批处理引擎MapReduce内部原理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.MapReduce作业生命周期
MapReduce作业作为一种分布式应用程序,可直接运行在Hadoop资源管理系统YARN之上(MapReduce On YARN)。如下图所示,每个MapReduce应用程序由一个MRAppMaster以及一系列MapTask和ReduceTask构成,它们通过ResourceManager获得资源,并由NodeManager启动运行。

当用户向YARN中提交一个MapReduce应用程序后,YARN将分为两个阶段运行该应用程序:第一个阶段是由ResourceManager启动MRAppMaster;第二个阶段是由MRAppMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行成功。如下图所示,YRAN的工作流程分为以下几个步骤: (1)用户向YARN集群提交应用程序,该应用程序包括以下配置信息:MRAppMaster所在的jar包,启动MRAppMaster的命令及其资源要求(CPU,内存等),用户配置jar包等。 (2)ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的MRAppMaster。 (3)MRAppMaster启动后,首先向ResourceManager注册(告之所在节点,端口号以及访问链接等),这样,用户可以直接通过ResourceManager查看应用程序的运行状态,直到所有任务运行结束,即重复步骤4~7。 (4)MRAppMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。 (5)一旦MRAppMaster申请到(部分)资源后,则通过一定的调度算法将资源分配给内部的任务,之后与对应的NodeManager通信,要求它启动这些任务。 (6)NodeManager为任务准备运行环境(包括环境变量,jar包,二进制程序等),并将任务执行命令写到一个shell脚本中,并通过运行该脚本启动任务。 (7)启动的Map Task或Reduce Task通过RPC协议向MRAppMaster汇报自己状态和进度,以让MRAppMaster随时掌握各种任务的运行状态,从而可以在任务失败时触发相应的容错机制。(在应用程序运行过程中,用户可随时通过RPC向MRAppMaster查询应用程序的当前运行状态) (8)应用程序运行完成后,MRAppMaster通过RPC向ResourceManager注销,并关闭自己。

ResourceManager,NodeManager,MRAppMaster以及MapTask/ReduceTask管理关系如下图所示。
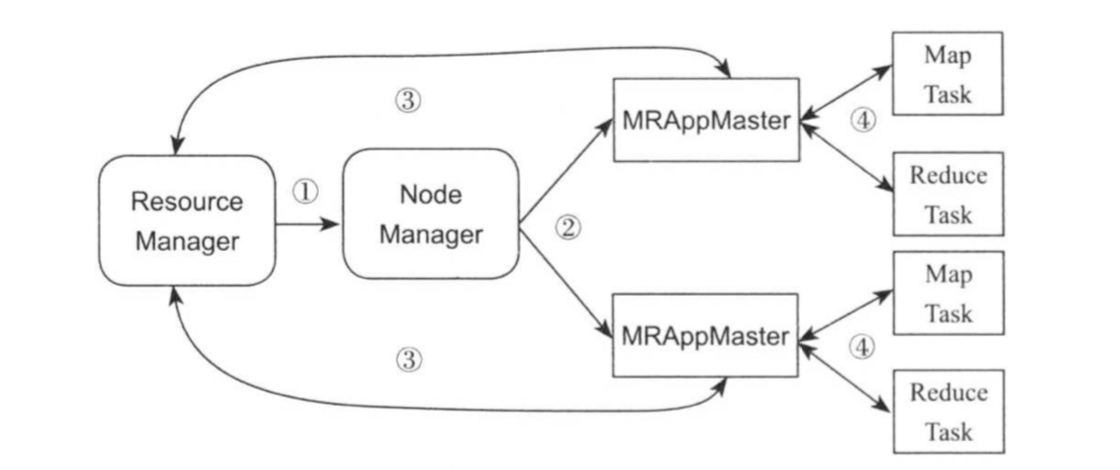
ResourceManager为MRAppMaster分配资源,并告之NodeManager启动它,MRAppMaster启动后,会通过心跳信息与ResourceManager之间的联系;MRAppMaster负责为Map Task/Reduce Task申请资源,并通知ResourceManager启动它们,Map Task/Reduce Task启动后,会通过心跳维持与MRAppMaster之间的关系,基于以上设计机制,接下来介绍一下MapReduce On YARN架构的容错性。
(1)YARN
YARN本身具有高度容错性,具体容错机制的实现,可参考为后期分析的关于YARN的笔记。
(2)MRAppMaster
MRAppMaster由ResourceManager管理,一旦MRAppMaster因故障挂掉,ResourceManager会重新为他分配资源,并启动之。重启后的MRAppMaster需借助上次运行时记录的信息恢复状态,包括未运行,正在运行和已运行完成的任务。
(3)MapTask/ReduceTask
任务由MRAppMaster管理,一旦MapTask/ReduceTask因故障挂掉或因程序bug阻塞住,MRAppMaster会为之重新申请资源并启动之。
二.Map Task与Reduce Task
为了帮助读者深入了解Map Task和Reduce Task内部实现原理,我们将Map Task分解成Read,Map,Collect,Spill和Combine五个阶段,将Reduce Task分解成Shuffle,Merge,Sort,Reduce和Write五个阶段。 在MapReduce计算框架中,一个应用程序被划分成Map和Reduce两个计算阶段,它们分别由一个或者多个Map Task和Reduce Task组成。其中,每个Map Task处理输入数据集合中的一片数据(split),产生若干数据片段,经分组聚集和归约后,将结果写到HDFS中,整个过程如下图所示。
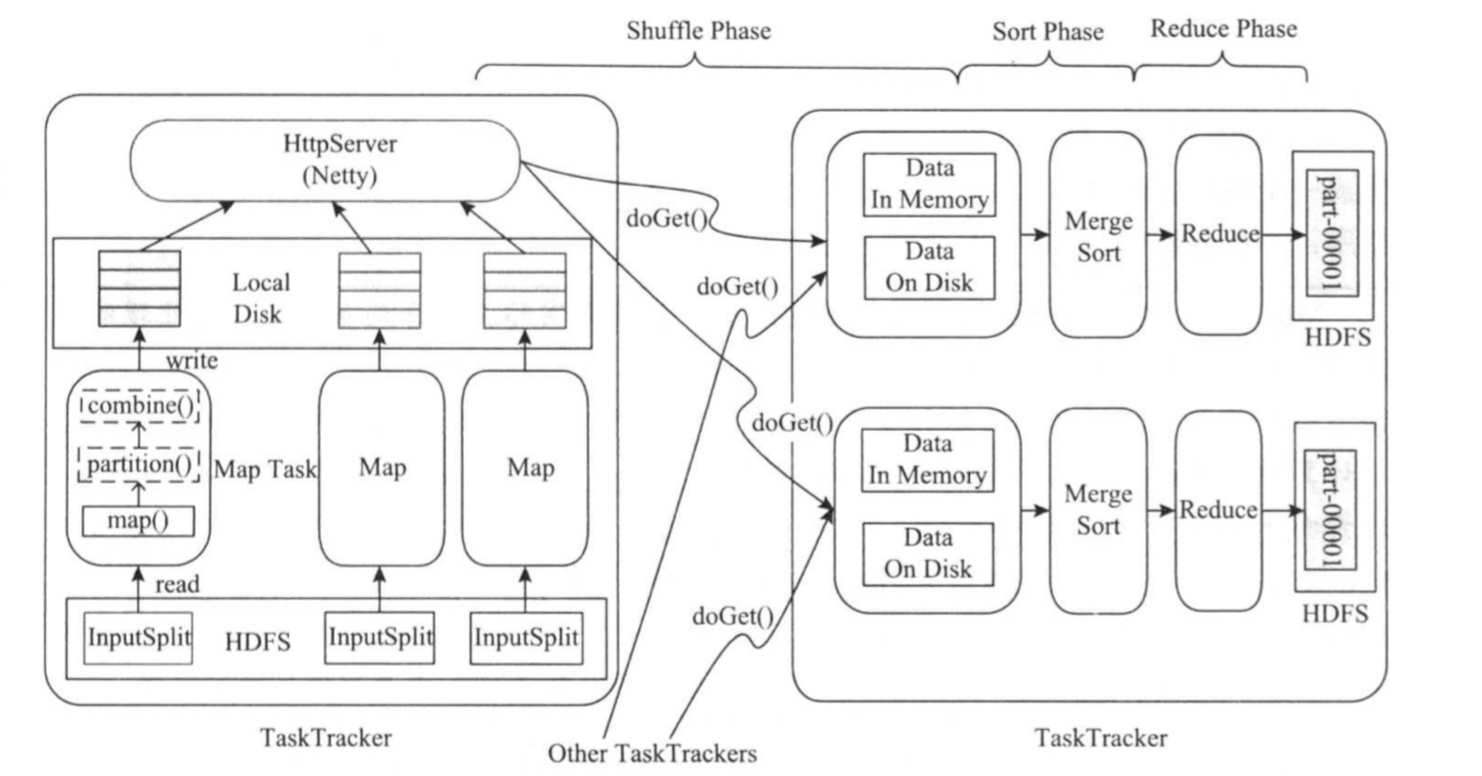
总体上看,Map Task越Reduce Task之间的数据传输采用了pull模型。为了提高容错性,Map Task端将中间计算结果存放到本地磁盘上,而Reduce Task则通过HTTP协议从各个Map Task端拉取(pull)相应的待处理数据。为了更好地支持大量Reduce Task并发从Map Task端拷贝数据,Hadoop采用了Netty(https://netty.io/)作为高性能网络传输服务。
对于Map Task而言,他的执行过程可概述为:首先,通过用户提供的InputFormat将对应的split解析成一系列<key,value>,并依次交给用户编写的map()函数处理;接着按照指定的Partitioner对数据分片,以确定每对<key,value>交给哪个Reduce Task处理;之后将数据交给用户定义的Combiner进行依次本地归约(用户没有定义则直接跳过);最后将处理结果保存在本地磁盘上。
对于Reduce Task而言,由于它的输入数据来自各个Map Task,因此首先通过HTTP从各个已经运行完成的Map Task上拷贝对应的数据分片;待数据拷贝完成后,在以key为关键字对所有数据进行排序,通过排序(注意,这个排序并不是对所有数据进行重新排序哟,而是针对key进行排序),key相同的记录会被聚集到一起形成分组;然后将每组数据依次交给用户编写的reduce()函数处理,并把处理结果直接写到HDFS上。
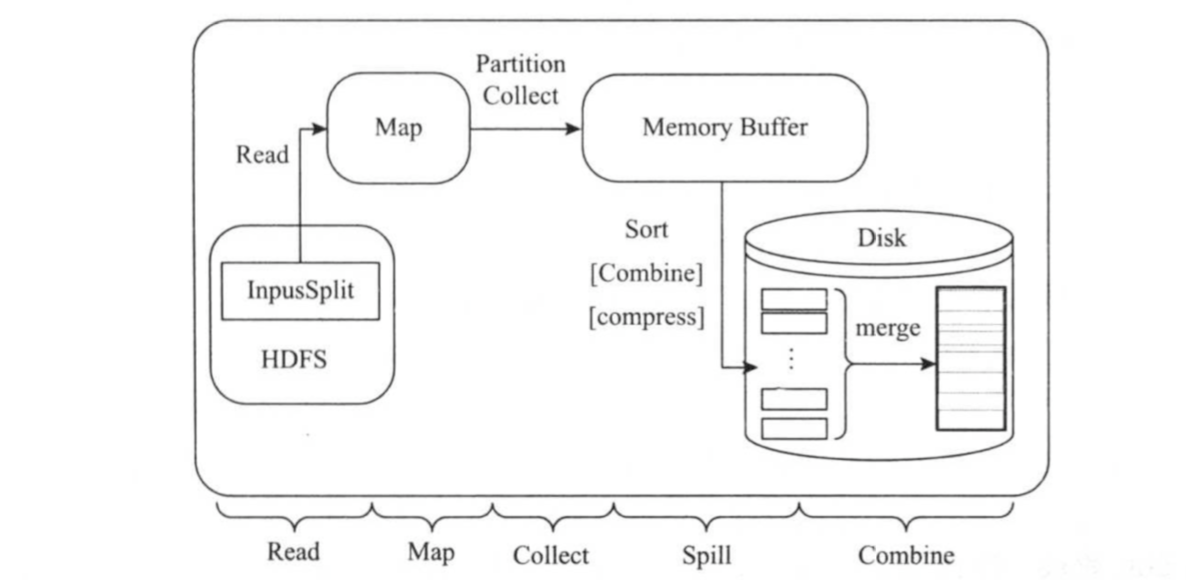
1>.Map Task详细流程
Map Task的整体计算流程如下图所示。共分为5个阶段,分别是: (1)Read阶段 Map Task通过InputFormat,从split中解析出一系列<key,value>。 (2)Map阶段 将解析出的<key,value>依次交给用户编写的map()函数处理,并产生一系列新的<key,value>。 (3)Collect阶段 在map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果,该函数内部,它将<key,value>划分成若干个数据分片(通过调用Partitioner),并写入一个环形内存缓冲区中。 (4)Spill阶段 即“溢写”,当环形缓冲区满后,MapReduce将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行依次本地排序,并在必要时对数据进行合并,压缩等操作。 (5)Combine阶段
当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。


该问题实际上包含两层含义,即处理结果为何不写入内存,或者直接发送给Reduce Task? (1)首先,Map Task不能够将数据写入内存,因为一个集群中可能会同时运行多个作业,且每个作业可能分成多批运行Map Task,显然,将计算结果直接写入内存会耗光机器的内存; (2)其次,MapReduce采用的是动态调度策略,这意味着,一开始只有Map Task执行,而Reduce Task处于未调度状态,因此无法将Map Task计算结果直接发送给Reduce Task。 (3)将Map Task写入本地磁盘,使得Reduce Task执行失败时可直接从磁盘上再次读取各个Map Task的结果,而无需让所有Map Task重新执行。 总之,Map Task将处理结果写入本地磁盘主要目的是减少内存存储压力和容错。
如果每个Map Task产生多个数据文件(比如每个Map Task为每个Reduce Task产生一个文件),则会生成大量中间小文件,这将大大降低文件读取性能,并严重影响系统扩展性(M个Map Task和R个Reduce Task 可能产生M*R个小文件)。
2>.Reduce Task详细流程
Reduce Task的整体计算流程如下图所示,共分为五个阶段,分别是: (1)Shuffle阶段 也称为Copy阶段,Reduce Task从各个Map Task上远程拷贝一片数据,并根据数据分片大小采取不同操作,如果其大小超过一定阈值(默认是100M,如果想要调大可以修改mapreduce.task.io.sort.mb),则写到磁盘上,否则直接放在内存中。 (2)Merge阶段 在远程拷贝数据的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用量过多或磁盘上文件数过多。 (3)Sort阶段 按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key想同的数据聚在一起,Hadoop采用了基于排序的策略,由于各个Map Task已经实现对自己的处理结果进行局部排序,因此Reduce Task只需对所有数据进行一次归并排序即可。
(4)Reduce阶段 在该阶段中,Reduce Task将每组数据一次交给用户编写的reduce()函数处理。 (5)Write阶段
将reduce()函数输出的结果写到HDFS上。

三.MapReduce关键技术
MapReduce在实现过程中用到了很多分布式优化技术,我们重点介绍数据本地性和推测执行两种技术。
1>.数据本地性(Data Locality)
MRAppMaster从ResourceManager申请到(部分)资源后,会通过一定的调度算法将资源进一步分配给内部的任务。对于Map Task而言,一个重要的调度策略是数据本地性,即MRAppMaster会尽量将Map Task调度到它所处理的数据节点。
在分布式环境中,为了减少任务执行过程中的网络传输开销,通常将任务调度到输入数据所在计算节点,也就是让数据在本地进行计算,而MapReduce正是以“尽力而为”的策略保证数据本地性的。
为了实现数据本地性,MapReduce需要管理员提供集群的网络拓扑结构。如下图所示,Hadoop集群采用了三层网络拓扑结构,其中,根节点表示整个集群,第一层代表数据中心,第二层代表机架或者交换机,第三层代表实际用于计算和存储的物理节点。对于目前的Hadoop各个发行版本而言,默认均采用了二层网络拓扑图结构,即数据中心一层暂时未被考虑。
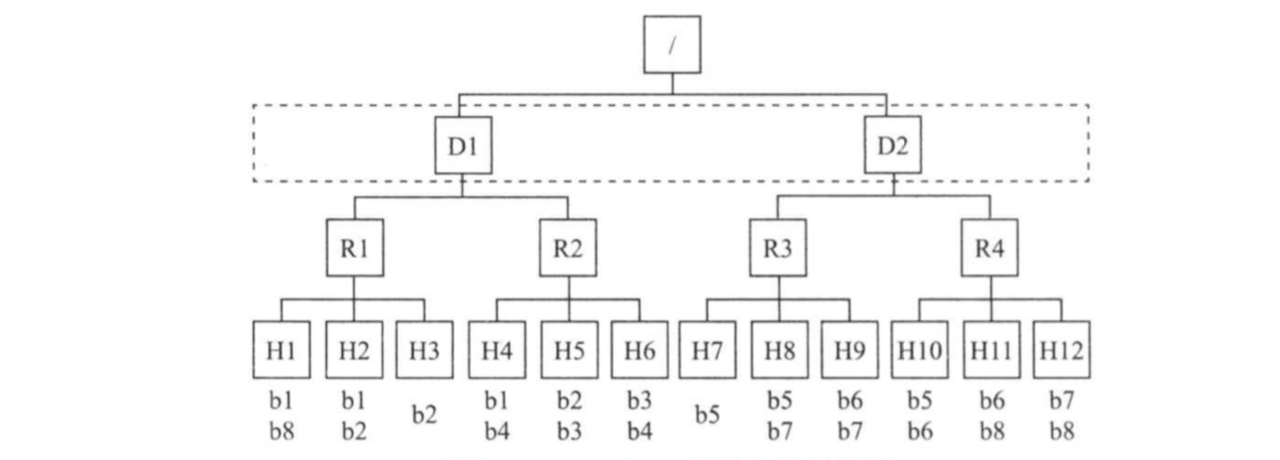
MapReduce根据输入数据与实际分配的计算资源之间的距离将任务分成三类:node-local,rack-local和off-switch,分别表示输入数据与计算资源同节点,同机架和跨机架,当输入数据与计算资源位于不同节点上是,MapReduce需将输入数据远程拷贝到计算资源所在的节点进行处理,两者距离越远,需要的网络开销越大,因此调度器进行任务分配时尽量选择离输入数据近的节点资源。 当MapReduce进行任务选择时,采用自底向上查找的策略。由于当前采用了两层网络拓扑结构,因此这种选择决定了任务优先级从高到底依次为:node-local,rack-local和off-switch,下面结合上图介绍的三种类型的任务被选中的场景: (1)场景一: 如果X是节点H1,任务Y输入数据块为b1,则该任务的数据本地性级别为node-local。 (2)场景二: 如果X是节点H1,任务Y输入的数据块为b2,则该任务的数据本地行界别为rack-local。 (3)场景三:
如果X是节点H1,任务Y输入的数据块为b4,则该任务的数据本地行界别为off-switch。
MRAppMaster会尽可能让任务运行在输入数据块所在的节点上,其次是输入数据块同机架的节点上,最后考虑其他机架上的节点。为了提高任务的数据本性级别,MapReduce采用了延迟掉的策略,即如果等待一段时间后,还未出现满足node-local要求的资源,则考虑满足rack-local需求的资源,如果等待一段时间后,还未出现满足rack-local需求的资源,则将任务随意调度到有空闲节点的资源上。
2>.推测执行(Speculative Execution)
在分布式集群环境下,因为程序Bug,负载不均衡或者资源不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行速度。为了避免这种情况发生,MapReduce采用推测执行机制,它根据一定的法则推测“拖后退”的任务,并为这样的任务启动一个备份任务,该任务与原始任务同时运行,最终选用最先成功运行完成任务的计算结果作为最终结果。