题记:
自己做程序员快三年有余了,感觉自己和刚入职相比确实有了不少进步,当然三年要是不进步那不就傻了吗,有时候我也在想,我在这三年里留下了什么,当然也不是说有多么高尚的想法,就是以后对别人介绍自己的时候,能否说出点什么了,就像去面试一样,总得拿出点看得见的业绩出来吧!没事的时候去知乎看看各位大神的膜拜一下以外,生活没有任何变化,我特别不喜欢考试,因为不喜欢背东西,不喜欢背东西的原因就是记性差,可是记性再差我也始终忘不了她,没有刻骨铭心的经历,却有深入骨髓的感觉,有点扯远了。
所以自己内心一直以来都有想在GitHub上留下一点印记的想法,因为最近项目中较多使用flume,所以看了很多flume的代码,发现了我觉得可以提出修改的地方了。很多项目的配置文件中,关于时间和容量类的配置基本都是不能附加单位的,这导致设置过大数值的时候转换困难以及阅读困难等问题,比如想设置2g容量,但是因为默认单位为byte,需要将2g转换成2147483648,很不方便,而flume中应用了大量的配置文件,我初步总结了一下用的这两方面配置的地方:


Exec Source ms:restartThrottle,batchTimeout Spooling Directory Source ms:pollDelay,maxBackoff, Event Deserializers BlobDeserializer byte:deserializer.maxBlobLength@BlobDeserializer Taildir Source ms:idleTimeout,writePosInterval,backoffSleepIncrement,maxBackoffSleep Twitter 1% firehose Source (experimental) ms:maxBatchDurationMillis Kafka Source ms:batchDurationMillis,backoffSleepIncrement,maxBackoffSleep NetCat Source byte:max-line-length@NetcatSource Syslog TCP Source byte:eventSize@SyslogTcpSource Multiport Syslog TCP Source byte:eventSize@MultiportSyslogTCPSource BlobHandler byte:handler.maxBlobLength Stress Source byte:size@StressSource Scribe Source byte:maxReadBufferBytes@ScribeSource HDFS Sink ms:hdfs.callTimeout Hive Sink ms:callTimeout Avro Sink ms:connect-timeout,request-timeout Thrift Sink ms:connect-timeout,request-timeout File Roll Sink ms:sink.rollInterval(s) AsyncHBaseSink ms:timeout MorphlineSolrSink ms:batchDurationMillis Kite Dataset Sink ms:kite.rollInterval(s) Memory Channel byte:byteCapacity@MemoryChannel Kafka Channel ms:pollTimeout File Channel byte:maxFileSize,minimumRequiredSpace@FileChannel ms:checkpointInterval,keep-alive Spillable Memory Channel byte:byteCapacity,avgEventSize@SpillableMemoryChannel ms:overflowTimeout, Pseudo Transaction Channel ms:keep-alive(s) Failover Sink Processor ms:processor.maxpenalty Load balancing Sink Processor ms:processor.selector.maxTimeOut Avro Event Serializer byte:syncIntervalBytes@AvroEventSerializer
2017年05月14日
但是因为涉及到的地方太多,而且有些对原有程序改动较大,所以我想找一个人讨论下,因此找到一个flume的开发人员,给他发了封邮件,英文的重要性就体现出来,靠着词典把这封邮件写出来了:
Dear Attila Simon: I use the flume in my work,when I was in the configuration of the flume, found that some of the parameters of configuration is very troublesome, and readability is very poor like the Memory Channel's byteCapacity ,File Channel's transactionCapacity and maxFileSize etc., basic it is about the capacity configuration.Generally when I was in the configuration that, I need a special calculation of byte after transformation, such as 2g into 2147483648, and must be withing annotated, otherwise the next time I read, don't know this is 2g intuitive So I wrote a simple method used for converting readable capacity allocation into corresponding byte code is as follows. public class Utils { private static final String REGULAR="((?<gb>\d+(\.\d+)?)(g|G|gb|GB))?((?<mb>\d+(\.\d+)?)(m|M|mb|MB))?((?<kb>\d+(\.\d+)?)(k|K|kb|KB))?((?<b>\d+)(b|B|byte|BYTE)?)?"; private static final int rate=1024; public static Long string2Bytes(String in){ return string2Bytes(in,null); } public static Long string2Bytes(String in,Long defaultValue){ if(in==null || in.trim().length()==0){ return defaultValue; } in=in.trim(); Pattern pattern = Pattern.compile(REGULAR); Matcher matcher = pattern.matcher(in); if(matcher.matches()){ long bytes=0; String gb=matcher.group("gb"); String mb=matcher.group("mb"); String kb=matcher.group("kb"); String b=matcher.group("b"); if(gb!=null){ bytes+=Math.round(Double.parseDouble(gb)*Math.pow(rate, 3)); } if(mb!=null){ bytes+=Math.round(Double.parseDouble(mb)*Math.pow(rate, 2)); } if(kb!=null){ bytes+=Math.round(Double.parseDouble(kb)*Math.pow(rate, 1)); } if(b!=null){ bytes+=Integer.parseInt(b); } return bytes; }else{ throw new IllegalArgumentException("the param "+in+" is not a right"); } } } Below is the test class @RunWith(Parameterized.class) public class UtilsTest { private String param; private Long result; public UtilsTest(String param,Long result){ this.param=param; this.result=result; } @Parameters public static Collection<Object[]> data() { return Arrays.asList(new Object[][]{ {"", null}, {" ", null}, {"2g", 1L*2*1024*1024*1024}, {"2G", 1L*2*1024*1024*1024}, {"2gb", 1L*2*1024*1024*1024}, {"2GB", 1L*2*1024*1024*1024}, {"2000m", 1L*2000*1024*1024}, {"2000mb", 1L*2000*1024*1024}, {"2000M", 1L*2000*1024*1024}, {"2000MB", 1L*2000*1024*1024}, {"1000k", 1L*1000*1024}, {"1000kb", 1L*1000*1024}, {"1000K", 1L*1000*1024}, {"1000KB", 1L*1000*1024}, {"1000", 1L*1000}, {"1.5GB", 1L*Math.round(1.5*1024*1024*1024)}, {"1.38g", 1L*Math.round(1.38*1024*1024*1024)}, {"1g500MB", 1L*1024*1024*1024+500*1024*1024}, {"20MB512", 1L*20*1024*1024+512}, {"0.5g", 1L*Math.round(0.5*1024*1024*1024)}, {"0.5g0.5m", 1L*Math.round(0.5*1024*1024*1024+0.5*1024*1024)}, }); } @Test public void testString2Bytes() { assertEquals(result,Utils.string2Bytes(param)); } } public class UtilsTest2 { @Test(expected =IllegalArgumentException.class) public void testString2Bytes1() { String in="23t"; Utils.string2Bytes(in); } @Test(expected =IllegalArgumentException.class) public void testString2Bytes2() { String in="2g50m1.4"; Utils.string2Bytes(in); } @Test(expected =IllegalArgumentException.class) public void testString2Bytes3() { String in="4.2g"; Utils.string2Bytes(in); } } I'm going to put all the reading capacity place to use this method to read, and compatible with the previous usage, namely not with units of numerical defaults to byte, why I don't fork and pull request the code, the reason is that some of the parameter name with byte or bytes, if its value is 2GB or 500MB, it is appropriate to do so, or making people confuse, so I ask for your opinion in advance. Parameters in the configuration of time whether to need to add the unit, I think can, do you think if capacity added to the unit, whether time synchronization also improved. In addition to this I also want to talk about another point, that is, when the user parameter configuration errors are handled, in the flume, the means of processing is to configure the error using the default values, and print the warn message, even in some places will not print the warn,the following codes are in the MemoryChannel.class try { byteCapacityBufferPercentage = context.getInteger("byteCapacityBufferPercentage", defaultByteCapacityBufferPercentage); } catch (NumberFormatException e) { byteCapacityBufferPercentage = defaultByteCapacityBufferPercentage; } try { transCapacity = context.getInteger("transactionCapacity", defaultTransCapacity); } catch (NumberFormatException e) { transCapacity = defaultTransCapacity; LOGGER.warn("Invalid transation capacity specified, initializing channel" + " to default capacity of {}", defaultTransCapacity); } I don't think this is right, because the common user won't be too care about a warn information, he would think that the program run successfully according to configuration parameters, the results do use the default values. I think, if the user doesn't set a property then we should use default values, if the user is configured with a property, he certainly expect to this attribute to run the program, if the configuration errors should stop running and allow the user to modify., of course, this approach may be too radical, may give the option to the user, may be a new property < Agent >.configuration.error = defaultValue/stopRunning, when configured to defaultValue shall, in accordance with the previous approach, configuration stopRunning will stop running the program. Thank you very much for reading such a long email,and most of email are machine translation, looking forward to your reply, if possible I hope to become a member of the flume contributors. from Lisheng Xia
重点就是提出自己的建议,但是因为涉及太多需要讨论下。然后就是等待回信中。
2017年05月17日
等了好多天,终于回信了:
Hi Lisheng Xia, I like this feature! I would like to add the dev list to this conversation so others can express their opinion as well. After all what community says is what really matters. We can discuss there your proposal in detail as well as whether there is a library which can help you in the unit conversion eg javax.measure. In my opinion it is appropriate : to have a configuration property name with "byte" and still allowing to specify the value with units, if it is clear from the documentation what would that mean (eg please see the GiB vs GB definitions here). extending this feature with time values (Hour,Minute,Second,Milisec...) having the conversation failures instantly and clearly visible to the user by throwing an exception. I think "< Agent >.configuration.error = defaultValue/stopRunning" would be even better but much harder to implement. Cheers, Attila
看他表达的意思是意见很好,但是有问题的地方还是需要大家讨论的,顺便他给我指出了我的一个认知错误,那就是GB和GiB的关系,还是涨了不少见识。可是我不知道怎么讨论以及去哪讨论,我就又发送了一封邮件询问他:
Hi Attila Thank you very much for your reply. I downloaded the javax.measure and read its source, and look at the definition of wikipedia about GiB and GB, learned a lot, and correct the wrong knowledge.Now the idea is as follows 1.Don't import jscience or other jars,write directly in the flume-ng-core project/org.apache.flume.tools package,create a new UnitUtils class for capacity and time of string parsing and transformation operations.don't introducing jscience package, is the cause of not directly provide available method, and the function of the project needs to need only a class can be completed, unnecessary modified pom.xml and import new jars. 2.About the capacity unit,because the window unit causes the confusion,my advice to simulate the JVM startup parameters, -Xms/-Xmx use rules, the rules only allowed to use the G/M/K/B or g/m/k/b to define (actual representative GiB/MiB/KiB/Byte), without the unit is Byte by default. The above two points, if not no problem, I will develop and test. In addition, the definition of unit of time, I need to discuss, is to use the h/m/s/S or H/m/s/S or use the Hour/Minute/Second/Millisecend.Can you tell me the way to where can be discussed. Cheers, Lisheng Xia
2017年05月18日
没想到这次回复这么快:
Hi Lisheng Xia, I think the best to discuss further on dev@flume.apache.org list (added to the email recipients list already). I recommend you to join that list as that is one of the early steps towards being a contributor. In general this page describes how to contribute to Apache Flume: https://cwiki.apache.org/confluence/display/FLUME/How+to+Contribute Cheers, Attila
只是我又遇到了难题,邮件列表这个东西很古老了,我怎么也找不到使用方法,然后如何贡献flume代码,我也看了好几遍,感觉还是找不到讨论的入口,我觉得自己好小白,里面很多东西还是不太明白,反复阅读了很多遍,觉得这个应该是个重点:

这个JIRA是什么,搜索了解了一番,果然又涨了不少知识,随后又去一个未知的的网站注册了JIRA账号,在里面把问题提出来了:
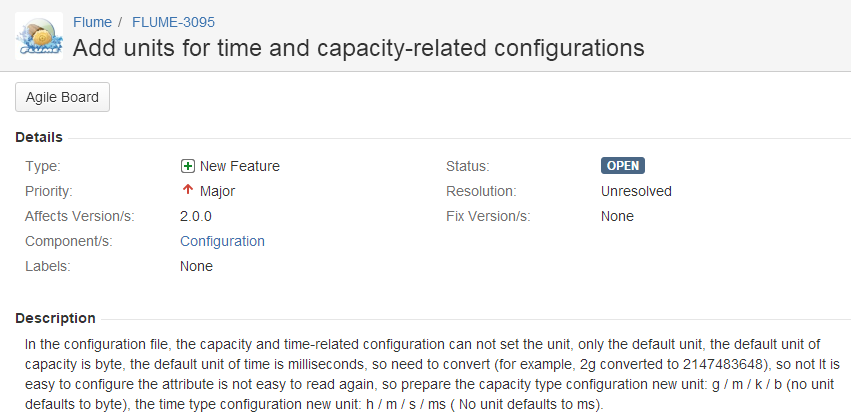
然后下面就不知道该做啥了,陷入等待中。
2017年05月22日
后来感觉等下去也不是办法,我就打算直接pull request试一下,克隆,下载,修改,提交,pull request,结果提交后有个大大的红叉号:

我又蒙了,完全不知道错在哪,本地基本测试我已经测试过了,而且这个错误,进去详情:
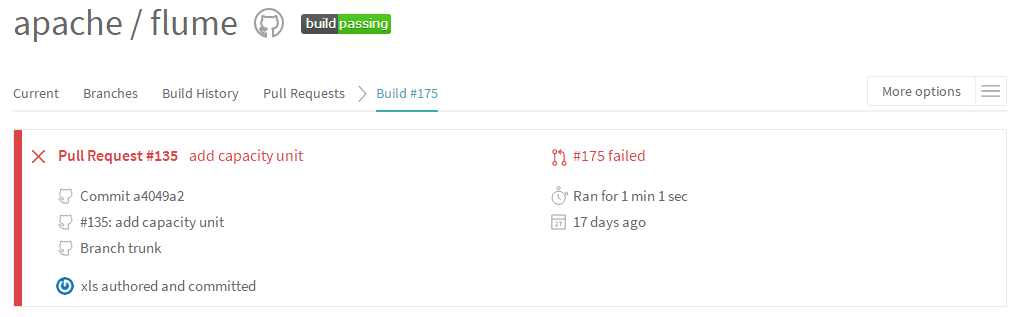
我就写了简简单单的方法就有这么多的错误,完全不知道是因为什么,我又去了解Travis CI是什么东西,果然又学到了很多知识,自己测试了下,果然这么多错误,只能一个个改正,然后重新上传。
2017年05月23日
最后重新提交,测试通过,然后自己写了个留言,问一下用户手册在哪,我需要更新:
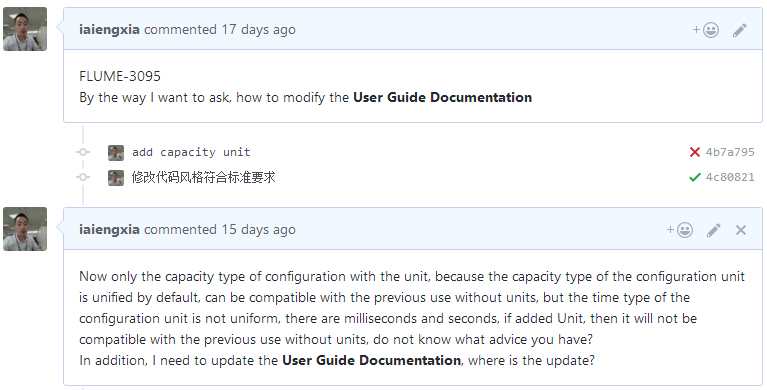
随后就又是等待中。
2017年06月02日
终于在今天一个开发者给我了回复,并提出了自己的建议:
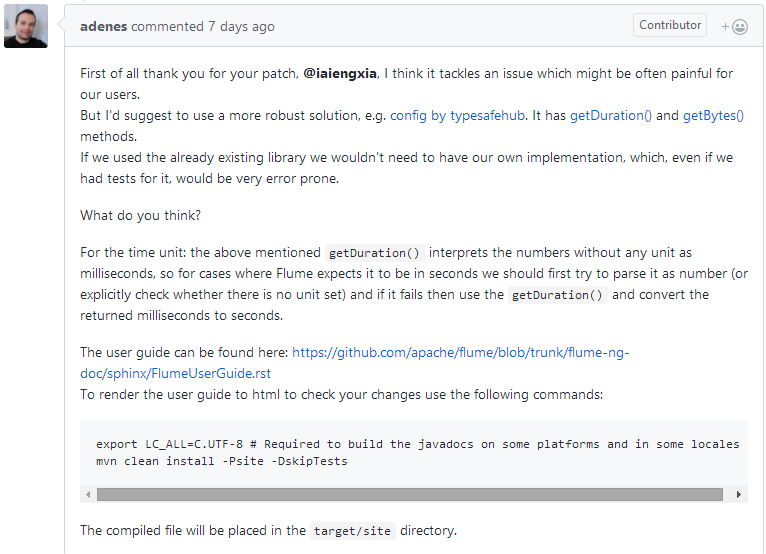
可是我完全不同意他的建议,于是我写了不同意的原因:
To be honest, before I write the tool class, I did not find a library that could meet my needs. Thank you for increasing my knowledge @adenes . I read the source code of config.jar and read the development documentation and did some basic Of the test, now listed under the advantages and disadvantages I know: Advantages of using config.jar: The solution is more mature and does not need to test the parsing parameters part of the code Disadvantages of using config.jar: There is no separate way to directly parse a string with a unit, you must reload the configuration file, the change is relatively large, not fully compatible with the original program Can only parse a number and a unit of the parameters, such as 1g500m this with a number of units can not be resolved (do not know if there is such a demand) Advantages of using custom tool classes to parse: You can parse parameters with multiple units Easy to use, the change is very small (read the time through a static method can be processed), and has been achieved Disadvantages of using custom tool classes to parse: Requires complete testing What do you think? For the time unit, I suggest that some of the recommendations, if I provided in the Context class getDuration () method used to resolve the time, if no unit does not need to parse the direct return number, there are units I will analyze the actual unit , Internally stored in milliseconds, but what number of units do I return? For example, the default unit in milliseconds, timeout = 3000, I will return 3000, timeout = 3s (internal resolution into 3000ms), I will return 3000 (return the number of units in milliseconds).But in the default unit for the case of seconds, timeout = 3, I will return 3, timeout = 3s, How much should I return , if according to the above logic I will still return 3000, but the user expects to return the unit for seconds, How do I know the user's expectations unit? Perhaps you can use the getDuration (String key, TimeUnit unit) method to let the user tell me what unit it needs to return value, but this will lead to another problem, if the default unit is seconds, timeout = 3, I can not know 3 real units and convert them into units that the user expects, because no unit can not simply return the number, and need to be converted into the unit desired by the user. It seems a bit difficult to analyze the time unit, because I need to meet the needs of existing components for time parameter resolution. I can not provide a common way to meet all the needs of the present situation. Based on the current situation, my suggestion is , No unit number directly return the number, there are units according to the actual unit analysis, and unified return in milliseconds as a unit of the number, if the user needs seconds, then their own conversion (really, the user needs for the second unit is not the beginning support time units, resulting in too long settings to read up is not convenient)...
结果好几天都没有回复,等待中。
虽然还没有结果,但是想说说自己的感想,一个就是对于开源的工具,能贡献就去贡献,不能只是享受使用它们的便利,也应该让这个工具持续的发展下去,还有就是不管什么第一次都是好困难,好几次我都快放弃了,估计也是因为第一次贡献代码很多地方都很小白,不管这次成不成功,我觉得只要开了这个头,以后我都会继续贡献下去,再说通过这个事也让我学到了特别多的东西,当然如果能用上自己贡献的代码还是有点成就感的。
2017年06月13日
按照他的要求修改了用户使用手册,这个时候碰到一个坑,flume-ng-doc不是一个Maven项目,只能修改了原始文件,修改完用户使用手册后以后又把配置文件模板修改了下,增加了单位使用的提醒,然后增加了工具类的测试方法,至此以外完成了,除时间单位解析所有的工作,提交等待他们下一步回应。
。。。等待中