总结源于海子博客http://www.cnblogs.com/dolphin0520/
1、在class文件中有一部分来存储编译期间生成的字面常量以及符号引用,这部分叫做class文件常量池,在运行期间对应着方法区的运行时常量池。
(1)String str1 = "hello world";和String str2= "hello world";都在编译期间生成了字面常量和符号引用,运行期间字面常量"hello world"被存储在运行时常量池(当然只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量; 否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
(2)String str = new String("hello world")通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。因此通过new来创建对象,创建出的一定是不同的对象,即使字符串的内容是相同的。该段代码执行过程和类的加载过程是有区别的。在类加载的过程中,确实在运行时常量池中创建了一个"hello world"对象,而在代码执行过程中确实只创建了一个String对象,即在堆上创建了"hello world"对象。
(3)String str = new String("hello"); str+="java";这段代码涉及(非创建)5个对象,首先,“hello”在堆和常量池各一个;其次,“java”在常量池有一个;最后,“helloJava”在堆和常量池各一个。第一次出现字符串直接量时会在池中创建一个新的,之后出现就不会创建了,而是直接把引用指向第一次创建的对象。但对于new出来的对象,无论怎样赋值,new一次在运行期创建一次(在堆中),不会考虑之前是否已经已存在相同的。而且,字符串是不可追加的,所以每次使用连接符号其实相当于先产生一个常量,然后再赋给引用,原来指向的串就成垃圾被回收了。
(4)String str1="java";//指向字符串常量池 String str2="blog";//指向字符串常量池 String s = str1+str2; +运算符会在堆中建立起两个String对象,这两个对象的值分别是“java”,"blog",也就是说从字符串常量池中复制这两个值,然后在堆中创建两个对象。然后再建立对象s,然后将“javablog”的堆地址赋给s. 这句话共创建了3个String对象。
2、Integer a = 1; Integer b = 2; Integer c = 3; Integer d = 3;
Integer e = 321; Integer f = 321; Long g = 3L; Long h = 2L;
System.out.println(c==d);//true
System.out.println(e==f);//false
System.out.println(c==(a+b));//true
System.out.println(c.equals(a+b));//true
System.out.println(g==(a+b));//true
System.out.println(g.equals(a+b));//false
System.out.println(g.equals(a+h));//true
当 "=="运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。另外,对于包装器类型,equals方法并不会进行类型转换。java中基本类型的包装类的大部分都实现了常量池技术,这些类是Byte, Short, Integer, Long, Character, Boolean, 另外两种浮点数类型(Float、Double)的包装类则没有实现。另外Byte, Short, Integer, Long, Character这5种整型的包装类也只在大于等于-128并且小于等于127时才使用常量池,也即对象不负责创建和管理大于127的这些类的对象。mvn install:install-file //mvn 命令
-Dfile=sojson-demo.jar //要添加的包
-DgroupId=com.sojson //pom文件对应的groupId
-DartifactId=com.sojson.demo //pom文件对应得artifactId
-Dversion=1.0 //添加包的版本
-Dpackaging=jar
public ∨ ∨ ∨ ∨
protect ∨ ∨ ∨ ×
default ∨ ∨ × ×
private ∨ × × ×
(10)update ft_airport set ft_airport.airport_name=REPLACE(airport_name,'机场','');
(11)Java8 时间日期api https://lw900925.github.io/java/java8-newtime-api.html
(12)分布式与集群的区别 http://blog.csdn.net/javaloveiphone/article/details/52368291
(13)kafka http://blog.csdn.net/tangdong3415/article/details/53432166
(14)Windows环境下的监控工具
jvisualvm.exe在JDK安装目录下的bin目录下面,双击即可打开。
MemoryAnalyzer.exe。
(15)this代表当前对象。
static是不允许用来修饰局部变量。
static final用来修饰成员变量和成员方法,可简单理解为“全局常量”! 对于变量,表示一旦给值就不可修改,并且通过类名可以访问。对于方法,表示不可覆盖,并且可以通过类名直接访问。
public class Test {
Person person = new Person("Test");
static{
System.out.println("test static");
}
public Test() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new MyClass();
}
}
class Person{
static{
System.out.println("person static");
}
public Person(String str) {
System.out.println("person "+str);
}
}
class MyClass extends Test {
Person person = new Person("MyClass");
static{
System.out.println("myclass static");
}
public MyClass() {
System.out.println("myclass constructor");
}
}
结果为:
test static myclass static person static person Test test constructor person MyClass myclass constructor
在执行开始,先要寻找到main方法,因为main方法是程序的入口,但是在执行main方法之前,必须先加载Test类,因此会执行Test类中的static块。(注意:如果main方法在MyClass类中,则先会加载其父类Test,执行Test类中的static块,再加载MyClass类,执行MyClass类中的static代码块)接着执行new MyClass(),而MyClass类还没有被加载,因此需要加载MyClass类。在加载MyClass类的时候,发现MyClass类继承自Test类,但是由于Test类已经被加载了,所以只需要加载MyClass类,那么就会执行MyClass类的中的static块。在加载完之后,就通过构造器来生成对象。而在生成对象的时候,必须先初始化父类的成员变量,因此会执行Test中的Person person = new Person(),而Person类还没有被加载过,因此会先加载Person类并执行Person类中的static块,接着执行父类的构造器,完成了父类的初始化,然后就来初始化自身了,因此会接着执行MyClass中的Person person = new Person(),最后执行MyClass的构造器。
第一点,所有的类都会优先加载基类
第二点,静态成员的初始化优先
第三点,成员初始化后,才会执行构造方法
第四点,静态成员的初始化与静态块的执行,发生在类加载的时候。
第五点,类对象的创建以及静态块的访问,都会触发类的加载。
5、对于子类可以继承的父类成员变量,如果在子类中出现了同名称的成员变量,则会发生隐藏现象,即子类的成员变量会屏蔽掉父类的同名成员变量。如果要在子类中访问父类中同名成员变量,需要使用super关键字来进行引用。对于子类可以继承的父类成员方法,如果在子类中出现了同名称的成员方法,则称为覆盖,即子类的成员方法会覆盖掉父类的同名成员方法。如果要在子类中访问父类中同名成员方法,需要使用super关键字来进行引用。注意:隐藏和覆盖是不同的。隐藏是针对成员变量和静态方法的,而覆盖是针对普通方法的。
public class Test {
public static void main(String[] args) {
Shape shape = new Circle();
System.out.println(shape.name); //隐藏了子类
shape.printType(); //被子类覆盖
shape.printName(); //隐藏了子类
}
}
class Shape {
public String name = "shape";
public Shape(){
System.out.println("shape constructor");
}
public void printType() {
System.out.println("this is shape");
}
public static void printName() {
System.out.println("shape");
}
}
class Circle extends Shape {
public String name = "circle";
public Circle() {
System.out.println("circle constructor");
}
public void printType() {
System.out.println("this is circle");
}
public static void printName() {
System.out.println("circle");
}
}
结果为:
shape constructor circle constructor shape this is circle shape
6、接口与抽象类
抽象类:[ public ] abstract class ClassName {
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
在其他方面,抽象类和普通的类并没有区别。
接口:[ public ] interface InterfaceName {
[ public static final ] String MSG = "hello",//全局常量
[ public abstract ] void print();//抽象方法
}
2)方法会被隐式地指定为public abstract方法
语法层面区别:
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
设计层面上的区别:
1)抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
7、创建成员内部类对象的一般方式
public class Test {
public static void main(String[] args) {
//第一种方式:
Outter outter = new Outter();
Outter.Inner inner = outter.new Inner(); //必须通过Outter对象来创建
//第二种方式:
Outter.Inner inner1 = outter.getInnerInstance();
}
}
class Outter {
private Inner inner = null;
public Outter() {
}
public Inner getInnerInstance() {
if(inner == null)
inner = new Inner();
return inner;
}
class Inner {
public Inner() {
}
}
}
8、线程创建到消亡的状态
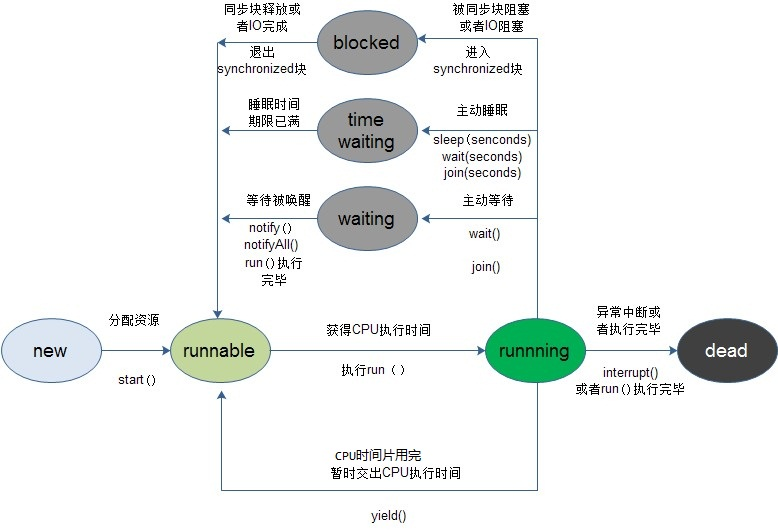
9、Lock和synchronized的选择
总结来说,Lock和synchronized有以下几点不同:
1)Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
2)synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
5)Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
10、nio读写文件
public static void main(String[] args) throws IOException {
FileInputStream in = new FileInputStream("D:\bbb.txt");
FileOutputStream on = new FileOutputStream("D:\aaa.txt");
//为该文件输入流生成唯一的文件通道 FileChannel
FileChannel channel = in.getChannel();
FileChannel fileChannel = on.getChannel();
//开辟一个长度为1024的字节缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
while(true){
//clear方法重设缓冲区,可以读新内容到buffer里
buffer.clear();
if (channel.read(buffer) == -1) {
break;
}
System.out.println(new String(buffer.array(),"GBK"));
//flip方法让缓冲区的数据输出到新的通道里面
buffer.flip();
fileChannel.write(buffer);
}
}
11、return、continue、break
public static void main(String[] args) {
for (int i = 0; i < 6; i++) {
if (i==4) {
return;//0 1 2 3 满足return条件后该循环体以及循环后的方法不往下执行
// break;//0 1 2 3 111 满足break条件后该循环终止,但循环后的方法仍往下执行
// continue;//0 1 2 3 5 111 仅满足continue条件的项不执行,循环体以及循环后的方法仍执行
}
System.out.println(i);
}
System.out.println(111);
}
12、简单工厂模式
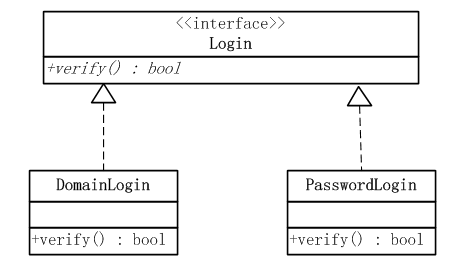
工厂方法模式
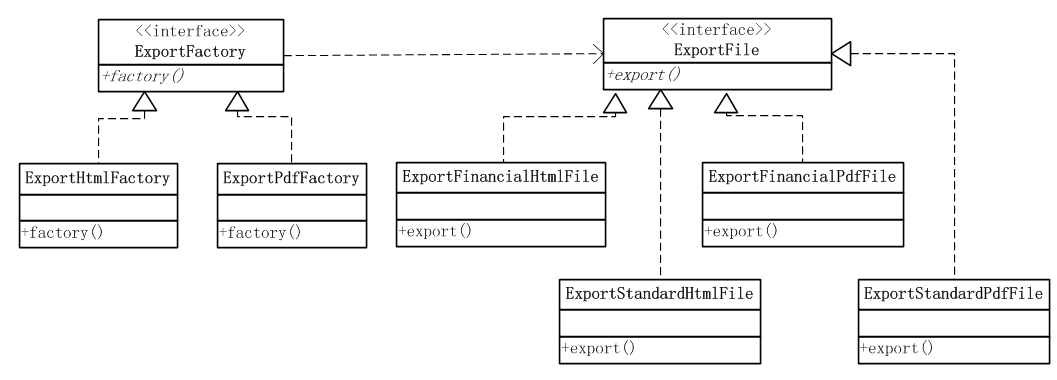
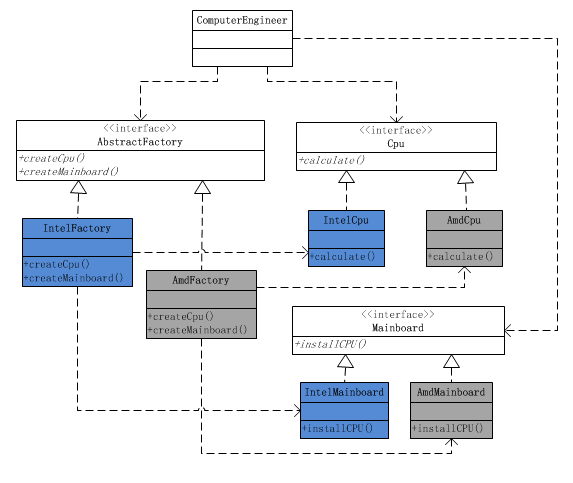
抽象工厂模式
http://www.cnblogs.com/java-my-life/archive/2012/03/28/2418836.html
在什么情况下应当使用抽象工厂模式
(1)一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有形态的工厂模式都是重要的。
(2)这个系统的产品有多于一个的产品族,而系统只消费其中某一族的产品。
(3)同属于同一个产品族的产品是在一起使用的,这一约束必须在系统的设计中体现出来。(比如:Intel主板必须使用Intel CPU、Intel芯片组)
(4)系统提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于实现。
13、成员变量与局部变量的区别:
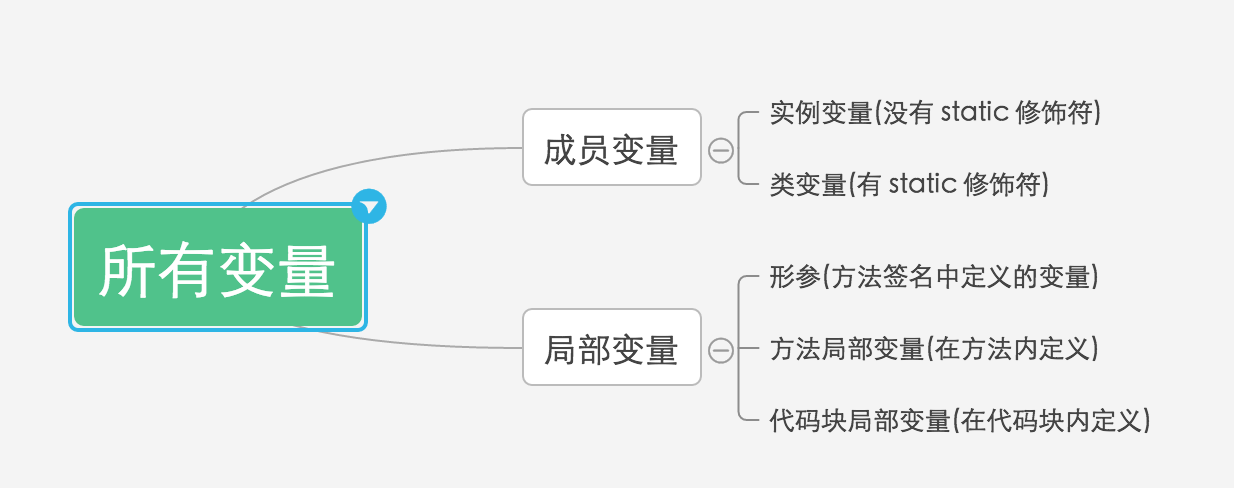
一:在方法中声明的变量,即该变量是局部变量,每当程序调用方法时,系统都会为该方法建立一个方法栈,其所在方法中声明的变量就放在方法栈中,当方法结束系统会释放方法栈,其对应在该方法中声明的变量随着栈的销毁而结束,这就局部变量只能在方法中有效的原因。在方法中声明的变量可以是基本类型的变量,也可以是引用类型的变量。
(1)当声明是基本类型的变量的时,其变量名及值(变量名及值是两个概念)是放在JAVA虚拟机栈中
(2)当声明的是引用变量时,所声明的变量(该变量实际上是在方法中存储的是内存地址值)是放在JAVA虚拟机的栈中,该变量所指向的对象是放在堆类存中的。
二:在类中声明的变量是成员变量,也叫全局变量,放在堆中的(因为全局变量不会随着某个方法执行结束而销毁)。同样在类中声明的变量即可是基本类型的变量 也可是引用类型的变量
(1)当声明的是基本类型的变量其变量名及其值放在堆内存中的
(2)引用类型时,其声明的变量仍然会存储一个内存地址值,该内存地址值指向所引用的对象。引用变量名和对应的对象仍然存储在相应的堆中
(1)定义的位置不同
成员变量定义在类中,在整个类中都可以被访问。
局部变量只定义在局部范围内,如:函数内,语句内等。
(2)在内存中的位置不同
成员变量存在于对象所在的堆内存中。
局部变量存在于栈内存中。
(3)生命周期不同
成员变量随着对象的建立而建立,随着对象的消失而消失。
局部变量随着方法的运行而出现,随着方法的弹栈而消失。
(4)初始化不同
成员变量不管程序有没有显式的进行初始化,加载时Java虚拟机都会先自动给它初始化为默认值。
局部变量声明之后,Java虚拟机就不会自动给它初始化为默认值,因此局部变量的使用必须先经过显式的初始化。
14、静态变量与成员变量的区别:
(1)所属范围不同
静态变量所属于类,成员变量所属于对象。
静态变量也称为:类变量 成员变量也称为:实例变量。
(2)调用不同
静态变量可以被对象和类名调用(一般用类名调用)。
成员变量只能被对象调用。
(3)加载时期不同
静态变量随着类的加载而加载。
成员变量随着对象的加载而加载。
(4)内存的存储区域不同
静态变量存储在方法区。
成员变量存储在堆内存。
15、摘录于http://www.cnblogs.com/xiaoxi/p/6428432.html
http://www.cnblogs.com/xiaoxi/p/6473480.html
(1)从Set集合元素不可重复性看hashCode()的作用
Set里面的元素是不可以重复的,那么如何做到?Set是根据equals()方法来判断两个元素是否相等的。比方说Set里面已经有1000个元素了,那么第1001个元素进来的时候,最多可能调用1000次equals方法,如果equals方法写得复杂,对比的东西特别多,那么效率会大大降低。使用HashCode就不一样了,比方说HashSet,底层是基于HashMap实现的,先通过HashCode取一个模,这样一下子就固定到某个位置了,如果这个位置上没有元素,那么就可以肯定HashSet中必定没有和新添加的元素equals的元素,就可以直接存放了,都不需要比较;HashCode相等,再equals比较,没有相同的元素就存,有相同的元素就不存。如果原来的Set里面有相同的元素,只要HashCode的生成方式定义得好(不重复),不管Set里面原来有多少元素,只需要执行一次的equals就可以了。这样一来,实际调用equals方法的次数大大降低,提高了效率。
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode在上面扮演的角色为寻域(寻找某个对象在集合中区域位置)。hashCode可以将集合分成若干个区域,每个对象都可以计算出他们的hash码,可以将hash码分组,每个分组对应着某个存储区域,根据一个对象的hash码就可以确定该对象所存储区域,这样就大大减少查询匹配元素的数量,提高了查询效率。
每个Java类都包含hashCode() 函数。但是,仅仅当创建某个“类的散列表”(Java集合中本质是散列表的类,如HashMap,Hashtable,HashSet)时,该类的hashCode() 才有用(作用是:确定该类的每一个对象在散列表中的位置);其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等),类的hashCode() 没有作用。
也就是说:hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
(2)equals()的作用
equals() 的作用是 用来判断两个对象是否相等(即,是否是同一个对象)。
public boolean equals(Object obj) {
return (this == obj);
}
既然Object.java中定义了equals()方法,这就意味着所有的Java类都实现了equals()方法,所有的类都可以通过equals()去比较两个对象是否相等。 但是,我们已经说过,使用默认的“equals()”方法,等价于“==”方法。因此,我们通常会重写equals()方法:若两个对象的内容相等,则equals()方法返回true;否则,返回fasle。
下面根据“类是否覆盖equals()方法”,将它分为2类。
(01) 若某个类没有覆盖equals()方法,当它的通过equals()比较两个对象时,实际上是比较两个对象是不是同一个对象。这时,等价于通过“==”去比较这两个对象。
(02) 我们可以覆盖类的equals()方法,来让equals()通过其它方式比较两个对象是否相等。通常的做法是:若两个对象的内容相等,则equals()方法返回true;否则,返回fasle。
(3)hashCode()与equals()总结
1)hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的;
2)如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同;
3)如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点;
4)两个对象的hashCode相同,并不一定表示两个对象就相同,也就是不一定适用于equals(java.lang.Object) 方法,只能够说明这两个对象在散列存储结构中,如Hashtable,他们“存放在同一个篮子里”。
hashCode是用于查找使用的,而equals是用于比较两个对象的是否相等的。
例如内存中有这样的位置
0 1 2 3 4 5 6 7
而我有个类,这个类有个字段叫ID,我要把这个类存放在以上8个位置之一,如果不用hashcode而任意存放,那么当查找时就需要到这八个位置里挨个去找,或者用二分法一类的算法。 但如果用hashcode那就会使效率提高很多。 我们这个类中有个字段叫ID,那么我们就定义我们的hashcode为ID%8,然后把我们的类存放在取得得余数那个位置。比如我们的ID为9,9除8的余数为1,那么我们就把该类存在1这个位置,如果ID是13,求得的余数是5,那么我们就把该类放在5这个位置。这样,以后在查找该类时就可以通过ID 除 8求余数直接找到存放的位置了。 但是如果两个类有相同的hashcode怎么办那(我们假设上面的类的ID不是唯一的),例如9除以8和17除以8的余数都是1,那么这是不是合法的,回答是:可以这样。那么如何判断呢?在这个时候就需要定义 equals了。 也就是说,我们先通过 hashcode来判断两个类是否存放某个篮子里,但这个篮子里可能有很多类,那么我们就需要再通过 equals 来在这个篮子里找到我们要的类。
为什么必须要重写hashcode方法,其实简单的说就是为了保证同一个对象,保证在equals相同的情况下hashcode值必定相同,如果重写了equals而未重写hashcode方法,可能就会出现两个没有关系的对象equals相同的(因为equal都是根据对象的特征进行重写的),但hashcode确实不相同的。