NameNode与DataNode的工作原理剖析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS写数据流程
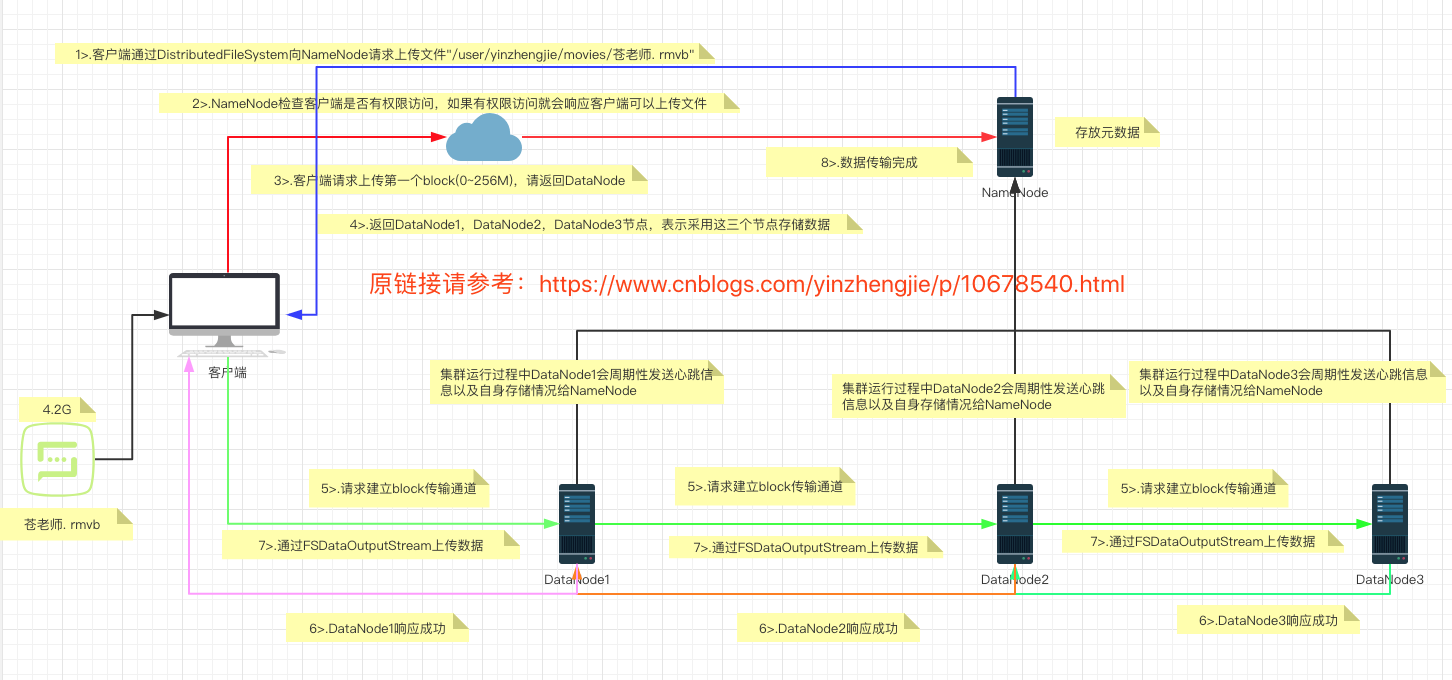
1>.客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 2>.NameNode返回是否可以上传。 3>.客户端请求第一个 Block上传到哪几个DataNode服务器上。 4>.NameNode返回3个DataNode节点,分别为DataNode1、DataNode2、DataNode3。 5>.客户端通过FSDataOutputStream模块请求DataNode1上传数据,DataNode1收到请求会继续调用DataNode2,然后DataNode2调用DataNode3,将这个通信管道建立完成。 6>.DataNode1、DataNode2、DataNode3逐级应答客户端。 7>.客户端开始往DataNode1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,DataNode1收到一个Packet就会传给DataNode2,DataNode2传给DataNode3;DataNode1每传一个packet会放入一个应答队列等待应答。 8>.当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
问第一个问题:请详细说明上面的第5步,DFSOutputStream是基于什么为单位上传数据的呢? DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。data queue会向NameNode节点请求适合存储数据副本的DataNode节点的列表,然后这些DataNode之前生成一个Pipeline数据流管道,我们假设副本集参数被设置为3,那么这个数据流管道中就有三个DataNode节点。 问第二个问题: 在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢? 首先,Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失; 接着,在正常的DataNode节点上的以保存好的block的ID版本会升级——这样发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,失效节点也会被从Pipeline中删除; 最后,剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。 如果Pipeline中的多个节点在写数据是发生失败,那么只要写成功的block的数量达到dfs.replication.min(默认为1,Hadoop2.9.2版本已经将其更名为dfs.namenode.replication.min),那么就任务是写成功的,然后NameNode后通过一步的方式将block复制到其他节点,最后事数据副本达到dfs.replication参数配置的个数。
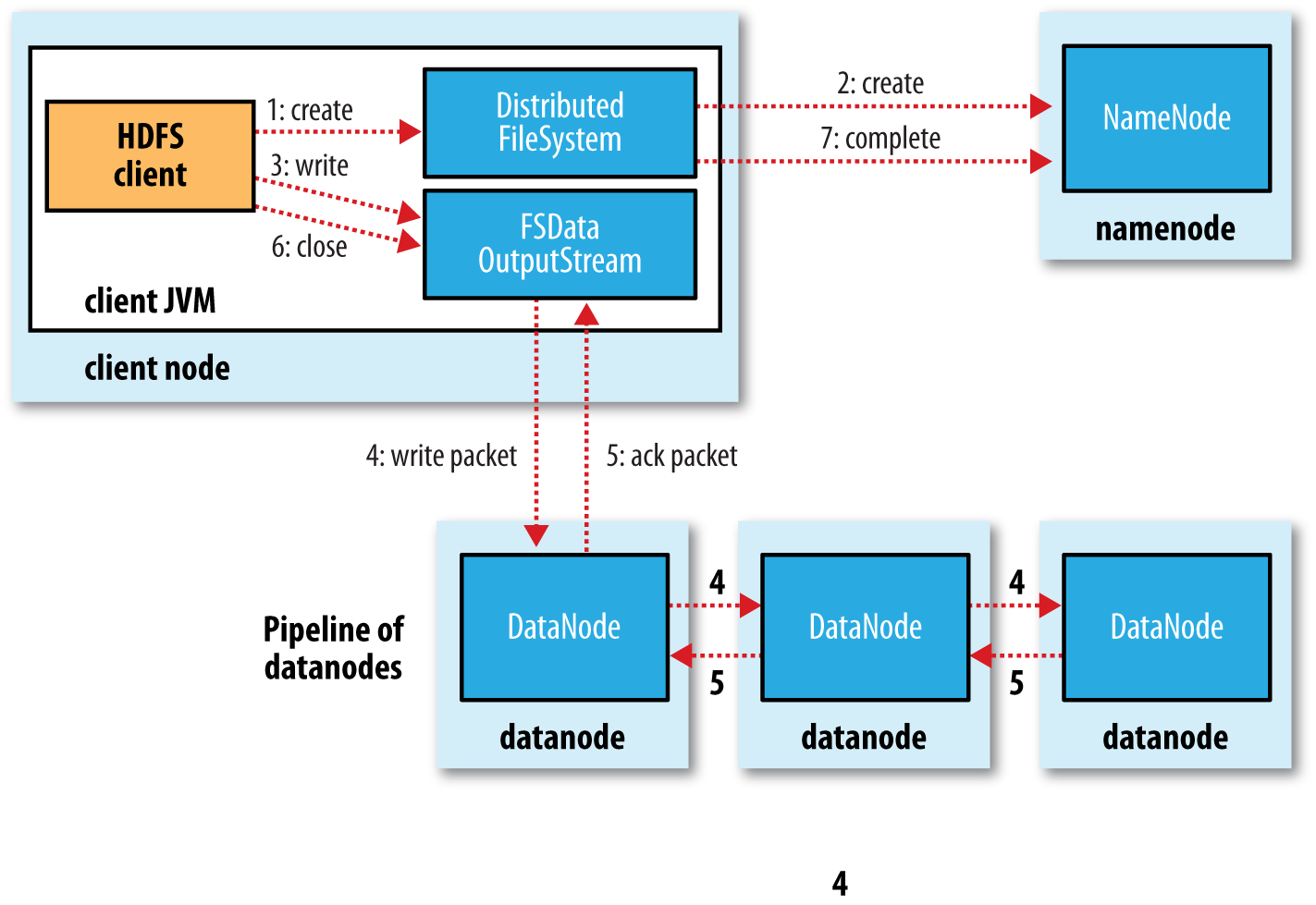


整个写流程如下: 第一步: 客户端调用DistributedFileSystem的create()方法,开始创建新文件:DistributedFileSystem创建DFSOutputStream,产生一个RPC调用,让NameNode在文件系统的命名空间中创建这一新文件; 第二步: NameNode接收到用户的写文件的RPC请求后,首先要执行各种检查,如客户是否有相关的创佳权限和该文件是否已存在等,检查都通过后才会创建一个新文件,并将操作记录到编辑日志,然后DistributedFileSystem会将DFSOutputStream对象包装在FSDataOutStream实例中,返回客户端;否则文件创建失败并且给客户端抛IOException。 第三步: 客户端开始写文件:DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。data queue会向NameNode节点请求适合存储数据副本的DataNode节点的列表,然后这些DataNode之前生成一个Pipeline数据流管道,我们假设副本集参数被设置为3,那么这个数据流管道中就有三个DataNode节点。 第四步: 首先DFSOutputStream会将packets向Pipeline数据流管道中的第一个DataNode节点写数据,第一个DataNode接收packets然后把packets写向Pipeline中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向Pipeline中的第三个DataNode节点。 第五步: DFSOutputStream内部同样维护另外一个内部的写数据确认队列——ack queue。当Pipeline中的第三个DataNode节点将packets成功保存后,该节点回向第二个DataNode返回一个确认数据写成功的信息,第二个DataNode接收到该确认信息后在当前节点数据写成功后也会向Pipeline中第一个DataNode节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将packets从ack queue中将数据删除。 在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢?如果这种情况发生,那么就会执行一些操作: 首先,Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的最前面以确保不会发生packets数据包的丢失; 接着,在正常的DataNode节点上的以保存好的block的ID版本会升级——这样发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,失效节点也会被从Pipeline中删除; 最后,剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。 如果Pipeline中的多个节点在写数据是发生失败,那么只要写成功的block的数量达到dfs.replication.min(默认为1),那么就任务是写成功的,然后NameNode后通过一步的方式将block复制到其他节点,最后使数据副本达到dfs.replication参数配置的个数。 因此,我们不得不怀疑该机制是否会导致一定的数据重复呢? 第六步: 完成写操作后,客户端调用close()关闭写操作,刷新数据; 第七步: 在数据刷新完后NameNode后关闭写操作流。到此,整个写操作完成。 参考链接:https://flyingdutchman.iteye.com/blog/1900536
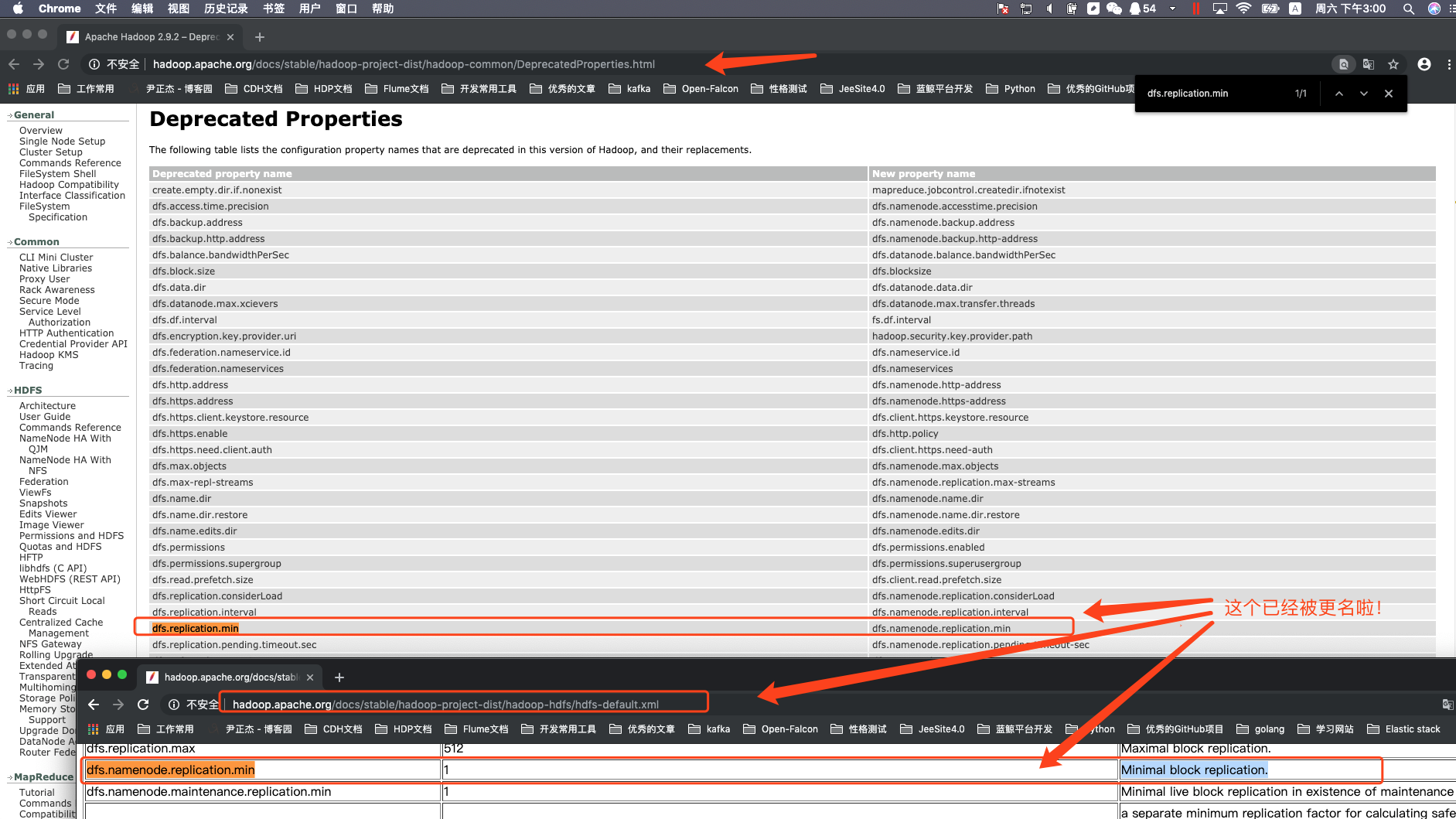
上面我们说到的dfs.replication.min属性官方已经被更名为dfs.namenode.replication.min,因此我们直接去官方文档查阅dfs.replication.min肯能会查不到,更多参数变更请参考官方说明:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/DeprecatedProperties.html(不推荐使用的属性下表列出了此版本的Hadoop中不推荐使用的配置属性名称及其替换。)
二.机架感知
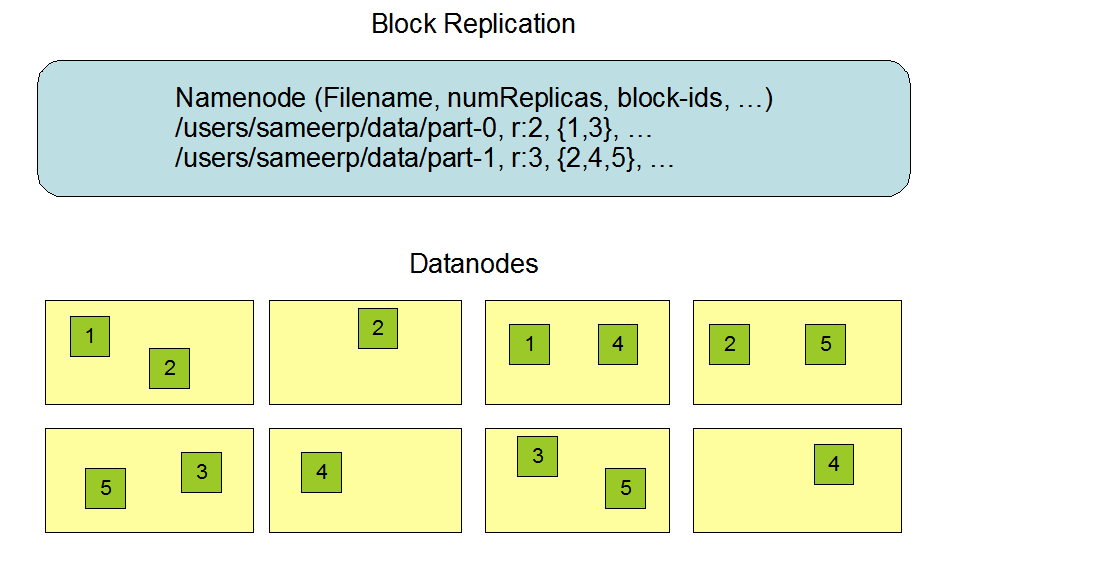
对于常见情况,当复制因子为3时,HDFS的放置策略是将一个副本放在本地机架中的一个节点上,另一个放在本地机架中的另一个节点上,最后一个放在不同机架中的另一个节点上。副本节点的选择大致为:
1>.第一个副本在Client所处的节点上,如果客户端在集群外,随机选一个;
2>.第二个副本和第一个副本位于相同机架,随机节点;
3>.第三个部分位于不同几家,随机节点; 感兴趣的小伙伴可以参考官方文档: 参考一:http://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
参考二:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/RackAwareness.html
三.HDFS读数据流程
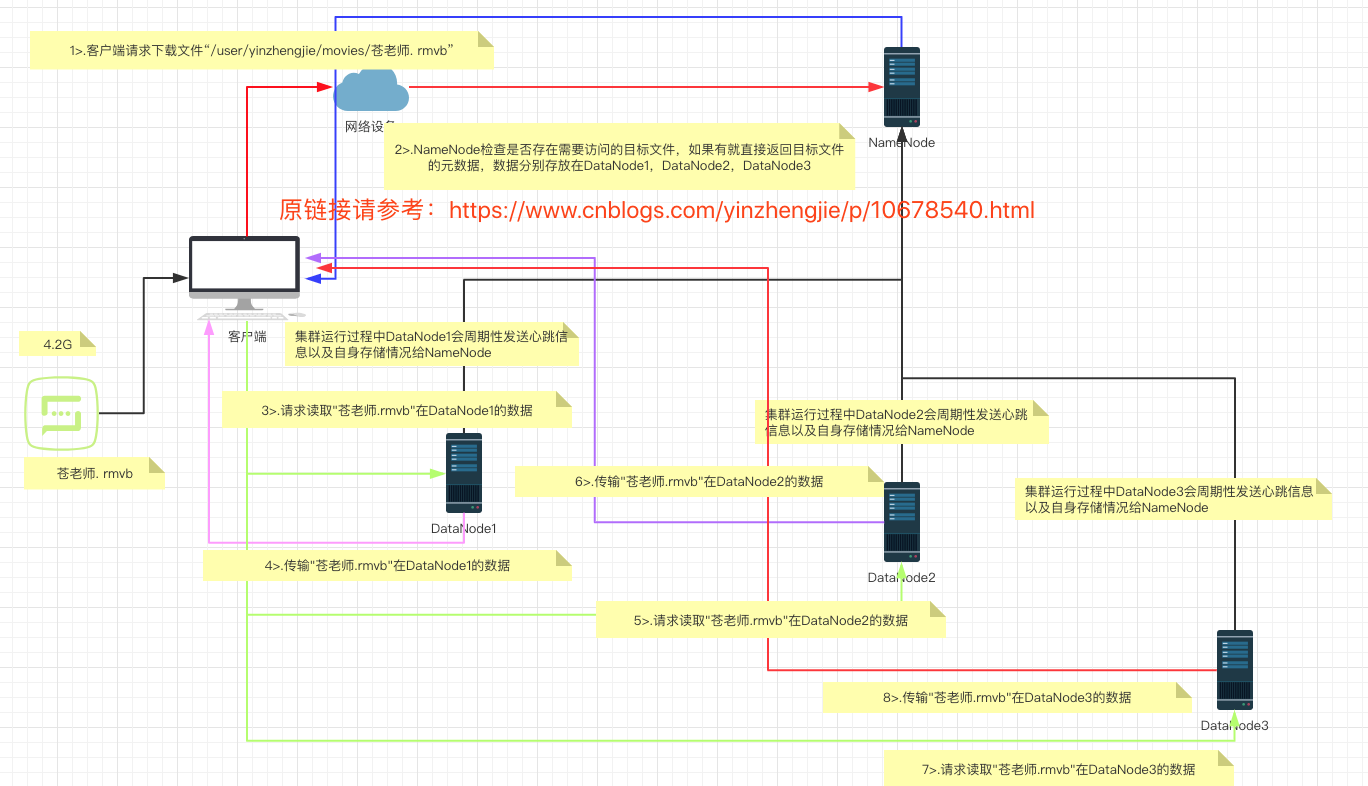
1>.客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2>.挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3>.DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4>.客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
四.DataNode工作原理
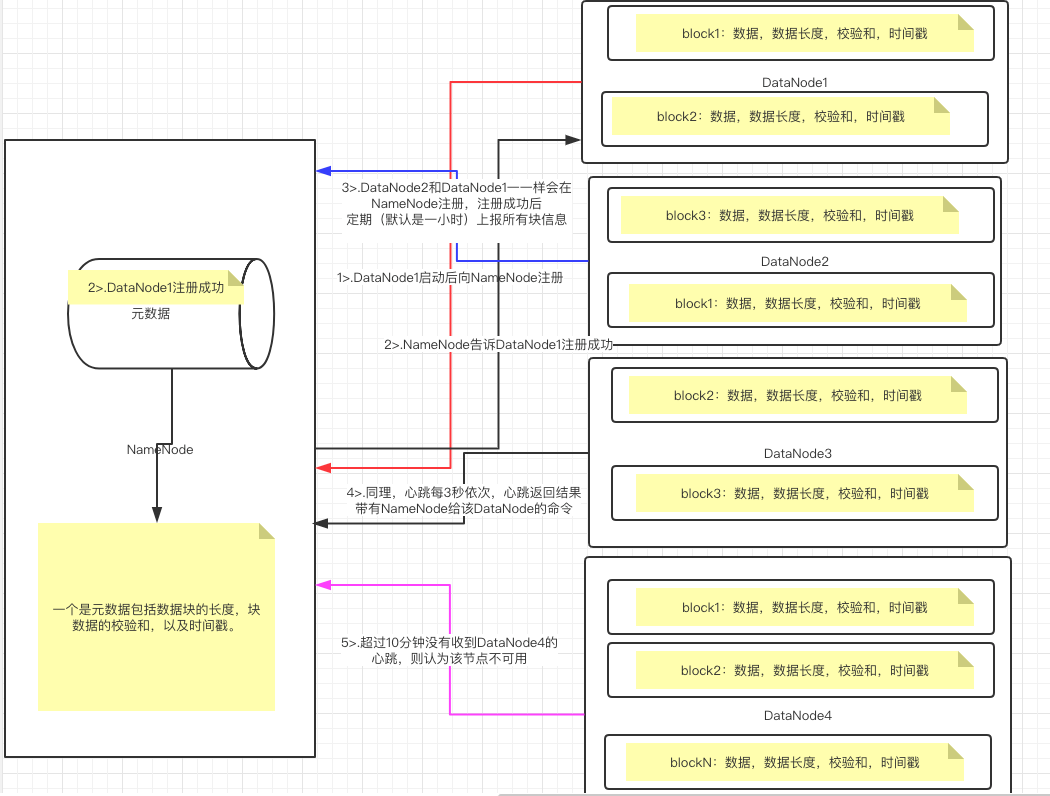
1>.一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2>.DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3>.心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4>.集群运行中可以安全加入和退出一些机器。
五.数据完整性
1>.当DataNode读取block的时候,它会计算checksum; 2>.如果计算后的checksum,与block创建时值不一样,说明block已经损坏; 3>.client读取其他DataNode上的block; 4>.datanode在其文件创建后周期验证checksum;
六.掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:“timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval ”。
而默认的"dfs.namenode.heartbeat.recheck-interval"大小为5分钟,"dfs.heartbeat.interval"默认为3秒。需要注意的是hdfs-site.xml配置文件中"heartbeat.recheck.interval"的单位为毫秒,"dfs.heartbeat.interval"的单位为秒。
[root@node101.yinzhengjie.org.cn ~]# cat /yinzhengjie/softwares/hadoop-2.9.2/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/hdfs/dfs/name</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> </configuration> <!-- hdfs-site.xml 配置文件的作用: #HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.namenode.checkpoint.period 参数的作用: #两个定期检查点之间的秒数,默认是3600,即1小时。 dfs.namenode.name.dir 参数的作用: #指定namenode的工作目录,默认是file://${hadoop.tmp.dir}/dfs/name,namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。建议配置的多目录用不同磁盘挂在,这样可以提升IO性能! dfs.replication 参数的作用: #为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用 保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个软件级备份。 dfs.heartbeat.interval 参数的作用: #设置心跳检测时间 dfs.namenode.heartbeat.recheck-interval和dfs.heartbeat.interval 参数的作用: #设置HDFS中NameNode和DataNode的超时时间,计算公式为:timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。 --> [root@node101.yinzhengjie.org.cn ~]#
七.DataNode的目录结构
和NameNode不同的是,DataNode的存储目录是初始阶段自动创建的,不需要额外格式化。
1>.查看DataNode目录下对应的版本号("${hadoop.tmp.dir}/dfs/data/current/VERSION")
[root@node101.yinzhengjie.org.cn ~]# ll /data/hadoop/hdfs/dfs/data/current/ total 8 drwx------. 4 root root 4096 Apr 12 18:44 BP-883662044-172.30.1.101-1555064443805 -rw-r--r--. 1 root root 229 Apr 12 18:44 VERSION [root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/VERSION #Fri Apr 12 18:44:23 CST 2019 storageID=DS-e181274d-eace-44c1-b001-ac26fbfa3f8c #存储id号 clusterID=CID-e7603940-eaba-4ce6-9ecd-3a449027b432 #集群id,全局唯一 cTime=0 #标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,改值会更新到新的时间戳。 datanodeUuid=a7c28347-2816-47ee-a3f9-153d11e162bf #datanode的唯一标识码 storageType=DATA_NODE #存储类型 layoutVersion=-57 #一般情况下是一个负数,通常只有HDFS增加新特性时才会更新这个版本号。 [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/VERSION #Fri Apr 12 18:44:23 CST 2019 storageID=DS-e181274d-eace-44c1-b001-ac26fbfa3f8c clusterID=CID-e7603940-eaba-4ce6-9ecd-3a449027b432 cTime=0 datanodeUuid=a7c28347-2816-47ee-a3f9-153d11e162bf storageType=DATA_NODE layoutVersion=-57 [root@node102.yinzhengjie.org.cn ~]#
[root@node103.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/VERSION #Fri Apr 12 18:44:23 CST 2019 storageID=DS-e181274d-eace-44c1-b001-ac26fbfa3f8c clusterID=CID-e7603940-eaba-4ce6-9ecd-3a449027b432 cTime=0 datanodeUuid=a7c28347-2816-47ee-a3f9-153d11e162bf storageType=DATA_NODE layoutVersion=-57 [root@node103.yinzhengjie.org.cn ~]#
2>.查看DataNode目录下对应数据块的版本号("${hadoop.tmp.dir}/dfs/data/current/BP-*/current/VERSION")
[root@node101.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/BP-883662044-172.30.1.101-1555064443805/current/VERSION #Fri Apr 12 18:44:23 CST 2019 namespaceID=1161472027 #是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可以用这个属性来区分不同datanode。 cTime=1555064443805 #标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。 blockpoolID=BP-883662044-172.30.1.101-1555064443805 #标识一个block pool,并且是跨集群的全局唯一。当一个新的NameSpace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID,在创建过程构建全局唯一的BlockPoolID此人为的配置更可靠一些。NameNode将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。 layoutVersion=-57 #改值是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。 [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/BP-883662044-172.30.1.101-1555064443805/current/VERSION #Fri Apr 12 18:44:23 CST 2019 namespaceID=1161472027 cTime=1555064443805 blockpoolID=BP-883662044-172.30.1.101-1555064443805 layoutVersion=-57 [root@node102.yinzhengjie.org.cn ~]# [root@node102.yinzhengjie.org.cn ~]#
[root@node103.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data/current/BP-883662044-172.30.1.101-1555064443805/current/VERSION #Fri Apr 12 18:44:23 CST 2019 namespaceID=1161472027 cTime=1555064443805 blockpoolID=BP-883662044-172.30.1.101-1555064443805 layoutVersion=-57 [root@node103.yinzhengjie.org.cn ~]#
八.DataNode多目录配置(我们在主节点做了任何修改后,最好同步到整个集群中去,否则可能会导致部分节点启动失败!)
DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本!切记,DataNode的多目录配置和NameNode的多目录配置效果是不一样的! NameNode配置多目录是为了把元数据存储多份,达到配置备份的目的。
关于已经有数据的HDFS集群中,配置案例如下:
[root@node101.yinzhengjie.org.cn ~]# cat /yinzhengjie/softwares/hadoop-2.9.2/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node101.yinzhengjie.org.cn:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/hdfs</value> </property> </configuration> <!-- core-site.xml配置文件的作用: 用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录以及用于rack-aware集群中的配置文件的配置等,此中的参数定义会覆盖core-default.xml文件中的默认配置。 fs.defaultFS 参数的作用: #声明namenode的地址,相当于声明hdfs文件系统。 hadoop.tmp.dir 参数的作用: #声明hadoop工作目录的地址。 --> [root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cat /yinzhengjie/softwares/hadoop-2.9.2/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/namenode1,file:///${hadoop.tmp.dir}/dfs/namenode2,file:///${hadoop.tmp.dir}/dfs/namenode3</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> </configuration> <!-- hdfs-site.xml 配置文件的作用: #HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.namenode.checkpoint.period 参数的作用: #两个定期检查点之间的秒数,默认是3600,即1小时。 dfs.namenode.name.dir 参数的作用: #指定namenode的工作目录,默认是file://${hadoop.tmp.dir}/dfs/name,namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。建议配置的多目录用不同磁盘挂在,这样可以提升IO性能! dfs.datanode.data.dir 参数的作用: #指定datanode的工作目录,议配置的多目录用不同磁盘挂在,这样可以提升IO性能!但是多个目录存储的数据并不相同哟!而是把数据存放在不同的目录,当namenode存储数据时效率更高! dfs.replication 参数的作用: #为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用 保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个软件级备份。 dfs.heartbeat.interval 参数的作用: #设置心跳检测时间 dfs.namenode.heartbeat.recheck-interval和dfs.heartbeat.interval 参数的作用: #设置HDFS中NameNode和DataNode的超时时间,计算公式为:timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。 --> [root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# scp -r /yinzhengjie/softwares/hadoop-2.9.2/ node102.yinzhengjie.org.cn:/yinzhengjie/softwares/
[root@node101.yinzhengjie.org.cn ~]# scp -r /yinzhengjie/softwares/hadoop-2.9.2/ node103.yinzhengjie.org.cn:/yinzhengjie/softwares/
[root@node101.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data1/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-a29dd65a-de0e-44b1-b51b-5d537f0ab7f1 clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=d1d3a605-0218-42b9-9638-255343195296 storageType=DATA_NODE layoutVersion=-57 [root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data2/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-9f2fa0b3-e9d7-4743-a9e8-ff2d81370200 clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=d1d3a605-0218-42b9-9638-255343195296 storageType=DATA_NODE layoutVersion=-57 [root@node101.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data1/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-053dada1-36dd-490b-a1d5-1a523bcfc6f3 clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=b43206d7-eb51-48b5-b269-6bd6502b5f9f storageType=DATA_NODE layoutVersion=-57 [root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data2/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-28a3e682-3ae8-4ce2-abf5-6691b669ef1a clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=b43206d7-eb51-48b5-b269-6bd6502b5f9f storageType=DATA_NODE layoutVersion=-57 [root@node102.yinzhengjie.org.cn ~]#
[root@node103.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data1/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-e55b7230-fc9b-4122-a19d-30cb5855d455 clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=ed3bea6a-f5cd-45e9-8302-6de2106ec863 storageType=DATA_NODE layoutVersion=-57 [root@node103.yinzhengjie.org.cn ~]#
[root@node103.yinzhengjie.org.cn ~]# cat /data/hadoop/hdfs/dfs/data2/current/VERSION #Mon Apr 15 15:47:43 CST 2019 storageID=DS-3d59f0c6-ebbf-4f3d-b470-256c01a200d4 clusterID=CID-377f58b3-a3a2-4ca7-bf72-7d47714cf9cd cTime=0 datanodeUuid=ed3bea6a-f5cd-45e9-8302-6de2106ec863 storageType=DATA_NODE layoutVersion=-57 [root@node103.yinzhengjie.org.cn ~]#
九.Hadoop的集群管理之服役和退役
详情请参考:Hadoop的集群管理之服役和退役 。