Hadoop基础-Hdfs各个组件的运行原理介绍
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.NameNode工作原理(默认端口号:50070)
1>.什么是NameNode
NameNode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。NameNode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息在系统启动时由数据节点重建。
2>.Name启动流程
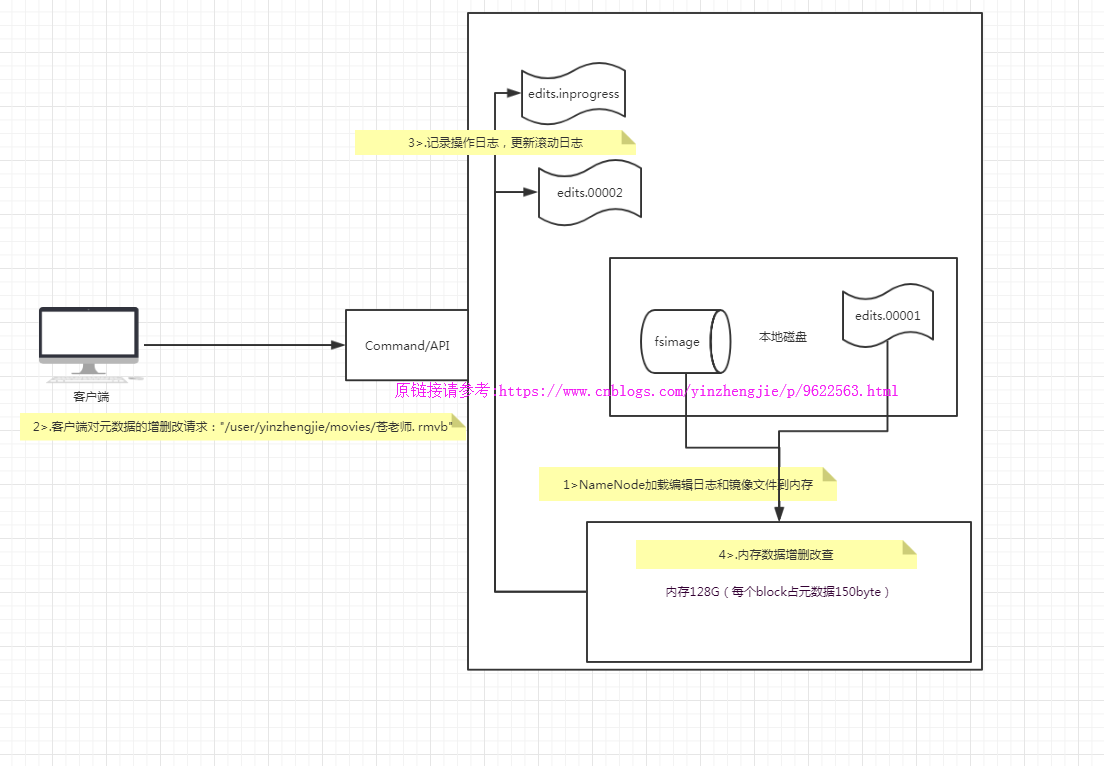
NameNode职责: 1>.负责客户端请求的响应 2>.元数据的管理(查询,修改) NameNode对数据的管理采用了三种存储形式: 1>.内存元数据(NameSystem) 2>.磁盘元数据镜像文件 3>.数据操作日志文件(可通过日志运算出元数据) 元数据存储机制: 1>.内存中有一份完整的元数据(内存meta data) 2>.磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中) 3>.用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件) NameNode启动流程概述: 1>.第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。 2>.客户端对元数据进行增删改的请求 3>.NameNode记录操作日志,更新滚动日志。 4>.namenode在内存中对数据进行增删改查 在NameNode端的工作流程如下: 1>.Namenode始终在内存中保存metedata,用于处理“读请求” 到有“写请求”到来时,namenode会首先写edits到磁盘,即向edits文件中写日志,当客户端操作成功后,相应的元数据会更新到内存matedata中,并且向客户端返回. 2>.Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。 查看namenode版本号 1>.在/home/yinzhengjie/data/hadoop/hdfs/ha/dfs/name1/current这个目录下查看VERSION文件, [yinzhengjie@s101 ~]$ cat /home/yinzhengjie/data/hadoop/hdfs/ha/dfs/name1/current/VERSION #Mon Aug 13 14:45:15 EDT 2018 namespaceID=1555352651 clusterID=CID-58730c19-c019-4f4c-97f1-0eb80eab6071 cTime=0 storageType=NAME_NODE blockpoolID=BP-1140132172-172.30.1.101-1534178655035 layoutVersion=-63 [yinzhengjie@s101 ~]$ 2>.namenode版本号具体解释 2.1>.namespaceID在HDFS上,会有多个Namenode,所以不同Namenode的namespaceID是不同的,分别管理一组blockpoolID。 2.2>.clusterID集群id,全局唯一 2.3>.cTime属性标记了namenode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。 2.4>.storageType属性说明该存储目录包含的是namenode的数据结构。 2.5>.blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。 2.6>.layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。 namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。具体配置如下: [hdfs-site.xml] <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value> <--注意,这个值咱们也可以写绝对路径,我测试过好使!--> </property>
3>.NameNode注意事项
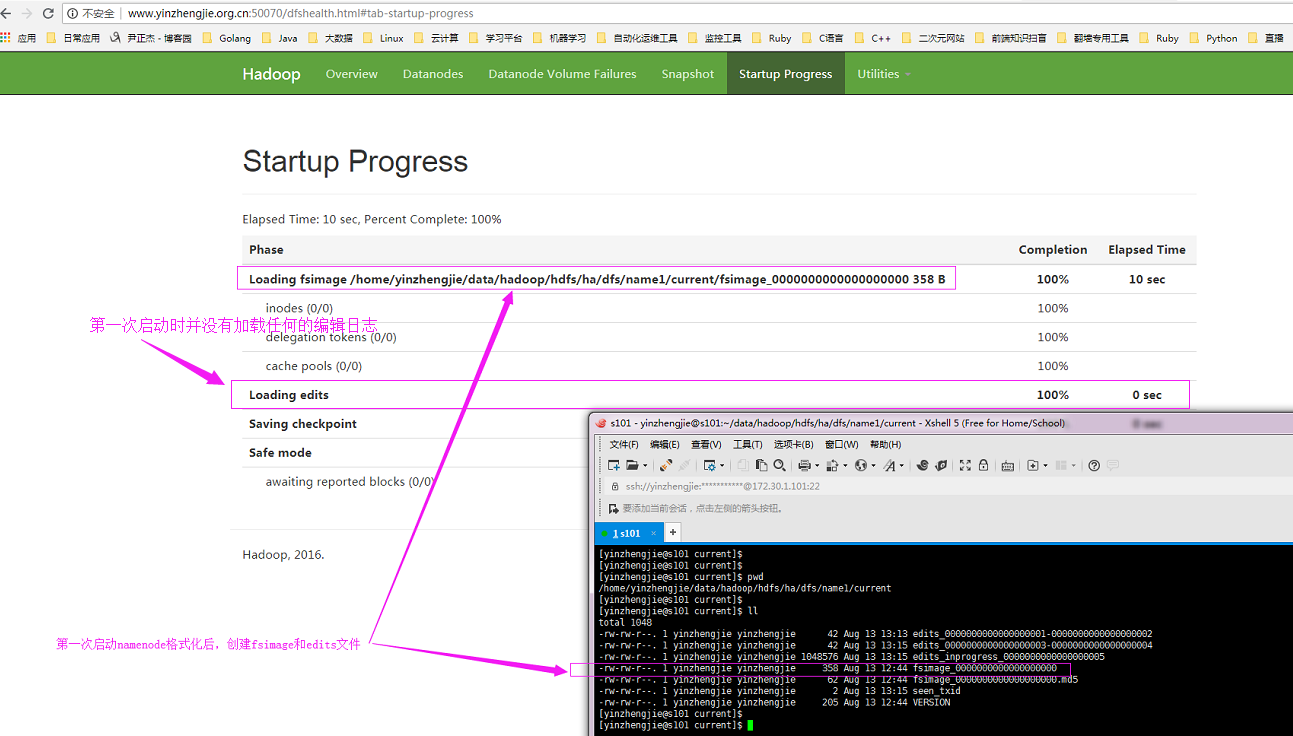
第一:如下图所示,第一次启动namenode格式化后,创建fsimage和edits文件
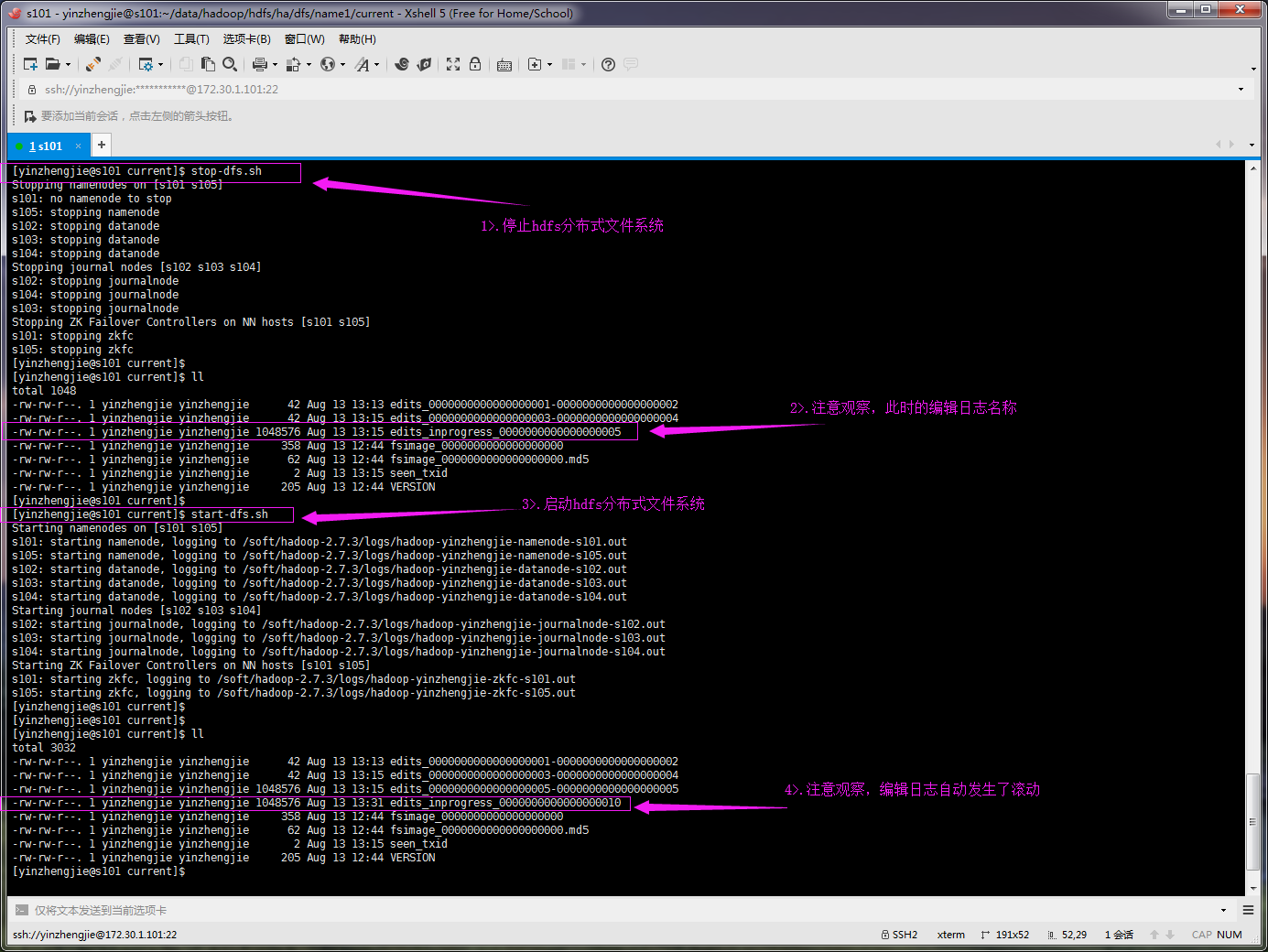
第二:重启hdfs分布式文件系统时,默认会自动滚动编辑日志,如下图所示:
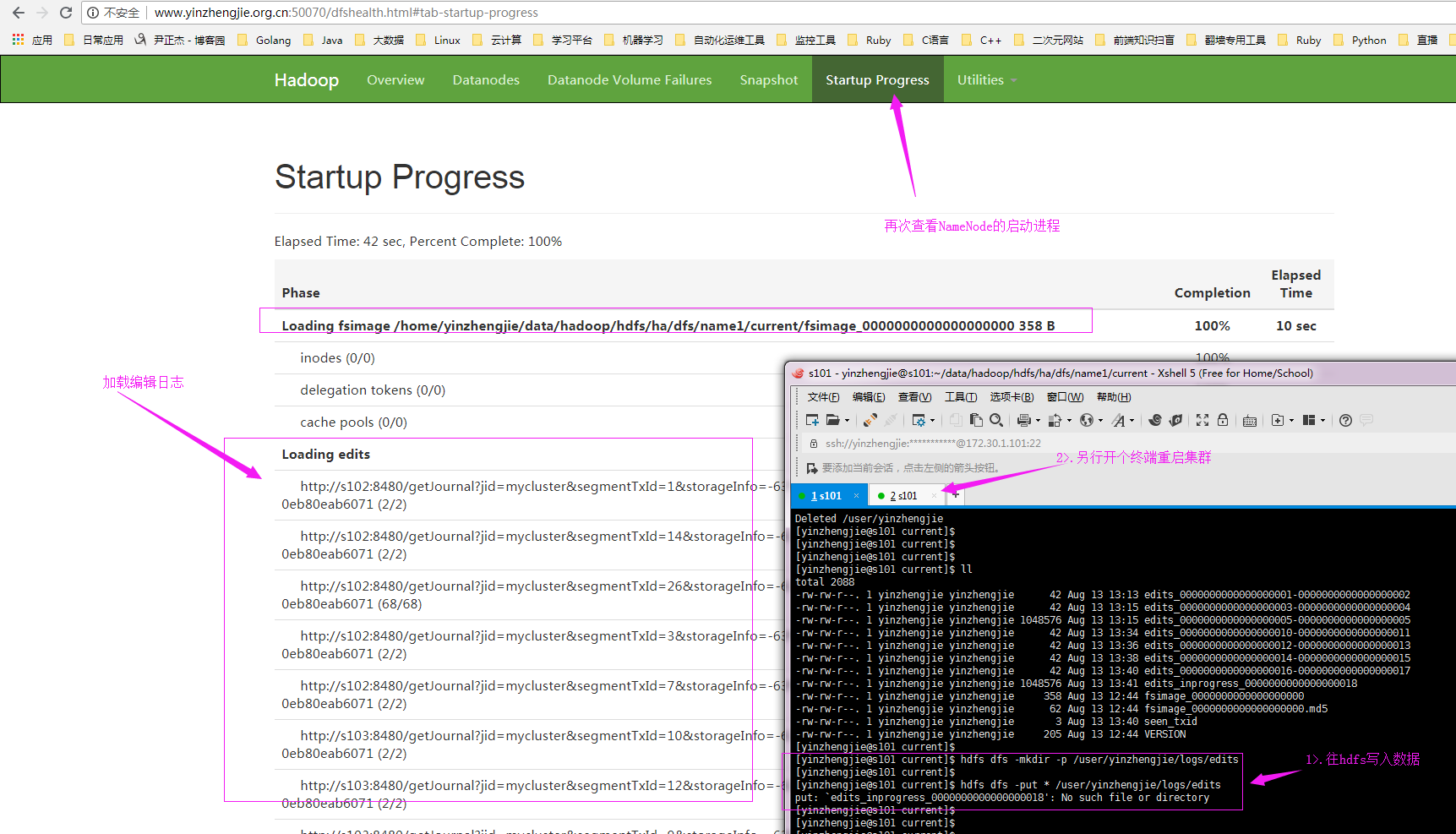
第三:如果不是第一次启动,直接加载编辑日志和镜像文件到内存,如下图所示:
想要了解更多关于镜像文件和编辑日志信息,可参考:https://www.cnblogs.com/yinzhengjie/p/9098092.html。
二.SecondaryNameNode工作原理(默认端口号:50090)
1>.什么是SecondaryNameNode
它是辅助namenode的进程,Secondary NameNode,为主namenode内存中的文件系统元数据创建检查点,Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。
2>.SecondaryNameNode有两个作用
2.1>.镜像备份,即备份fsimage(fsimage是元数据发送检查点时写入文件);
2.2>.日志与镜像的定期合并。简单的说是将Namenode中edits日志和fsimage合并,防止如果Namenode节点故障,namenode下次启动的时候,会把fsimage加载到内存中,应用edits log,edits log往往很大,导致操作往往很耗时。(这也是namenode容错的一套机制)
以上两个过程同时进行,称为checkpoint(检查点)。
3>.NameNode+SecondaryNameNode的工作原理
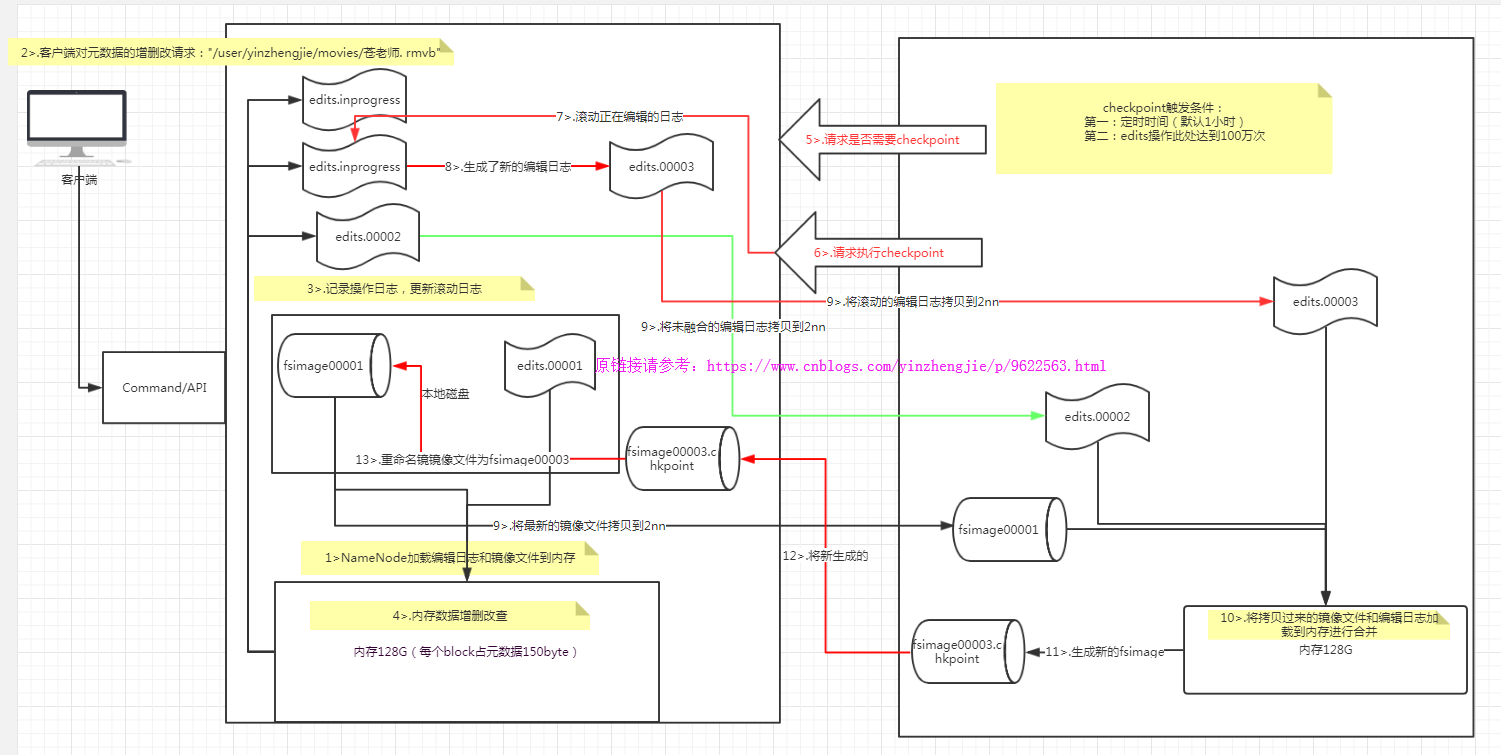
第一阶段:NameNode启动 1>.第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。 2>.客户端对元数据进行增删改的请求 3>.NameNode记录操作日志,更新滚动日志。 4>.NameNode在内存中对数据进行增删改查 第二阶段:Secondary NameNode工作 1>.Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。 2>.Secondary NameNode请求执行checkpoint。 3>.NameNode滚动正在写的edits日志 4>.将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode 5>.Secondary NameNode加载编辑日志和镜像文件到内存,并合并。 6>.生成新的镜像文件fsimage.chkpoint 7>.拷贝fsimage.chkpoint到NameNode 8>.NameNode将fsimage.chkpoint重新命名成fsimage
检查点和编辑日志存放位置:
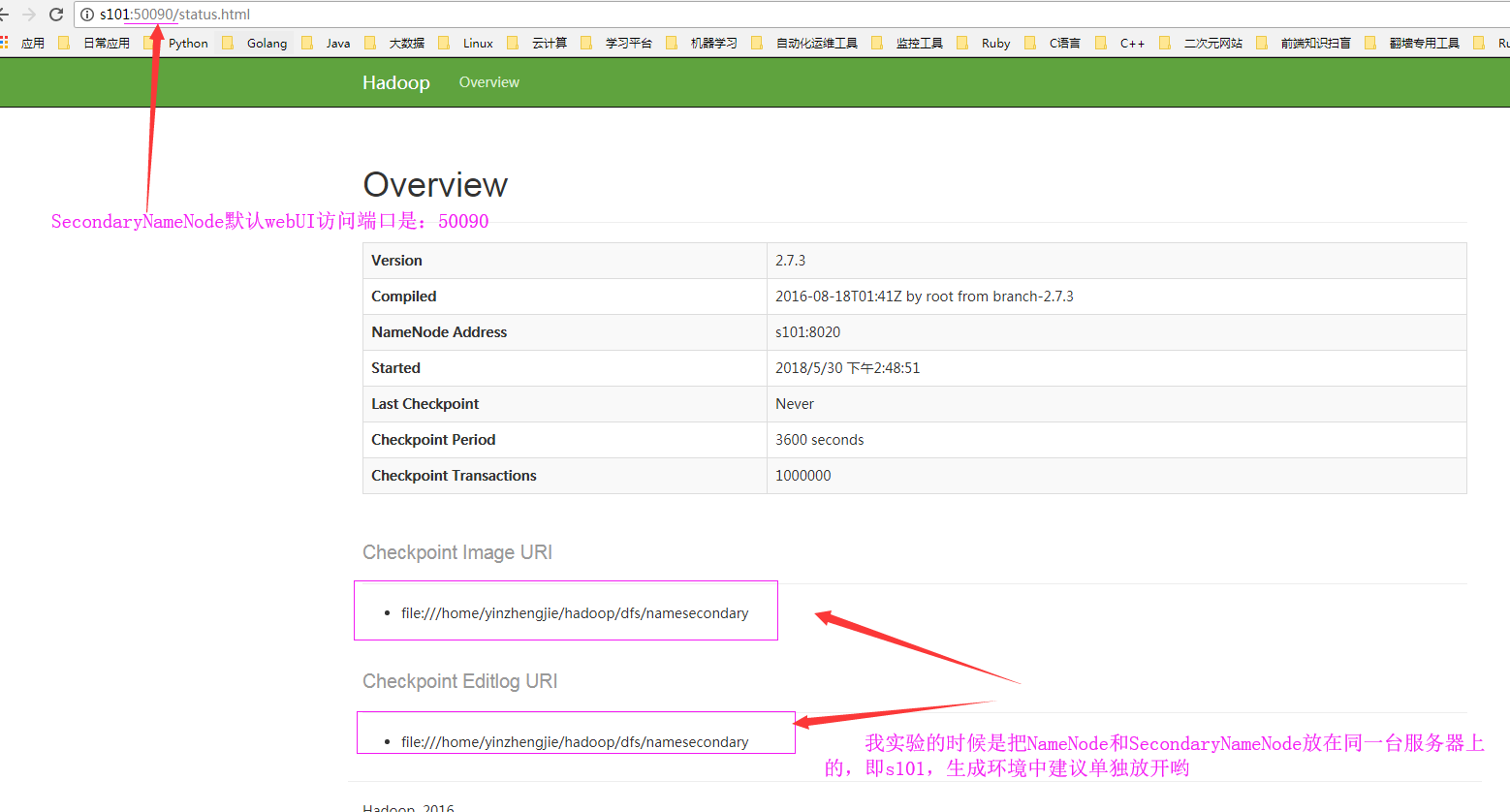
chkpoint检查时间参数设置 1>.通常情况下,SecondaryNameNode每隔一小时执行一次。 [hdfs-default.xml] <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> 2>.一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。 <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60</value> <description> 1分钟检查一次操作次数</description> </property> SecondaryNameNode目录结构 Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。 在/home/yinzhengjie/hadoop-2.7.3/data/hdfs/dfs/namesecondary/current这个目录中查看SecondaryNameNode目录结构。 edits_0000000000000000001-0000000000000000002 fsimage_0000000000000000002 fsimage_0000000000000000002.md5 VERSION SecondaryNameNode的namesecondary/current目录和主namenode的current目录的布局相同。 好处:在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。 方法一:将SecondaryNameNode中数据拷贝到namenode存储数据的目录; 方法二:使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode中数据拷贝到namenode目录中。
三.DataNode工作原理
1>.什么是DataNode
用大白话来说,NameNode用来存储一些元数据信息的,而DataNode却是用来存放真实数据的。
2>.DataNode的工作机制
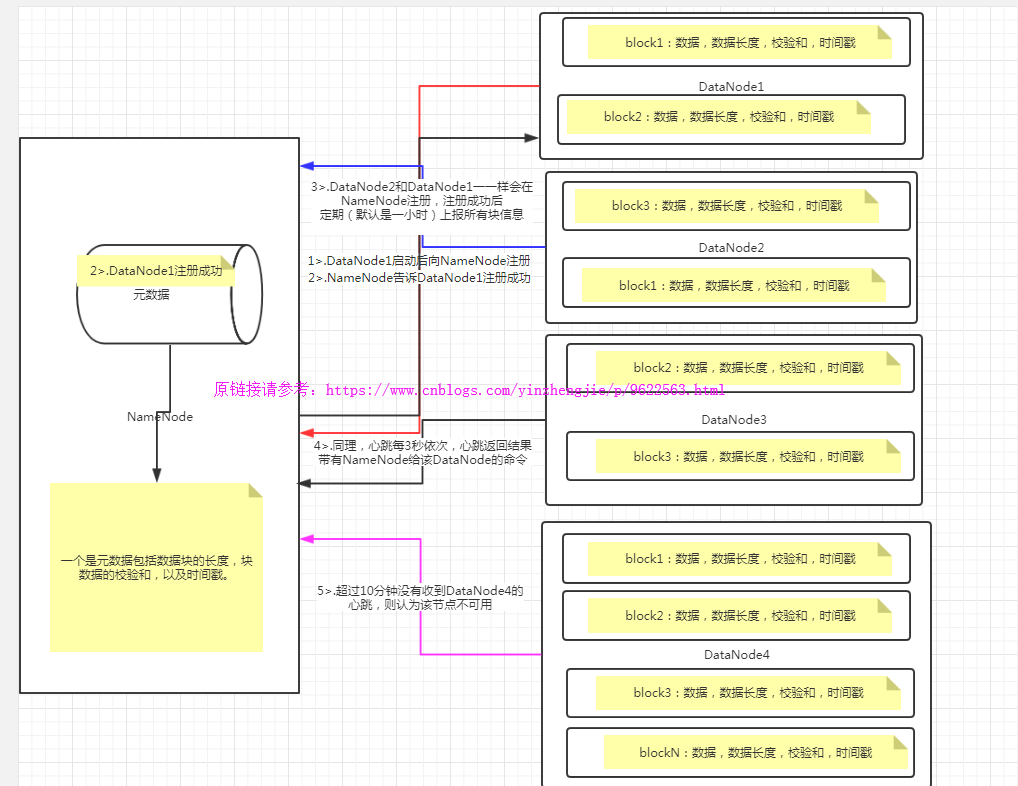
如上图所示,DataNode和NameNode的通信机制如下:
1>.一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2>.DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3>.心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
集群运行中可以安全加入和退出一些机器。这种专业术语叫做集群的服役和退役。关于如何服役和退役详情请参考我之前分享的笔记:https://www.cnblogs.com/yinzhengjie/p/9101070.html
DataNode的校验和是为了保证数据的完整性: 1>.当DataNode读取block的时候,它会计算checksum; 2>.如果计算后的checksum,与block创建时值不一样,说明block已经损坏; 3>.client此时会读取其他DataNode上的block; 4>.datanode在其文件创建后周期验证checksum; 5>.不论数据是否发生改变,DataNode都会定期(默认是一小时)上报数据; 掉线时限参数设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。 而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。 [hdfs-site.xml] <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> datanode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。具体配置如下: [hdfs-site.xml] <property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property>
四.HDFS扫盲(跟你们小伙伴聊天别被他这些简单问题问到了)
1>.请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么?
1>.NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。 2>.SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。 3>.DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。 4>.ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。 5>.NodeManager(TaskTracker)执行任务。 6>.DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。 7>.JournalNode 高可用情况下存放namenode的editlog文件。
2>.
3>.