一、组员职责分工
| 队员姓名 | 主要分工 |
|---|---|
| 朱庆章 | 测评福州最受欢迎的商圈(参考人气) |
| 陈梦雪 | 测评福州最受欢迎的商圈(参考人气) |
| 关文涛 | 分别测评福州人均消费50以下,50-100、100-200、200以上最佳(性价比最高)的前五家美食餐厅(参考评价与价格) |
| 黄宇航 | 测评福州最佳美食聚集地 |
| 黄奕颂 | 测评福州最佳美食聚集地 |
| 王瑞卿 | 测评福州服饰类综合评分最高的商圈 |
| 胡康 | 测评福州服饰类综合评分最高的商圈 |
| 梅恒权 | 基本数据可视化 |
| 汪倍名 | UI界面 |
| 杨欢 | 爬虫数据 |
二、 github 的提交日志截图

三、程序运行截图
测评福州最佳美食

测评福州服饰类综合评分最高的商圈

爬虫数据
四、程序运行环境
- python 3
- webstorm
- 有网络的电脑 用IE Edge Chrome浏览器打开
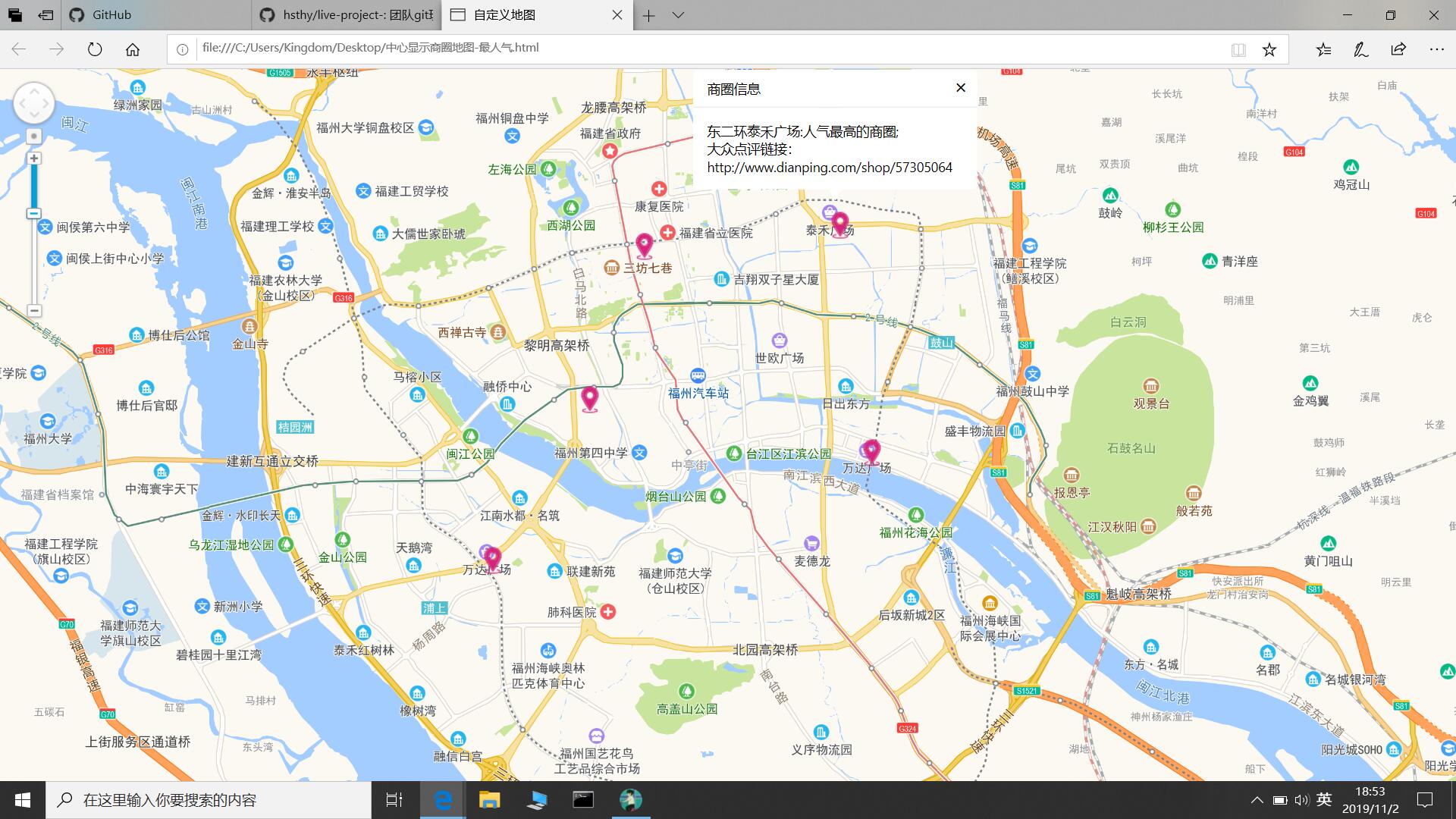
五、GUI界面
地图
界面演示

6.基础功能实现
1)爬虫部分
鉴于要获取福州地区受欢迎的商圈,我们首先要得知店铺的相关信息。
-
爬取美团网站上福州地区的美食与服饰部分的信息,其中主要信息有地址、评分和点评人数
部分代码如下:
def down(keyword,txtpath=''):
browser.get('https://fz.meituan.com/')
time.sleep(2)
text=browser.find_element_by_xpath('/html/body/header/div[2]/div[2]/div[1]/input')
text.send_keys(keyword)
btn=browser.find_element_by_xpath('/html/body/header/div[2]/div[2]/div[1]/button')
btn.click()
time.sleep(3)
array = []
if os.path.exists(txtpath):
os.remove(txtpath)
try:
for i in range(30):
print("第{0}页".format(i), end=' ')
renqi=browser.find_element_by_xpath('/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[1]/div/div[3]/a')
renqi.click()
time.sleep(3)
try:
# '/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[2]/div[1]'
# '/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[2]/div[1]'
lists = browser.find_elements_by_xpath('/html/body/div[1]/div/div/div[2]/div[1]/div[2]/div[2]/div')
except Exception as e:
print('4',e)
print(len(lists))
time.sleep(2)
try:
for j in lists:
try:
dic = {}
try:
href = j.find_element_by_xpath('./div/div/div/div/a')
except Exception as e:
print('href',e)
dic["href"] = href.get_attribute('href')
# print(dic["href"],href.text)
dic["name"] = href.text
dic["data-id"] = json.loads(href.get_attribute("data-lab"))
try:
level = j.find_elements_by_xpath('./div/div/div/div/div[@class="item-eval-info clearfix"]/span')
except Exception as e:# print(len(level))
print('level')
dic["level"] = []
dic["price"]=''
try:
dic["price"]=j.find_element_by_xpath('./div/div/div/div/div[3]/div/span[@class="avg-price"]').text
print(dic["price"])
except:
pass
for k in level:
dic["level"].append(k.text)
dic["address"] = j.find_element_by_xpath(
'./div/div/div/div/div[@class="item-site-info clearfix"]/div/span[@class="address ellipsis"]').text
# print(dic["address"])
except Exception as e:
print('2',e)
array.append(dic)
except Exception as e:
print('1', e)
nextPage = browser.find_element_by_xpath('/html/body/div/div/div/div[2]/div[1]/nav/ul/li[7]')
time.sleep(3)
nextPage.click()
time.sleep(3)
except Exception as e:
print('2', e)
print(array)
with open(txtpath, 'a+', encoding="gbk", errors='ignore') as f:
f.write(json.dumps(array, ensure_ascii=False, indent=4))
-
爬取的数据为JSON格式,部分信息结果:
{ "href": "https://www.meituan.com/meishi/5427649/", "name": "肯德基(万象店)", "data-id": { "keyword": "宝龙万象城美食", "poi_id": 5427649, "custom": { "cat_id": 1, "sort_type": "人气最高", "index": 1 } }, "level": [ "不错", "4分", "0人评论" ], "price": "人均29", "address": "台江区工业路691号万象城购物中心一,二" }
2)评价指标部分
评价一个店铺是否受欢迎,需要从多个方面来考虑,因存在评分高而无人评论或者评分低而评论数过多的情况,
所以需设定一个指标来判断。
-
首先,将JSON文件转换成文本,对其中每家店铺的评分做一个排序,计算出平均评价人数和平均分
-
其次,低于平均分和评价人数的商铺直接过滤
-
再者,将筛选后的店铺根据评价人数做一个排序
-
最后,选出五个最受欢迎的商铺
(对于服饰,在评论人数出需稍作改动) 代码如下:
for i in fd: if len(i['price'])==0 or len(i['level'])<3 or len(i['level'][2])==0: continue pl=int(i['level'][2][:-3]) pllist.append(pl) avg+=pl #print(pl) pllist.sort(reverse=True) avg=avg/len(pllist) print('pl max:',pllist[0]) print('pl mid:',pllist[int(len(pllist)/2)] ) print('pl avg:',avg ) pllist50=[] pllist100=[] pllist200=[] pllist200plus=[] for i in fd: if len(i['price'])==0 or len(i['level'])<3 or len(i['level'][2])==0: continue pl=int(i['level'][2][:-3]) #print(pl,avg) if pl>avg: name = i['name'] rawdata = i['level'] rawprice = i['price'] rawlist = [name, rawdata, rawprice] #print(pl) if(int(i['price'][2:])<=50): pllist50.append(rawlist) elif (int(i['price'][2:])<=100): pllist100.append(rawlist) elif (int(i['price'][2:])<=200): pllist200.append(rawlist) else: pllist200plus.append(rawlist) print(pllist50[0]) def cmp(elem1,elem2): if(elem1[1][1][:-1]!=elem2[1][1][:-1]): return float(elem1[1][1][:-1])-float(elem2[1][1][:-1]) else: return float(elem1[1][2][:-3])-float(elem2[1][2][:-3]) def key2(elem): return elem[1][:-1] key=cmp_to_key(cmp) pllist50.sort(key=key,reverse=True) news_ids = [] for id in pllist50: if id not in news_ids: news_ids.append(id) pllist50=news_ids pllist100.sort(key=key,reverse=True) news_ids = [] for id in pllist100: if id not in news_ids: news_ids.append(id) pllist100=news_ids pllist200.sort(key=key,reverse=True) news_ids = [] for id in pllist200: if id not in news_ids: news_ids.append(id) pllist200=news_ids pllist200plus.sort(key=key,reverse=True) news_ids = [] for id in pllist200plus: if id not in news_ids: news_ids.append(id) pllist200plus=news_ids
3)地图制作
对于测评出福州最受欢迎的商圈,大佬决定采用地图控件的方式粗暴、直观的将位置展现给大家
- 地图制作采用高德地图的控件,点我看刺激精彩内容
- 首先,定义一个Map渲染基础地图
- 其次,设定中心,地图中心位置坐标大致是119.35,26 使显示中心大致在福州市
- 然后,自定义一个坐标列表,列表内容是商圈的经纬度和一个显示详情的文本窗体
- 最后,实例化提示信息的窗体
4)数据可视化
题目要求采用基本数据可视化,组内大佬们觉得太EASY了,就要弄点高级的东西,于是采用ECharts绘制,所谓ECharts,缩写来自 Enterprise Charts,商业级数据图表,是百度的一个开源的数据可视化工具,一个纯 Javascript 的图表库,能够在 PC 端和移动设备上流畅运行,兼容当前绝大部分浏览器(IE6/7/8/9/10/11,chrome,firefox,Safari等),底层依赖轻量级的 Canvas 库 ZRender,ECharts 提供直观,生动,可交互,可高度个性化定制的数据可视化图表。
Ecchats特点:
-
ECharts 属于开源软件,并且提供了非常炫酷的图形界面,特色是地图,另外还提供了柱状图、折线图、饼图、气泡图及四象限图等;
-
ECharts 使用简单,在官网中封装了 JS,只要会引用就会得到完美的展示效果;
-
ECharts 种类多,ECharts 实现简单,各类图形都有;相应的模板,还有丰富的 API 及文档说明,非常详细;
-
ECharts 兼容性好,基于HTML5,有着良好的动画渲染效果。
-
通过队友对数据分析出来的商铺排名结果,参数直接植入,画出条形图,具有比较好的可视化效果。
7.鼓励有想法且有用的功能
- 对于更高端的操作,类似服务器动态链接,实时显示店铺更新的信息,
组内大佬觉得时间来不及回去看比赛了,于是就不做了 - 对于评价指标,我们思考了很多种方法,赋予权值,
各种胡乱数学操作,最后还是按照评分和点评人数乖乖排序... - 对于前端网页标题不能指定的问题,点子鬼才杨欢同学提出可以截白色图片将标题垫到顶部
八、遇到的困难及解决方法
- 组员1:杨欢
困难: 美团,大众点评等数据源API获取需要商家资质,个人学生无法获得。
解决办法: 通过requests和selenium等爬虫手段获取美团数据 。
- 组员2:梅恒权
困难: js不太熟悉 。
解决办法:边用边百度。
- 组员3:朱庆章
困难: 一开始图标会飘到海上,且初始情况下地图显示为中国地图全貌,不能很好反应福州市区情况 。
解决办法: 改小图标的分辨率到20×20,改显示地图的中心经纬度,初始情况下地图放大一定比率。
- 组员4:黄奕颂
困难: 我的任务是测评出福州最佳美食聚集地,但是我得到的数据是有限的,只有从美团爬出的万象城、万达、泰禾广场、东街口和五一广场这几个地方的店铺数据,但是福州还是有除了这几个地方的美食聚集地,所以这次遇到的最大的困难就是数据难以收集全面吧 。
解决办法: 从百度上找到了需要的数据。
- 组员5:王瑞卿
困难:商圈的店铺存在评价很高但评论数太少,单综合两者排序存在数据污染,结果不合理的情况,需要设计合理算法进行综合考虑现实情况进行评价。
解决办法:先经讨论按合理量对评价分评论数等评价受欢迎度的因素进行按权分配所占比例,同时综合考虑物美价廉性价比等因素,进行排序筛选。
- 组员6:汪倍民
困难: 前端排版美观有难度 。
解决办法: 问同学和百度 。
九、马后炮
-
杨欢: 如果我能更懒一点,那我就可以变得更加肥宅了 。
-
梅恒权: 如果再给我半天,那么可以写出多个统计图可视化出来。
-
朱庆章: 如果再给我半小时能把显示的框框做好看点的 。
-
黄奕颂: 如果我知道今天会用到的数据,那么我会先用爬虫爬取到更多的数据来为今天的编程作业服务 。
-
王瑞卿: 如果我能向队友多学习一点,那么也不会这么菜 。
-
陈梦雪: 如果我厉害一点,就好了 。
-
黄宇航: 如果我能再厉害点,就不会呆呆的围观大佬们解题而自己不知道在干嘛。
-
胡康:如果前端学的更熟练一点,就不会什么忙也帮不上了。
十、评估每位组员的贡献比例
| 组员 | 贡献比 |
|---|---|
| 梅恒权 | 12% |
| 王瑞卿 | 8% |
| 杨欢 | 12% |
| 汪倍民 | 12% |
| 关文涛 | 12% |
| 黄奕颂 | 9% |
| 陈梦雪 | 9% |
| 朱庆章 | 12% |
| 黄宇航 | 8% |
| 胡康 | 8% |
十一、PSP表格
| 过程 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| 估计任务时间 | ||
| 开发 | ||
| 需求分析 (包括学习新技术) | ||
| 生成设计文档 | ||
| 设计复审 | ||
| 代码规范 (为目前的开发制定合适的规范) | ||
| 具体设计 | ||
| 具体编码 | ||
| 代码复审 | ||
| 测试(自我测试,修改代码,提交修改) | ||
| 报告 | ||
| 测试报告 | ||
| 计算工作量 | ||
| 事后总结, 并提出过程改进计划 | ||
| 合计 |
十二、学习进度表
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 9 | 200 | 2000 | 5 | 10 | 尝试使用python对数据库的操纵 ,团队讨论 |
| 10 | 2000 | 4000 | 4 | 14 | 团队合作,python的使用 |