Reduce Join实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Reduce Join概述
Map端主要的工作: 为来自不同表或文件的key/value对,打标签以区别不同的来源记录。然后用连接字段未作key,其余部分和新加的标志作为value,最后进行输出。 Reduce端的主要工作: 在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一组当中将哪些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。 Reduce Join的缺点: 这种方式中,和贝宁的操作是在Reduce阶段完成,Reducer端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极其容易产生数据倾斜。 解决方案就是Map阶段是西安数据合并。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12811796.html
二.Reduce Join实战案例
1>.需求说明
将商品信息表中数据根据商品pid合并到订单数据表中。


1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6
01 小米 02 华为 03 格力
2>.OrderBean.java
package cn.org.yinzhengjie.reducejoin; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class OrderBean implements WritableComparable<OrderBean> { private String id; private String pid; private int amount; private String pname; @Override public String toString() { return id + " " + pname + " " + amount; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public int getAmount() { return amount; } public void setAmount(int amount) { this.amount = amount; } public String getPname() { return pname; } public void setPname(String pname) { this.pname = pname; } //重写比较方法 @Override public int compareTo(OrderBean obj) { //先比较pid是否相同 int compare = this.pid.compareTo(obj.pid); //如果是pid是相同的,就比较pname,否则就让其不在同一个分组. if (compare == 0){ return obj.pname.compareTo(this.pname); }else { return compare; } } //重写序列化方法 @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(id); dataOutput.writeUTF(pid); dataOutput.writeInt(amount); dataOutput.writeUTF(pname); } //重写反序列化方法 @Override public void readFields(DataInput dataInput) throws IOException { this.id = dataInput.readUTF(); this.pid = dataInput.readUTF(); this.amount = dataInput.readInt(); this.pname = dataInput.readUTF(); } }
3>.ReducerJoinComparator.java
package cn.org.yinzhengjie.reducejoin; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class ReducerJoinComparator extends WritableComparator { protected ReducerJoinComparator(){ super(OrderBean.class,true); } //按照pid进行分组 @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean oa = (OrderBean)a; OrderBean ob = (OrderBean)b; return oa.getPid().compareTo(ob.getPid()); } }
4>.ReducerJoinMapper.java
package cn.org.yinzhengjie.reducejoin; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class ReducerJoinMapper extends Mapper<LongWritable,Text,OrderBean,NullWritable> { private OrderBean orderBean = new OrderBean(); //用于定义当前MapTask正在处理的文件名 private String filename; //在任务开始之前执行一次 @Override protected void setup(Context context) throws IOException, InterruptedException { //获取切片信息 FileSplit fs = (FileSplit)context.getInputSplit(); //获取当前MapTask正在处理的文件名 filename = fs.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split(" "); if (filename.equals("order.txt")){ orderBean.setId(fields[0]); orderBean.setPid(fields[1]); orderBean.setAmount(Integer.parseInt(fields[2])); //order.txt中不包含"Pname"列数据,但此处我们一定要设置为空. orderBean.setPname(""); }else { orderBean.setPid(fields[0]); orderBean.setPname(fields[1]); //同理,pd.txt中不包含"ID"和"Amount"列数据,但此处我们一定要设置为空. orderBean.setId(""); orderBean.setAmount(0); } //将封装的数据写入上下文(hadoop框架)中 context.write(orderBean,NullWritable.get()); } }
5>.ReducerJoinReducer.java
package cn.org.yinzhengjie.reducejoin; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; public class ReducerJoinReducer extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //拿到迭代器 Iterator<NullWritable> iterator = values.iterator(); //取出第一个数据(比如: 01 小米),此时数据指针下意,获取第一个OrderBean iterator.next(); //将Pname字段取出(得到"小米"),即从第一个OrderBean中取出品牌名称 String pname = key.getPname(); //遍历剩下的OrderBean,设置品牌名称并写出 while (iterator.hasNext()){ iterator.next(); key.setPname(pname); context.write(key,NullWritable.get()); } } }
6>.ReducerJoinDriver.java
package cn.org.yinzhengjie.reducejoin; import cn.org.yinzhengjie.mapreduce.WordCountMapper; import cn.org.yinzhengjie.mapreduce.WordCountReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class ReducerJoinDriver { public static void main(String[] args) throws ClassNotFoundException, InterruptedException, IOException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(ReducerJoinDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(ReducerJoinMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(ReducerJoinReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); //设置自定义分组 job.setGroupingComparatorClass(ReducerJoinComparator.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
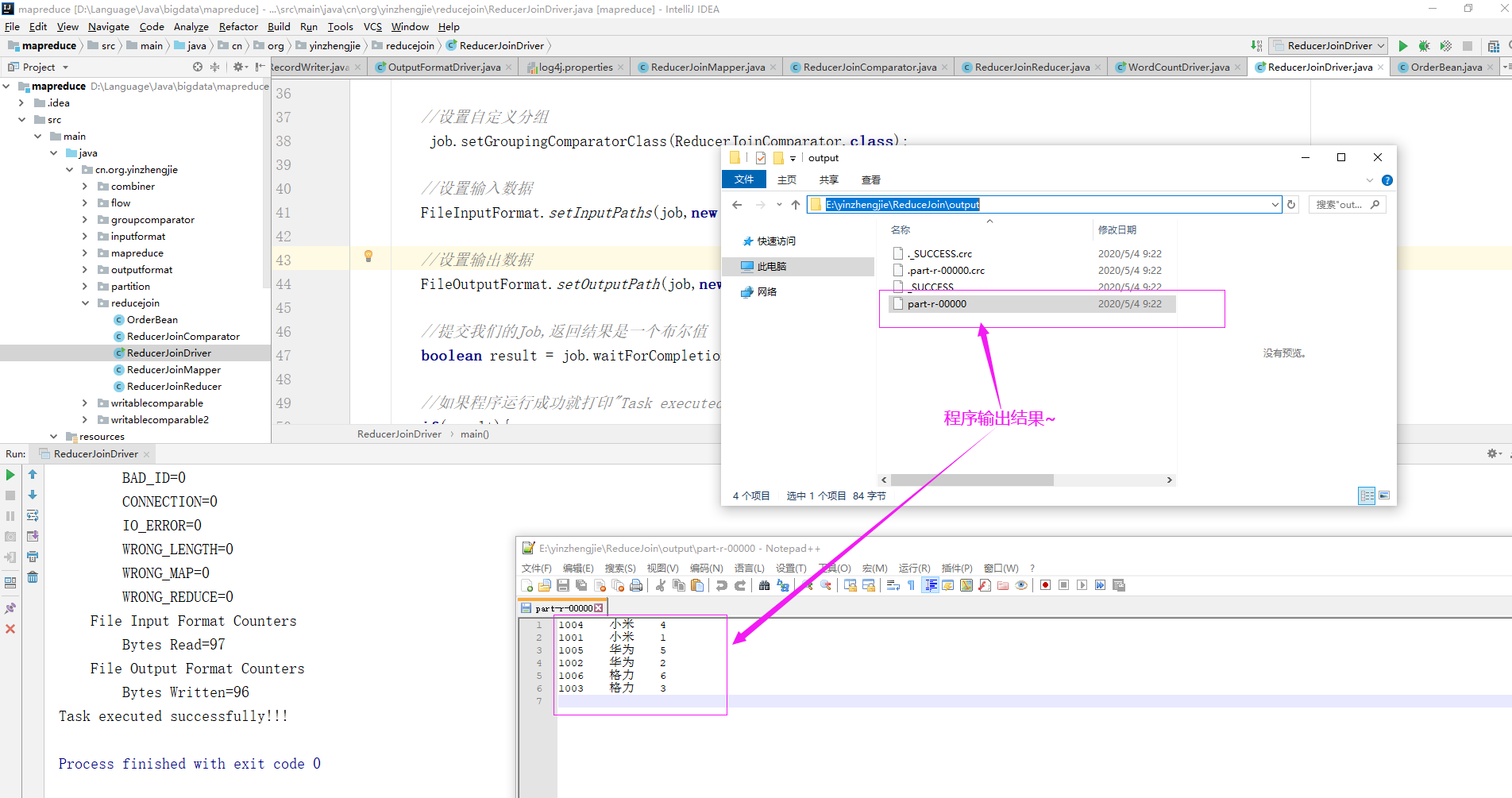
7>.运行ReducerJoinDriver.java代码
配置参数:E:yinzhengjieReduceJoininput E:yinzhengjieReduceJoinoutput