在大数据、人工智能时代,我们通常需要从网站中收集我们所需的数据,网络信息的爬取技术已经成为多个行业所需的技能之一。而Python则是目前数据科学项目中最常用的编程语言之一。使用Python与BeautifulSoup可以很容易的进行网页爬取,通过网站爬虫获取信息可以帮助企业或个人节省很多的时间和金钱。学习本文之后,我相信大部分新手都能根据自己的需求来开发出相应的网页爬虫。
基础条件
了解简单的Python编程规则(Python 3.x)了解简单的网页Html标签
如果您是完全的新手也不用担心,通过本文您可以很容易地理解。
安装所需包
首先,您需要先安装好Python 3.x,Python安装包可以从python.org下载,然后我们需要安装requests和beautifulsoup4两个包,安装代码如下:
$ pip install requests $ pip install beautifulsoup4
爬取网页数据
现在我们已经做好了一切准备工作。在本教程中,我们将演示从没被墙的维基百科英文版页面中获取历届美国总统名单。
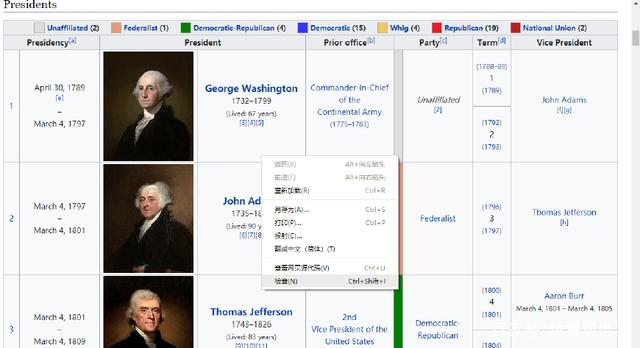
由下图可知,表格的内容位于class属性为wikitable的table标签下,我们需要了解这些标签信息来获取我们所需内容。

了解网页信息之后,我们就可以编写代码了。首先,我们要导入我们安装的包:
import requests from bs4 import BeautifulSoup
为了获取网页数据我们要使用requests的get()方法:
url = "https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States" page = requests.get(url)
检查http响应状态,来确保我们能正常获取网页,如果输出状态代码为200则为正常:
print(page.status_code)
现在我们已经获取了网页数据,让我们看看我们得到了什么:
print(page.content)
上面的代码会显示http相应的全部内容,包括html代码和我们需要的文本数据信息。通过使用beautifulsoup的prettify()方法可以将其更美观的展示出来:
soup = BeautifulSoup(page.content, 'html.parser') print(soup.prettify())
这会将数据按照我们上面“检查”中看到的代码形式展示出来:
接下来我们将使用bs4对象的find方法提取table标签中的数据,此方法返回bs4对象:
tb = soup.find('table', class_='wikitable')
table标签下有很多嵌套标签,通过网页检查中的代码可以发现,我们最终是需要获得title元素中的文本数据,而title元素位于a标签下,a标签位于b标签下,b标签位于table标签下。为了获取所有我们所需的数据,我们需要提取table标签下的所有b标签,然后找到b标签下的所有a标签,为此,我们使用find_all方法来迭代获取所有b标签下的a标签:
for link in tb.find_all('b'):
name = link.find('a')
print(name)
可以看出,这并不是我们所要的最终结果,其中掺杂着html代码,不用担心,我们只需为上面的代码添加get_text()方法,即可提取出所有a标签下title元素的文本信息,代码改动如下:
for link in tb.find_all('b'): name = link.find('a') print(name.get_text('title'))
最终获得所有总统的名单如下:
George Washington
John Adams
Thomas Jefferson
James Monroe
。。。