HDFS的I/O流操作
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
上一篇笔记分享了Hdfs已经封装好的API,其实我们还可以采用IO流的方式实现数据的上传和下载。
一.利用IO流实现文件的上传
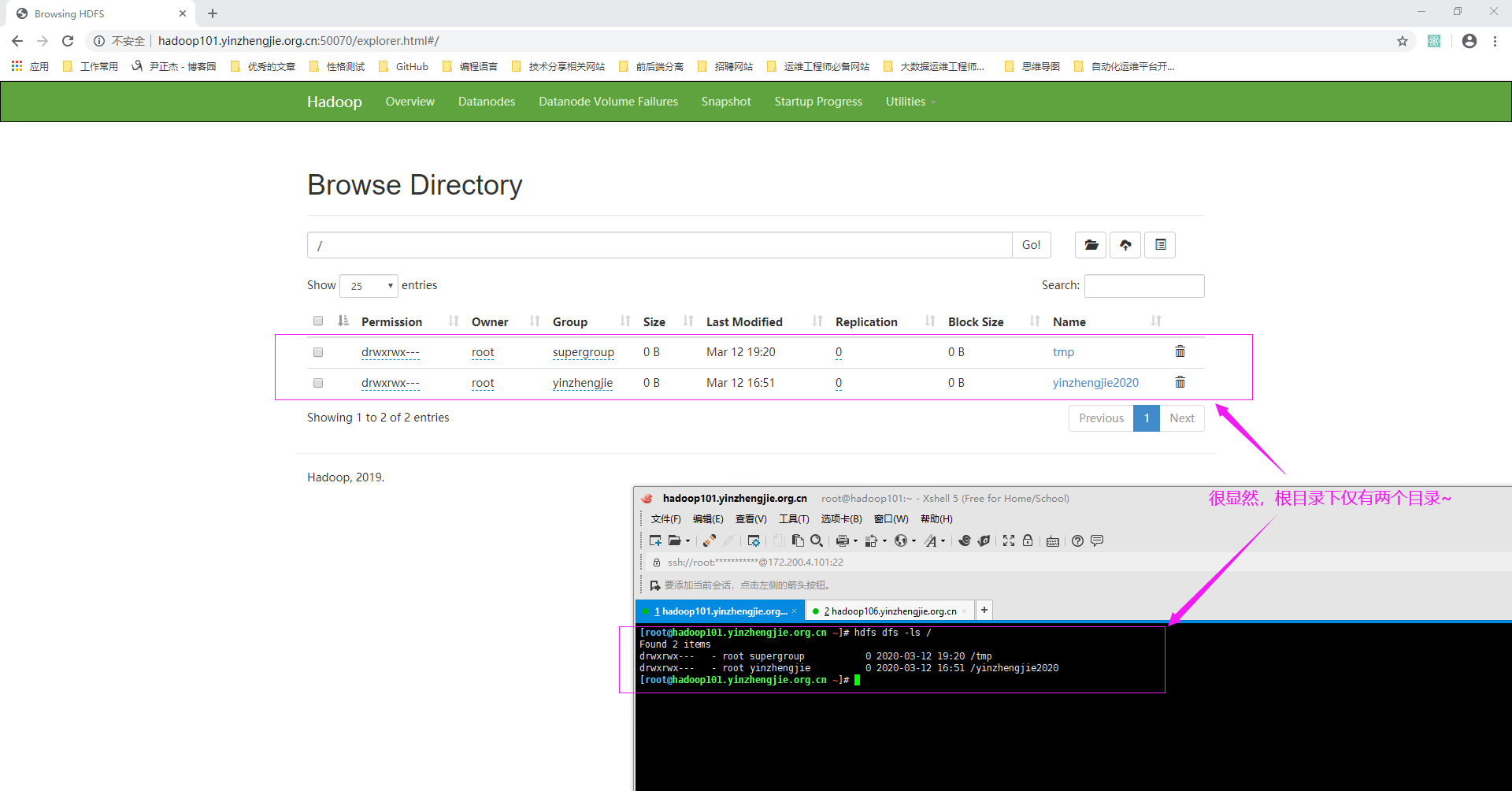
1>.查看NameNode的WebUI
2>.JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.Test; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.net.URI; public class HdfsClient8 { @Test public void upload() throws IOException, InterruptedException { //创建配置文件对象 Configuration conf = new Configuration(); //指定上传文件的副本数 conf.setInt("dfs.replication",1); //获取文件系统对象 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),conf,"root"); //创建输入流 FileInputStream fis = new FileInputStream(new File("E:\yinzhengjie\host.log")); //获取输出流 FSDataOutputStream fos = fs.create(new Path("/hosts")); //流对拷 IOUtils.copyBytes(fis,fos,conf); //释放资源 IOUtils.closeStream(fos); IOUtils.closeStream(fis); fs.close(); } }
3>.再次访问NameNode的WebUI

二.利用IO流是实现文件的下载
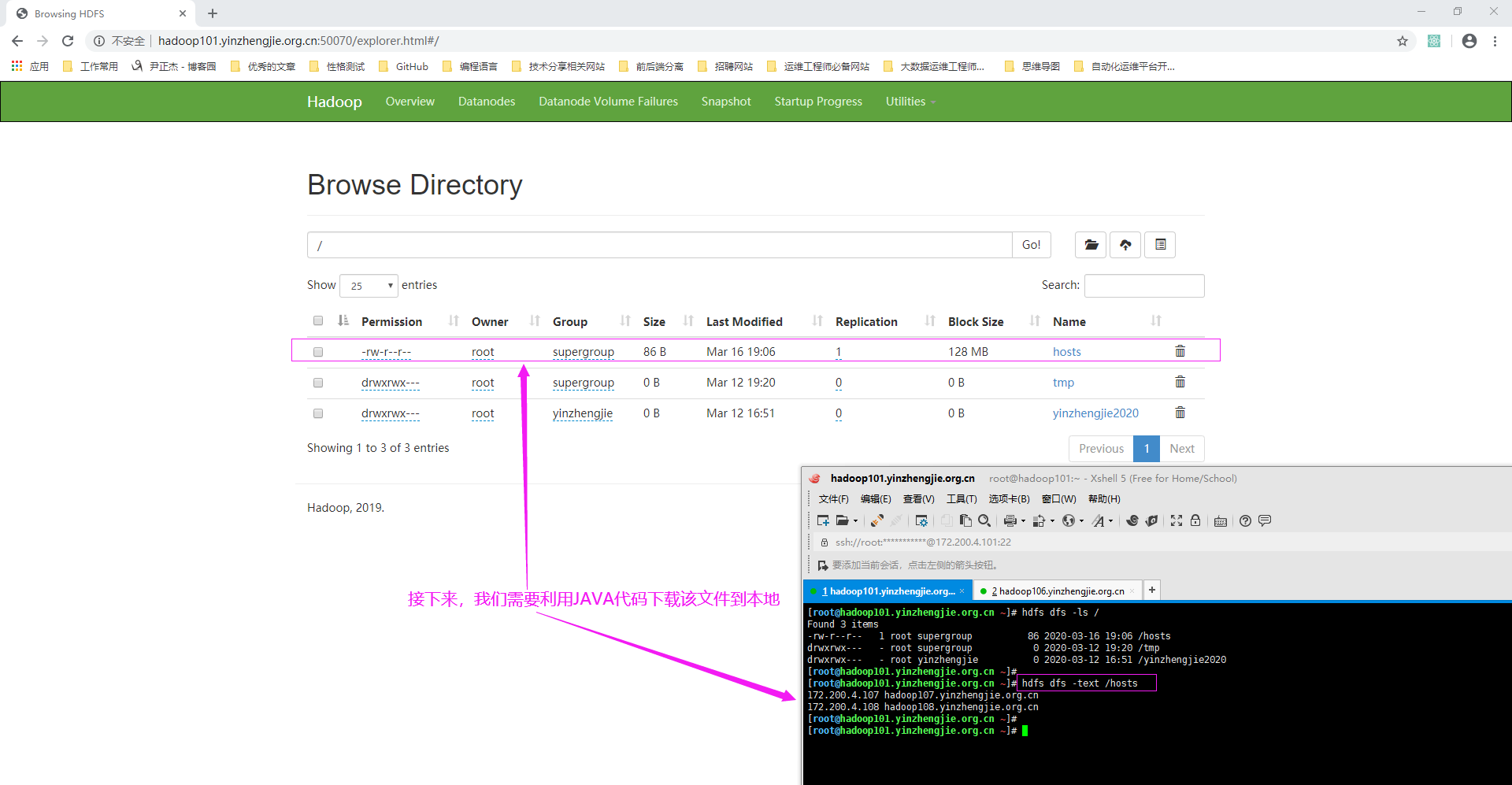
1>.查看NameNode的WebUI
2>.JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.Test; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.net.URI; public class HdfsClient9 { @Test public void download() throws IOException, InterruptedException { //创建配置文件对象 Configuration conf = new Configuration(); //指定上传文件的副本数 conf.setInt("dfs.replication",1); //获取文件系统对象 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),conf,"root"); //获取输入流 FSDataInputStream fis = fs.open(new Path("/hosts")); //获取输出流 FileOutputStream fos = new FileOutputStream(new File("E:\yinzhengjie\myHosts.txt")); //流的对拷 IOUtils.copyBytes(fis,fos,conf); //释放资源 IOUtils.closeStream(fos); IOUtils.closeStream(fis); fs.close(); } }
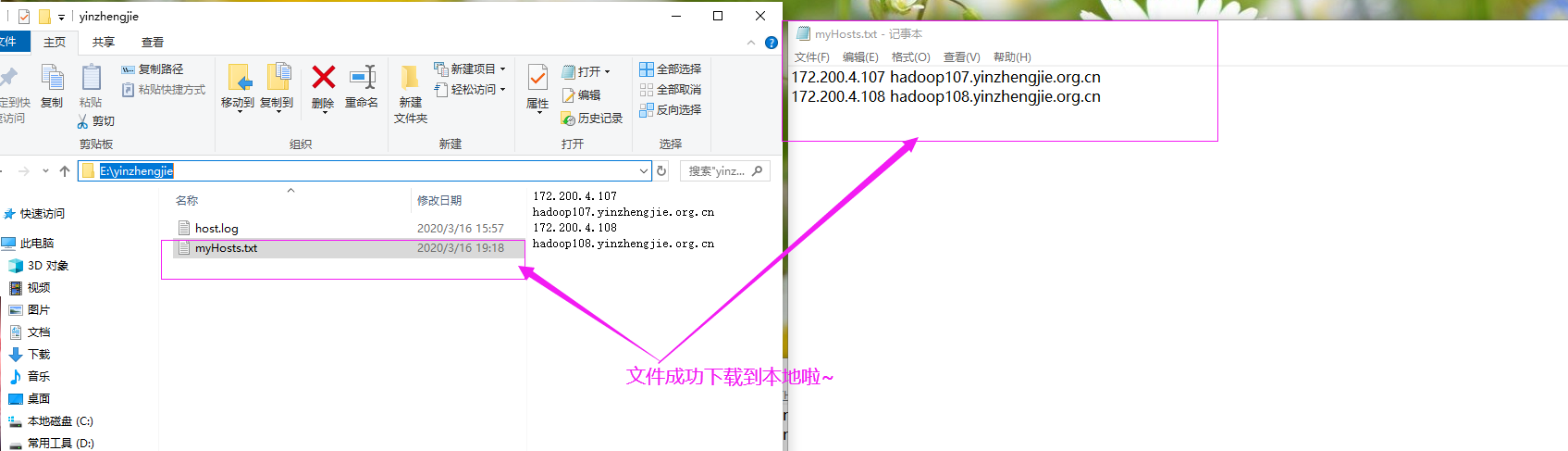
3>.查看下载文件
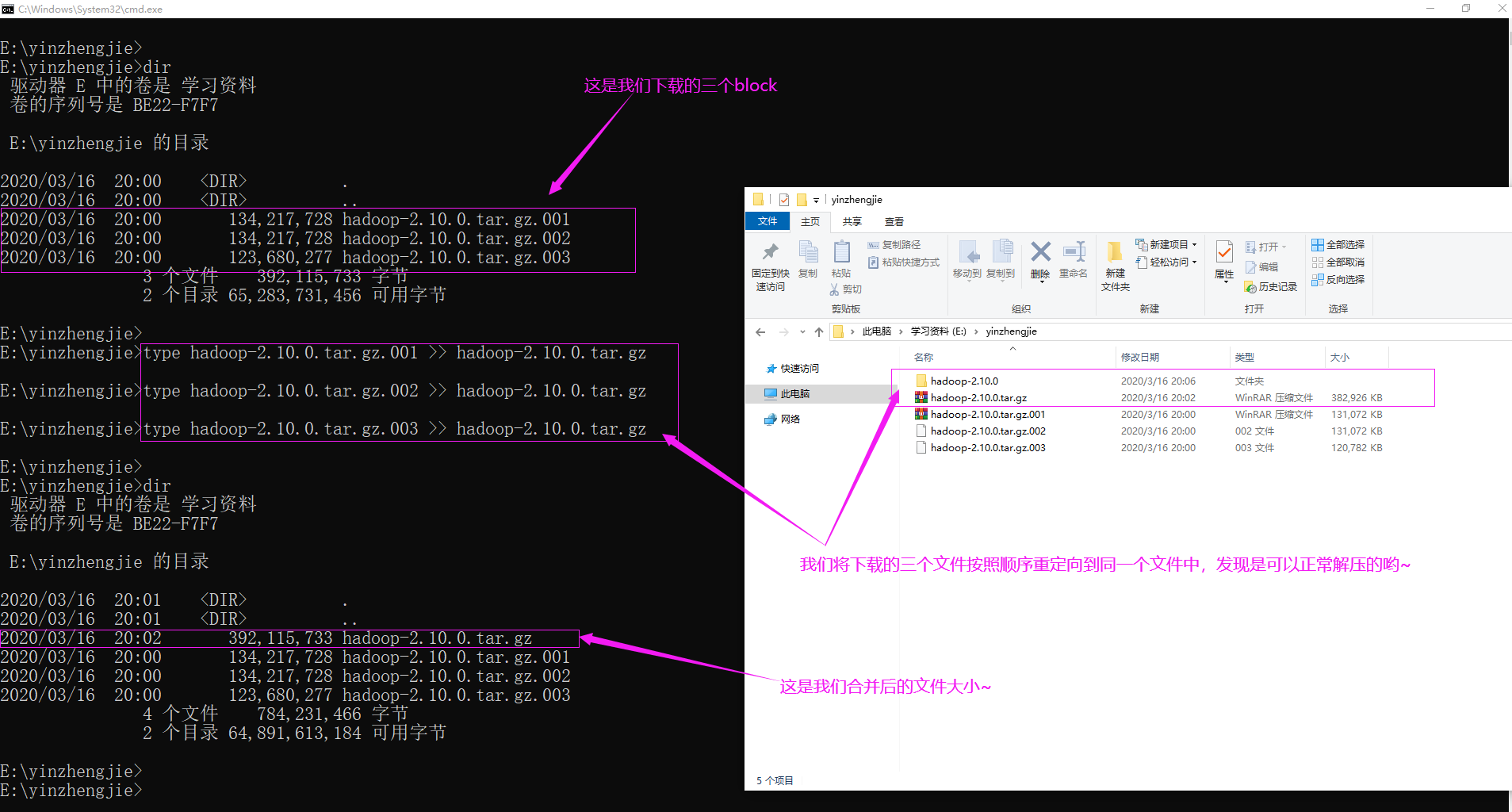
三.定位文件读取案例
1>.查看NameNode的WebUI
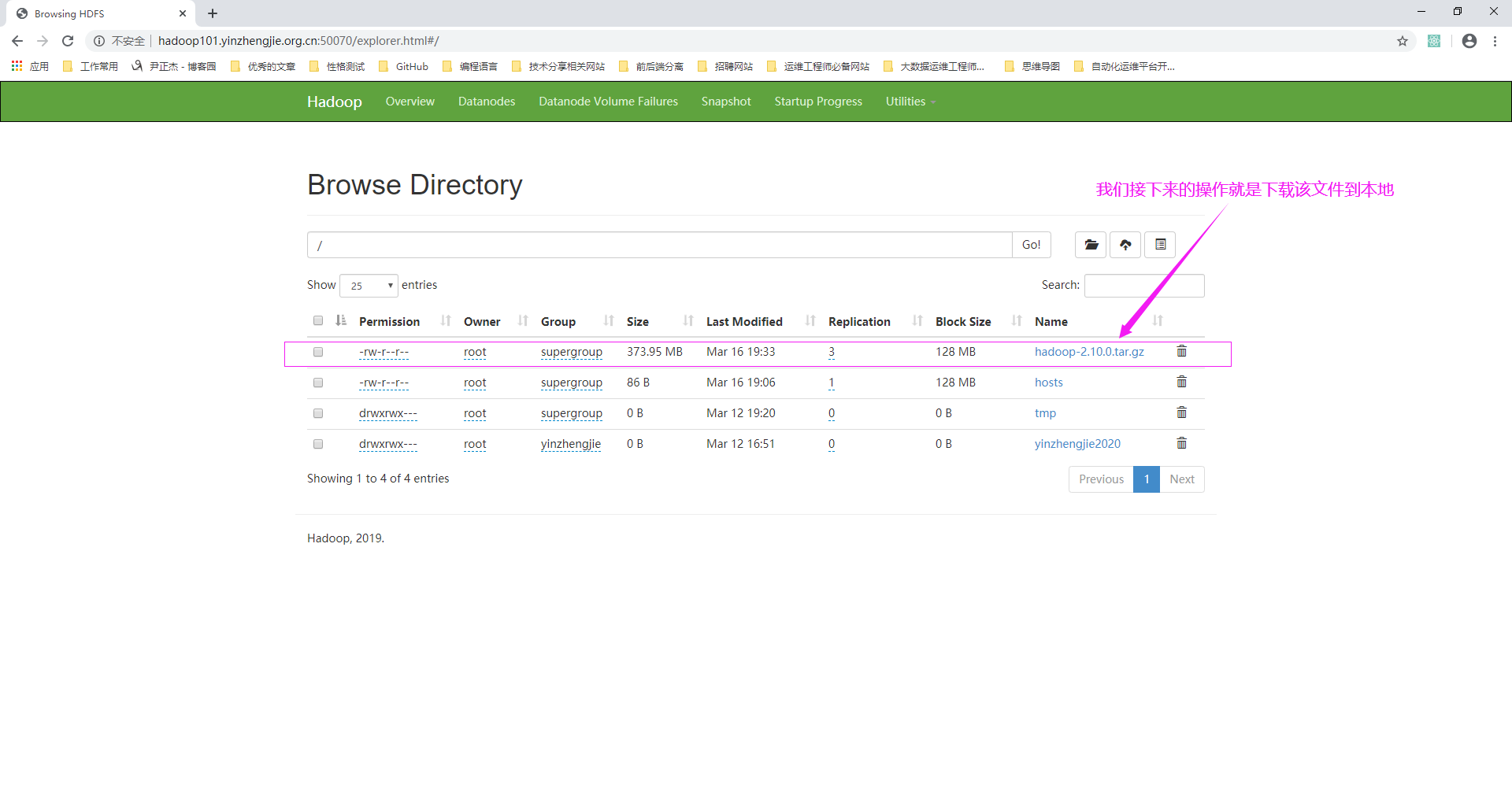
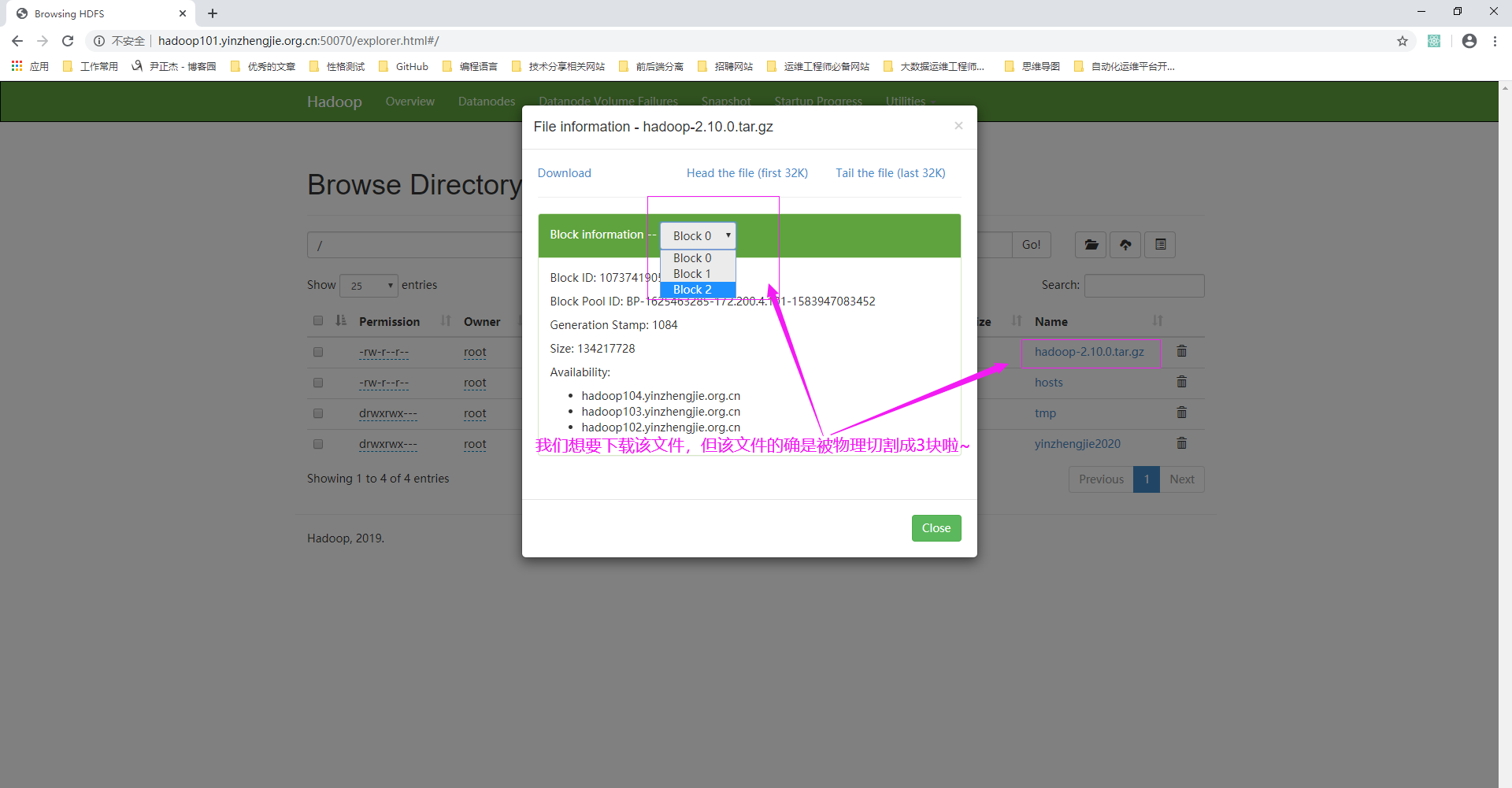
如上图所示,点击该文件可以查看该文件被物理切割成多少块,如下图所示。由于块大小是128,因此373.85被切割成了三块。
2>.JAVA代码
package cn.org.yinzhengjie.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.net.URI; public class HdfsClient10 { public static void main(String[] args) throws Exception { DownLoadFirstBlock(); DownLoadSecondBlock(); DownLoadThirdBlock(); } public static void DownLoadFirstBlock() throws IOException, InterruptedException { //创建配置文件对象 Configuration conf = new Configuration(); //指定上传文件的副本数 conf.setInt("dfs.replication",1); //获取文件系统对象 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),conf,"root"); //获取输入流 FSDataInputStream fis = fs.open(new Path("/hadoop-2.10.0.tar.gz")); //创建输出流 FileOutputStream fos = new FileOutputStream(new File("E:\yinzhengjie\hadoop-2.10.0.tar.gz.001")); //流拷贝 byte[] buf = new byte[1024]; //只拷贝128MB = 1024 * 1024 * 128 for (int i=0;i<1024 * 128;i++){ fis.read(buf); fos.write(buf); } //释放资源 IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); } public static void DownLoadSecondBlock() throws IOException, InterruptedException { //创建配置文件对象 Configuration conf = new Configuration(); //指定上传文件的副本数 conf.setInt("dfs.replication",1); //获取文件系统对象 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),conf,"root"); //获取输入流 FSDataInputStream fis = fs.open(new Path("/hadoop-2.10.0.tar.gz")); //定位输入数据位置,即定位到128MB的位置 fis.seek(1024 * 1024 * 128); //创建输出流 FileOutputStream fos = new FileOutputStream(new File("E:\yinzhengjie\hadoop-2.10.0.tar.gz.002"));//流拷贝 byte[] buf = new byte[1024]; //只拷贝128MB = 1024 * 1024 * 128 for (int i=0;i<1024 * 128;i++){ fis.read(buf); fos.write(buf); } //释放资源 IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); } public static void DownLoadThirdBlock() throws IOException, InterruptedException { //创建配置文件对象 Configuration conf = new Configuration(); //指定上传文件的副本数 conf.setInt("dfs.replication",1); //获取文件系统对象 FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop101.yinzhengjie.org.cn:9000"),conf,"root"); //获取输入流 FSDataInputStream fis = fs.open(new Path("/hadoop-2.10.0.tar.gz")); //定位输入数据位置,即定位到256MB的位置 fis.seek(1024 * 1024 * 128 * 2); //创建输出流 FileOutputStream fos = new FileOutputStream(new File("E:\yinzhengjie\hadoop-2.10.0.tar.gz.003")); //流的对拷 IOUtils.copyBytes(fis,fos,conf); //释放资源 IOUtils.closeStream(fis); IOUtils.closeStream(fos); fs.close(); } }
3>.再次访问NameNode的WebUI