资源管理与调度系统-YARN的资源调度器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
资源调度器是Hadoop YARN中最核心的组件之一,它是ResourceManager中的一个插拔式服务组件,负责整个集群资源的管理和分配。
Hadoop最初是为了批处理作业而设计的,当时(MRv1)仅提供了一种简单的FIFO(First In First Out)调度机制分配任务。但随着Hadoop的普及,单个Hadoop集群中的用户量和应用程序种类不断增加,适用于批处理场景的FIFO调度机制不能很好地利用集群资源,也难以满足不同应用程序的服务质量要求,因此,设计适用与多用户的资源调度器势在必行。
一.层级队列管理机制
在学习Capacity Scheduler和Fair Scheduler之前,我们先了解一下Hadoop的用户和资源管理机制,这是任何Hadoop可插拔资源调度器的基础。 在Hadoop 0.20.x版本或者更早的版本,Hadoop采用了平级队列组织方式,在这种组织方式中,管理员将用户和资源分到若干个扁平队列中,在每个队列中,可指定一个或几个队列管理员管理这些用户和资源,比如杀死任意用户的应用程序,修改任意用户应用程序的优先级等。 随着Hadoop应用越来越广泛,扁平化的队列组织方式已不能满足实际需求,从而出现了层级队列的方式。
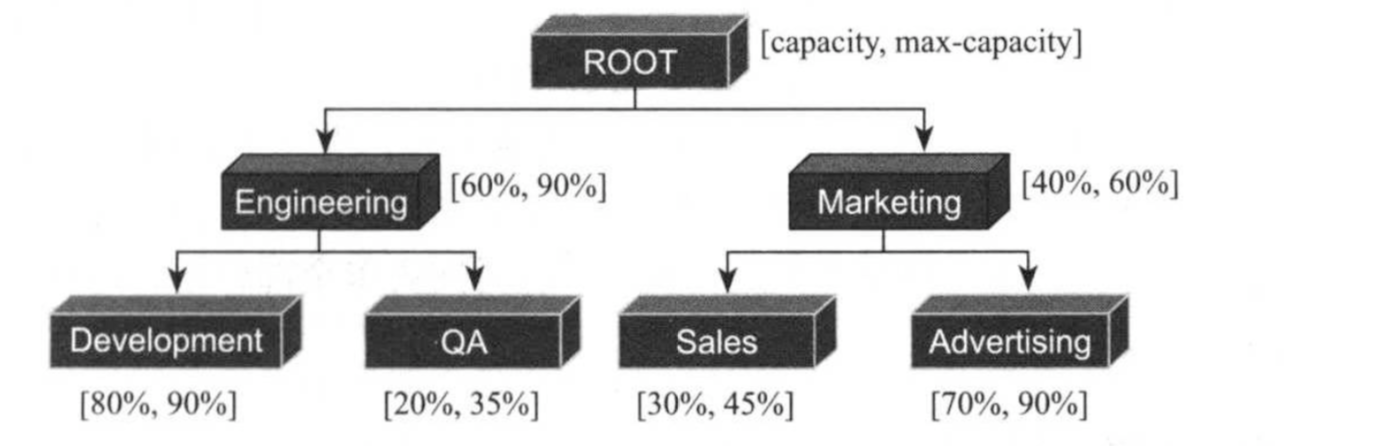
如上图所示,在一个Hadoop集群中,管理员将所有计算资源划分给了两个队列,每个队列对应一个“组织”,其中有一个组织叫“Engineering”,占用系统总资源的60%,它内部包含两个子队列“Development”和“QA”,分别占用80%和20%的资源;另一个组织叫“Marketing”,占用系统总资源的40%,它内部也包含两个子队列“Sales”和“Advertising”,分别占用30%和70%的资源。 在实际生成环境中,对于“Engineering”队列而言,管理员可能更想有效地控制这60%资源,比如将大部分资源分配给“Development”队列的同时,能够让“QA”有最少资源保证,当“Development”中80%基础资源有剩余时,可优先给同父子队列“QA”,但为了防止“QA”一次性获得全部资源以至于“Development”需要资源时无法第一时间回收它们,可将“QA”最多获得资源设为35%,为此,一种可能的配置方式如下:
ROOT {
Engineering min=60%,max=90%{
Development min=80%,max=90%
QA min=20,max=35%
}
Marketing min=40%,max=60%{
Sales min=30%,max=45%
Advertising min=70%,max=90%
}
}
这就是层级队列组织方式,该队列组织方式具有以下特点:
1>.子队列
(1)队列可以嵌套,每个队列均可以包含子队列。
(2)用户只能将应用程序提交到最底层的队列,即叶子队列。
2>.最少容量
(1)每个子队列均有一个“最少容量比”属性,表示可以使用父队列的容量百分比。 (2)调度器总是优先选择当前资源使用率最低的队列,并为之分配资源。比如同级别个队列Q1和Q2,他们的最少容量均为30,而Q1已使用10,Q2已使用12,则调度器会优先将资源分配给Q1。 (3)最少容量不是“总会保证最低容量”,如果一个队列最少容量为20,而该队列中所有队列仅使用了5,那么剩下的15可能会分配给其他需要的队列。 (4)最少容量的值为不小于0的数,但也不能大于“最大容量”。
3>.最大容量
(1)为了防止一个队列超量使用资源,可以分为队列设置一个最大容量,这是一个资源使用上限,任何时刻使用的资源总量不能超过该值。 (2)默认情况下队列的最大容量是无限大,这意味着,当一个队列只配置了20%的资源,所有其他队列没有应用程序时,该队列可能使用100%的资源,而当其他队列有应用程序提交时,在逐步归还(如果一段时间内未全部归还,可通过抢占的方式强制收回)。
二.多租户资源调度产生背景
Hadoop最初的设计目的是支持大数据批处理,如日志挖掘,Web索引等作业,为此,Hadoop仅提供了一个非常简单的调度机制:FIFO,即先来先服务,该调度机制下,所有作业被统一提交到一个队列中,Hadoop按照提交顺序依次运行这些作业。 但随着Hadoop的普及,单个Hadoop集群的用户量越来越大,不同用户提交的应用程序往往具有不同的服务质量要求(Quality Of Service,简称Qos),典型的应用有以下几种: (1)批处理作业: 这种作业往往耗时较长,对完成时间一般没有严格要求,典型应用有数据挖掘,机器学习等。 (2)交互式作业: 这种作业期望能及时返回结果,支持类SQL的交互式查询语言,典型应用有数据交互式分析,参数化报表生成等。
(3)生成性作业:
这种作业要求有一定的资源保证,典型应用有统计值极速啊,垃圾数据分析等。
此外,这些应用程序对硬件资源的需求量也是不同的,如过滤,统计类作业一般为CPU密集型作业,而数据挖掘,机器学习作业一般为I/O密集型作业。考虑到以上应用程序特点,简单的FIFO调度策略不仅不能满足多样化需求,也不能充分利用硬件资源。
为了克服单队列FIFO调度器的不足,多用户多队列调度器诞生了。当前要注意有两种多用户资源调度器的设计思路:
(1)第一种是在一个物理集群上虚拟多个Hadoop集群,这些集群各自拥有全套独立的Hadoop服务,典型的代表是HOD(Hadoop On Demand)调度器;
(2)另一种是扩展Hadoop调度器,使之支持多个队列多用户,这种调度器允许管理员按照应用需求对用户或者应用程序分组,并为不同的分组分配不同的资源量,同时通过添加各种约束防止单个用户或者应用程序独占资源,进而能够满足各种Qos需求,典型代表是Yahoo!的Capacity Scheuler和Facebook的Fari Scheduler。
关于HOD的相关链接:http://hadoop.apache.org/docs/r1.0.4/hod_scheduler.html。
Capacity Scheuler相关的链接:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html。
Fari Scheduler相关的链接:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html。
三.Capacity/Fair Scheduler
1>.Capacity Scheuler
Capacity Scheduler是Yahoo!开发的多租户调度器,它一队列为单位划分资源,每个队列可设定一个比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用,而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。总是,Cacacity Scheduler主要有以下几个特点: (1)容量保证 管理员可为每个队列设置资源最低保证和资源使用上限,而所有提交到该队列的应用程序共享这些资源。
(2)灵活性
如果一个队列的资源有剩余,可以暂时共享给哪些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列释放资源后会归还给该队列。 (3)多重租凭
支持多用户共享集群和多应用程序同时运行,为防止单个应用程序,用户或者队列独占集群中的资源,管理员可为之增加多种约束(比如单个用户使用最多使用的资源量)。
(4)安全保证
管理员可通过ACL限制每个队列的访问控制列表,普通用户可为自己的应用程序指定其他哪些用户可管理它(比如杀死它)。
(5)动态更新配置文件
管理员可根据需要动态修改各种资源调度器相关配置参数而无需重启集群。
Capacity Scheduler允许用户在配置文件capacity-scheduler.xml中设置队列层级关系,队列资源占用比等信息,如刚刚说到的层级管理队列图(晚上翻会看到一张图),展示的队列组织方式为例,Capacity Scheduler的配置方式如下表所示
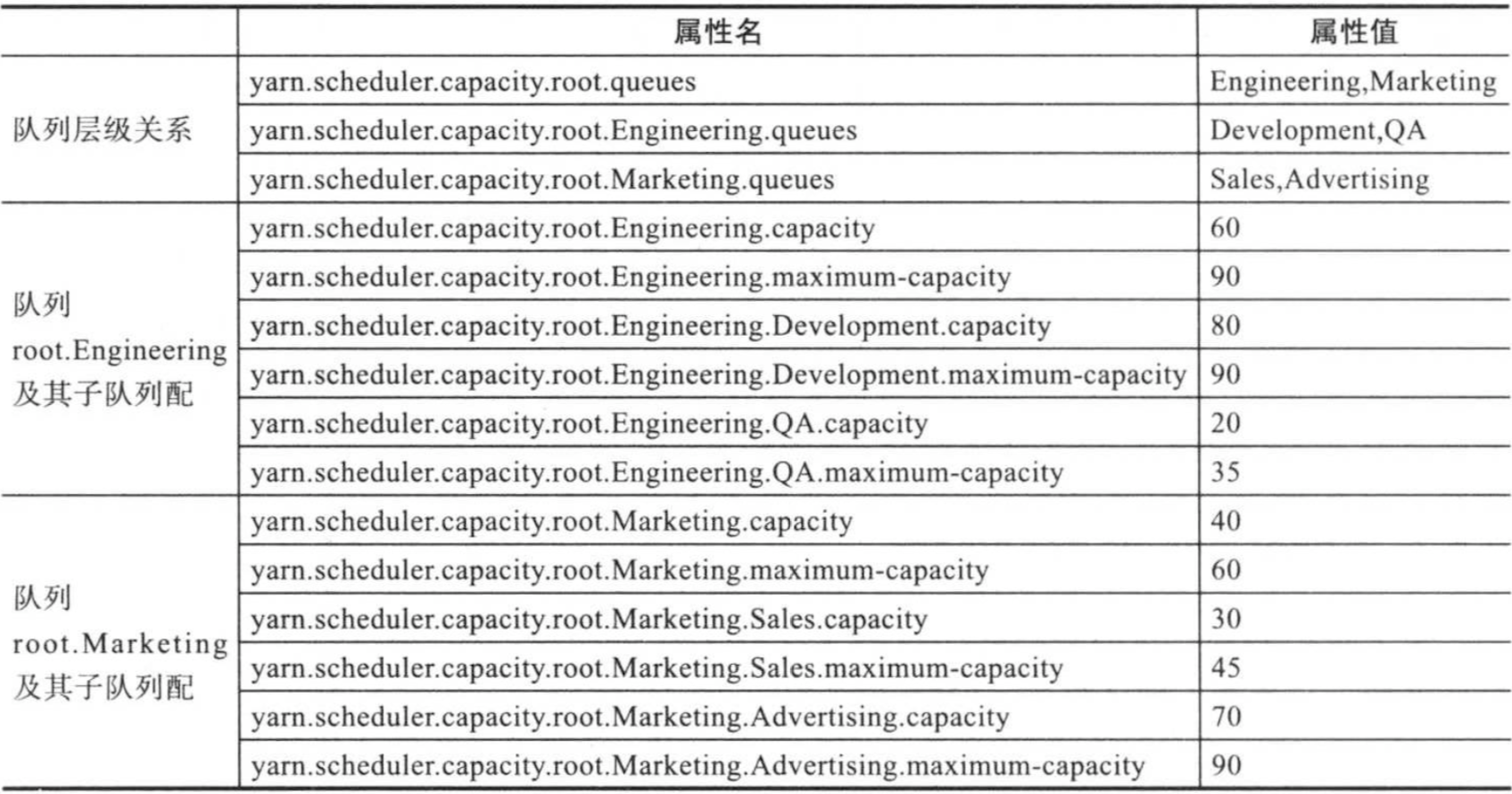
在capacity-scheduler.xml中,以属性名/属性值格式保存,如上图中前两行可写成: <configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>Engineering,Market</value> </property> <property> <name>yarn.scheduler.capacity.root.Engineering.queues</name> <value>Development,OA</value> </property> <!--其他属性配置,参考上面的配置照猫画虎就成!--> </configuration>
由于篇幅有限,该调度器只是做了个简单的说明,详情请参考官网网站:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html(博主强烈推荐你抽2分钟看看他!)。
2>.Fari Scheduler
Fari Schedule是Facebook开发的多用户调度器,同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限为防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。当然,Fair Schedule也存在很多的Capacity Scheduler不同之处,主要体现在以下几个方面: (1)资源公平共享 在每个队列中,Fair Scheduler可选择按照FIFO,Fair或DRF策略为应用程序分配资源,其中Fari策略是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/3的资源。 (2)调度资源配置灵活 Fair Scheduler允许管理员为每个队列单独设置调度策略(当前支持FIFO,Fair和RDF惨重)。 (3)提高小应用程序响应时间 由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成。 (4)应用程序在队列间转移 用户可以统带将一个正在运行的应用从一个队列转移到另外一个队列中。 Fari Scheduler允许用户在配置文件fari-scheduler.xml中设置队列层级关系,队列资源占比等情况,我们还是以层级管理队列图(本博客中的从上往下看第一幅图)展示的组织方式为例,Fari Scheduler配置如下: <allocations> <queue name="Engineering"> <minResources>1000000mb,500vcores</minResources> <maxResources>1500000mb,750vcores</manResources> <maxRuningApps>200</maxRuningApps> </queu> <queue name="Development"> <minResources>800000mb,400vcores</minResources> <maxResources>900000mb,450vcores</manResources> </queu> <queue name="QA"> <minResources>2000000mb,100vcores</minResources> <maxResources>3500000mb,170vcores</manResources> </queu> </allocations>
注意,Fair Scheduler没有采用百分比的方式表示资源,取而代之的是实际的资源数量。由于篇幅有限,详情请参考官方文档:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html(博主强烈推荐阅读)
3>.Capacity Scheduler与Fair Scheduler对比
随着Hadoop版本的演化,Fair Scheduler和Capacity Scheduler的功能越来越完善,包括层级队列组织方式,资源抢占,批量调度等,也正因为如此,两个调度器同质化越来越严重,目前看来,两个调度器从设计到支持特效等方面已经非常接近,而由于Fari Scheduler支持多种调度策略,可以认为Fari Scheduler具备了Capacity Schedule具备的所有功能。
从多个方面对比这两个调度器的异同,如下图所示:
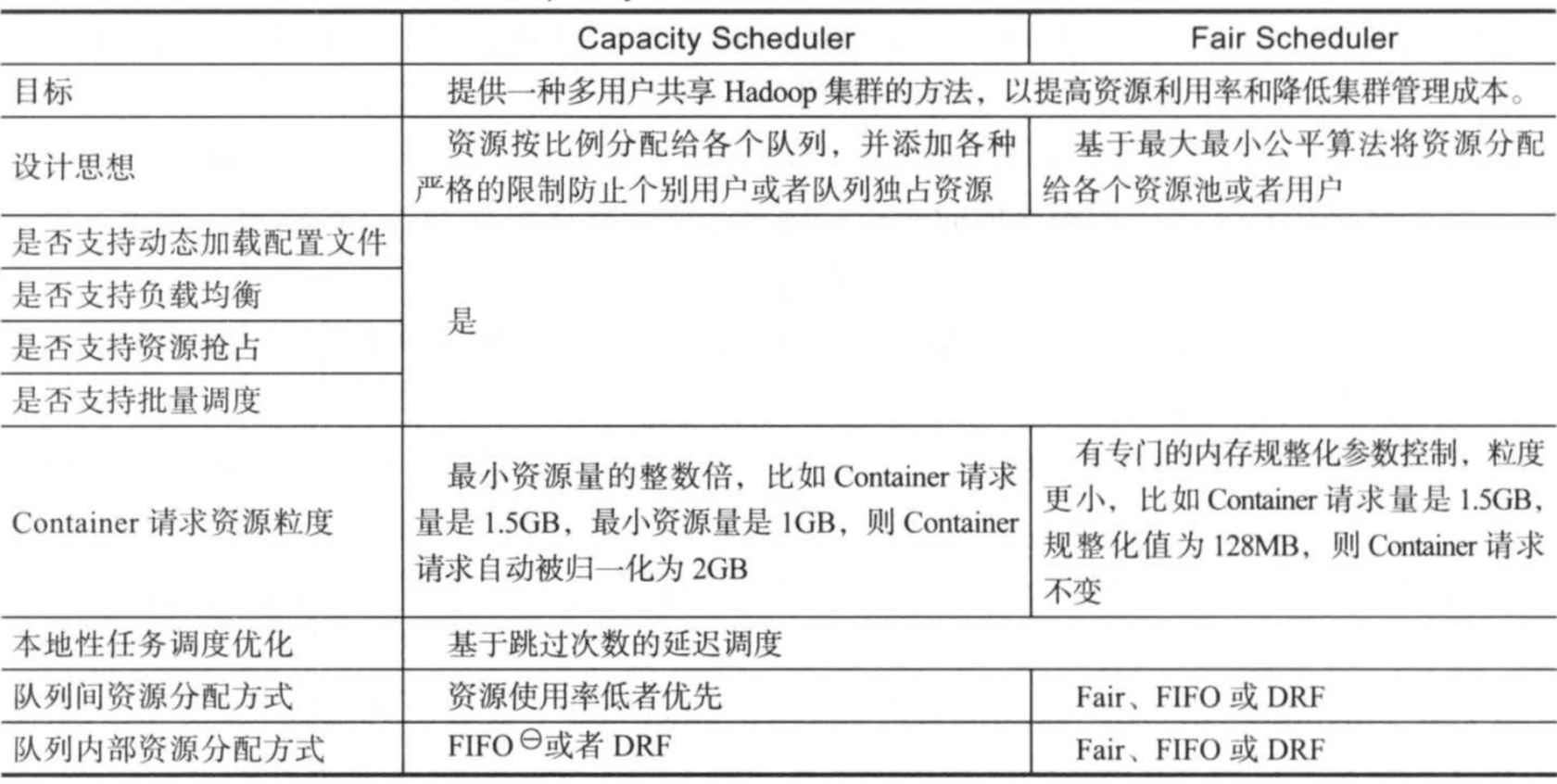
Fari Scheduler最初是为了引入公平调度策略而提出的,它扩展了面向单类型资源的max-min公平算法,让其支持多种类型资源,这是很多公司选择Fair Scheduler的原因,但随着Capacity Scheduler也引入这一资源分配算法,两者差异化已并不明显。
从2.8.0版本开始,Capacity Scheduler支持队列内部定制化调度机制,可从FIFO和Fair中二选一。
四.基于节点标签的调度
从2.6.0版本开始,YARN引入了一种新的调度策略:基于标签的调度机制,该机制的主要引入动机是更好让YARN运行在异构集群中,进而更好地管理和调度混合类型的应用程序。
1>什么是基于标签的调度
顾名思义,基于标签是一种调度策略,就像基于优先级的调度一样,是调度器中众多调度策略中的一种,可以根其他调度策略混合使用。
该策略的基本上是:用户可以为每个NodeManager打上标签,比如highmem,highdisk等,以作为NodeManager的基本属性;同时,用户可以为调度器中的队列设置若干标签,以限制该队列只能占用包含对应标签的节点资源,这样,提交到某个队列中的作业,只能运行在特定的一些节点上。通过打标签,用户可将Hadoop分成若干个子集群,进而使得用户可将应用程序运行到符合某种特征的节点上,比如可将内存密集型的应用程序(比如Spark)运行到内大内存节点上。
2>.标签调度的应用场景
为了更好的解释基于标签调度的应用场景,我们来看一个简单的应用案例。
公司A最初Hadoop集群共有20个节点,硬件资源是32GB内存,4TB磁盘,后来,随着Spark计算框架的流行,公司希望引入Spark技术,而为了更好地运行Spark程序,公司特买了10个大内存节点,内存是64GB。为了让Spark和MapReduce等不同类型的程序“和谐”地运行在一个集群中,公司A规定:Spark 程序只运行在后来的10个大内存节点上,如下图所示:
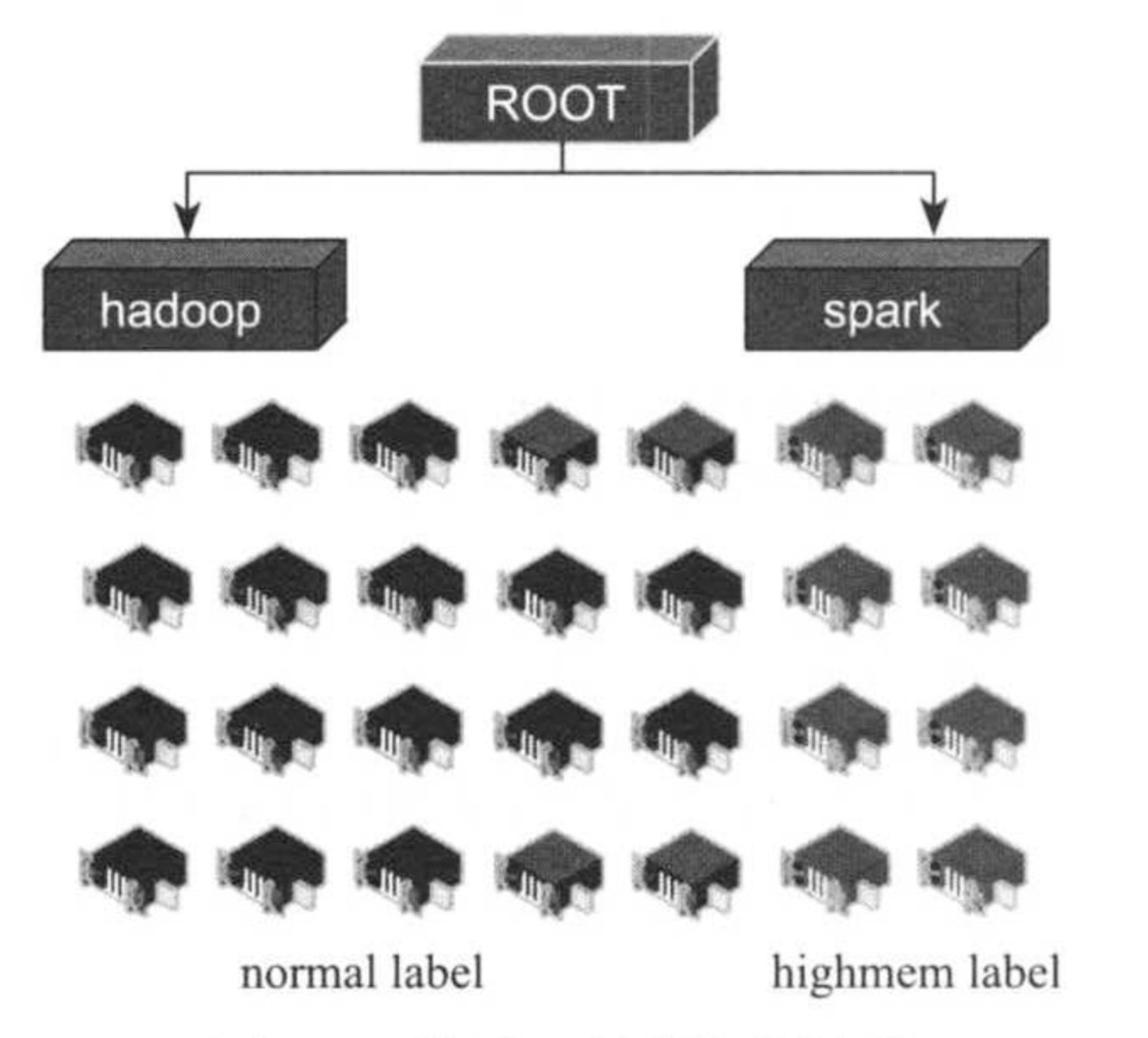
如何实现这种独特的任务调度方式呢?有了基于标签调度机制后,这是一件非常容易的事情,流程如下: (1)为20个旧节点打上normal标签,为10个新节点打上highmem标签。 1)设置系统级别label: yarn rmadmin -addToClusterNodeLabels "normal,highmem" 2)为节点打上label,比如节点node101的label为normal(必须属于系统界别label),则使用命令: yarn rmadmin -replaceLabelsOnNode "node1-adress,normal" (2)在Capacity Scheduler中,创建两个队列,分别是hadoop和Spark,其中hadoop队列可使用的标签是normal和highmem,其中normal默认为label,而spark则是highmem,并配置两个队列的capacity和max-capacity等属性。资源配置容量如下: capacity(hadoop) = 50 #hadoop队列可使用的无label资源比例为50% capacity(hadoop,label=normal) = 100 #hadoop队列可使用的normal标签资源比例为100% capacity(hadoop,label=highmem) = 10 #hadoop队列可使用的highmem标签资源比例为10% capacity(spark) = 50 #spark队列可使用的无标签资源比例为50% capacity(spark,label=highmem) = 90 #spark队列可使用的highmem标签资源比例为90% 由于系统中没有未打标签的节点,所以每个队列中无标签资源比暂时不会用到。以上配置转换成Capacity Scheduler配置文件标准语法如下: <configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>hadoop,spark</value> </property> <property> <name>yarn.scheduler.capacity.root.accessible-node-labels.normal.capcity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.accessibel-node-labels.highmem.capacity</name> <value>100</value> </property> <!--配置hadoop队列--> <property> <name>yarn.scheduler.capacity.root.hadoop.accessible-node-labels</name> <value>normal,highmem</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.capacity</name> <value>50</value> </property> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>hadoop,spark</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.accessible-node-labels.normal.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.accessibel-node-labels.highmem.capacity</name> <value>10</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.default-node-label-expression</name> <value>normal</value> </property> <!--配置spark队列--> <property> <name>yarn.scheduler.capacity.root.spark.accessible-node-labels</name> <value>highmem</value> </property> <property> <name>yarn.scheduler.capacity.root.spark.capacity</name> <value>50</value> </property> <property> <name>yarn.scheduler.capacity.root.spark.accessiable-node-labels.highmem.capactity</name> <value>90</value> </property> <property> <name>yarn.scheduler.capacity.root.spark.default-node-label-expression</name> <value>highmem</value> </property> <configuration> (3)将spark作业提交到spark队列中,MapReduce作业提交到Hadoop队列中(需指定使用哪种label资源,否则spark资源永远无法得到使用,默认是normal)。 #提交spark作业到spark队列中 spark-subit --queue spark --class xxx... #提交mapReduce作业到hadoop队列中 hadoop jar -Dmapreduce.job.queuename=hadoop...
五.资源抢占模型
在资源调度器中,每个队列可设置一个最小资源量和最大资源量,其中,最小资源量是资源紧缺情况下每个队列需要保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。
资源抢占发生的原因是完全由于“最小资源量”这一概念,通常而言,为了提高资源利用率,资源调度器(包括Capacity Scheduler和Fair Scheduler)会将负载较轻的队列得的资源暂时分配给负载重的队列(即最小资源量并不是硬资源保证,当队列不需要任何资源时,并不会满足他的最小资源量,而是暂时将空闲资源分配给其他需要资源的队列),仅当负载较轻的队列突然收到新提交的应用程序时,调度器才进一步将本属于该队列的资源后,才能将这些资源“物归原主”,这通常需要一段不确定的等待时间。为了方式应用程序等待时间过长,调度器等待一段时间后若发现资源并未得到释放,则进行资源抢占。
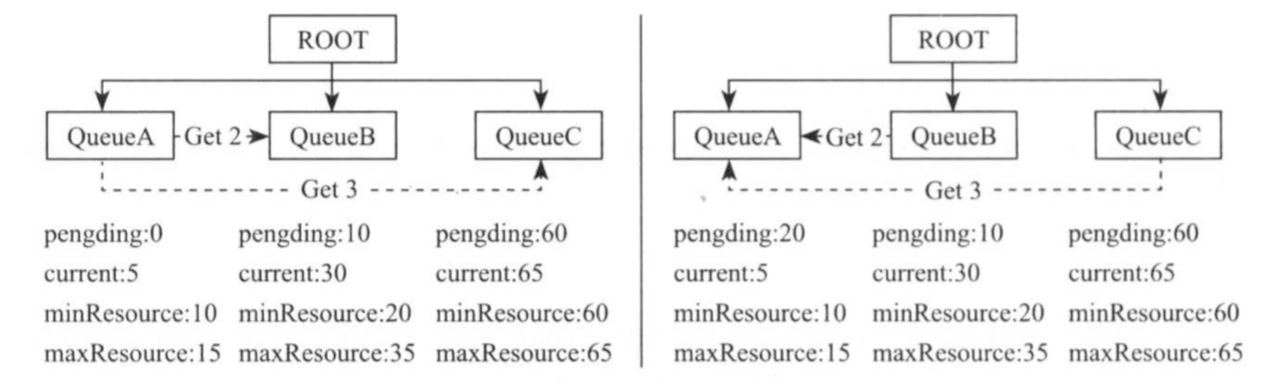
如上图所示,整个集群资源总量为100(为了简便,没有区分CPU或者内存),且被分为三个队列,分别是QueueA,QueueB和QueueC,它们的最小资源量和最大资源量(由管理员配置)分别是(10,15),(20,35)和(60,65),某一时刻,它们尚需的资源量和正在使用的资源量分别是(0,5),(10,30)和(60,65),即队列QueueA负载较轻,部分资源暂时不会使用,它将不会使用的5个资源共享给其他两个队列(QueueB和QueueC分别得到2个和3个),而队列QueueB和QueueC除了使用来自队列QueueA的资源外,还使用了整个系统共享的10个资源(100-10-20-60=10),某一时刻,队列QueueA突然增加了一批应用程序,此时共需要20个资源,则资源调度器需要从QueueB和QueueC中抢占5个本该属于QueueA的资源。需要注意的是,为了避免资源浪费,资源调度器通常会等待一段时间后才会强制回收资源,而这段等待时间内,QueueB和QueueC可能已经释放了本该属于QueueA的资源。