表达式中匹配机制默认是贪婪匹配,会尽量多的匹配。如果想使用惰性匹配,可以在量词后面加一个?,如*?,+?,??
4、分组相关
当findall的匹配规则涉及到分组时,会优先匹配分组里的结果,而不是匹配符合整个正则表达式的结果。如果不需要优先匹配分组,可以在分组中使用(?:xxx)取消优先。
search(n)可以传递一个参数n,返回第n个分组匹配到的结果。
split(xxx)如果涉及到分组,会把分组中的内容也保存下来。
分组命名,与django中路由匹配的一样,(?P<xxx>d+)(?P=xxx),如果想匹配的两个部分是一样的,可以使用这个,比如匹配html标签
七、math模块
1.math.gcd(x,y):返回x和y的最大公约数
八、itertools模块
1.itertools.groupby(list, func):将序列里的数据,根据func的规则分组
2.itertools.product(A,B,C...):返回参数里每个元素的笛卡尔积数组组成的列表。
九、functools模块
1.functools.wraps:用来给装饰器函数加上,保持原函数的函数信息
2.functools.lru_cacache:用来给函数加上的装饰器,传入该函数的参数和结果会做一个缓存,同样的参数直接返回结果,但是只会缓存不可变类型的参数结果。
十、collections模块
1.defaultdict:当键不存在时返回什么
2.namedtuple:具名元祖
3.deque:双端队列
4.Counter:返回一个字典,键为参数序列中出现的元素,值为各个元素出现的次数
5。OrderDict:有序字典