Hadoop生态圈-Azkaban实现文件上传到hdfs并执行MR数据清洗
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
如果你没有Hadoop集群的话也没有关系,我这里给出当时我部署Hadoop集群的笔记:https://www.cnblogs.com/yinzhengjie/p/9154265.html。当然想要了解更多还是请参考官网的部署方案,我部署的环境只是测试开发环境。
一.启动Hadoop集群
1>.启动脚本信息


[yinzhengjie@s101 ~]$ more /usr/local/bin/xzk.sh #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -ne 1 ];then echo "无效参数,用法为: $0 {start|stop|restart|status}" exit fi #获取用户输入的命令 cmd=$1 #定义函数功能 function zookeeperManger(){ case $cmd in start) echo "启动服务" remoteExecution start ;; stop) echo "停止服务" remoteExecution stop ;; restart) echo "重启服务" remoteExecution restart ;; status) echo "查看状态" remoteExecution status ;; *) echo "无效参数,用法为: $0 {start|stop|restart|status}" ;; esac } #定义执行的命令 function remoteExecution(){ for (( i=102 ; i<=104 ; i++ )) ; do tput setaf 2 echo ========== s$i zkServer.sh $1 ================ tput setaf 9 ssh s$i "source /etc/profile ; zkServer.sh $1" done } #调用函数 zookeeperManger [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more /usr/local/bin/xcall.sh #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数" exit fi #获取用户输入的命令 cmd=$@ for (( i=101;i<=105;i++ )) do #使终端变绿色 tput setaf 2 echo ============= s$i $cmd ============ #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 ssh s$i $cmd #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more /soft/hadoop/sbin/start-dfs.sh #!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Start hadoop dfs daemons. # Optinally upgrade or rollback dfs state. # Run this on master node. usage="Usage: start-dfs.sh [-upgrade|-rollback] [other options such as -clusterId]" bin=`dirname "${BASH_SOURCE-$0}"` bin=`cd "$bin"; pwd` DEFAULT_LIBEXEC_DIR="$bin"/../libexec HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR} . $HADOOP_LIBEXEC_DIR/hdfs-config.sh # get arguments if [[ $# -ge 1 ]]; then startOpt="$1" shift case "$startOpt" in -upgrade) nameStartOpt="$startOpt" ;; -rollback) dataStartOpt="$startOpt" ;; *) echo $usage exit 1 ;; esac fi #Add other possible options nameStartOpt="$nameStartOpt $@" #--------------------------------------------------------- # namenodes NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -namenodes) echo "Starting namenodes on [$NAMENODES]" "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" --config "$HADOOP_CONF_DIR" --hostnames "$NAMENODES" --script "$bin/hdfs" start namenode $nameStartOpt #--------------------------------------------------------- # datanodes (using default slaves file) if [ -n "$HADOOP_SECURE_DN_USER" ]; then echo "Attempting to start secure cluster, skipping datanodes. " "Run start-secure-dns.sh as root to complete startup." else "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" --config "$HADOOP_CONF_DIR" --script "$bin/hdfs" start datanode $dataStartOpt fi #--------------------------------------------------------- # secondary namenodes (if any) SECONDARY_NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -secondarynamenodes 2>/dev/null) if [ -n "$SECONDARY_NAMENODES" ]; then echo "Starting secondary namenodes [$SECONDARY_NAMENODES]" "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" --config "$HADOOP_CONF_DIR" --hostnames "$SECONDARY_NAMENODES" --script "$bin/hdfs" start secondarynamenode fi #--------------------------------------------------------- # quorumjournal nodes (if any) SHARED_EDITS_DIR=$($HADOOP_PREFIX/bin/hdfs getconf -confKey dfs.namenode.shared.edits.dir 2>&-) case "$SHARED_EDITS_DIR" in qjournal://*) JOURNAL_NODES=$(echo "$SHARED_EDITS_DIR" | sed 's,qjournal://([^/]*)/.*,1,g; s/;/ /g; s/:[0-9]*//g') echo "Starting journal nodes [$JOURNAL_NODES]" "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" --config "$HADOOP_CONF_DIR" --hostnames "$JOURNAL_NODES" --script "$bin/hdfs" start journalnode ;; esac #--------------------------------------------------------- # ZK Failover controllers, if auto-HA is enabled AUTOHA_ENABLED=$($HADOOP_PREFIX/bin/hdfs getconf -confKey dfs.ha.automatic-failover.enabled) if [ "$(echo "$AUTOHA_ENABLED" | tr A-Z a-z)" = "true" ]; then echo "Starting ZK Failover Controllers on NN hosts [$NAMENODES]" "$HADOOP_PREFIX/sbin/hadoop-daemons.sh" --config "$HADOOP_CONF_DIR" --hostnames "$NAMENODES" --script "$bin/hdfs" start zkfc fi # eof [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more /soft/hadoop/sbin/start-yarn.sh #!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Start all yarn daemons. Run this on master node. echo "starting yarn daemons" bin=`dirname "${BASH_SOURCE-$0}"` bin=`cd "$bin"; pwd` DEFAULT_LIBEXEC_DIR="$bin"/../libexec HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR} . $HADOOP_LIBEXEC_DIR/yarn-config.sh # start resourceManager #"$bin"/yarn-daemon.sh --config $YARN_CONF_DIR start resourcemanager "$bin"/yarn-daemons.sh --config $YARN_CONF_DIR --hosts masters start resourcemanager # start nodeManager "$bin"/yarn-daemons.sh --config $YARN_CONF_DIR start nodemanager # start proxyserver #"$bin"/yarn-daemon.sh --config $YARN_CONF_DIR start proxyserver [yinzhengjie@s101 ~]$
2>.启动zookeeper集群
[yinzhengjie@s101 ~]$ xzk.sh start 启动服务 ========== s102 zkServer.sh start ================ ZooKeeper JMX enabled by default Using config: /soft/zk/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ========== s103 zkServer.sh start ================ ZooKeeper JMX enabled by default Using config: /soft/zk/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ========== s104 zkServer.sh start ================ ZooKeeper JMX enabled by default Using config: /soft/zk/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xcall.sh jps ============= s101 jps ============ 2630 AzkabanWebServer 2666 AzkabanExecutorServer 3485 Jps 命令执行成功 ============= s102 jps ============ 2354 Jps 2319 QuorumPeerMain 命令执行成功 ============= s103 jps ============ 2332 Jps 2303 QuorumPeerMain 命令执行成功 ============= s104 jps ============ 2337 Jps 2308 QuorumPeerMain 命令执行成功 ============= s105 jps ============ 2310 Jps 命令执行成功 [yinzhengjie@s101 ~]$
3>.启动HDFS分布式文件系统
[yinzhengjie@s101 ~]$ start-dfs.sh SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Starting namenodes on [s101 s105] s101: starting namenode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-namenode-s101.out s105: starting namenode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-namenode-s105.out s105: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s105.out s103: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s103.out s104: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s104.out s102: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s102.out Starting journal nodes [s102 s103 s104] s103: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s103.out s102: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s102.out s104: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s104.out SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Starting ZK Failover Controllers on NN hosts [s101 s105] s101: starting zkfc, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-zkfc-s101.out s105: starting zkfc, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-zkfc-s105.out [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xcall.sh jps ============= s101 jps ============ 4016 Jps 3939 DFSZKFailoverController 2630 AzkabanWebServer 2666 AzkabanExecutorServer 3629 NameNode 命令执行成功 ============= s102 jps ============ 2480 JournalNode 2405 DataNode 2583 Jps 2319 QuorumPeerMain 命令执行成功 ============= s103 jps ============ 2382 DataNode 2303 QuorumPeerMain 2463 JournalNode 2559 Jps 命令执行成功 ============= s104 jps ============ 2465 JournalNode 2387 DataNode 2563 Jps 2308 QuorumPeerMain 命令执行成功 ============= s105 jps ============ 2547 DFSZKFailoverController 2436 DataNode 2365 NameNode 2655 Jps 命令执行成功 [yinzhengjie@s101 ~]$
4>.启动YARN资源调度器
[yinzhengjie@s101 ~]$ start-yarn.sh starting yarn daemons s101: starting resourcemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-resourcemanager-s101.out s105: starting resourcemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-resourcemanager-s105.out s105: starting nodemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-nodemanager-s105.out s103: starting nodemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-nodemanager-s103.out s104: starting nodemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-nodemanager-s104.out s102: starting nodemanager, logging to /soft/hadoop-2.7.3/logs/yarn-yinzhengjie-nodemanager-s102.out [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xcall.sh jps ============= s101 jps ============ 3939 DFSZKFailoverController 2630 AzkabanWebServer 4231 Jps 2666 AzkabanExecutorServer 4140 ResourceManager 3629 NameNode 命令执行成功 ============= s102 jps ============ 2480 JournalNode 2675 Jps 2405 DataNode 2638 NodeManager 2319 QuorumPeerMain 命令执行成功 ============= s103 jps ============ 2615 NodeManager 2698 Jps 2382 DataNode 2303 QuorumPeerMain 2463 JournalNode 命令执行成功 ============= s104 jps ============ 2465 JournalNode 2689 Jps 2387 DataNode 2308 QuorumPeerMain 2618 NodeManager 命令执行成功 ============= s105 jps ============ 2547 DFSZKFailoverController 2915 Jps 2436 DataNode 2365 NameNode 2782 NodeManager 命令执行成功 [yinzhengjie@s101 ~]$
5>.检查web服务是否可用正常访问
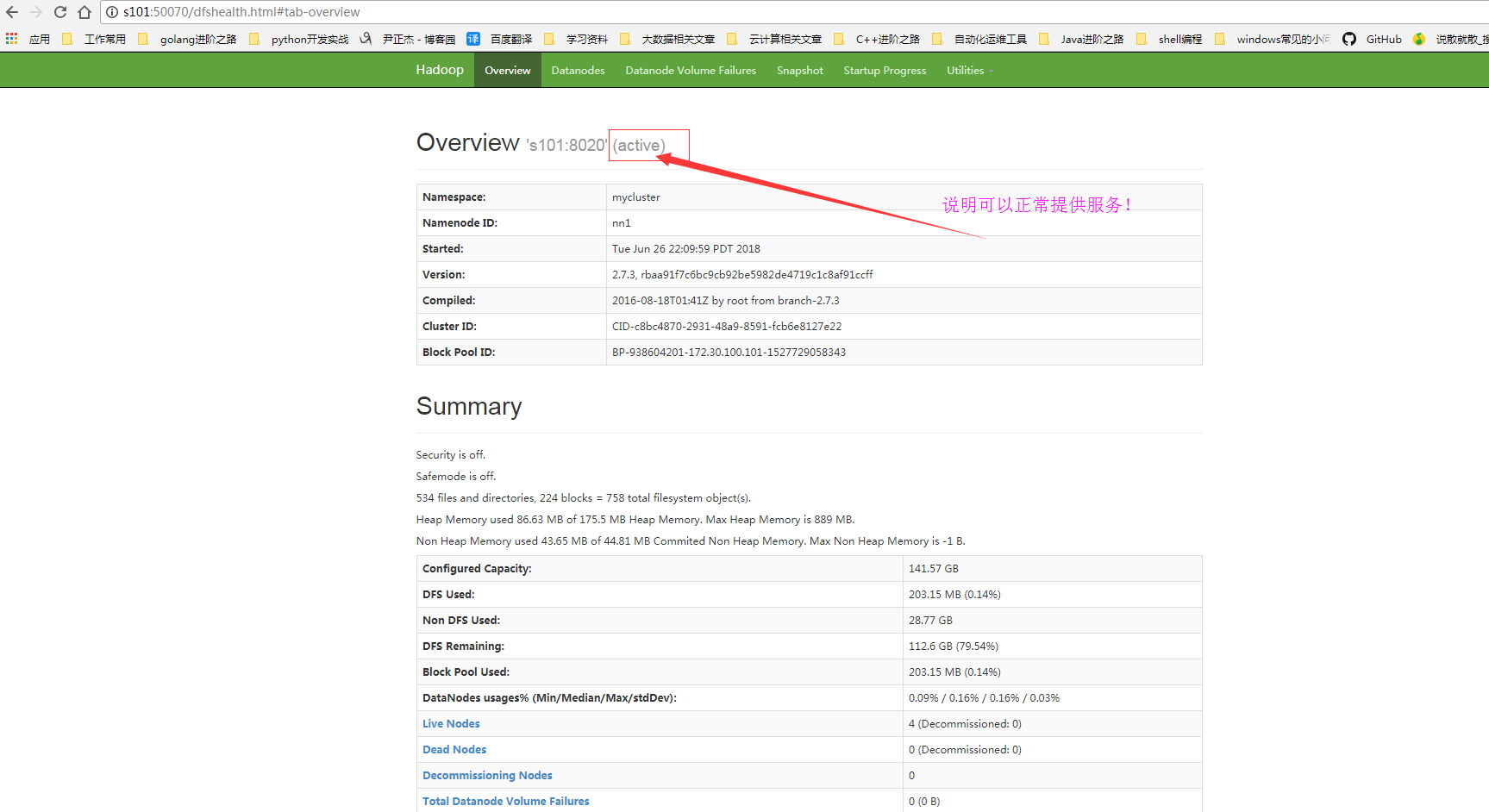
二.文件上传到hdfs
1>.创建job文件并将其压缩
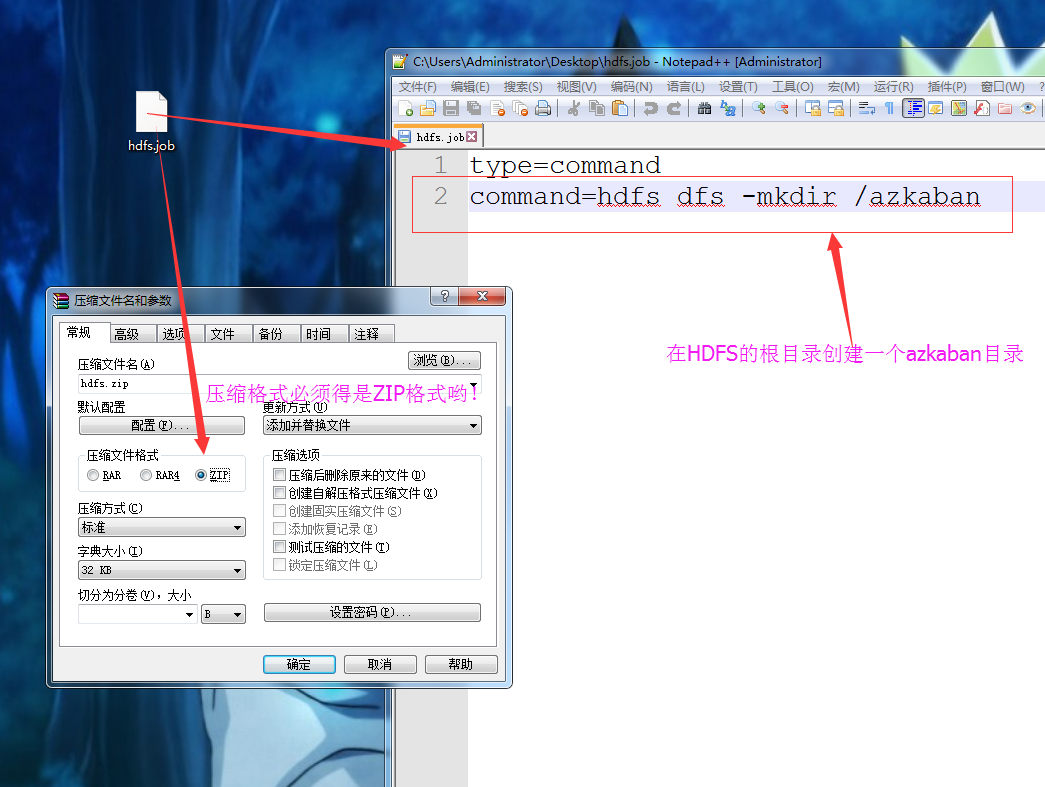
2>.将压缩后的文件上传至Azkaban的WEB服务器上

3>.执行jpb程序
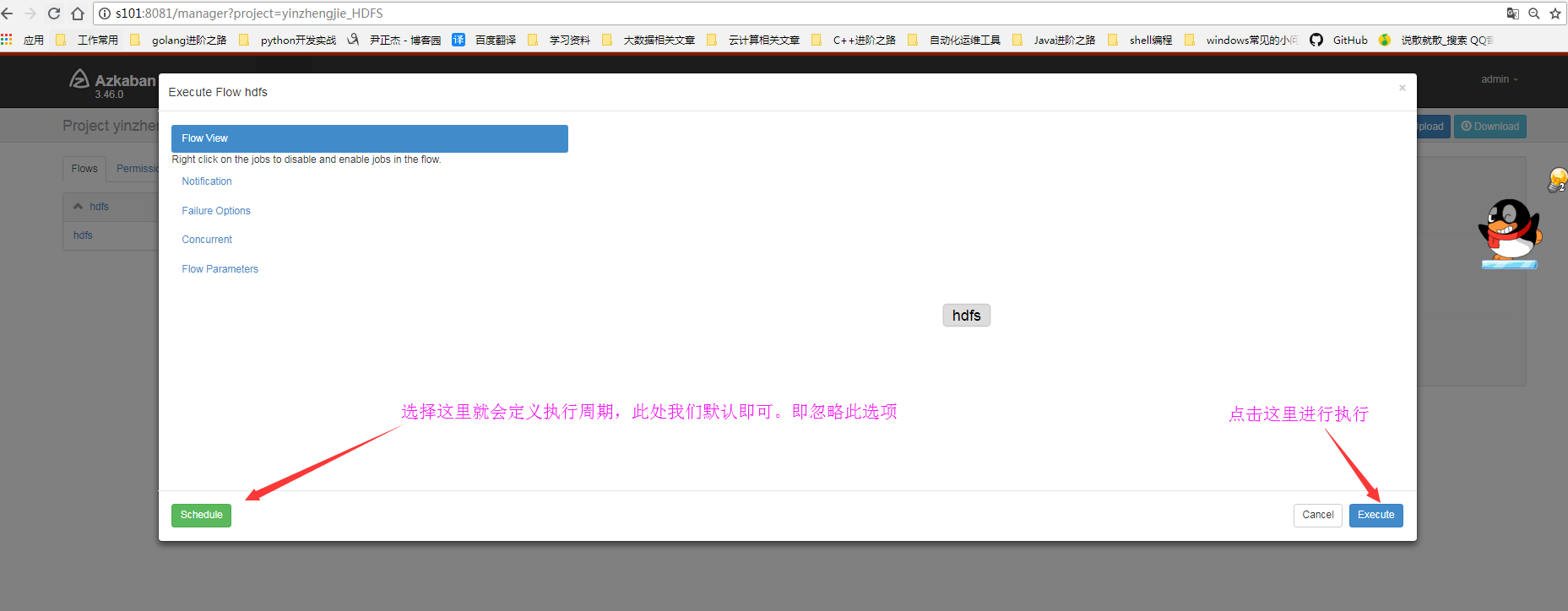
4>.点击继续
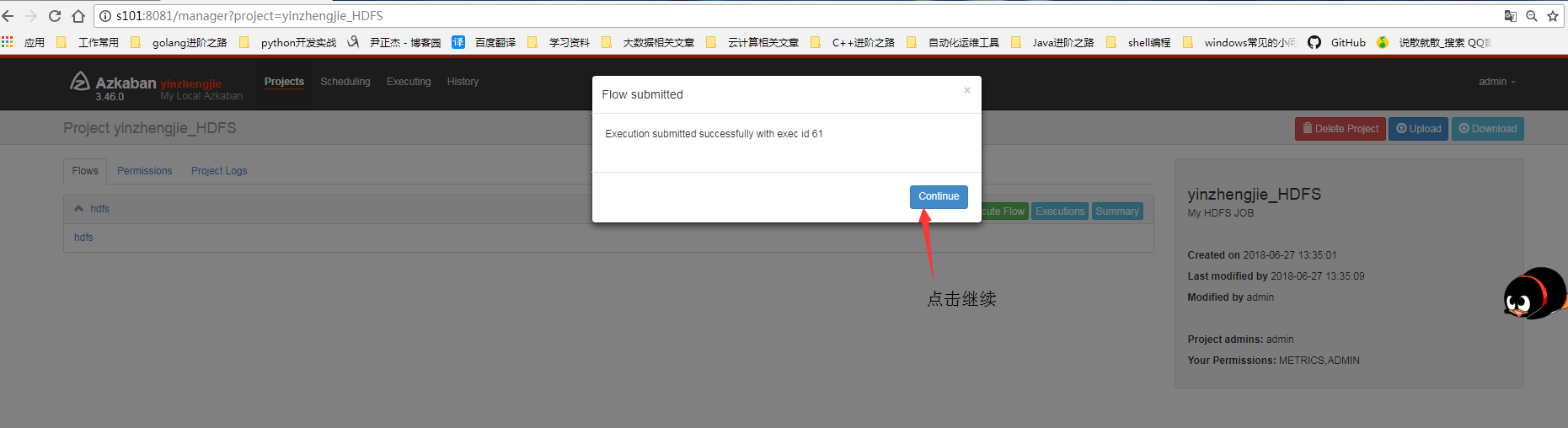
5>.查看细节
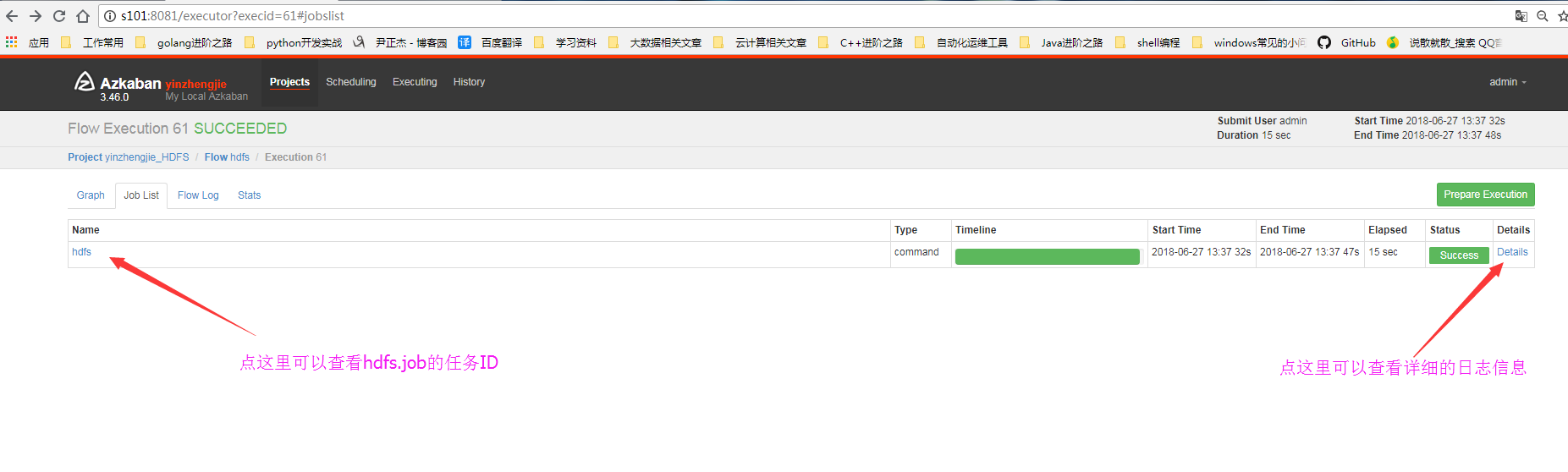
6>.查看日志信息
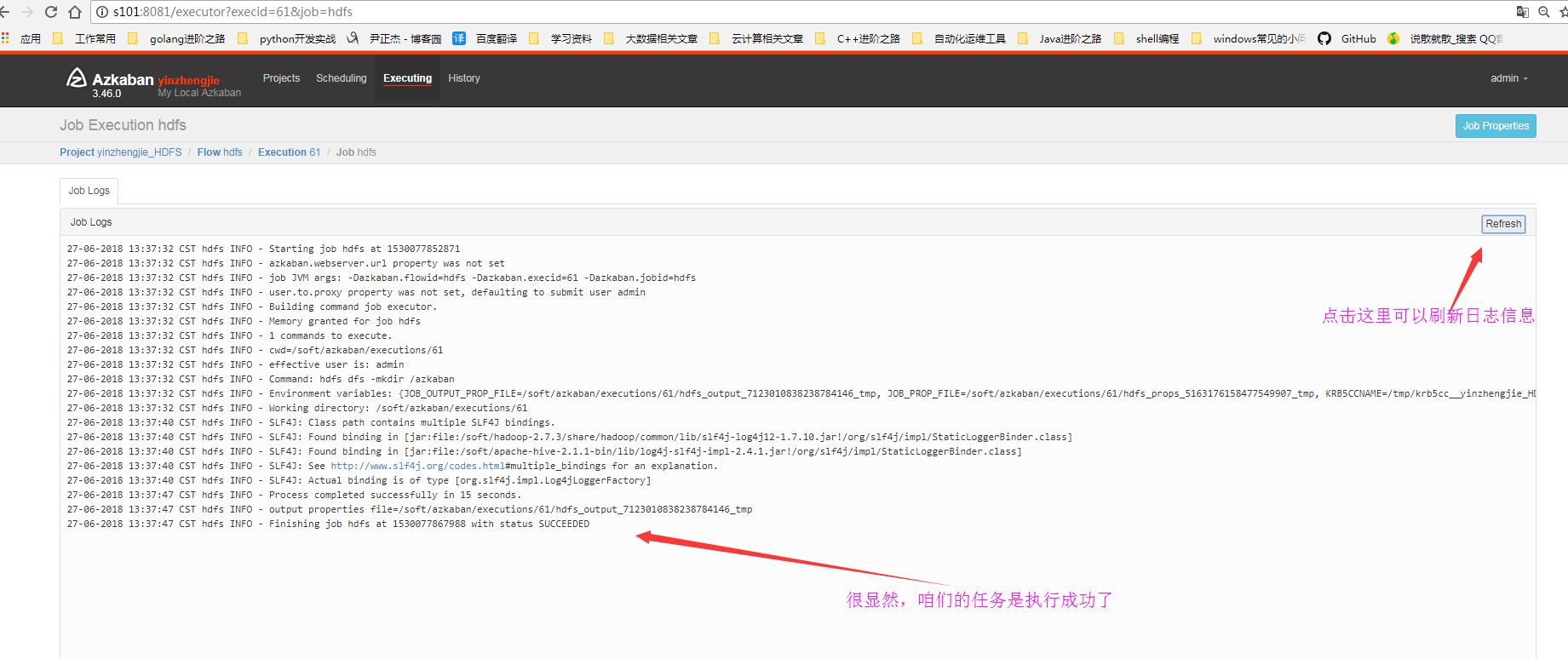
7>.查看HDFS的webUI是否在根下成功创建azkaban目录

8>.查看执行ID

三.执行MR数据清洗
1>.编辑的配置文件内容
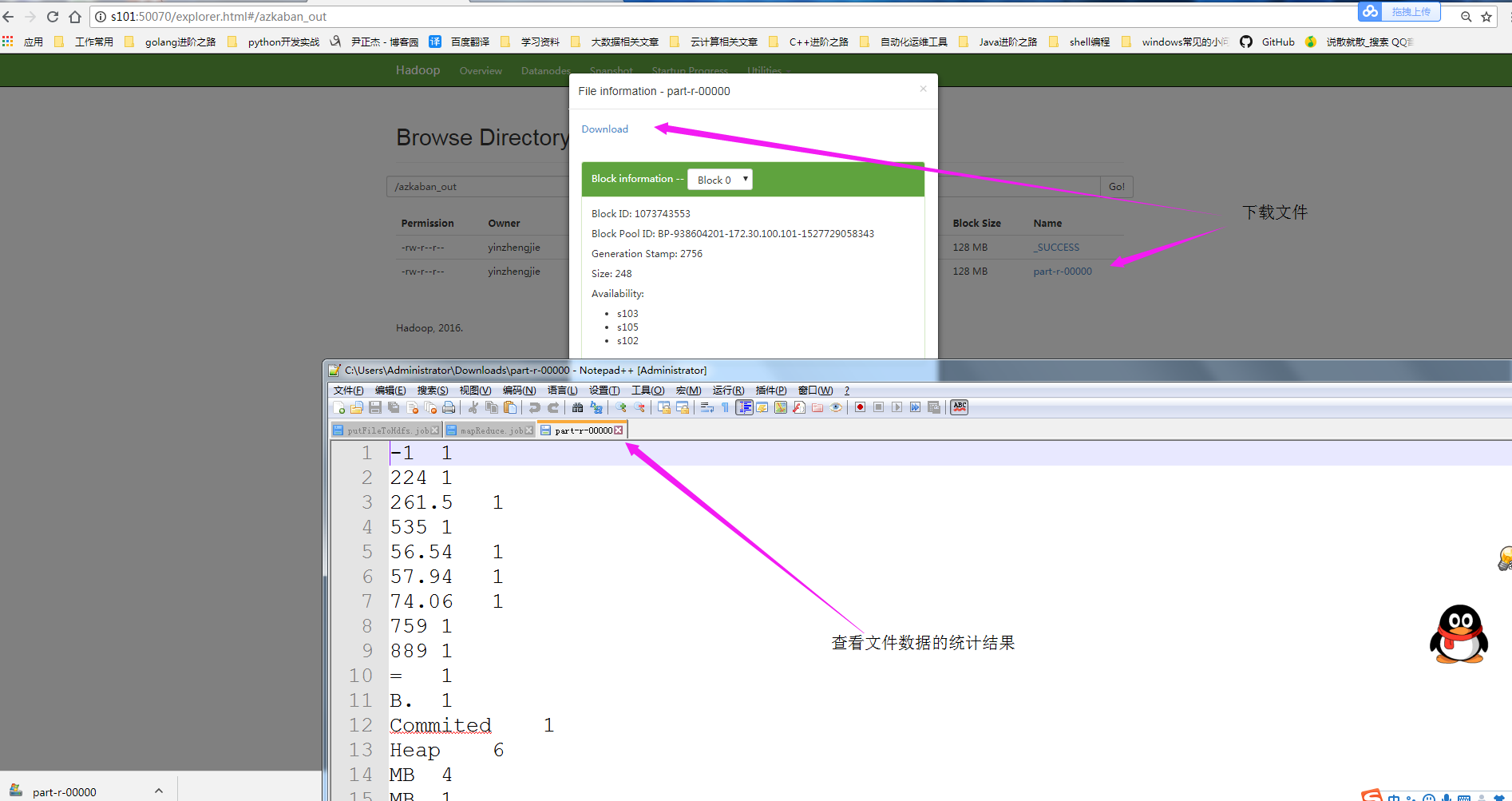
[yinzhengjie@s101 ~]$ more /home/yinzhengjie/yinzhengjie.txt Security is off. Safemode is off. 535 files and directories, 224 blocks = 759 total filesystem object(s). Heap Memory used 74.06 MB of 261.5 MB Heap Memory. Max Heap Memory is 889 MB. Non Heap Memory used 56.54 MB of 57.94 MB Commited Non Heap Memory. Max Non Heap Memory is -1 B. [yinzhengjie@s101 ~]$
#putFileToHdfs Add by yinzhengjie type=command command=hdfs dfs -put /home/yinzhengjie/yinzhengjie.txt /azkaban
#mapreduce.job ADD by yinzhengjie type=command command=hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /azkaban /azkaban_out
2>.编辑job任务并压缩

3>.将任务上传到azkaban的WEB界面中
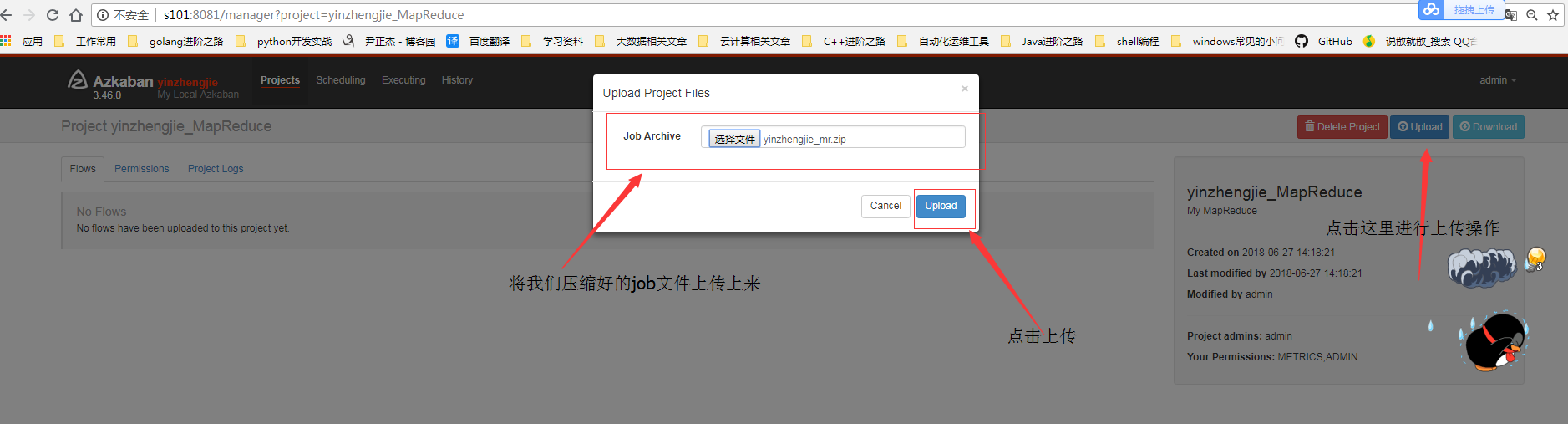
4>.选择执行顺序
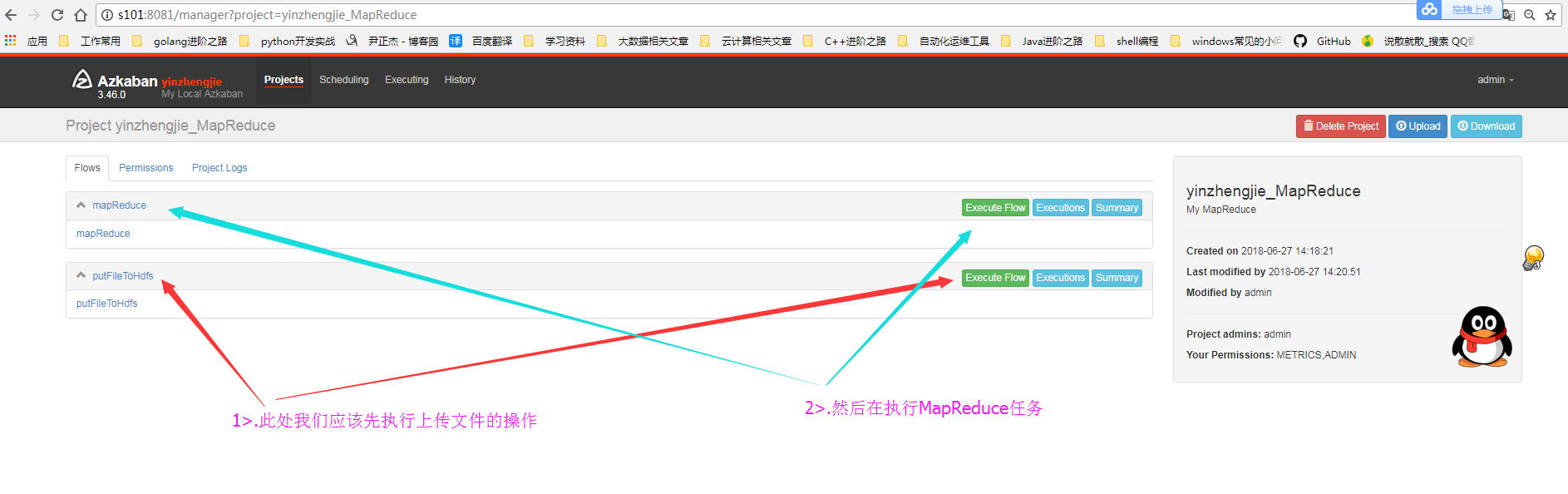
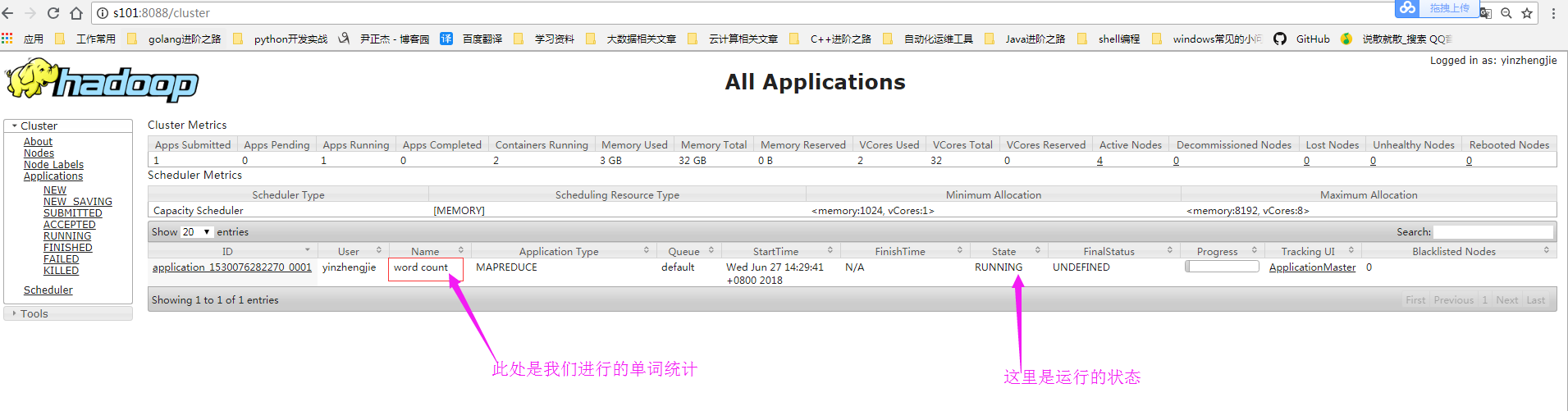
5>.查看MapReduce的运行状态
6>.查看MapReduce的运行结果