HDFS的数据流之增删改查概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS上传(写入/增)流程
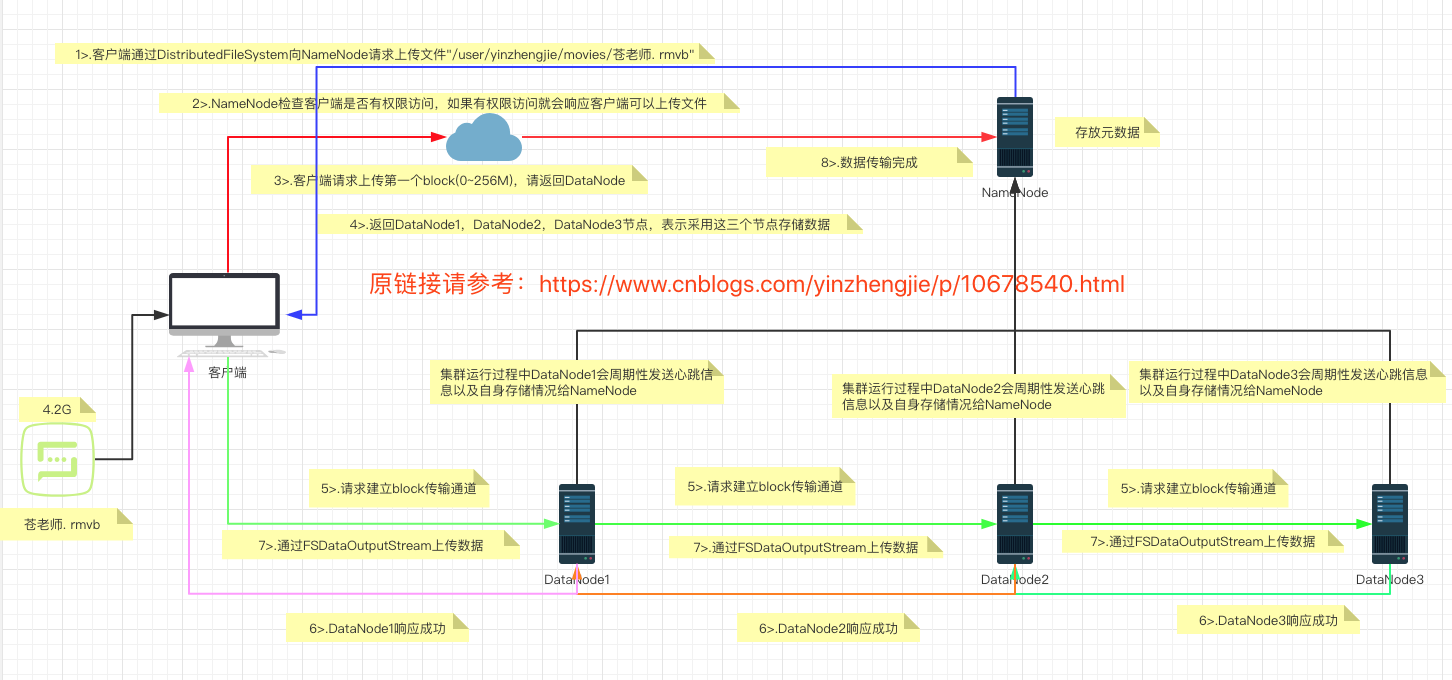
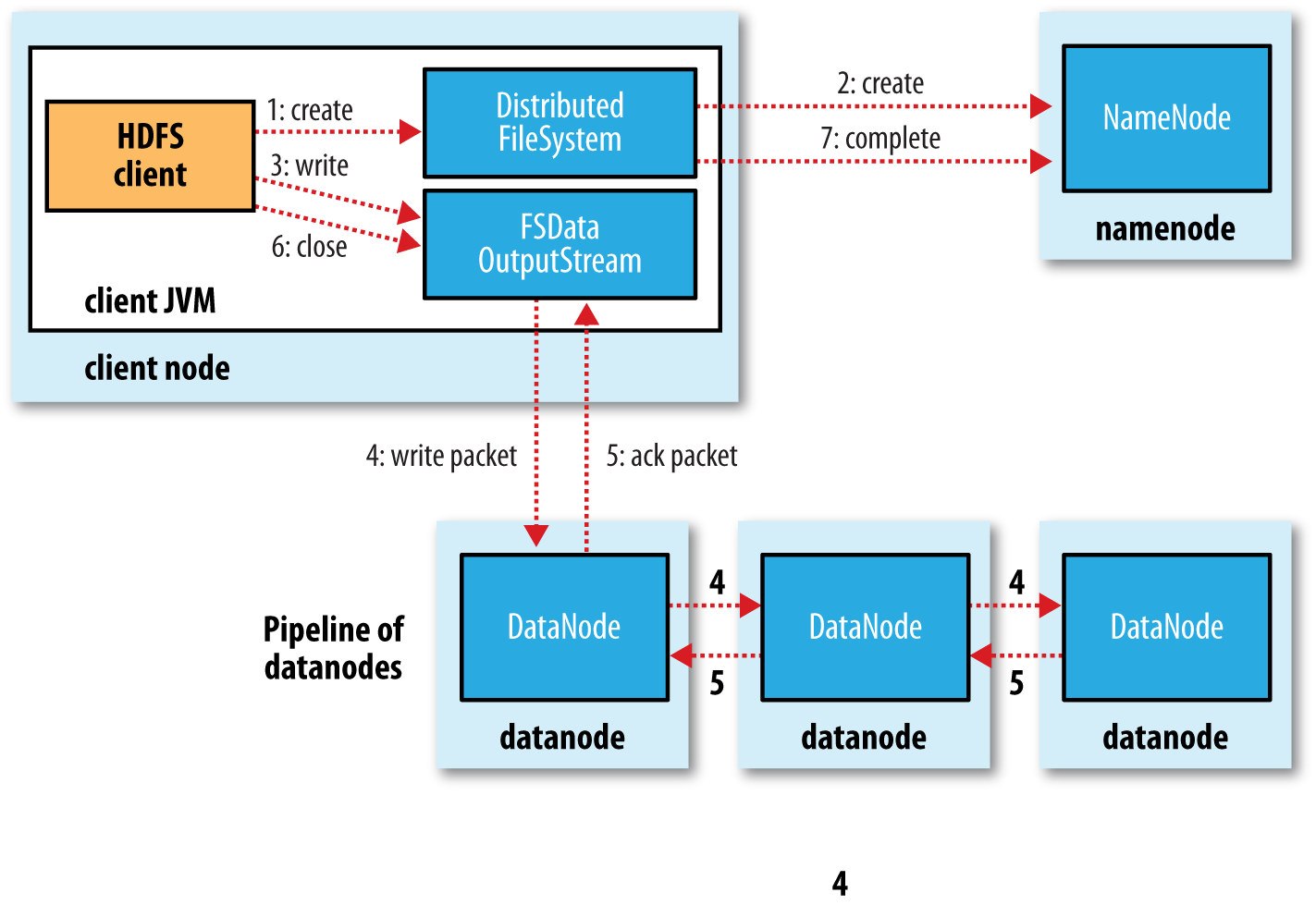
如上图所示,HDFS在做写入文件时流程大概如下所示: 1>.客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode需要验证客户端是否有权限写入,还需要检查目标文件是否已存在,如果是多级目录还需要检查父目录是否存在; 2>.NameNode返回是否可以上传,如果不可以上传(比如没权限或目标文件已经存在),则写入流程到此终止,如果有权限上传,则需要继续执行下面的流程; 3>.客户端此时会开启一个输出流(FSDataOutputStream),于此同时会发起请求上传第一个Block(这个块大小默认是128MB); 4>.NameNode接收到请求后会像客户端返回可以存储数据的DataNode列表,这个DataNode列表的主机数量取决于你设置的集群副本数,若你设置的是默认副本数3个,则会返回三个DataNode主机,比如:["hadoop102.yinzhengjie.org.cn","hadoop103.yinzhengjie.org.cn","hadoop104.yinzhengjie.org.cn"]; 5>.客户端通过输出流(FSDataOutputStream)向最近的一个DataNode节点(比如:"hadoop102.yinzhengjie.org.cn")发起请求建立通道,该节点并不会立即响应客户端,而是会向"hadoop103.yinzhengjie.org.cn"节点发起建立通道的请求,"hadoop103.yinzhengjie.org.cn"接收到"hadoop102.yinzhengjie.org.cn"发来的建立通道请求也不会立即回复,而会向"hadoop104.yinzhengjie.org.cn"发起建立通道请求; 6>."hadoop104.yinzhengjie.org.cn"收到"hadoop103.yinzhengjie.org.cn"发来的请求建立通道时,在正常的情况下,"hadoop104.yinzhengjie.org.cn"会应答"hadoop103.yinzhengjie.org.cn"节点建立通道成功,此时"hadoop103.yinzhengjie.org.cn"收到"hadoop104.yinzhengjie.org.cn"的应答成功消息后会立即响应"hadoop102.yinzhengjie.org.cn"应答成功,最终"hadoop102.yinzhengjie.org.cn"会响应客户端应答成功。这意味着这个"串连"的通道被打通啦; 7>.通道建立成功后,客户端开始往最近的DataNode(比如"hadoop102.yinzhengjie.org.cn")传输Packet(64Kb),"hadoop102.yinzhengjie.org.cn"收到Packet数据是在内存中的,此时它会将内存的数据一边落地,一边将数据发给和"hadoop103.yinzhengjie.org.cn"节点建立的通道,当"hadoop103.yinzhengjie.org.cn"节点收到"hadoop102.yinzhengjie.org.cn"的Packet时,也会一边将数据进行落地,一边将数据发给和"hadoop104.yinzhengjie.org.cn"节点建立的通道。当"hadoop104.yinzhengjie.org.cn"将"hadoop103.yinzhengjie.org.cn"发来的Packet落地后,会返回消息给"hadoop103.yinzhengjie.org.cn"数据写入成功的消息,此时"hadoop103.yinzhengjie.org.cn"接收到"hadoop104.yinzhengjie.org.cn"的数据写入成功的消息后,它还需要等待自己的Packet数据落地成功后,才会将数据落地成功的消息返回给"hadoop102.yinzhengjie.org.cn",同理,当"hadoop102.yinzhengjie.org.cn"收到了"hadoop103.yinzhengjie.org.cn"的消息落地成功后,他也需要将自己的Packet落地成功后参会返回给客户端说它也落地成功。需要注意的是:发送Packet并不是等待所有节点的第一个Packet完全落地以后才会发送第二个Packet,而是将一个块大小拆分成多个Packet以一个队列的形式发送的哟,也就是说每个主机上都维护了一个Packet队列; 8>.当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器,过程就是重复上述步骤。当所有的块传输完毕后,客户端会告诉NameNode数据传输完毕,与此同时会关闭掉输出流(FSDataOutputStream)以释放本地资源,NameNode收到客户端数据传输完毕的消息后,会添加响应的元数据信息; 常见问题刨析: Q1:DFSOutputStream是基于什么为单位上传数据的呢? 答:DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。
Q2:如果建立管道失败意味着什么呢? 答:意味着客户端写入DataNode数据失败了,此时客户端应该会抛出一个异常有关于和DataNode节点建立连接失败的相关信息。
Q3:如果上传数据在和第一个数据节点(DataNode)传输数据失败意味着什么呢? 答:意味着数据传输失败了。
Q4:如果上传数据在和第一个数据节点(DataNode)是正常的,但是在第二个或者第三个数据节点传输数据失败意味着什么呢? 答:如果第一个节点数据写入是正常的,默认情况下,别说后面的两个节点有任意一个挂掉,就算后面的所有DataNode节点同时挂掉,本次写入数据依旧是成功后,只不过此时该数据块只有一个副本,在做心跳信息汇报时NameNode会重新选取2个节点来将该节点的数据同步到其它的两个节点上哟。当然这个功能依赖于dfs.replication.min(默认为1,Hadoop2.9.2版本已经将其更名为dfs.namenode.replication.min)参数,如果你将dfs.namenode.replication.min的数字改为2,那也就意味着如果有三个节点上传数据,你必须得保证前两个数据是写入成功的哟,这个参数我不建议设置过大,设置过大的确可以提升可靠性,但这也降低了可用性。
Q5:每次上传一个新的Block都会创建一个新的输出流(FSDataOutputStream)吗? 答:并不会,在整个上传过程中只有一个输出流(FSDataOutputStream)哟。
Q6:数据被切割成不同的块上传到服务器上,那么问题来了,这个Block到底时NameNode切割的还是DataNode切割的呢?
答:切割块(Block)是客户端完成的操作。
二.HDFS下载(读取/查)流程
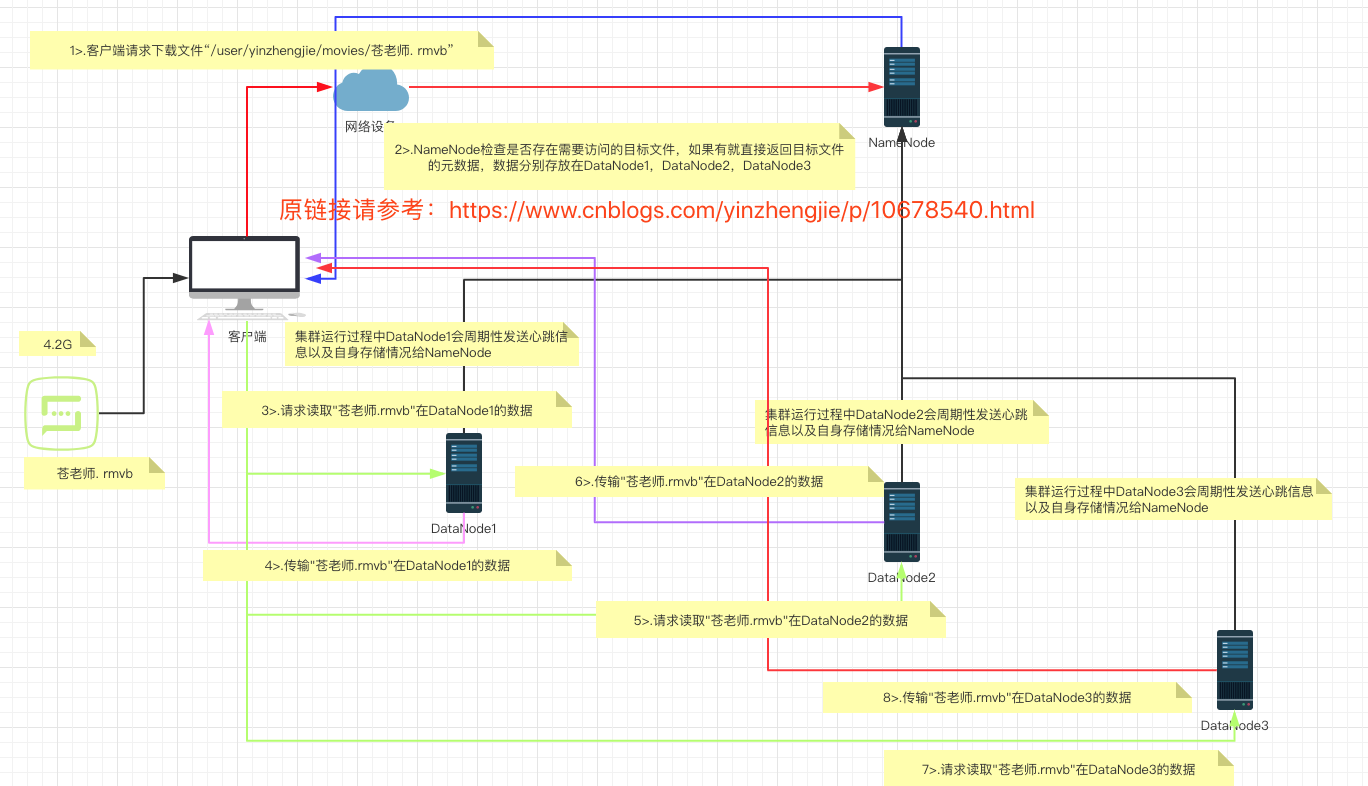
如上图所示,HDFS的读取流程大致如下: 1>.客户端通过Distributed FileSystem(集群的抽象封装)向NameNode请求下载文件; 2>.NameNode通过查询元数据(包括文件所在路径及其权限信息),如果文件不存在直接返回客户端文件不存在,如果文件存在则根据元数据信息判断用户是否有权限读取,如果无权限访问则到此步骤结束,如果有权限访问可以继续下面的步骤; 3>.客户端创建一个输入流(FSDataInputStream)并请求下载第一个Block(块大小默认是128MB); 4>.NameNode返回DataNode的列表; 5>.就近原则挑选一台DataNode服务器(比如"hadoop102.yinzhengjie.org.cn"),请求与这一台DataNode主机建立通道即可; 6>."hadoop102.yinzhengjie.org.cn"主机应答成功后,就开始传输Package给客户端的输入流(FSDataInputStream),最后客户端落地到本地磁盘; 7>.当一个Block传输完成之后,客户端再次请求NameNode下载第二个Block的服务器,过程就是重复上述步骤。
8>.当所有的块传输完毕后,客户端会告诉NameNode数据传输完毕,与此同时会关闭掉输出流(FSDataOutputStream)以释放本地资源,NameNode收到客户端数据传输完毕的消息后,会添加响应的元数据信息。 常见问题刨析: Q1:在下载文件时,客户端还需要和返回的DataNode列表的所有主机建立通道吗? 答:不需要,它只需要和最近一台DataNode主机建立通道完成数据传输即可,如果最近一台DataNode建立通信失败则会随机挑选DataNode列表的主机进行数据传输,如果在此时所有的DataNode均不可访问这意味文件下载失败。 Q2:返回DataNode的列表个数和什么有关? 答:这个DataNode列表的主机数量取决于你设置的集群副本数,若你设置的是默认副本数是3个,则会返回三个DataNode主机,比如:["hadoop102.yinzhengjie.org.cn","hadoop103.yinzhengjie.org.cn","hadoop104.yinzhengjie.org.cn"]; Q3:DataNode主机列表的在读取数据时仅有一台会读取,那么其它的DataNode都空闲着,它们的作用是什么呢? 答:其实就是一个备胎的作用,当一个节点由于某种不可描述的原因意外宕机时,此时可以从DataNode列表的其它主机随机选择一个主机也能下载数据。
三.HDFS的删除流程
我们上面分析了HDFS的上传和下载流程。我们发现无论是上传还是下载文件都得客户端来参与整个过程。
那么问题来啦,删除文件的工作流程是如何的呢?
答:删除文件过程并不需要客户端来参与整个过程,它只需要告诉NameNode要删除哪个元数据信息即可,NameNode和DataNode之间有心跳信息,当NameNode和DataNode进行相互通信时,NameNode知道哪些节点真正存储元数据信息的数据,它会将删除指令伴随NameNode的心跳信息发送给相应的DataNode删除数据。
四.HDFS的修改流程
首先我们要明确一点,HDFS仅支持数据追加(append),不支持文件的随机修改。
如果你需要修改的是元数据信息,这个问题倒是不大,因为元数据信息的修改只是在NameNode节点完成,但是如果你想要随机修改HDFS的数据是不允许的。
我们在Hue组件中给我们一种错觉,好像编辑文件后就能修改似的,但实际上Hue帮我们修改数据前,是先将之前的版本数据删除掉在将新的文件内容上传上去。如果你修改的文件内容比较大,这意味着这个时间会很长。