MapReduce实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
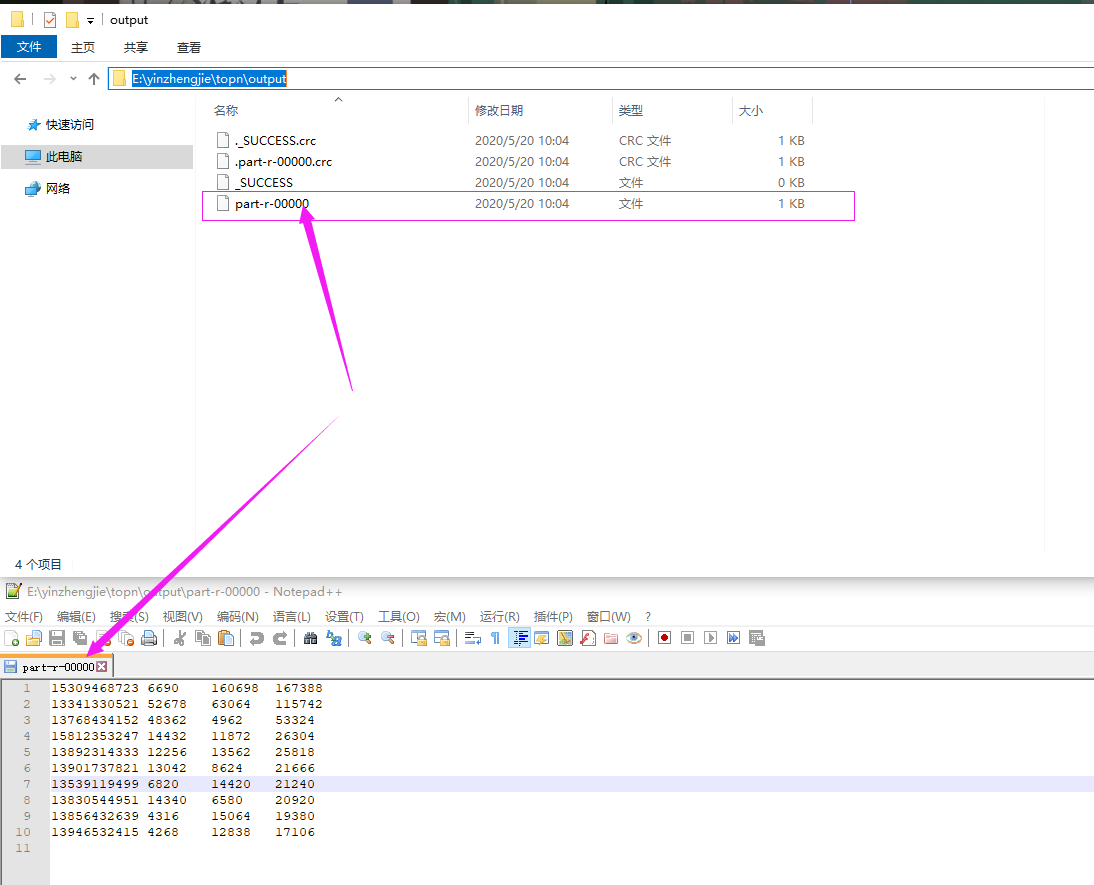
一.TOP N 案例
1>.测试数据


13071253242 6248 4260 10508 13168435653 2432 3908 6340 13268738793 2460 3040 5500 13341330521 52678 63064 115742 13511251143 6420 2426 8846 13539119499 6820 14420 21240 13562439731 3896 5956 9852 13590412962 10272 5828 16100 13768434152 48362 4962 53324 13782846535 5836 7432 13268 13830544951 14340 6580 20920 13843685338 10278 5356 15634 13856432639 4316 15064 19380 13892314333 12256 13562 25818 13901737821 13042 8624 21666 13946532415 4268 12838 17106 15309468723 6690 160698 167388 15812353247 14432 11872 26304 18371172953 5580 7452 13032
2>.案例代码
package cn.org.yinzhengjie.topn; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class FlowBean implements WritableComparable<FlowBean> { private long upFlow; private long downFlow; private long sumFlow; @Override public String toString() { return upFlow +" "+ downFlow + " " + sumFlow; } public void set(long upFlow,long downFlow){ this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } //按照总流量的降序排列 @Override public int compareTo(FlowBean obj) { return Long.compare(obj.sumFlow,this.sumFlow); } //注意序列化的顺序 @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } //反序列化的顺序要和序列化的顺序保持一致 @Override public void readFields(DataInput dataInput) throws IOException { upFlow = dataInput.readLong(); downFlow = dataInput.readLong(); sumFlow = dataInput.readLong(); } }
package cn.org.yinzhengjie.topn; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 让所有数据分到同一组的比较器 */ public class FlowComparator extends WritableComparator { protected FlowComparator(){ super(FlowBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { //返回0会让所有数据都到同一组 return 0; } }
package cn.org.yinzhengjie.topn; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowMapper extends Mapper<LongWritable,Text,FlowBean,Text> { private FlowBean flow = new FlowBean(); private Text phone = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split(" "); phone.set(fields[0]); flow.set(Long.parseLong(fields[1]),Long.parseLong(fields[2])); context.write(flow,phone); } }
package cn.org.yinzhengjie.topn; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; public class FlowReducer extends Reducer<FlowBean,Text,Text,FlowBean> { @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Iterator<Text> iterator = values.iterator(); //由于所有数据被分配到同一组且按照sumFlow进行排序的,此时我们可以直接取TOP 10. for (int i = 0;i <10;i++){ if (iterator.hasNext()){ context.write(iterator.next(),key); } } } }
package cn.org.yinzhengjie.topn; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class FlowDriver { public static void main(String[] args) throws ClassNotFoundException, InterruptedException, IOException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(FlowDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(FlowMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(FlowReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); //设置自定义的GroupingComparator类路径 job.setGroupingComparatorClass(FlowComparator.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
3>.运行结果
15309468723 6690 160698 167388 13341330521 52678 63064 115742 13768434152 48362 4962 53324 15812353247 14432 11872 26304 13892314333 12256 13562 25818 13901737821 13042 8624 21666 13539119499 6820 14420 21240 13830544951 14340 6580 20920 13856432639 4316 15064 19380 13946532415 4268 12838 17106
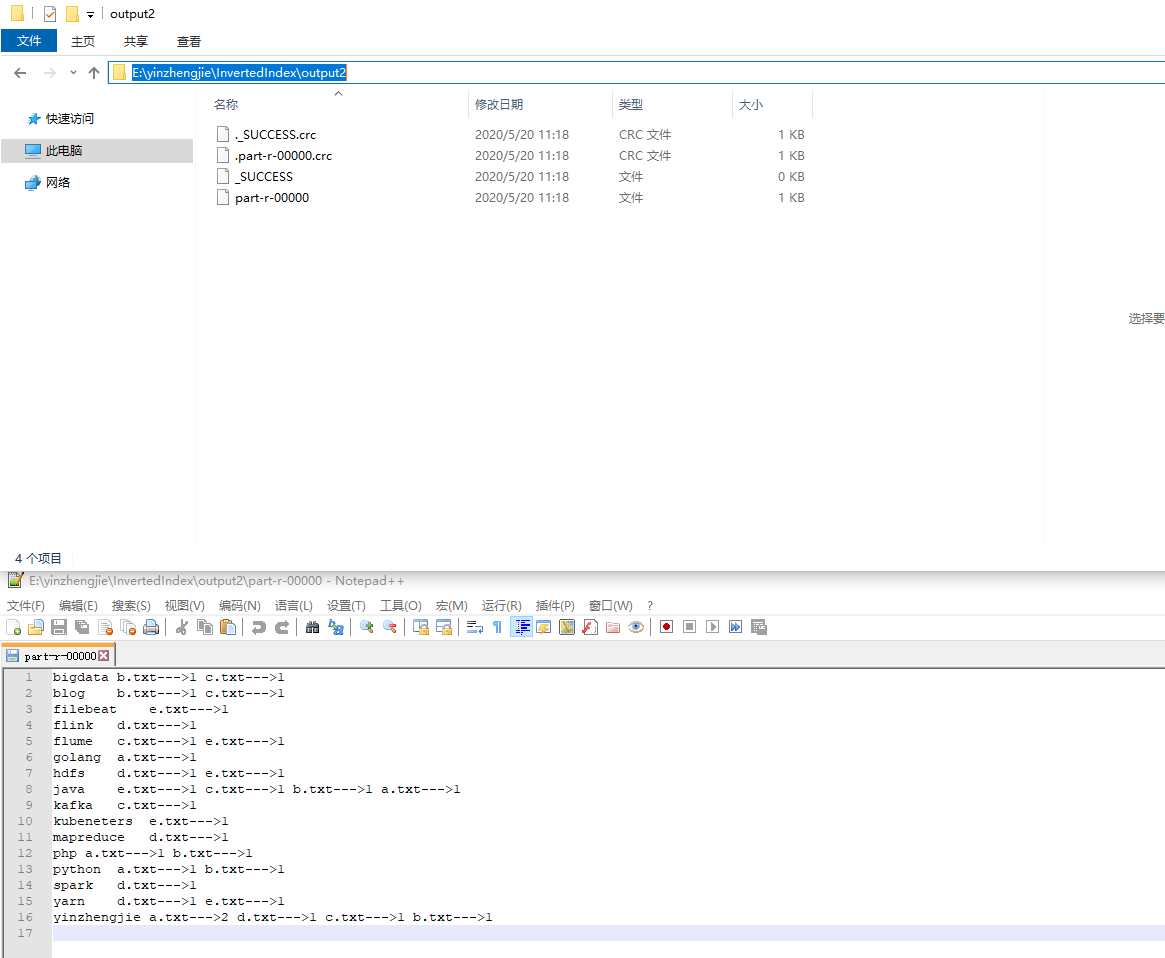
二.倒排索引案例
1>.测试数据
yinzhengjie golang
python yinzhengjie
java php
java php
yinzhengjie python
blog bigdata
blog yinzhengjie
java kafka
flume bigdata
hdfs yinzhengjie
yarn mapreduce
spark flink
flume filebeat
java yarn
hdfs kubeneters
2>.案例代码
package cn.org.yinzhengjie.invertedindex; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class InvertedIndexMapper1 extends Mapper<LongWritable,Text,Text,IntWritable> { private Text k = new Text(); private IntWritable v = new IntWritable(); private String filename; /** * 获取文件名 */ @Override protected void setup(Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit)context.getInputSplit(); filename = fs.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); for (String word:words){ k.set(word + "-----" + filename); v.set(1); context.write(k,v); } } }
package cn.org.yinzhengjie.invertedindex; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class InvertedIndexReduce1 extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value:values){ sum += value.get(); } v.set(sum); context.write(key,v); } }
package cn.org.yinzhengjie.invertedindex; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class InvertedIndexMapper2 extends Mapper<LongWritable,Text,Text,Text> { private Text k = new Text(); private Text v = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("-----"); k.set(split[0]); String[] fields = split[1].split(" "); v.set(fields[0] + "--->" + fields[1]); context.write(k,v); } }
package cn.org.yinzhengjie.invertedindex; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class InvertedIndexReduce2 extends Reducer<Text,Text,Text,Text> { private Text v = new Text(); private StringBuilder sb = new StringBuilder(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { sb.delete(0,sb.length());//清空sb对象 for (Text value : values){ sb.append(value.toString()).append(" "); } v.set(sb.toString()); context.write(key,v); } }
package cn.org.yinzhengjie.invertedindex; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class InvertedIndexDriver { public static void main(String[] args) throws ClassNotFoundException, InterruptedException, IOException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(InvertedIndexDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(InvertedIndexMapper1.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(InvertedIndexReduce1.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); /** * 如果第一个mapreduce运行完毕后我们可以紧接着运行第二个mapreduce * 生产环境中,建议写成2个Driver文件,这样解耦性更强,而且方便调度工具进行调度 */ if(result){ System.out.println("First MapReduce run successfully!!!"); //获取一个Job实例 Job job2 = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job2.setJarByClass(InvertedIndexDriver.class); //设置自定义的Mapper类路径(classpath) job2.setMapperClass(InvertedIndexMapper2.class); //设置自定义的Reducer类路径(classpath) job2.setReducerClass(InvertedIndexReduce2.class); //设置自定义的Mapper程序的输出类型 job2.setMapOutputKeyClass(Text.class); job2.setMapOutputValueClass(Text.class); //设置自定义的Reducer程序的输出类型 job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(Text.class); //设置输入数据 FileInputFormat.setInputPaths(job2,new Path(args[1])); //设置输出数据 FileOutputFormat.setOutputPath(job2,new Path(args[2])); //提交我们的Job,返回结果是一个布尔值 boolean result2 = job2.waitForCompletion(true); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
3>.运行结果
bigdata-----b.txt 1 bigdata-----c.txt 1 blog-----b.txt 1 blog-----c.txt 1 filebeat-----e.txt 1 flink-----d.txt 1 flume-----c.txt 1 flume-----e.txt 1 golang-----a.txt 1 hdfs-----d.txt 1 hdfs-----e.txt 1 java-----a.txt 1 java-----b.txt 1 java-----c.txt 1 java-----e.txt 1 kafka-----c.txt 1 kubeneters-----e.txt 1 mapreduce-----d.txt 1 php-----a.txt 1 php-----b.txt 1 python-----a.txt 1 python-----b.txt 1 spark-----d.txt 1 yarn-----d.txt 1 yarn-----e.txt 1 yinzhengjie-----a.txt 2 yinzhengjie-----b.txt 1 yinzhengjie-----c.txt 1 yinzhengjie-----d.txt 1
bigdata b.txt--->1 c.txt--->1 blog b.txt--->1 c.txt--->1 filebeat e.txt--->1 flink d.txt--->1 flume c.txt--->1 e.txt--->1 golang a.txt--->1 hdfs d.txt--->1 e.txt--->1 java e.txt--->1 c.txt--->1 b.txt--->1 a.txt--->1 kafka c.txt--->1 kubeneters e.txt--->1 mapreduce d.txt--->1 php a.txt--->1 b.txt--->1 python a.txt--->1 b.txt--->1 spark d.txt--->1 yarn d.txt--->1 e.txt--->1 yinzhengjie a.txt--->2 d.txt--->1 c.txt--->1 b.txt--->1
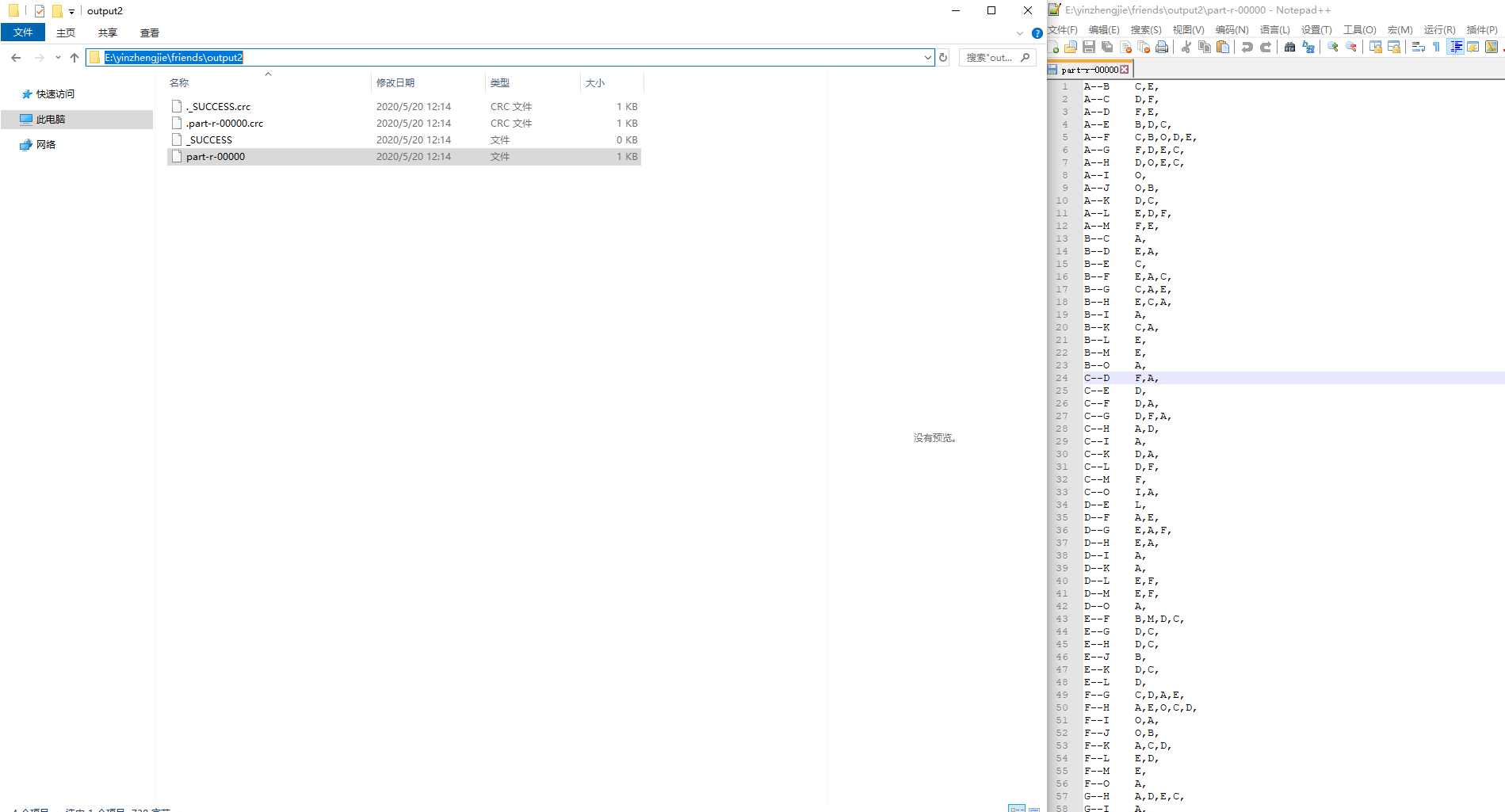
三.找好友案例
1>.测试数据
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
2>.案例代码
package cn.org.yinzhengjie.friends; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class Mapper1 extends Mapper<LongWritable,Text,Text,Text> { private Text k = new Text(); private Text v = new Text(); /** * 思路: * 将我关注了谁转换成谁关注了我 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] friends = value.toString().split(":"); //关注鄙人的人作为value v.set(friends[0]); //被关注的人作为key for (String man : friends[1].split(",")){ k.set(man); context.write(k,v); } } }
package cn.org.yinzhengjie.friends; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class Reducer1 extends Reducer<Text,Text,Text,Text> { private Text v = new Text(); private StringBuilder sb = new StringBuilder(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { sb.delete(0,sb.length()); for (Text value:values){ sb.append(value.toString()).append(","); } v.set(sb.toString()); context.write(key,v); } }
package cn.org.yinzhengjie.friends; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class Mapper2 extends Mapper<LongWritable,Text,Text,Text> { private Text k = new Text(); private Text v = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); v.set(split[0]); String[] men = split[1].split(","); for (int i = 0; i < men.length; i++) { for (int j = i+1; j < men.length; j++) { if (men[i].compareTo(men[j]) > 0){ k.set(men[j] + "--" + men[i]); }else { k.set(men[i] + "--" + men[j]); } context.write(k,v); } } } }
package cn.org.yinzhengjie.friends; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class Reducer2 extends Reducer<Text,Text,Text,Text> { private Text v = new Text(); private StringBuilder sb = new StringBuilder(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { sb.delete(0,sb.length()); for (Text value : values) { sb.append(value.toString()).append(","); } v.set(sb.toString()); context.write(key,v); } }
package cn.org.yinzhengjie.friends; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class MRDriver { public static void main(String[] args) throws ClassNotFoundException, InterruptedException, IOException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(MRDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(Mapper1.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(Reducer1.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); /** * 如果第一个mapreduce运行完毕后我们可以紧接着运行第二个mapreduce * 生产环境中,建议写成2个Driver文件,这样解耦性更强,而且方便调度工具进行调度 */ if(result){ System.out.println("First MapReduce run successfully!!!"); //获取一个Job实例 Job job2 = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job2.setJarByClass(MRDriver.class); //设置自定义的Mapper类路径(classpath) job2.setMapperClass(Mapper2.class); //设置自定义的Reducer类路径(classpath) job2.setReducerClass(Reducer2.class); //设置自定义的Mapper程序的输出类型 job2.setMapOutputKeyClass(Text.class); job2.setMapOutputValueClass(Text.class); //设置自定义的Reducer程序的输出类型 job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(Text.class); //设置输入数据 FileInputFormat.setInputPaths(job2,new Path(args[1])); //设置输出数据 FileOutputFormat.setOutputPath(job2,new Path(args[2])); //提交我们的Job,返回结果是一个布尔值 boolean result2 = job2.waitForCompletion(true); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
3>.运行结果