自定义OutputFormat代码实现
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.OutputFormat接口实现类概述
OutputFormat是MapRedice输出的基类,所有实现MapReduce输出都实现了 OutputFormat接口。接下来我们介绍几种常见的OutputFormat实现类。
1>.文本输出(TextOutputFormat)
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把他们转换为字符串。
2>.二进制输出(SequenceFileOutputFormat)
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它格式紧凑,很容易被压缩。
3>.自定义OutputFormat
根据用户需求,自定义实现输出。
使用场景:
为了实现控制最终文件的食醋胡路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReducer程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出要求可以通过自定义OutputFormat来实现。
自定义OutputFormat大致步骤:
(1)自定义一个类继承FileOutputFormat;
(2)改写RecordWriter,具体改写输出数据的write()方法。
二.自定义OutputFormat案例
1>.需求说明
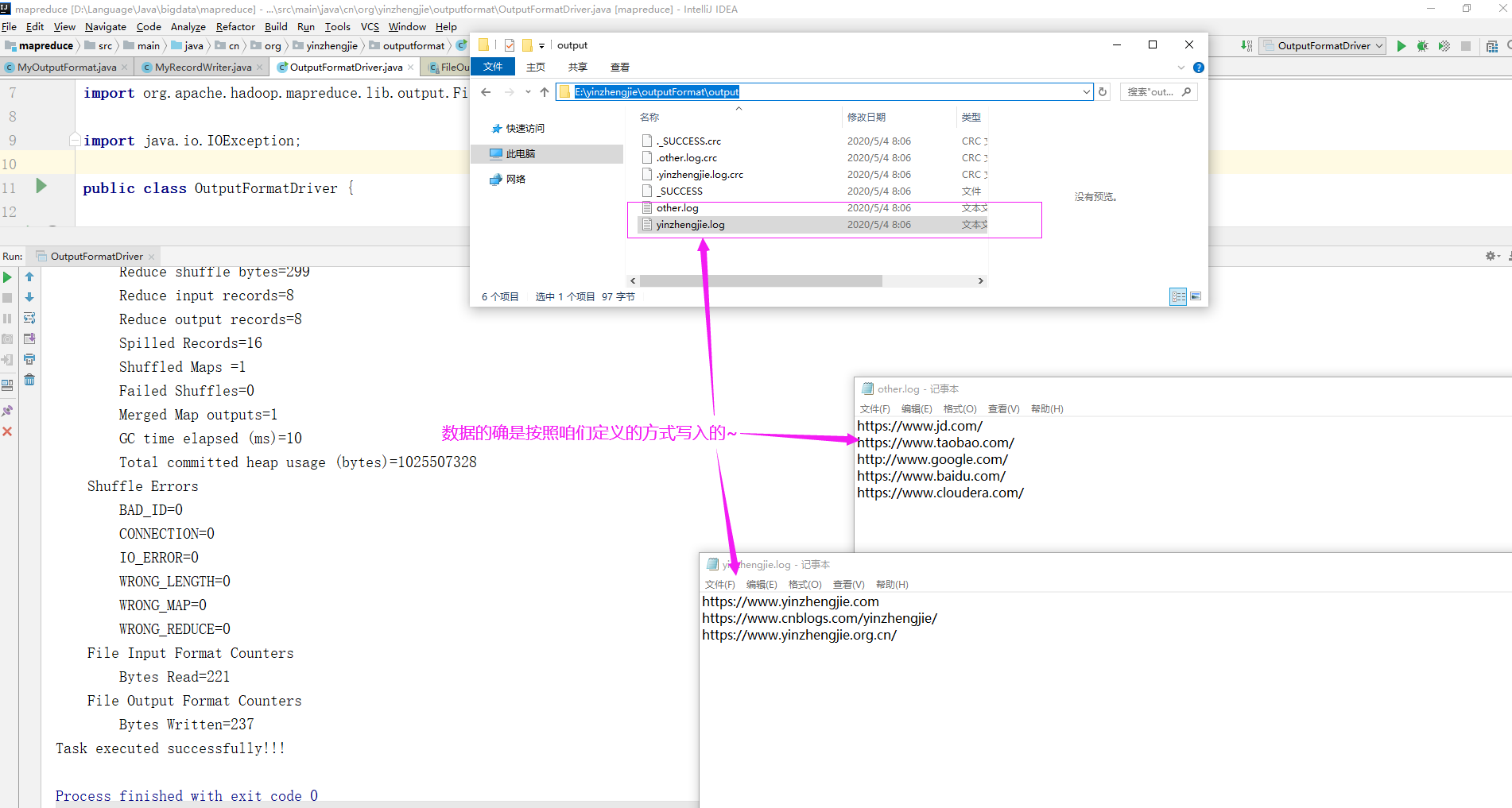
过滤输入website.txt日志,包含yinzhengjie的网站输出到E:yinzhengjieoutputFormatyinzhengjie.log,不包含yinzhengjie的网站输出到E:yinzhengjieoutputFormatother.log


https://www.yinzhengjie.com https://www.jd.com/ https://www.taobao.com/ http://www.google.com/ https://www.baidu.com/ https://www.cloudera.com/ https://www.cnblogs.com/yinzhengjie/ https://www.yinzhengjie.org.cn/
2>.MyRecordWriter.java
package cn.org.yinzhengjie.outputformat; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; public class MyRecordWriter extends RecordWriter<LongWritable,Text> { //使用hadoop为咱们提供的API,不建议使用"FileOutputStream",因为将来咱们的代码是需要往HDFS集群上写的. private FSDataOutputStream yinzhengjie; private FSDataOutputStream other; /** * 初始化方法,开启2个I/O流 * @param job */ public void initialize(TaskAttemptContext job) throws IOException { /** * 获取输出路径信息: * 在FileOutputFormat.setOutputPath中底层定义的key是"job.getConfiguration().set(FileOutputFormat.OUTDIR, outputDir.toString());" */ String outputDir = job.getConfiguration().get(FileOutputFormat.OUTDIR); //获取文件系统 FileSystem fileSystem = FileSystem.get(job.getConfiguration()); //开启2个I/O流 yinzhengjie = fileSystem.create(new Path(outputDir + "/yinzhengjie.log" )); other = fileSystem.create(new Path(outputDir + "/other.log" )); } /** * 用于将K,V写出,每对K,v调用一次 */ @Override public void write(LongWritable key, Text value) throws IOException, InterruptedException { //拿到的数据并不包含换行符,因此我们需要手动加上,不然写出的数据是没有换行的哟~ String line = value.toString() + " "; //判断每行数据是否包含"yinzhengjie",如果包含则写入到指定的I/O流中 if (line.contains("yinzhengjie")){ yinzhengjie.write(line.getBytes()); }else { other.write(line.getBytes()); } } /** * 用于关闭资源 */ @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(yinzhengjie); IOUtils.closeStream(other); } }
3>.MyOutputFormat.java
package cn.org.yinzhengjie.outputformat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class MyOutputFormat extends FileOutputFormat<LongWritable,Text> { @Override public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { MyRecordWriter myRecordWriter = new MyRecordWriter(); //将job信息传递给咱们自定义的RecordWriter,这样方便咱们自定义的RecordWriter获取job的配置信息 myRecordWriter.initialize(job); return myRecordWriter; } }
4>.OutputFormatDriver.java
package cn.org.yinzhengjie.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class OutputFormatDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(OutputFormatDriver.class); //设置OutputFormat的类路径 job.setOutputFormatClass(MyOutputFormat.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
5>.运行OutputFormatDriver类
指定程序的参数为: E:yinzhengjieoutputFormatinput E:yinzhengjieoutputFormatoutput