Hadoop基础--统计商家id的标签数案例分析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.项目需求
将“temptags.txt”中的数据进行分析,统计出商家id的评论标签数量,由于博客园无法上传大文件的文本,因此我把该文本的内容放在博客园的另一个链接了(需要的戳我),如果网页打不开的话也就可以去百度云盘里下载副本,链接:https://pan.baidu.com/s/1daRiwOVe6ohn42fTv6ysJg 密码:h6er。
实现效果如下:
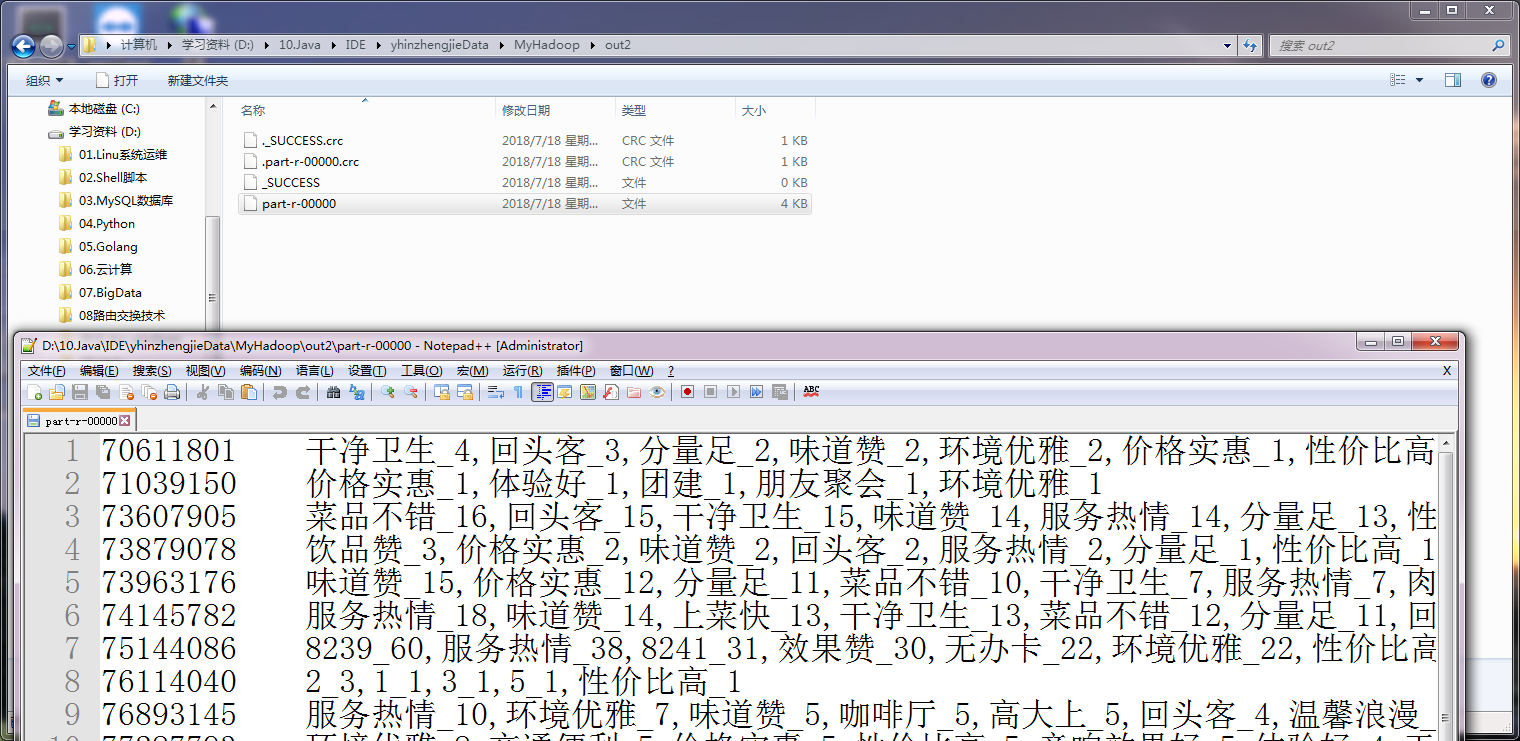
二.代码实现


1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import com.alibaba.fastjson.JSON; 9 import com.alibaba.fastjson.JSONArray; 10 import com.alibaba.fastjson.JSONObject; 11 12 import java.util.ArrayList; 13 import java.util.List; 14 15 public class Util { 16 public static List<String> taggen(String comment){ 17 //解析传进来的字符串 18 JSONObject jo = JSON.parseObject(comment); 19 //拿到包含商家评论的相关的标签 20 JSONArray jArray = jo.getJSONArray("extInfoList"); 21 //过滤掉不含商家评论的标签 22 if(jArray != null && jArray.size() != 0){ 23 //定义一个空的有序集合 24 List<String> list = new ArrayList<String>(); 25 //通过jArray得到第一个json串,作为json对象 26 JSONObject jo2 = jArray.getJSONObject(0); 27 //进一步拿到商家评论的相关的标签 28 JSONArray jArray2 = jo2.getJSONArray("values"); 29 //进一步过滤掉不含商家评论的标签 30 if(jArray2 != null && jArray2.size() != 0){ 31 for (Object obj : jArray2) { 32 //将商检评论的标签添加到我们定义的集合中 33 list.add(obj.toString()); 34 } 35 return list; 36 } 37 } 38 return null; 39 } 40 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.io.WritableComparable; 9 import java.io.DataInput; 10 import java.io.DataOutput; 11 import java.io.IOException; 12 13 public class TagBean implements WritableComparable<TagBean> { 14 private String tag; 15 private int count; 16 17 /** 18 * compareTo() 方法用于将 Number 对象与方法的参数进行比较。可用于比较 Byte, Long, Integer等。 19 * 该方法用于两个相同数据类型的比较,两个不同类型的数据不能用此方法来比较。 20 */ 21 public int compareTo(TagBean o) { 22 if(o.count == this.count){ 23 return this.getTag().compareTo(o.getTag()); 24 } 25 return o.count - this.count; 26 } 27 28 public void write(DataOutput out) throws IOException { 29 out.writeUTF(tag); 30 out.writeInt(count); 31 } 32 public void readFields(DataInput in) throws IOException { 33 tag = in.readUTF(); 34 count = in.readInt(); 35 } 36 public String getTag() { 37 return tag; 38 } 39 public void setTag(String tag) { 40 this.tag = tag; 41 } 42 public int getCount() { 43 return count; 44 } 45 public void setCount(int count) { 46 this.count = count; 47 } 48 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 13 import java.io.IOException; 14 import java.util.List; 15 16 public class TaggenMapper extends Mapper<LongWritable,Text,Text,IntWritable> { 17 18 /** 19 * 20 * @param key //这是读取行的偏移量 21 * @param value //这是这是的数据,每条数据格式都类似,比如:70611801 {"reviewPics":null,"extInfoList":null,"expenseList":null,"reviewIndexes":[1,2],"scoreList":[{"score":4,"title":"环境","desc":""},{"score":5,"title":"服务","desc":""},{"score":4,"title":"口味","desc":""}]} 22 * @param context 23 */ 24 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 25 String line = value.toString(); 26 String[] arr = line.split(" "); 27 String id = arr[0]; 28 String json = arr[1]; 29 //我们对数据进行解析,把用户评论的标签数都整合起来,用tags变量来接受数据 30 List<String> tags = Util.taggen(json); 31 //如果tags没数据,则不写入 32 if(tags != null && tags.size() != 0){ 33 for(String tag : tags){ 34 //给数据打标签,最终结果类似于 : 70611801_价格实惠 35 String compKey = id+ "_"+ tag; 36 context.write(new Text(compKey), new IntWritable(1)); 37 } 38 } 39 } 40 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 import java.io.IOException; 13 14 public class TaggenReducer extends Reducer<Text, IntWritable , Text, IntWritable> { 15 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 16 Integer sum = 0; 17 for(IntWritable value : values){ 18 sum += value.get(); 19 } 20 context.write(key, new IntWritable(sum)); 21 } 22 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Mapper; 10 11 import java.io.IOException; 12 13 public class TaggenMapper2 extends Mapper<Text,Text, Text,Text> { 14 15 16 //89223651_价格实惠 8 17 @Override 18 protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { 19 20 //此时的key其实就是上一个MapReduce的结果,比如:70611801_价格实惠 21 String compkey = key.toString(); 22 //我们将结果进行拆分,取出来id,比如 : 70611801 23 String id = compkey.split("_")[0]; 24 //我们将结果进行拆分,取出来tag,比如 : 价格实惠 25 String tag = compkey.split("_")[1]; 26 //此时的value的值其实就是对key的一个计数 : 比如key出现的次数为8 27 String sum = value.toString(); 28 //这个时候我们就是将tag和之前的value进行拼接,得出结果如下 : 价格实惠_8 29 String newVal = tag + "_" + sum; 30 //最后将我们重写组合的key和value重新分发给reduce 31 context.write(new Text(id), new Text(newVal)); 32 } 33 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Reducer; 10 11 import java.io.IOException; 12 import java.util.TreeSet; 13 14 public class TaggenReducer2 extends Reducer<Text,Text,Text,Text> { 15 16 protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 17 //使用TreeSet的目的是实现去重并排序 18 TreeSet<TagBean> ts = new TreeSet<TagBean>(); 19 //迭代value,并将其放入treeSet,而TreeSet使用的排序是自定义(TagBean)的。 20 for(Text value:values){ 21 String[] arr = value.toString().split("_"); 22 String tag = arr[0]; 23 int count = Integer.parseInt(arr[1]); 24 TagBean tagBean = new TagBean(); 25 tagBean.setTag(tag); 26 tagBean.setCount(count); 27 ts.add(tagBean); 28 } 29 //迭代TreeSet中的TagBean,并得到tag和count,放进StringBuffer 30 StringBuffer sb = new StringBuffer(); 31 for (TagBean tb : ts) { 32 String tag = tb.getTag(); 33 int count = tb.getCount(); 34 String val = tag+"_"+count; 35 sb.append(val+ ","); 36 } 37 String newVal = sb.toString().substring(0, sb.length() -1); 38 //经过上面的整理,可以把同一个商家id的所有标签整个到一起,最终发送出去FileOutputFormat,最终格式为类型如 : 83084036 价格实惠_1,干净卫生_1 39 context.write(key,new Text(newVal)); 40 //TreeSet置空 41 ts.clear(); 42 //StringBuffer置空 43 sb.setLength(0); 44 } 45 }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.taggen; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 18 public class TaggenApp { 19 20 public static void main(String[] args) throws Exception { 21 Configuration conf = new Configuration(); 22 conf.set("fs.defaultFS","file:///"); 23 FileSystem fs = FileSystem.get(conf); 24 Job job = Job.getInstance(conf); 25 job.setJobName("taggen"); 26 job.setJarByClass(TaggenApp.class); 27 job.setMapperClass(TaggenMapper.class); 28 job.setReducerClass(TaggenReducer.class); 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(IntWritable.class); 31 Path outPath = new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\out"); 32 if(fs.exists(outPath)){ 33 fs.delete(outPath,true); 34 } 35 FileInputFormat.addInputPath(job,new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\temptags.txt")); 36 FileOutputFormat.setOutputPath(job,outPath); 37 if(job.waitForCompletion(true)){ 38 Job job2 = Job.getInstance(conf); 39 job2.setJobName("taggen2"); 40 job2.setJarByClass(TaggenApp.class); 41 job2.setMapperClass(TaggenMapper2.class); 42 job2.setReducerClass(TaggenReducer2.class); 43 job2.setOutputKeyClass(Text.class); 44 job2.setOutputValueClass(Text.class); 45 job2.setInputFormatClass(KeyValueTextInputFormat.class); 46 Path outPath2 = new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\out2"); 47 if(fs.exists(outPath2)){ 48 fs.delete(outPath2,true); 49 } 50 FileInputFormat.addInputPath(job2,outPath); 51 FileOutputFormat.setOutputPath(job2,outPath2); 52 job2.waitForCompletion(true); 53 } 54 } 55 }