资源管理与调度系统-YARN的基本架构与原理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
为了能够对集群中的资源进行统一管理和调度,Hadoop2.0引入了数据操作系统YARN。YARN的引入大大提高了集群的资源利用率,并降低了集群管理成本。
首先,YARN能够将资源按需分配给各个应用程序,这大大提高了资源利用率,其次,YARN允许各类短作业和长服务混合部署在一个集群中。并提供了容错,资源隔离及负载均衡等方面的支持,这大大简化了作业和服务的部署和管理成本。
一.YARN产生背景
由于MRv1(MapReduce version 1)在扩展性,可靠性,资源利用率和多框架等方面存在明显不足,Apache开始尝试对MapReduce进行升级改造,进而诞生了更加先进的下一代MapReduce计算框架MRv2(MapReduce version 2)。 由于MRv2将资源管理模块构建成了一个独立的通用系统YARN,这直接使得MRv2的核心从计算框架MapReduce转移为资产管理系统YARN。
相关文章可参考:https://issues.apache.org/jira/browse/MAPREDUCE-279。
1>.MRv1局限性
YARN是在MRv1基础上演化而来的,它克服了MRv1架构中的各种局限性。在正式介绍YARN之前,我们先了解MRv1的一些局限性,这可概括为以下几个方面:
(1)可靠性差
MRv1采用了master/slave结构,其中,master存在单点故障问题,一旦它出现故障将导致整个集群不可用。
(2)扩展性差
在MRv1中,JobTracker(master)同时兼备了资源管理和作业控制两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群扩展性。
(3)资源利用概率底
MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个任务不会用完槽位对应的资源,且其他任务也无法使用这些的空闲资源。此外,Hadoop将槽位分为Map Slot和Reduce Slot两种,且不允许它们之间共享,常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时,只会运行Map Task,此时Reduce Slot闲置)
(4)无法支持多种计算框架
随着互联网高速发展,MapReduce这种基于磁盘的离线计算框架已经不能满足应用需求,从而出现了一些新的计算框架,包括内存计算框架,流式计算框架和迭代式计算框架等,而MRv1不能支持多种计算框架并存。
为了克服以上几个缺点,Apache开始尝试对Hadoop进行升级改造,进而诞生了更加先进的下一代MapReduce计算框架MRv2。正式由于MRv2将资源管理功能抽象成了一个独立的通用系统YARN,直接导致下一代MapReduce的核心从单一的计算框架MapReduce转移为通用的资源管理系统YARN。为了让读者更进一步理解以YARN为核心的软件栈,我们将之与MapReduce为核心的软件栈进行对比。
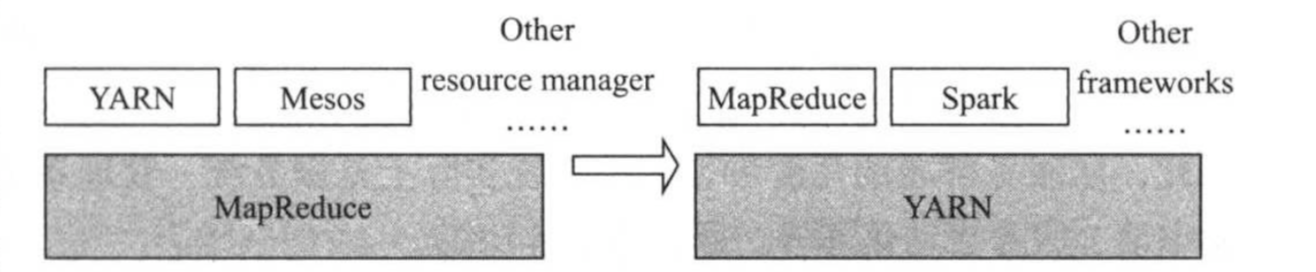
如下图所示,在以MapReduce为核心的协议栈中,资源管理系统YARN是可插拔替换的,比如选择Mesos替换YARN,一旦MapReduce接口改变,所有的资源管理系统的实现均需要跟着改变;但以YARN为核心的协议栈则不同,所有框架都需要实现YARN定义的对外接口以运行在YARN之上,这意味着Hadoop2.0可以打造一个以YARN为核心的生态系统。
2>. YARN设计动机
YARN作为一个通用的资源管理系统,其目标是将短作业和长服务混合部署到一个集群中,并为它们提供统一的资源管理和调度功能。YARN是大数据系统发展到一定阶段的必然之物,除了YARN之外,目前市场上存在很多其他资源管理系统,典型的代表有Google的Borg与Omega和Kubernetes,Twitter的Mesos和腾讯的Torca。概括起来,这类系统的动机是解决两类问题:提高集群资源利用率和服务自动化部署。 Brog: Google的Borg系统是一个集群管理器,可以运行数千个不同的应用程序中的数十万个作业,这些作业分布在多个集群中,每个集群最多有数万台计算机。2015年出版, 博主推荐阅读一:https://ai.google/research/pubs/pub43438。 博主推荐阅读二:https://www.infoq.com/news/2015/04/google-borg Omega: Omega,作为Borg的延伸,它的出现是出于提升Borg生态系统软件工程的愿望。Omega应用到了很多在Borg内已经被认证的成功的模式,但是是从头开始来搭建以期更为一致的构架。Omega存储了基于Paxos、围绕transaction的集群的状态,能够被集群的控制面板(比如调度器)接触到,使用了优化的进程控制来解决偶尔发生的冲突。这种分离允许Borgmaster的功能被区分成几个并列的组建,而不是把所有变化都放到一个单独的、巨石型的master里。许多Omega的创新(包括多个调度器)都被收录进了Borg. 博主推荐阅读:https://www.douban.com/note/547709628/?type=rec。 Kubernetes: 谷歌研发的第三个容器管理系统是Kubernetes。Kubernetes的研发和认知背景,是针对在谷歌外部的对Linux容器感兴趣的开发者以及谷歌在公有云底层商业增长的考虑。和Borg、Omega完全是谷歌内部系统相比,Kubernetes是开源的。 像Omega一样,Kubernetes在其核心有一个被分享的持久存储,有组件来检测相关ojbect的变化。跟Omega不同的是,Omega把存储直接暴露给信任的控制面板的组件,而在Kubernete中,是要完全由domain-specific的提供更高一层的版本控制认证、语义、政策的REST API来接触,以服务更多的用户。更重要的是,Kubernetes是由一支在集群层面应用开发能力更强的开发者开发的,他们主要的设计目标是用更容易的方法去部署和管理复杂的分布式系统,同时仍然能通过容器所提升的使用效率来受益。 博主推荐阅读:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/。 Mesos: Mesos使用与Linux内核相同的原理构建,仅在不同的抽象级别上构建。Mesos内核在每台机器上运行,并为API提供应用程序(例如,Hadoop,Spark,Kafka,Elasticsearch),用于整个数据中心和云环境的资源管理和调度。 博主推荐阅读:http://mesos.apache.org/ Torca: torca作为腾讯Typython云平台的资源调度子系统,已经在网页搜索,广告方面广泛应用。Torca属于Monolithic架构,一个Torca集群由一个Central Manager和若干Execute Server组成。Central Manager是集群任务调度中心,Execute Server接收任务并负责相应执行。 博主推荐阅读:http://www.360doc.com/content/17/0112/09/39325967_621918175.shtml。
1>.提高集群资源利用率
在大数据时代,为了存储和处理海量数据,需要规模较大的服务器集群或者数据中心,一般来说,这些集群上运行着众多类型负载的应用程序和服务,比如离线作业,流式作业,迭代式作业,Crawler Server,Web Server等,传统的做法是,每种类型的作业或者服务对应一个单独的集群,以避免互相干扰。这样,集群被分割成数量众多的小集群:Hadoop集群,HBase集群,Storm集群,Web Server集群等。
然而,由于不同类型的作业服务需要的资源量不同,因此,这些较小集群的利用率通常很不均衡,有的集群满负荷,资源紧张,而另外一些则长时间闲置,资源利用率极低,而由于这些集群之间资源无法共享,因此造就了不同时间段不同集群资源利用率不同。
为了提高资源整体利用率,一种解决方案是将这些小集群合并成一个大集群,让它们共享这个大集群的资源,并由一个资源统一调度系统进行资源管理和分配,这就诞生了类似与YARN的系统。从集群共享角度看,这类系统实际上将公司的所有硬件资源抽象一台大型计算机,供所有用户使用。
2>.服务自动化部署
一旦将所有服务计算资源抽象成一个“大型计算机”后,就会产生一个问题:公司的各种服务如何进行部署?Brog/YARN/Mesos/Torca这类系统需要具备服务自动化部署的功能,因此,从服务部署的角度看,这类系统实际上是服务统一管理系统,这类系统提供服务资源申请,服务自动化部署,服务容错等功能。
二.YARN设计思想
在Hadoop 1.0中,JobTracker由资源管理(TaskScheduler模块实现)和作业控制两部分组成,具体如下图所示:
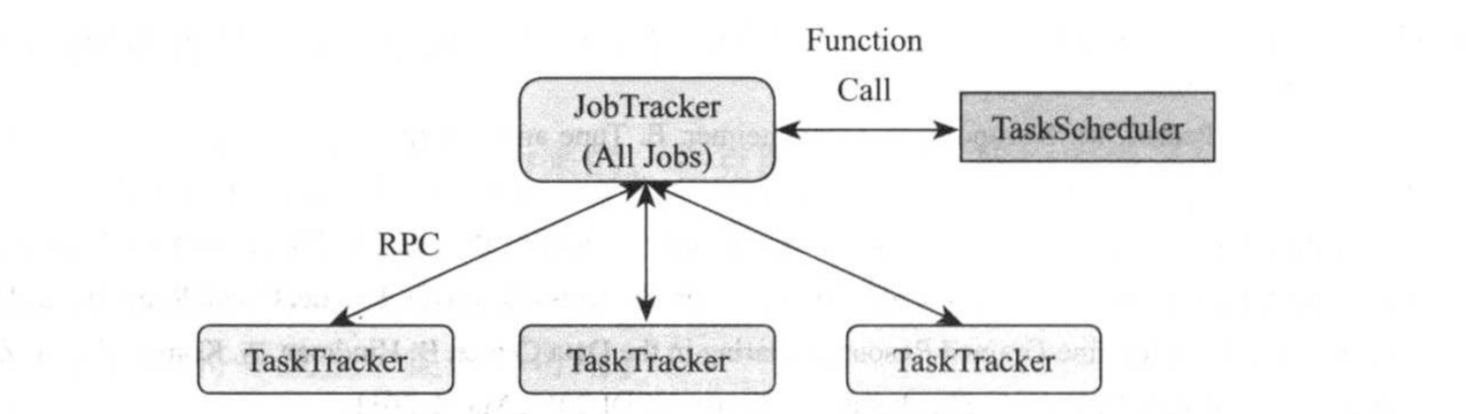
第一代Hadoop MapReduce之所以在可扩展性,资源利用率和多框架支持等方面存在不足,正式由于第一代Hadoop对JobTracker赋予的功能过多而造成负载过重,此外,从设计角度上看,第一代Hadoop未能够将资源管理相关的功能和应用程序相关的功能分开,造成第一代Hadoop难以支持多种计算框架。
下一代MapReduce框架的基本设计思想是将JobTracker的两个主要功能,及资源管理和作业控制(包括作业监控,容错等),分拆成两个独立的进程,如下图所示:
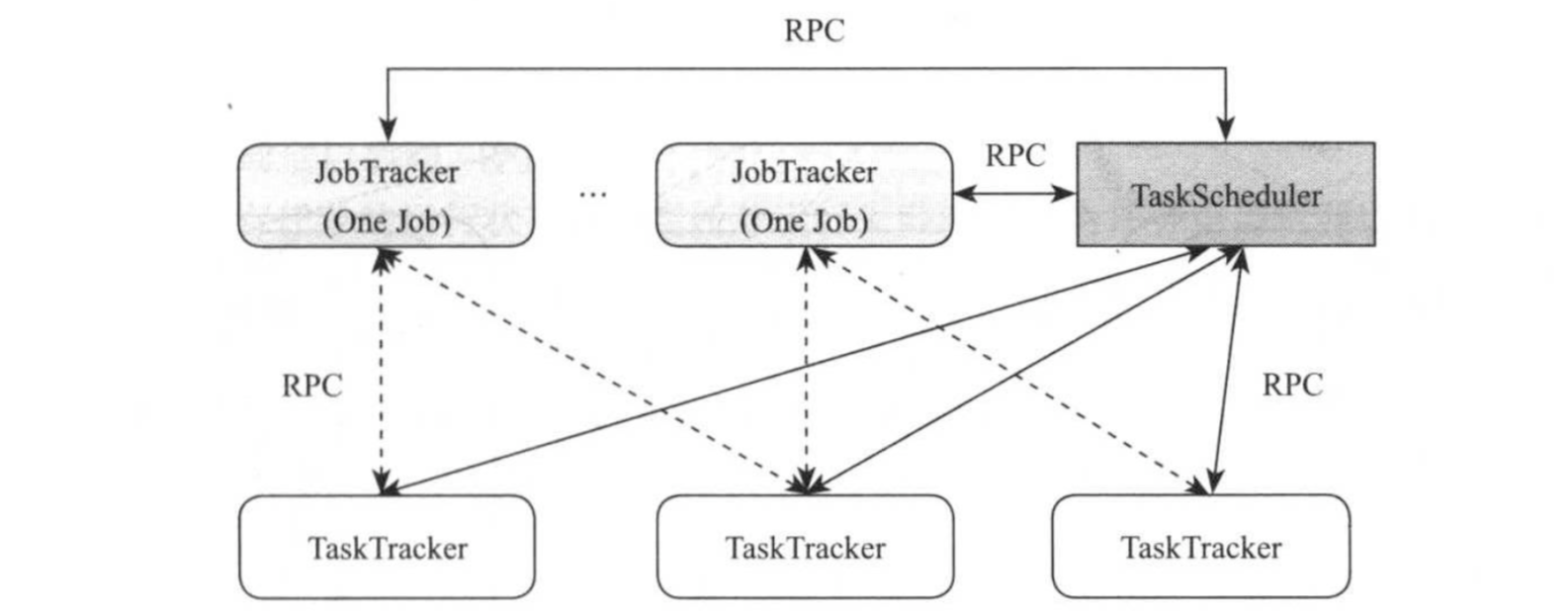
资源管理进程与具体应用程序无关,它负责整个集群的资源管理(内存,CPU,磁盘等),而作业控制进程则是直接与应用程序相关的模块,且每个作业控制进程只负责管理一个作业(这说明每个作业控制进程的信息是不共享的,因此它们很可能将作业放在同一台物理机器上执行导致某台机器负载过大)。
这样,通过原有JobTracker中与应用程序相关和无关的模块分开,不仅减轻了JobTracker的负载,也使得Hadoop支持更多的计算框架。
从资源管理的角度看,下一代MapReduce框架衍生出了一个资源统一管理平台,它使得Hadoop不再局限与仅支持MapReduce一种计算模型,而是可无限融入多种计算框架,并且对这些框架进行统一管理和调度。
三.YARN的基本架构
YARN总体上采用master/slave架构,其中,ResourceManager为master,NodeManager为slave,ResourceManager负责对各个NodeManager上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,他负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务,由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会互相影响。
下图描述了YARN的基本组成结构,YARN主要由ResourceManager,NodeManager,ApplicationMaster(图中给出了MapReduce和MPI两种计算框架的ApplicationMaster,分别为MR AppMstr和MPI AppMstr)和Container等几个组件构成。
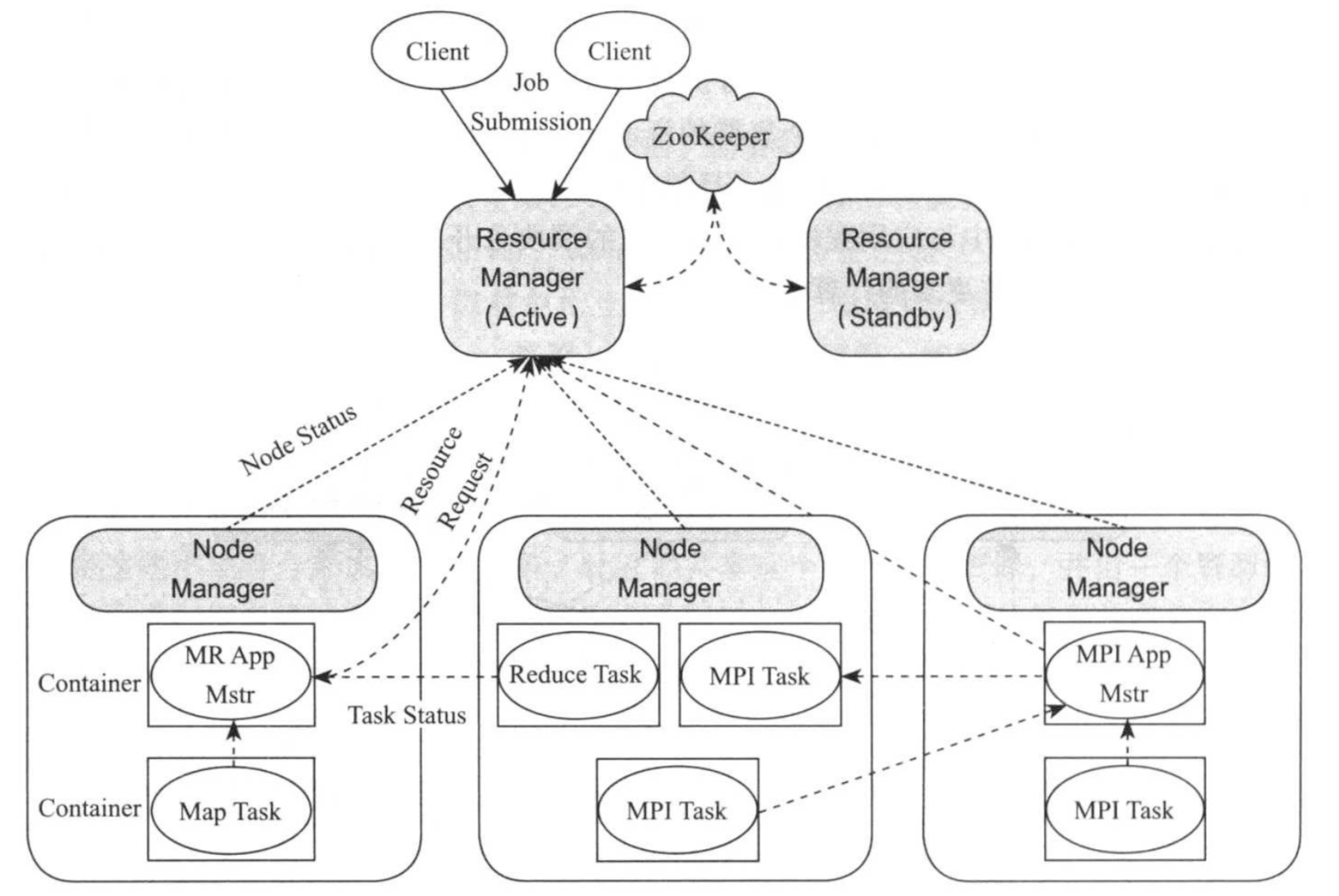
1>.ResourceManager(简称RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。他主要由两个组件构成:调度器(Scheduler)和应用管理器(Applications Manager,简称ASM)。 (1)调度器(Scheduler) 调度器主要功能是根据资源容量,队列等方面的限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个应用程序。
YARN中的调度器是一个“纯调度器”,他不在从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。
调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,他将内存,CPU,磁盘,网络等资源封装在一起,从而限定每个任务使用的资源量。
在YARN中,资源调度器是一个可插拔的组件,用户根据自己的需求设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler。 (2)应用管理器(Applications Manager,简称ASM)
应用程序管理器负责整个系统中的所有应用程序,包括应用程序提交,与调度器协商资源以启动ApplicationMaster,监控ApplicationMaster运行状态并在失败时重新启动他等。
为了避免单个ResourceManager出现单点故障导致整个集群不可用,YARN引入贮备ResourceManager实现HA,当Active ResourceManager出现故障时,Standby ResourceManager会通过zookeeper选举,自动提升为Active ResourceManager。
2>.ApplicationMaster(简称AM)
用户提交的每个应用程序均包含一个独立的AM,其主要功能包括: (1)与RM调度器协商以获取资源(用Container表示)。 (2)将得到的资源进一步分配给内部的任务。 (3)与NM通信已启动/停止任务。 (4)监控所有任务的运行状态,并在任务运行失败时重新为任务申请资源以重启任务。 当前YARN源代码中自带了两个AM实现,一个是用于演示AM编写方法的实例程序distributedshell,它可以申请一定数目的Container运行一个shell命令或shell脚本,另一个是运行MapReducer应用程序的AM,即MRAppMaster。很多开源的计算框架和服务为了能够运行在YARN上,也提供了自己的ApplicationMaster实现,包括Open MPI,Spark,HBase,Impala等。
3>.NodeManager(简称NM)
NM是每个节点上的资源管理器,一方面,它会定时的向RM汇报本节点上的资源使用情况和各个Container的运行状态,另一方面,它接受并处理来自AM的任务启动/停止等各种请求。在一个集群中,NodeManager通常存在多个,由于YARN内置了容错机制,单个NodeManager的故障不会对集群的应用程序运行产生严重影响。
4>.Container
Container是YARN中的基本资源分配单位,是对应用程序运行环境的抽象,并未应用程序提供资源隔离环境。它封装了多维度的资源,如内存,CPU,磁盘,网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。 YARN中每个任务均会对应一个Container,且该任务只能使用Container中描述的资源。 需要注意的是,Container不同于MRv1的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。Container最终是由ContainerExecutor启动和运行的,YARN提供了三种可选的ContainerExecutor: (1)DefaultContainerExecutor 默认ContainerExecutor实现,直接以进程方式启动Container,不提供任何隔离机制和安全机制,任何应用程序最终均是以YARN服务启动着的身份运行的。 (2)LinuxContainerExecutor 提供了安全的Cgroups隔离的ContainerExecutor,它以应用程序提交者的身份运行Container,且使用Cgroups为Container提供CPU和内存隔离的运行环境。 (3)DockerContainerExecutor
基于Docker实现的ContainerExecutor,可直接在YARN集群中运行Docker Container。Docker是基于Linux Container技术构建的非常轻量级的虚拟机,目前被广泛应用在服务器部署,自动化测试等场景中。
YARN内存隔离:https://issues.apache.org/jira/browse/YARN-3
Docker官网:https://www.docker.com/
四.YARN的高可用
YARN提供了恢复机制,这使得YARN在服务出现故障和人工重启时,不会对正在运行的应用程序产生任何影响。
我们将从ResourceManager HA,ResourceManager Recovery和NodeManager Recovery三个方面讨论YARN在高可用方面的设计。以下几种高可用机制的实现,使得YARN成为一个通用的资源管理系统,这使得在一个集群中混合部署短作业和长服务变得可能。
1>.ResourceManager HA
ResourceManager负责集群中资源的调度和应用程序的管理,是YARN最核心的组件。由于采用了master/slave架构,这使得ResourceManager成为单点故障。为了避免ResourceManager故障导致整个集群不可用,YARN引入了Active/Standby ResourceManager,通过冗余方式解决单点故障。
当Active ResourceManager出现故障时,Standby ResourceManager可通过Zookeeper选举成为Active ResourceManager,并通过ResourceManager Recovery机制恢复状态。
关于YARN的HA部署可参考为之前的笔记:https://www.cnblogs.com/yinzhengjie/p/10726455.html
2>.ResourceManager Recovery
RecourseManager内置了重启恢复功能,当ResourceManager就地重启,或发生Active/Standby切换是,不会影响正在运行的应用程序运行。ResourceManager Recovery主要流程如下: (1):保存元信息 Active ResourceManager运行过程中,会将应用程序的元数据,状态信息以及安全凭证等数据持久化到状态存储系统(state-store)中,YARN支持三种可选的state-store,分别是: 1)基于zookeeper的state-store: zookeeper是ResourceManager HA必选的state-store,尽管ResourceManager Restart可选其他的state-store,但只有zookeeper能防止脑裂(split-brain)现象,即同时存在多个Active ResourceManager状态信息的情况。 2)基于FileSystem的state-store: 支持HDFS和本地文件系统两种方式,但不能防止脑裂(split-brain) 3)基于LevelDB的state-store: 基于LevelDB的state-store比前两种方案更加轻量级。LevelDB能更好地支持原子操作,每次更新占用更少的IO资源,生成的文件数目更少。 LevelDB中文网:https://leveldb.org.cn/。 (2):加载元信息 一旦Active ResourceManager 重启或出现故障,新启动的ResourceManager将从存储系统中重新加载应用程序的相关数据,在此过程中,所有运行在各个NodeManager的Container仍然正常运行。 (3):重构状态信息 新的ResourceManager重启完成后,各个NodeManager会向它重新注册,并将所管理的Container回报给ResourceManager,这样ResourceManager可动态重构资源分配信息,各个应用程序以及其对应Container等关键数据;同时,ApplicationMaster会向ResourceManager重新发送资源请求,以便ResourceManager重新为其分配资源。
3>.NodeManager Recovery
NodeManager内置了重新恢复功能,当NodeManager就第重启时,之前正在运行的Contain不会被杀掉,而是有新的NodeManager接管,并继续正常运行。
五.YARN工作流程
运行在YARN上的应用程序主要分为两类:短作业和长服务,其中,短作业是值一定时间内(可能是秒级,分钟级或小时级,尽管天级别或者更长时间的也存在,但非常少)可运行完成并退出的应用程序,比如MapReduce作业,Spark作业等;长服务是值不出意外,用不终止运行的应用程序,通常是一些在线服务,比如Storm Service(主要包括Nimbus和Supervisor两类服务),HBase Service(包括Hmaster和RegionServer两类服务)等,而它们本身作为一个框架或服务提供了访问接口供用户使用。尽管这两类应用程序作用不同,一类直接运行数据处理程序,一类用于部署服务(在服务上再运行数据处理程序),但运行在YARN上的流程是想用的。
当用户向YARN中提交一些应用程序后,YARN将分为两个阶段运行该应用程序:第一个阶段是启动ApplicationMaster;第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行成功。如下图所示:
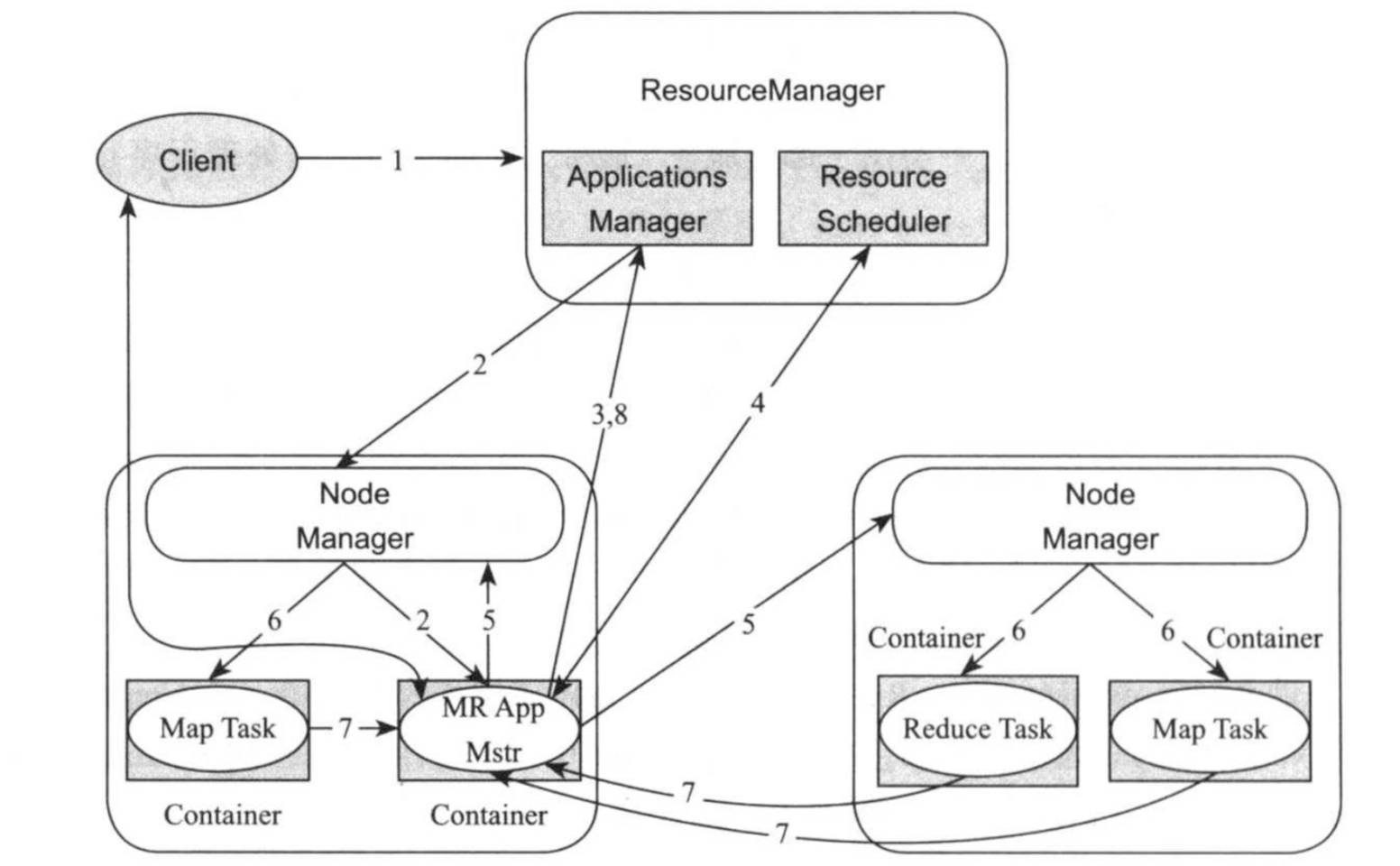
YARN的工作流程分为以下结果步骤: 1)提交应用程序 用户通过客户端与YARN ResourceManager通信以提交应用程序。应用程序中包括ApplicationMaster可之行代码,启动命令和资源需求,应用程序可执行代码和资源需求,优先级,提交到的队列等信息。 2)启动ApplicationMaster ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster,之后ApplicationMaster的生命周期直接被ResourceManager管理。 3)ApplicationMaster注册 ApplicationMaster启动后,首先,向ResourceManager注册,这样,用户可以直接通过ResourceManager查看应用程序的运行状态,然后,它将初始化应用程序,并按照一定的策略为内部申请资源,监控它们的运行状态,直到运行结束,即重复步骤4-7。 4)获取资源 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。 5)请求启动Container 一旦ApplicationMaster申请到资源后,则与对应的NodeManager通信,请求为其启动任务(NodeManager会将任务放到Container中) 6)启动Container NodeManager为任务设置好运行环境(包括环境变量,jar包,二进制程序等)后,将任务启动命令写到一个脚本中,并通过ContainerExecutor运行该脚本启动任务。
7)Container监控 ApplicationMaster可通过两种方式获取各个Container运行的状态以便在任务失败时重新启动任务: 方式一:ApplicationMaster与ResourceManager间维护了周期性心跳信息,每次通信可获取自己分管的Container的运行状态。 方式二:各个Container可通过某个RPC协议向ApplicationMaster汇报自己的状态和进度(视具体情况而定,比如MapReduce和YARN均实现了该方式)。 8)注销ApplicationMaster 应用程序运行完成后,ApplicationMaster向ResourceManager注销,并退出执行。
博主推荐阅读:“HBase ON YARN”(https://hortonworks.com/blog/hoya-hbase-on-yarn-application-architecture/)