交互式计算引擎MOLAP篇
摘自:《大数据技术体系详解:原理、架构与实践》
MOLAP是一种通过预计算cube方式加速查询的OLAP引擎,它的核心思想是“空间换时间”,典型代表包括Druid和Kylin。
一.Druid简介
Druid是一个用于大数据实时查询和分析的高容错,高性能开源分布式OLADP系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
Durid是基于列存储的,其设计之初主要目的是存储时间序列数据,因此数据强制按照时间分隔不同的数据段(segment),除了时间戳以外,一个数据段中还有纬度(dimension)和度量(metric)两种类型的列。
Durid能够快速对数据进行过滤和聚合,它常用来给一些面向分析人员的应用提供查询引擎。有些大规模的Druid集群每秒钟能够插入数十亿条事件并提供上千次的查询。
Druid官网网站:http://druid.io/。

Druid整个架构由实时线和批处理线两部分构成,本质上是对Lamaba架构的一种实现。如上图所示,Druid系统主要由三个外部依赖:用于分布式协调服务的zookeeper;存储集群数据信息和相关规则的Metadata Storage;存放备份数据的Deep Stroage。
Druid节点类型比较多,可以从三个方面了解系统架构:
(1)首先,从外部看,提供查询接口的节点是Broker节点,它根据具体的情况可能会将查询分发到实时(Real-time)节点或历史(Historical)节点,前者存放实时数据,后者存放历史数据;
(2)其次,从集群内部看,负责协调数据存储的是Coorinator节点,它读取Metadata,通过Zookeeper通知不同的Historical节点应当载入或丢弃哪些数据段;
(3)最后,从数据Ingest来看,可以将实时数据交给Real-time节点进行处理(real-time index),也可以直接将数据建好索引存放到Deep Storage中,然后更新Metadata(batch index),现在Druid提倡用Indexing Service来统一处理两种数据Ingest的情况。
二.Kylin简介
Kylin是Hadoop生态圈下的一个MOLAP系统,是ebay大数据部门从2014年开始研发的支持TB到PB级别数据量的分布式OLAP分析引擎。其特点包括:
(1)可扩展的超快OLAP引擎;
(2)提供ANSI-SQL接口;
(3)交互式查询能力;
(4)引入MOLAP Cube的概念以加速分析过程。
(5)支持JDBC/RESTful等访问方式,与BI工具可无缝整合。
Kylin的核心思想是利用空间换时间,它通过预计算,将查询结果预先存储到HBase上以加快数据处理效率。
Kylin官网网站:http://kylin.apache.org/。
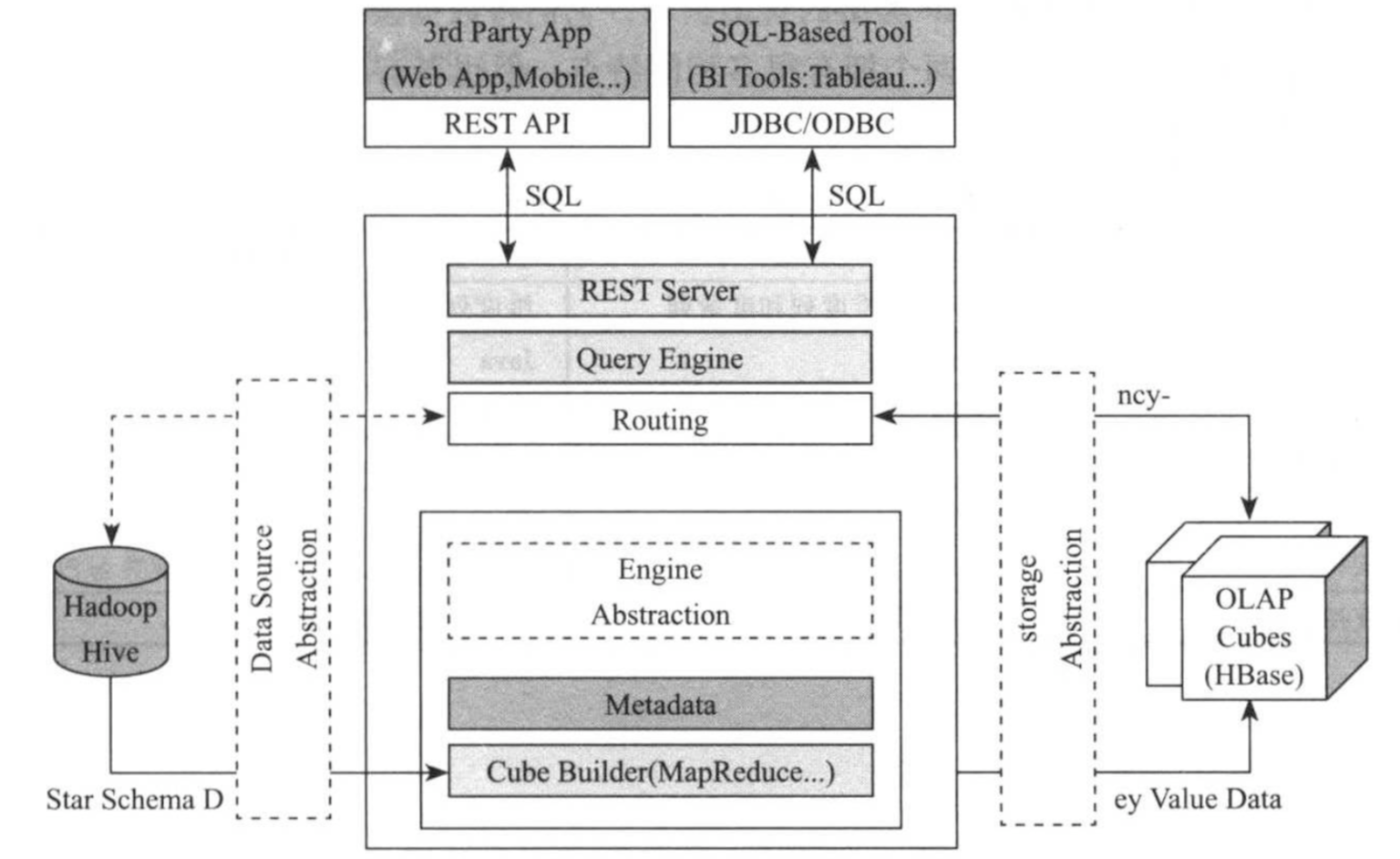
Kylin实现过程复用了大量开源系统,具体如上图所示。
RESST Server:
提供一些RESTful接口,例如创建cube,构建cube,刷新cube,合并cube等cube相关操作,元数据管理,用户访问权限,系统配置动态修改等。
JDBC/ODBC接口:
Kylin提供了JDBC驱动,使用JDBC接口的查询和使用RESTful接口的查询内部实现流程是相同的。这类接口使用Kyin能够兼容各种可视化工具,包括tableau和mondrian等。
Query引擎:
Kylin使用一个开源的calcite框架实现SQL的解析,相当于SQL引擎层。
calcite官网网站:http://calcite.apache.org/.
Routing:
该模块负责将SQL生成的执行计划转换成面向cube缓存的查询。cube是通过预计算缓存在HBase中,这些查询只需从HBase直接获取结果返回即可,一般在妙计甚至毫秒级完成。
Metadata:
Kylin中包含大量的元数据信息,包括cube的定义,星状模型的定义,作业的信息,作业的输出嘻嘻,纬度的存放目录信息等,元数据和cube都存储在Hbase中。
Cube构建引擎:
负责预计算方式的构建cube,这是通过MapReduce/Spark计算生成HTable然后加载到HBase中完成的。
三.Druid于Kylin对比
Druid与kylin均是MOLAP类型的查询引擎,它们将数据按照多维度数据方式存储,并通过索引方式加速计算。它们两个拥有很多相同特点,但也各有自己的特色,它们的异同对比如下图所示。
