Hadoop生态圈-Azkaban实现hive脚本执行
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客中在HDFS分布式系统取的数据,而这个数据的是有之前我通过MapReduce生产的数据,详情请参考:https://www.cnblogs.com/yinzhengjie/p/9233393.html
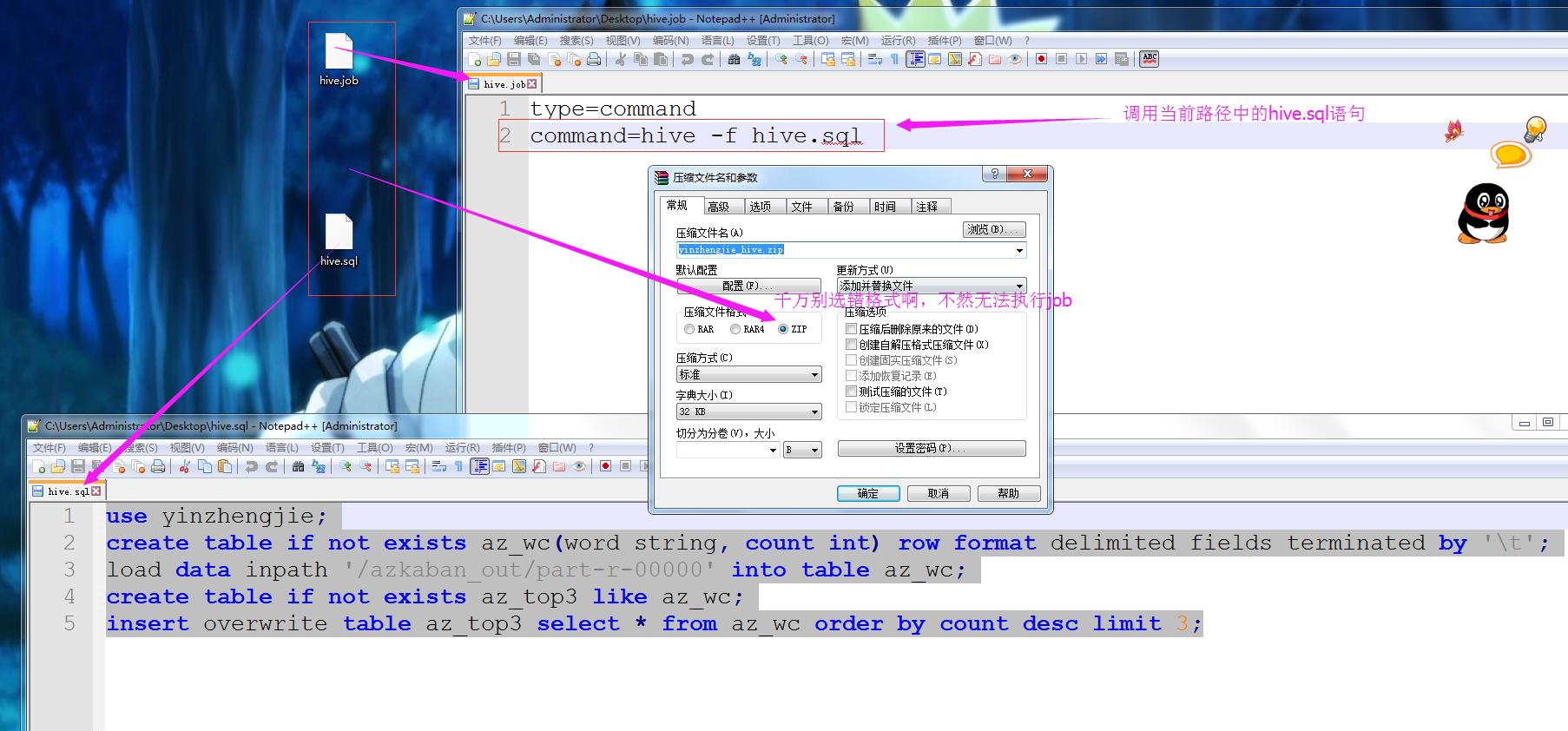
1>.创建job文件


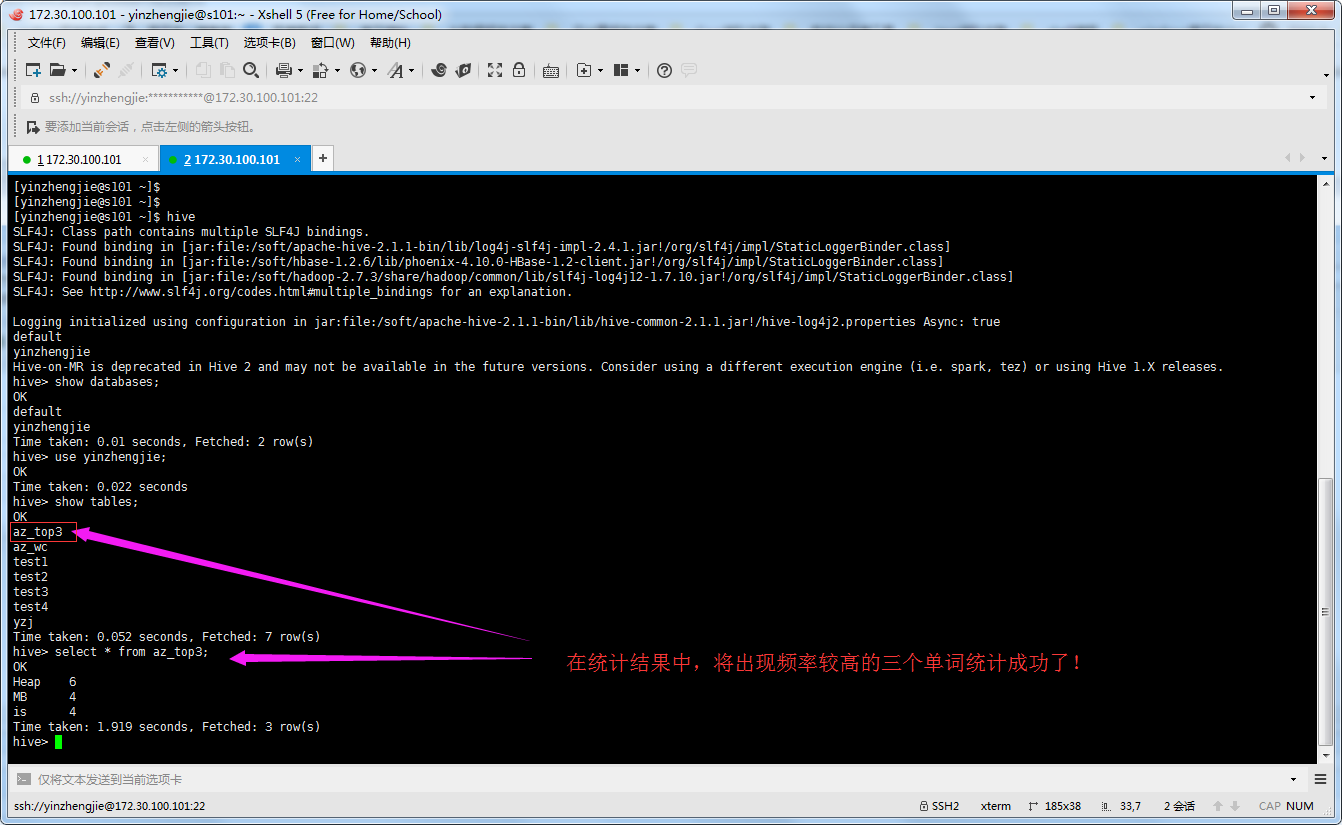
use yinzhengjie; create table if not exists az_wc(word string, count int) row format delimited fields terminated by ' '; load data inpath '/azkaban_out/part-r-00000' into table az_wc; create table if not exists az_top3 like az_wc; insert overwrite table az_top3 select * from az_wc order by count desc limit 3;
type=command
command=hive -f hive.sql
2>.压缩配置文件
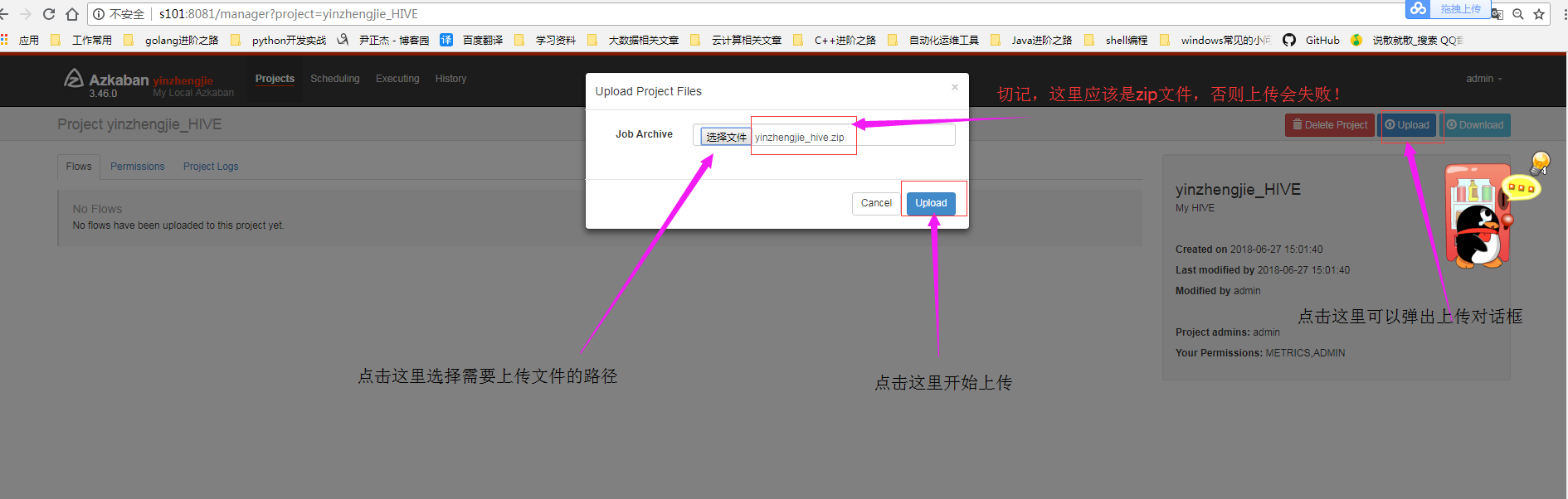
3>.将压缩后的job文件上传到azkaban的WEB界面中
4>.执行hive任务
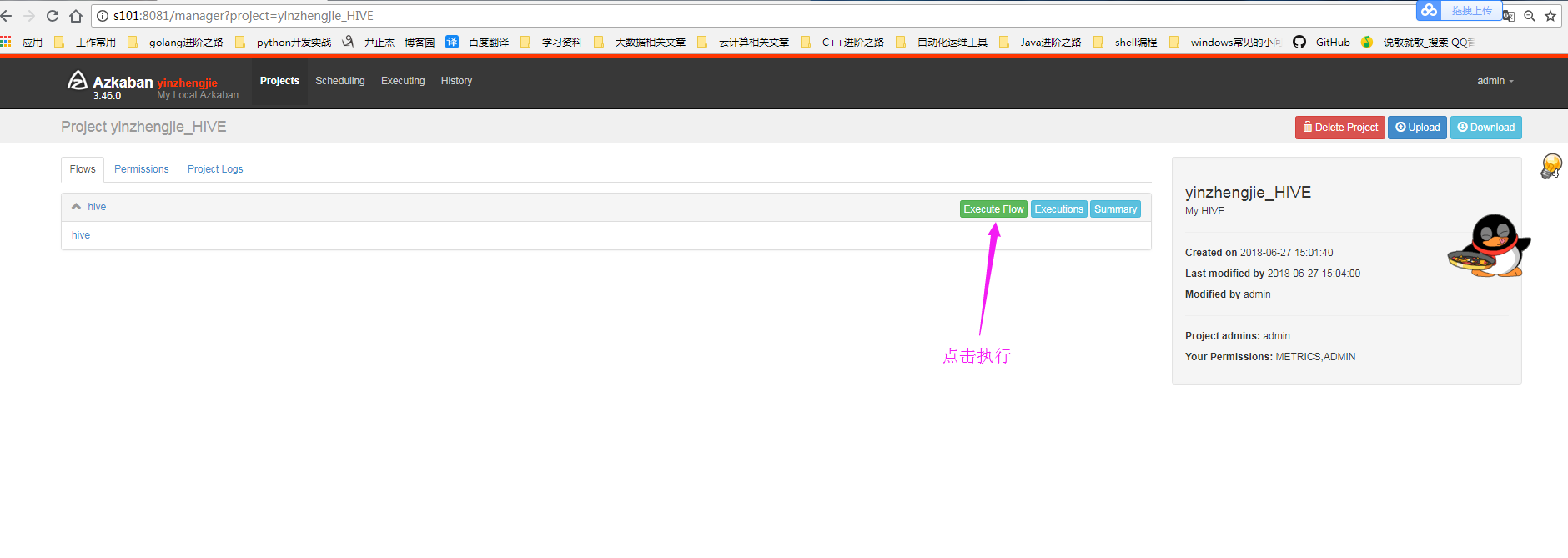
5>.点击Execute
6>.点击继续
7>.等待执行结束
8>.查看执行状态
9>. 任务执行成功
10>.登录到hive服务器中,查看是否成功将数据导入到hive中