工具:Anaconda
先进入该页,新浪新闻:http://news.sina.com.cn/china/
往下翻,找到这样的最新消息
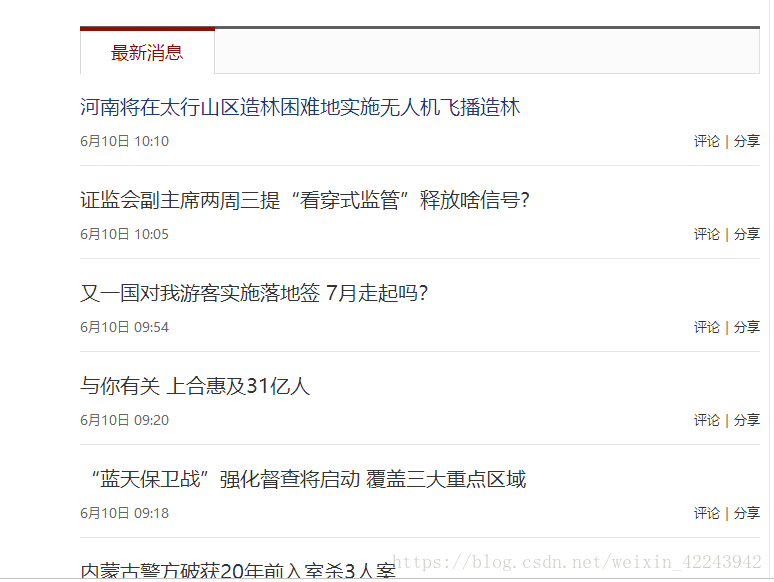
先爬取单个页面的信息:(随便点一个进去),
该新闻网址:http://news.sina.com.cn/c/nd/2018-06-08/doc-ihcscwxa1809510.shtml
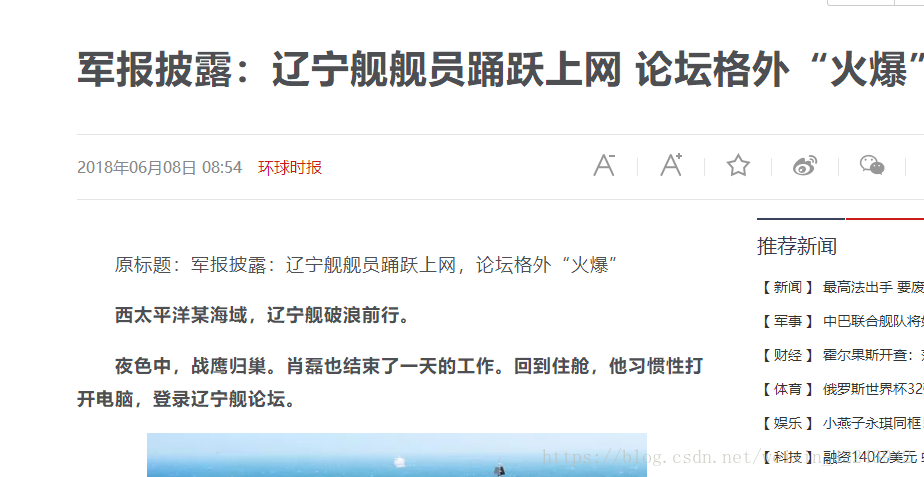
用开发者模式分析网页结构之后,我要获取新闻标题,新闻时间,新闻来源,文章内容,作者姓名,评论总数等,代码如下(主要用的是BeautifulSoup模块):
import requests from bs4 import BeautifulSoup from datetime import datetime import json res=requests.get('http://news.sina.com.cn/c/nd/2018-06-08/doc-ihcscwxa1809510.shtml') res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') title=soup.select('.main-title')[0].text #timesource1=soup.select('.date-source')[0].text.split(' ')[1] #获取时间 timesource=soup.select('.date-source span')[0].text #获取时间 dt=datetime.strptime(timesource,'%Y年%m月%d日 %H:%M') dt.strftime('%Y-%m-%d') place=soup.select('.date-source a')[0].text #获取新闻来源 article=[] #获取文章内容 for p in soup.select('#article p')[:-1]: article.append(p.text.strip()) articleall=' '.join(article) editor=soup.select('#article p')[-1].text.strip('责任编辑:') #获取作者姓名 comments=requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=json& channel=gn&newsid=comos-hcscwxa1809510&group=undefined&compress=0&ie=utf-8& oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1') #print(comments.text) jd=json.loads(comments.text) #用jason解析器 comment_num=jd['result']['count']['total'] #获得评论总数
将上述单页面的代码进行封装整理:
newsurl='http://news.sina.com.cn/c/nd/2018-06-08/doc-ihcscwxa1809510.shtml' commenturl='http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1' def getcommentcounts(newsurl): #获取评论数 m=re.compile('doc-i(.*?).shtml').findall(newsurl) newsid=m[0] comments=requests.get(commenturl.format(newsid)) jd=json.loads(comments.text) return jd['result']['count']['total'] def getnewsdetail(newsurl): #获得单页的新闻内容 result={} res=requests.get(newsurl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') result['title']=soup.select('.main-title')[0].text #标题 timesource=soup.select('.date-source span')[0].text result['time']=datetime.strptime(timesource,'%Y年%m月%d日 %H:%M').strftime('%Y-%m-%d') #时间 result['place']=soup.select('.source')[0].text #来源 article=[] #获取文章内容 for p in soup.select('#article p')[:-1]: article.append(p.text.strip()) articleall=' '.join(article) result['article']=articleall result['editor']=soup.select('#article p')[-1].text.strip('责任编辑:') #获取作者姓名 result['comment_num']=getcommentcounts(newsurl) return result
上面的代码搞定了每一个网址所包含的具体的新闻内容,但是我们是要批量爬取多页的新闻内容,每一页大概并列包含了20多个新闻,所以对网页的开发者模式进行分析后先获取每一页的所有新闻对应的url,如下:
url='http://api.roll.news.sina.com.cn/zt_list?channel=news&cat_1=gnxw&cat_2==gdxw1||=gatxw||=zs-pl||=mtjj&level==1||=2&show_ext=1&show_all=1&show_num=22&tag=1&format=json&page={}&callback=newsloadercallback&_=1528548757769' def parseListLinks(url): newsdetail=[] res=requests.get(url) jd=json.loads(res.text.lstrip(' newsloadercallback(').rstrip(');')) for ent in jd['result']['data']: newsdetail.append(getnewsdetail(ent['url'])) return newsdetail
得到每一页的所有新闻的url之后,我们要获得多页的所有新闻,分析url可得,每一页有网址上的page来进行控制,那就可以写一个循环(批量抓取10页的新闻信息放在news_total里):
news_total=[] for i in range(1,10): newsurl=url.format(i) newsary=parseListLinks(newsurl) news_total.extend(newsary)
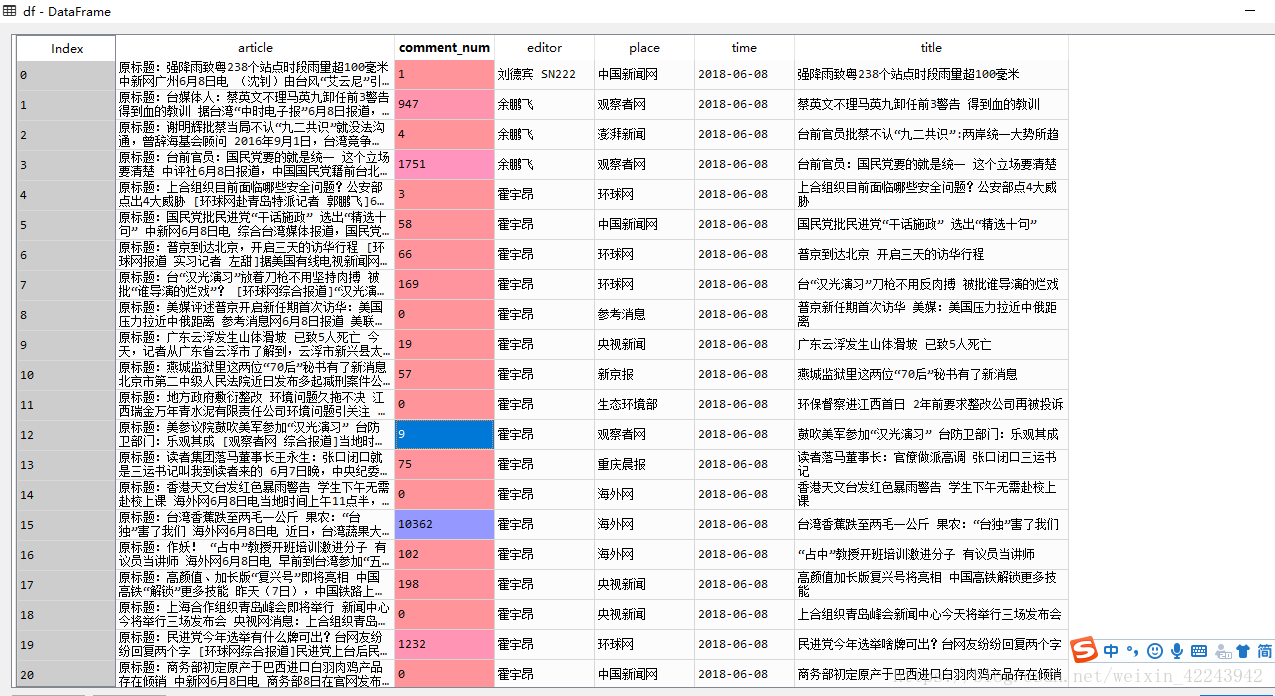
最后将结果用pandas进行整理,当然,整理完了之后也可以保存成excel方便以后阅读:
import pandas as pd df=pd.DataFrame(news_total)
最后结果如下所示:
以上转自https://blog.csdn.net/weixin_42243942/article/details/80639040